{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于知识粒度的约简在Web使用挖掘中的应用研究
引用本文
赵洁, 莫赞, 刘洪伟, 张沙清, 董振宁. 基于知识粒度的约简在Web使用挖掘中的应用研究. 现代图书情报技术, 2013, 29(2): 50-56
Zhao Jie, Mo Zan, Liu Hongwei, Zhang Shaqing, Dong Zhenning. Web Usage Mining Using Reduction of Knowledge Granule. New Technology of Library and Information Service, 2013, 29(2): 50-56
Permissions
Zhao Jie, Mo Zan, Liu Hongwei, Zhang Shaqing, Dong Zhenning. Web Usage Mining Using Reduction of Knowledge Granule. New Technology of Library and Information Service, 2013, 29(2): 50-56
基于知识粒度的约简在Web使用挖掘中的应用研究
摘要
基于粒计算思想, 构建多粒度的Web用户行为描述模型, 然后使用基于知识粒度的约简算法对数据进行约简。实验数据证明, 模型可描述多种粒度的用户行为特征, 其中的总体行为描述模型有横向约简数据的效果, 基于粒度原理的约简算法能更高效地对海量数据进行纵向约简, 有效减轻后续模式分析的工作量。
关键词:
Web使用挖掘; 多粒度; 约简
Web Usage Mining Using Reduction of Knowledge Granule
Abstract
This paper proposes multi-granularity Web user behavior description model using granular theory, then the reduction algorithm based on knowledge granule is applied for the data. The experiment results prove that the model can not only descript multi-granularity user behavior characteristics, but also have the effect of horizontal dimension reduction. And efficient vertical dimension reduction is achieved by the reduction algorithm, which effectively reduce the work in the subsequent pattern analysis.
Keyword:
Web usage mining; Multi-granularity; Reduction
1 引 言
高维问题在Web使用挖掘分析中经常遇到, 如在对Web用户进行聚类分析中, 以网页作为属性对用户进行聚类、购物篮分析等。因为Web站点的页面数以百千计, 用页面作为维向量的模型往往面临高维带来的数据稀疏性问题。当数据维数高于20时, 传统聚类分析的性能会急剧下降, 甚至无法完成聚类任务。为了解决高维问题, 其中一种方法是采用属性转换或者属性约简方法, 以减少数据维度[1]。
文献[2]通过奇异值分析来对聚类算法中的URL进行降维。文献[1]提出降低维度是在指定最大平均对数可能性下无监督学习过程的结果, 并把相关的降维策略应用到聚类中, 可以防止产生超大聚类, 并减少无用聚类的个数。 文献[3]对聚类中用户访问的特征进行概化, 以减少维数。文献[4]为了解决传统聚类方法处理高维稀疏数据对象聚类结果不理想的问题, 提出SS/OSF聚类方法, 该方法基于对象组相似度 (SS) 和对象组特征向量 (OSF) , 并借助对象特征向量的可加性实现, 用于对以网页作为维度的Web用户进行聚类。文献[5]用模糊粗糙集属性约简方法来对高维向量进行降维, 从而提高分类准确度和计算效率。但上述方法一定程度上存在算法效率不理想和信息损失的问题。数据约简分为横向元组约简与纵向属性约简两种[6]。目前基于粗糙集理论的属性约简效果最好。属性约简是粗糙集研究的重要内容之一[7], 是指在保证信息系统分类或决策能力不变的条件下, 删除条件属性中的冗余属性, 从而减少数据挖掘要处理的数据量。
