{kind=link}
{kind=link}
应用实践国家精品课程网上资源用户满意度评价模型构建*
引用本文
胡德华, 任磊, 车丹. 应用实践国家精品课程网上资源用户满意度评价模型构建*. 现代图书情报技术, 2013, 29(1): 75-82
Hu Dehua, Ren Lei, Che Dan. Research on Consumer Satisfaction Index Evaluation Model of Online Resources for National Elaborate Curriculum. New Technology of Library and Information Service, 2013, 29(1): 75-82
Permissions
Hu Dehua, Ren Lei, Che Dan. Research on Consumer Satisfaction Index Evaluation Model of Online Resources for National Elaborate Curriculum. New Technology of Library and Information Service, 2013, 29(1): 75-82
应用实践国家精品课程网上资源用户满意度评价模型构建*
摘要
构建包括7个隐变量(用户经验、用户需要、用户预期、质量感知、价值感知、用户满意度和用户忠诚)的国家精品课程网上资源用户满意度评价模型, 然后利用Smart PLS软件实证该模型的科学性, 并探讨该模型的应用前景。
关键词:
国家精品课程; 网上资源; 用户满意度; PLS路径模型
Research on Consumer Satisfaction Index Evaluation Model of Online Resources for National Elaborate Curriculum
Abstract
Consumer Satisfaction Index (CSI) evaluation model of online resources is built for National Elaborate Curriculum(NEC), which has seven latent variables such as user experience, user need, user expect, perceived quality, perceived value, user satisfaction and user loyalty. And then the authors conduct an empirical research on the model by Smart PLS and confirm the scientific of the model. In the end, the application of the model is evaluated and analyzed.
Keyword:
National elaborate curriculum; Online resources; Consumer satisfaction index; PLS path model
1 引 言
国家精品课程是具有一流教师队伍、一流教学内容、一流教学方法、一流教材、一流教学管理等特点的示范性课程[1], 其网上资源不仅包括与课程教学和管理相关的课程资源, 如教学大纲、教案、习题、实验指导、参考资料等, 还包括网络课件和授课录像等[2], 是国家精品课程评估的主要依据, 也是课程资源共享的基础。
自从美国学者Cardozo于1965年首次发表论文探索用户满意度之后, 众多专家与学者对“ 用户满意度” 进行了探讨[3, 4, 5, 6, 7]。并且应用到图书馆电子资源质量评价、馆藏资源评价、网站评价等各个方面[8, 9, 10]。近年来, 用户满意度理论逐步引入到精品课程评价, 如钱学艳等[11]对预防医学精品课程建设满意度进行了调查分析, 韩正彪等[12]构建了信息检索与利用国家精品课程网站的用户满意度测评模型。但是这些评价的主体主要是学生, 较少涉及教师, 并且评价指标和模型是针对某一特定的课程。
因此, 本文将用户满意度理论引入到国家精品课程网上资源评价, 以“ 用户(教师和学生)” 为中心, 结合国家精品课程网上资源的特征, 构建国家精品课程网上资源用户满意度评价模型, 对其进行实证研究, 以建立具有实践价值的国家精品课程网上资源测评方法。
2 国家精品课程网上资源用户满意度的
相关维度分析
瑞典首次于1989年建立起顾客满意度指数模型(Swedish Customer Satisfaction Barometer, SCSB), 主要包括感知表现、顾客期望、顾客满意度、顾客抱怨和顾客忠诚5个维度(即隐变量)[13]。之后, 德国、加拿大等20多个国家和地区先后建立了全国或地区性的顾客满意指数模型。Fornell等[14]在SCSB模型的基础上, 提出美国顾客满意度指数模型(American Customer Satisfaction Index, ACSI), 创新性地增加了一个维度— — 价值感知, 共有6个维度。与其他模型相比, ACSI模型更加科学地反映顾客的消费认知过程, 客观地体现消费者对服务质量的评价, 综合表征顾客满意的程度, 并在全世界各个领域得到广泛应用。
本文以ACSI模型为基础, 考虑到评价的主体(学生或老师)均具有相关的知识或经验, 提出用户经验维度, 作为探索型变量考察其对用户满意及其他隐变量的影响。此外, 学生需要借助国家精品课程网上资源进行课程学习、参考复习等; 教师需要借助国家精品课程网上资源进行课程建设或指导教学等, 因此根据马斯洛的需要层次理论, 本文提出用户需要维度。它们与ACSI的6个维度一起构成本模型的8个维度。结合国家精品课程网上资源的特征, 详细分析如下:.