总结Web用户分析研究中存在的问题, 绝大部分研究对于Web用户浏览行为的描述都基于单一粒度即会话/事务的描述模型。虽然会话/事务的粒度较细, 具有较强的分辨能力, 但存在较多问题: 若数据源为单纯的Web日志, 那么会话识别尤其是事务识别的精度会极大影响挖掘效果, 从而使得后续的模式分析很难得到有价值的知识; 同时, 由于自身特点, 会话/事务具有瞬时性、片面性, 其中一个会话/事务中仅含有少量页面序列, 仅表现用户行为片断, 描述的粒度虽然很细, 但无法比较稳定和准确地描绘用户行为特征; 在实际分析中, 由会话/事务构成的用户描述矩阵, 往往是维度巨大的稀疏矩阵, 这为后续模式分析提出了巨大挑战。
Web用户行为体现出多元化、复杂化的特征, 如何更好地捕捉用户的行为特征, 从而进一步挖掘用户的爱好、习惯, 是学术界和电子商务实践者关注的热点。基于此, 本文将粒计算的思想应用于Web使用挖掘中, 通过对数据的多粒度描述, 提供更全面的用户行为描述, 然后对数据进行纵向约简, 为后续模式分析提供优质数据, 并符合海量数据的速度要求。
2 粒度原理及整体框架
由知识颗粒及知识粒度定义[7, 8]可知, 一个基本颗粒相当于Rough集的一个等价类, 等价类也称为等价颗粒。粒度本身是物理学的概念, 指“微粒大小的平均度量”[9], 知识R粒度的大小表示它的分辨能力。当R为相等关系时, R的粒度达到最小值; 当R为论域关系时, R的粒度达到最大值。
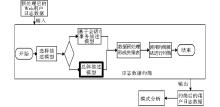
本文提出约简在Web使用挖掘中应用的整体流程, 如图1所示:
 | 图1 约简在Web使用数据中应用的整体框架 |
把经过预处理的Web用户行为数据作为输入。选择描述模型, 根据不同描述模型得到不同的行为描述矩阵, 对矩阵中的数据进行离散化等处理, 形成决策表, 使用约简算法对决策表进行约简。最后把约简后的决策表作为输出。总体描述模型具有纵向约简效果, 因此在图1中用加粗框进行区别。
3 基于总体行为描述模型的横向约简
本文提出的多粒度行为描述模型, 包括经典的基于事务的和基于总体行为的描述模型。前者粒度较小, 能提供对用户行为的精细分析, 采用页面浏览时间和页面点击次数作为描述指标, 与现有的研究方法类似; 后者模型粒度较大, 提供对用户行为的整体分析。下面主要针对总体行为模型进行分析。
3.1 基于总体行为描述指标的横向约简分析
在本描述模型中, 提出三个新指标对用户行为进行描述, 包括: 浏览频度、总浏览时间和总浏览次数, 详细阐述可参考文献[10]。
与基于会话/事务的描述模型不同, 这三个指标关注的是一段时间内某个用户的总体浏览行为, 所涉及的浏览时间和次数是在一段时间内所有浏览页面时间和次数的汇总, 从而把描述一个用户的多个会话/事务纵向压缩成更少的记录。由于在一段较长的时间内, 同一个用户所浏览的页面可能更多, 因此基于上述指标构建的行为描述矩阵中数据的稀疏度将会大大降低, 不仅有效降低后续模式分析算法设计的难度, 而且更容易从中挖掘用户的兴趣、意向和特征。总体描述模型中的粒度也可进一步细分为周、月、季度和年等, 这相当于在模型中进一步引入了易于理解的时间因素, 具有很好的现实解释性, 也能更好地区别用户的活跃性, 有助于进一步制定营销决策。
虽然总体行为仍以会话识别为基础, 但是总体行为指标是对一段时间内若干会话的聚合, 因此预处理阶段的会话识别所产生的误差会在一定程度上得到消除, 会话识别精度所产生的负面影响也因此会有所下降, 后续模式分析的准确度会得到一定提高。并且总体行为描述指标值的计算基于经典的会话识别, 因此实现代价较小。
3.2 基于总体行为描述指标的描述矩阵
以下定义中, n表示站点URL 的个数, m表示用户数。
定义1: 用户浏览频度矩阵。 根据浏览频度定义[10]建立Web站点的用户浏览频度矩阵如下, 其中, fij 为第i个用户对第j个URL在一段时间内的浏览频度。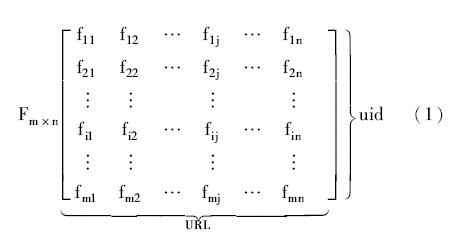