(1)用户经验: 是指国家精品课程网上资源用户使用网上资源之前已经具有的关于其他课程网上资源的使用经验, 不仅包括其他学校同一课程网上资源的使用经验, 还包括其他课程的使用经验, 以及用户本身关于课程专业知识的积累程度。用户经验会直接或间接影响用户对国家精品课程网上资源的预期, 以及对其质量的平均水平的认知, 进而影响用户满意度。因此用户经验是与用户满意有重要关联的隐变量。
(2)用户需要:根据马斯洛的需要层次理论, 只有需要才会付诸行动, 进而对行为的结果产生满意或不满意的态度。对于国家精品课程网上资源, 用户需要直接从学习或者教学任务中产生, 即“ 求知的需要” , 这种需要能否得到满足是用户能否满意的重要因素。
(3)用户预期:用户在购买和使用产品或服务之前对产品或服务质量等方面的期望。对于国家精品课程网上资源用户, 面对已经产生的用户需要, 抱有“ 能够通过学习行为解决问题” 的期待和信念即为用户预期。而这实际上就是对国家精品课程网上资源的预期, 具体表现为对学习资料与学习过程的预期, 即对精品课程网上资源内容、功能和服务性的预期。
(4)质量感知:是在用户购买并消费某种产品或服务一定时期以后, 对其质量水平的实际感受。就国家精品课程网上资源而言, 其用户的质量感知应该理解为用户在使用精品课程网上资源之后, 对网上资源提供的信息系统性能、信息内容本身以及服务水平等做出的主观评判及总体评价和感受。而用户后期对网上资源满意与否, 更多是在实际感受的水平上与用户经验、用户预期、甚至是用户需要进行比较而得出的。
(5)价值感知:是用户在同时考虑消费代价、质量感知以及用户需要之后对产品或服务的评价, 即对比用户在购买和使用某产品或服务时所付出的时间和精力与使用产品或服务后的收获而得出的主观判断。对于国家精品课程网上资源用户, 价值感知是网上资源搜索结果满足用户需要的程度的主观评价, 包括“ 内容价值感知” 、“ 服务价值感知” 、“ 功能价值感知” 和“ 与付出相比的用户总体价值感知” 。
(6)用户满意:是指用户在购买和使用某产品或服务以后, 形成的满意或不满意的态度。对于国家精品课程网上资源, 用户满意度是综合考虑用户经验、用户预期和价值感知等方面后得出的对课程网上资源的满意或不满意的主观态度, 包括与曾经的课程网上资源使用经历相比此次消费经历达到预期水平与否、达到平均水平与否、达到理想水平与否和总体满意程度4个方面。
(7)用户抱怨:是指用户在购买和使用某产品或服务过程中所产生的不满以及后续行为, 包括“ 正式抱怨” 和“ 非正式抱怨(负面口碑)” 两种形式。对于国家精品课程网上资源, 用户“ 正式抱怨” 表现为向课程建设者提出抱怨, 而“ 非正式抱怨” 表现为向其他人诉说对课程网上资源的不满意。“ 用户抱怨” 是课程建设者非常重视的信息, 资源建设水平的提高是通过用户抱怨而实现的, 而且当用户得知自己的抱怨受到重视和采纳时往往会增加对资源的喜爱程度, 进而提高用户忠诚, 因此具有实际的研究价值。
(8)用户忠诚:是指用户在使用过某产品与服务后, 愿意再次发生同种消费行为的可能性, 即用户对某种品牌的产品或服务持有肯定态度的程度、承诺的程度以及愿意在未来继续发生消费行为的程度。对于国家精品课程网上资源, 其用户忠诚是对课程建设者的肯定和支持, 是课程建设者持续提供优质资源的动力。该隐变量包括两个显变量, “ 首选使用” 和“ 参考使用” 。课程资源的使用不存在“ 排它性” , 可以同时使用多种资源来完成对同一信息需要的满足, “ 首选使用” 和“ 参考使用” 正是根据课程资源的这一使用特点而设计的。
3 概念模型的提出
根据上述分析, 初步提出国家精品课程网上资源用户满意度概念模型, 如图1所示:
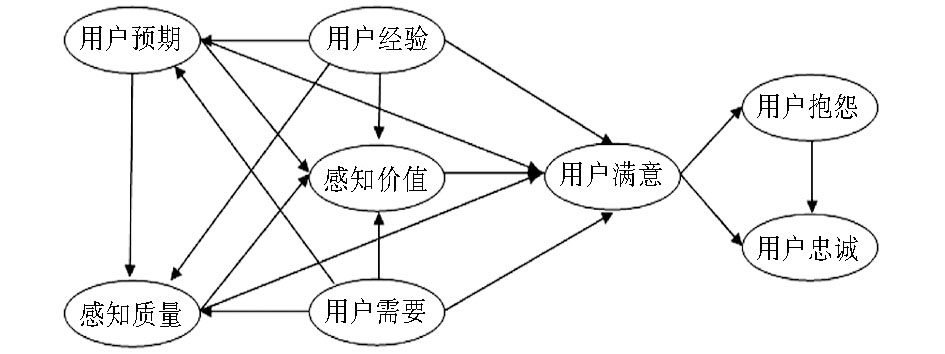 | 图1 国家精品课程网上资源用户满意度概念模型 |
3.1 隐变量间的关系假设
(1)用户经验与用户预期显著正相关;
(2)用户经验与价值感知显著正相关;
(3)用户经验与质量感知显著正相关;