定义2: 用户总浏览时间矩阵。 根据总体浏览时间定义[10]建立一段时间内Web站点用户对网页的总浏览时间矩阵如下, 其中, t′ij 为第i个用户事务对第j个URL 在一段时间内总的浏览时间。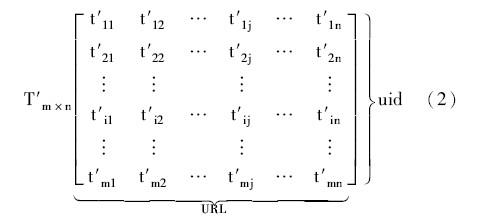
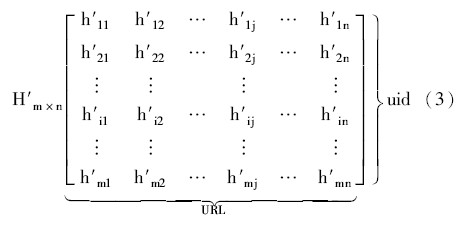
定义3: 用户总点击次数矩阵。 根据总体点击次数定义[10]建立一段时间内Web站点用户对网页的总浏览时间矩阵如下, 其中, h′ij 为第i个用户事务对第j个URL 在一段时间内总的点击次数。
4 基于约简算法的纵向约简
4.1 基于知识粒度的约简算法
求取最小属性约简已被证明是一个NP-Hard问题[11], 本文将决策表存储在数据库中, 通过动态SQL语句生成所使用的各属性字符串, 并且通过SQL语句, 得到已排序的数据集, 降低算法实现的复杂度。前期工作中, 笔者设计了基于知识粒度的高效完备约简算法[12]。其中等价类算法时间复杂度为O (|A||U|) , 正域计算的时间复杂度降低到O (|A||U/P|) , 在最差的情况下|U/P|=|U|。计算正区域的算法复杂度为O (|D||U|) , 基于此计算SGF (a, R, D) 的时间复杂度为O (|D||U|) , 从而得到最终约简算法的复杂度是O (|C|2|U|) , 空间复杂度为O (|U|) 。算法中采用多种启发策略, 包括舍弃无用属性, 采用新启发信息选择属性, 使用前向检验策略, 以及减少不必要计算。理论和实验分析证明, 该约简算法适用于海量Web使用数据的挖掘。
4.2 基于3M算法的指标值离散化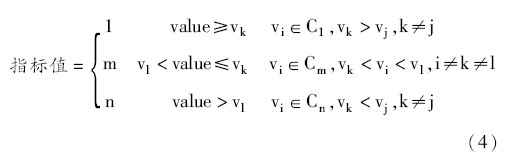
在对数据约简和后续分析中,需要对数据进行离散化。目前绝大多数的研究[4, 13-15]对于浏览指标,仅依靠人工设定区间,方法比较简单,但带有较强的主观性,当数据随时间或用户行为发生变化时,区间没有随之变化。
本文使用聚类算法3M[16]对数据进行离散化,采用属性(指标值、个数)对数据特征进行描述,得到最佳的聚类模式和类别个数n,并根据以下公式得到离散化数据:.
其中,Ck表示按大小排序后的簇。如果决策者认为某些簇成员数过大,可以对这些簇再次进行聚类。最后得到n个排序后的簇{C1,C2,…,Cn},然后利用公式(4),将数据离散化。
4.3 纵向约简流程
.
基于上述分析得到行为描述模型中的矩阵,包括浏览时间、浏览次数、浏览频度、总体浏览时间、总体浏览次数5个矩阵,通过对数据横向加总,获得决策属性D,从而构造决策表;使用上述3M算法对表中的属性分别进行离散处理;使用约简算法对决策表进行约简。约简后的决策表即可作为后续模式分析的输入。
以总体浏览时间为例说明约简的整体流程,如图 2所示:
 | 图2 基于约简算法的纵向约简流程 |
对源数据进行预处理,进行用户识别和会话识别。通过会话识别计算用户在某一个页面上的浏览时间。假设本次统计粒度为“周”,则把前6天到第7天所发生的会话作为分析对象。用户uk访问页面pi的时间为ti,若在后续页面pi+1的访问时间为ti+1,则认为uk在页面pi的停留时间为tstay=ti+1-ti,通过一周内所有会话中pi的停留时间加总得到uk总停留时间tv。对tstay和tv使用3M算法进行离散化,得到一个用户访问页面的决策表S,S=(U,R,V,f),R=C∪D,其中C={ai|i=1,2,…m}是条件属性集合,具体为用户访问的页面pj(j=1,2,…m);D={d}是决策属性;上述用户的总停留时间tv的离散值作为决策属性;U={x1, x2,… xn}为论域ui(i=1,2,…n);V为属性的值域,即用户访问页面的总停留时间的离散值;ai(xj)是样本xj在属性ai上的取值,即uj在pi上的停留时间的离散值;最后,对决策表应用上述的约简算法,得到约简后的属性集合C’={ai|i=1,2,…q},具体为py(y=1,2,…q),其中y≤m。
5 实验设计及分析
测试数据源来自广东省某大型金属公司电子商务平台的UIBD日志[17]。首先对比不同用户描述模型,对横向约简的结果进行分析;然后把不同的约简算法应用到基于会话/事务和总体行为两种描述模型中,对纵向约简结果进行分析。
5.1 横向约简实验及结果分析
.