(4)用户经验与用户满意显著正相关;
(5)用户需要与用户预期显著正相关;
(6)用户需要与质量感知显著正相关;
(7)用户需要与价值感知显著正相关;
(8)用户需要与用户满意显著正相关;
(9)用户预期与质量感知显著正相关;
(10)用户预期与价值感知显著正相关;
(11)用户预期与用户满意显著正相关;
(12)质量感知与价值感知显著正相关;
(13)质量感知与用户满意显著正相关;
(14)价值感知与用户满意显著正相关;
(15)用户满意与用户忠诚显著正相关;
(16)用户满意与用户抱怨显著负相关;
(17)用户抱怨与用户忠诚显著负相关。
3.2 显变量及其与隐变量的关系
在上述隐变量及其相互关系基础上, 根据网上资源评价理论及相关研究以及学生访谈和专家咨询, 结合国家精品课程网上资源的特征, 提出以下显变量, 它们与隐变量的关系如表1所示:
| 表1 隐变量及其显变量 |
4 模型验证
4.1 评价对象
选取某工科大学化学、机械设计基础、物理化学、系统解剖和文献信息检索5门国家精品课程(以数字1、2、3、4、5表示)网上资源的用户进行调查。选取标准是: 被调查者(学生)至少有半个学期以上学习该门国家精品课程; 上课人数大于100人、正在开课并且在调查时间内尚未结课的国家精品课程。
4.2 调查问卷
充分利用专家咨询和多次试调查收集到的信息对问卷测量项目进行反复修改, 形成最终的调查问卷。相关研究表明, Likert 10对于用户满意度调查研究是比较合适的[15]。因此, 采用Likert 10评分法。经Smart PLS可靠性检验, 各个隐变量的克朗巴赫α (Cronbach’ s α )系数均大于0.78, 平均达到0.8688。同时, 各隐变量的平均提取方差(AVE)值均大于0.5, 各变量的载荷系数均大于0.5, 这表明各隐变量的聚合效度较好; 各隐变量的AVE大于所有因子相关系数的平方, 这表明各隐变量具有较好的结构效度。因此, 该问卷具有良好的信度和效度。
4.3 调查与处理方法
根据评价主体的不同, 采用不同的调查方法。对于学生, 主要采用问卷调查; 对于教师, 采用问卷调查、网上问卷调查和电话访问。回收问卷的处理方法:对于课程名称与所调查课程名称不相符的问卷, 作为无效问卷处理; 对于有缺省数据的问卷, 如果缺失数据未超过10%, 则予以缺省值处理, 即用显变量的均值代替, 以减少对其他的统计量(如标准差和相关系数)的影响[16]; 对于缺失数据超过10%的问卷, 作为无效问卷处理。回收有效问卷情况如表2所示:
| 表2 回收有效问卷情况 |
4.4 验证方法
用户满意评价模型参数估计应用最多的方法是基于PLS和LISREL的结构方程建模技术, 这两种方法各有优劣。基于成分提取的PLS方法具有很强的解释与预测能力, 对数据的分布没有严格要求而且可以是小样本。基于协方差拟合的LISREL方法对数据分布有一定要求且需要大样本。而许多国家的顾客满意度指数模型均采用PLS估计[17, 18], 因此本文利用Smart PLS软件进行验证分析[19], 采用基于PLS路径模型的参数估计方法进行探索性研究。根据软件对数据文件的格式编码要求, 需要先将数据编码输入Excel文件后, 导出TXT格式的数据文件, 再利用Smart PLS软件分析数据。
5 结 果
5.1 模型的解释能力
可以看出:用户满意度(F)回归方程的R2高达0.77, 这表明F的总变异中由A、B、C、D和E所解释的比例达到76.67%, 远远超过ECSI(欧洲顾客满意度指数)对R2值的要求(0.65), 也高于ACSI(美国顾客满意度指数)模型中顾客满意度回归方程的R2值(0.75)[20], 接近CCSI(中国顾客满意度指数)中顾客满意度回归方程的R2值(服务业平均为0.78)[21]。这表明国家精品课程网上资源用户满意评价模型(NEC Online Resources CSI)的合理性。
(1)主要隐变量对用户满意的解释能力较强。R2用于衡量结构模型的解释能力。模型检验如表3所示:
| 表3 模型检验 |