.
以月为时间单位,对基于事务的描述模型和用户总体行为描述模型的数据进行对比,如表 1所示。
| 表1 不同行为描述模型下的数据对比 |
其中,类型1数据是事务模型下分析所得数据,类型2是用户总体行为模型下所得数据,类型3是用户总体行为模型下、统计1-6月共同出现的用户所得数据。
 | 图3 不同粒度数据的数量比对 |
由图 3可知,不同模型下的数据相差很大,如果不加区别地使用,可能造成时间、效率上的损失。如果在实际应用中,对这些数据有选择性地使用,将事半功倍。
两种模型下的数据都可以形成多种粒度:不同时间粒度和不同用户粒度。不同时间粒度的数据可基于月、季度、年等不同时间单位,分析用户行为在不同时间中的变化规律,及在不同时期的活跃程度,考虑时节、季节对用户购买行为的影响。
基于事务模型细小粒度的数据分析,体现了个体的使用习惯、爱好,分析结果主要用于优化网站结构及个性化服务等方面。
对于不同用户粒度,可以在所有用户中抽取出“忠实”用户。如上述类型3数据,抽取了6个月连续出现的“忠实”用户数据,这些用户可以认为是长期对网站感兴趣,处于活跃状态的用户,可重点对这些用户进行研究,提高他们的忠诚度,并制定营销策略。本文的用户总体行为描述模型中,时间单位为月。
5.2 纵向约简实验及结果分析
(2)约简算法在两种描述模型中运算结果对比.
.
部特征的方法所得到的分析结果反映的是短期的趋势和规律,基于全局特征的方法所得到的结果反映的是长期的趋势和规律。在实际应用中,可以根据需要,采用不同粒度数据和不同粒度(包括时间和用户)的特征进行离散化。
本实验验证基于粒度原理属性约简算法(简称本文算法)对Web使用挖掘数据约简的准确性和高效性,实验中采用算法 b[11]与本文算法进行比较。
(1)约简结果描述指标.
按整体框架中的思想对数据进行处理,得到相应的决策表。为了对比结果,定义以下两个属性:.
属性约简率AR=(决策表属性数-约简后属性数)决策表属性数×100%.
约简结果相似度ARS=本文算法约简结果∩算法b约简结果本文算法约简结果∪算法b约简结果×100%
| 表2 在日志上约简结果对比 |
取不同粒度的数据分析,以月、季度和半年为单位,离散化有多种方案,依据不同的数据特征可以得到不同的离散化结果,采用两种方案进行对比。
方案1:使用全局特征(半年数据特征)进行离散化。
方案2:每个月的数据使用局部特征(本月数据特征)进行离散化。
 | 图4 离散化后区间中记录数量对比 |
 | 图5 离散化后区间数量对比 |
可以看出,在实际应用中,应该根据实际需要采取不同的离散化方案。例如,基于小粒度数据特征的分析,得到的是短期用户行为的特征;基于大粒度数据特征的分析,则可得到较长时期用户行为的特征。不同结果之间的比较,体现了用户行为的动态特征,反映出用户兴趣、需求的变化。
| 表3 表3 不同约简算法在事务模型数据的约简结果对比1(方案1) |
| 表4 表4 不同约简算法在事务模型数据的 |
由表3和表4可知,大部分情况下,两种算法均可以获得约简,两种约简结果相似。基于事务模型的分析,粒度较小,因此可被约简的数据较少,这与预期相符。
由表5和表6可知,本文基于知识粒度的算法在大多数情况下获得最小约简结果。基于总体模型的分析,粒度较粗,比较有针对性,因此得到更简洁的结果。
从以上实验数据可知,基于不同的数据粒度和不同特征的离散数据,约简会得到不同的结果。 基于局
| 表5 表5 不同算法在总体行为模型数据 约简结果对比1(方案1) |
| 表6 表6 不同算法在总体行为模型数据约简结果对比2(方案2) |
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|