(2)模型中大部分隐变量对显变量具有较好的解释能力。具体体现在以下几个方面:
①公因子方差(Communality)衡量模型中隐变量对显变量的预测能力, 即显变量的方差中由隐变量解释的部分所占的比例。由表3可知, 从公因子方差的角度来看, 除隐变量D(质量感知)的公因子方差低于0.6外, 其余7个隐变量的公因子方差值均大于0.7, 平均达到0.80。这表明隐变量对其显变量有较好的解释能力。
②从载荷系数(Loadings)来看, 如表4所示, 30个显变量中, 只有3个显变量的载荷系数小于0.7, 8个显变量的载荷系数在0.7和0.8之间, 9个在0.8至0.9之间, 10个均大于0.9; 显变量的载荷系数平均水平达到0.84。
③从载荷系数和权重的显著性检验来看, 显变量的载荷和权重采用Bootstrapping方法进行检验[22], 由表4可知, 除了G(用户抱怨)的权重未通过检验外, 其余显变量的载荷系数和权重都有较高的T-Statistics, 显著性检验结果为“ 显著” 。这表明除G外, 其余隐变量对其显变量有较好的解释能力。
| 表4 显变量的权重和载荷系数 |
5.2 模型的预测能力
(2)交叉验证(Cross Validated, CV) 采用Blindfolding方法交叉验证隐变量实测值与模型预测值之间的拟合程度[23]。当CV>0时, 说明模型中的关系具有较强的预测能力。可分为交叉验证公因子方差(根据隐变量得分对数据进行预测)和交叉验证冗余度(根据具有解释力度的隐变量对显变量的数据进行预测)。从交叉验证的角度来看, 由表6可知, 全部隐变量的交叉验证冗余度(CV Red.)和交叉验证公因子方差(CV Com.)均有效, 其平均值分别达到0.44和0.53, 表明模型的预测能力较强。
(1)冗余度(Redundancy)用于衡量显变量对其隐变量的预测能力。冗余度越大, 说明显变量对隐变量解释的力度越大。因此作为外生隐变量的A(用户经验)和B(用户需要)没有冗余度。由表5可知, 模型中5个隐变量的冗余度均大于0.1, 模型的预测能力较强。
| 表5 模型检验 |
| 表6 模型的交叉检验 |
5.3 模型隐变量的因果关系
可以看出, 17个隐变量因果关系假设中有8个通过检验, 认为具有显著性, 即A→ D(用户经验与质量感知呈显著正相关)、B→ C(用户需要与用户预期呈显著正相关)、B→ D(用户需要与质量感知呈显著正相关)、C→ D(用户预期与质量感知呈显著正相关)、D→ E(质量感知与价值感知呈显著正相关)、D→ F(质量感知与用户满意呈显著正相关)、E→ F(价值感知与用户满意呈显著正相关)和F→ H(用户满意与用户忠诚呈显著正相关); 而其余隐变量因果关系假设未通过检验, 不能认为其具有显著性。
本文采用Bootstrapping检验技术对隐变量之间因果关系假设进行验证, Bootstrapping检验是计算每个路径系数的标准误差(Standard Error, SE), 并利用该标准误差计算T统计量(T-Statistics), 依据T-Statistics的大小判断其关系的显著性。隐变量因果关系检验如表7所示:
| 表7 隐变量因果关系检验 |
对于未通过的隐变量因果关系, 可能的解释如下:
(1)A(用户经验)对C(用户预期)、E(价值感知)和F(用户满意)的路径系数不显著。B(用户需要)对E(价值感知)和F(用户满意)的路径系数不显著。原因在于:
①A(用户经验)对C(用户预期)、E(价值感知)和F(用户满意)以及B(用户需要)对E(价值感知)和F(用户满意)本身不相关。A(用户经验)与B(用户需要)是本文引入模型的新的隐变量, 属于探索性研究变量, 与其他因变量的关系并不明确, 因此在假设时采用全因果关系设定, 即A→ C、A→ D、A→ E、A→ F、B→ C、B→ D、B→ E和B→ F, 借由路径系数及检验来确定与其他因变量的关系。因此有可能其关系本身就是不明显的。
②A(用户经验)对C(用户预期)、E(价值感知)和F(用户满意)的关系是非线性的。用户经验是“ 专业积累” 与“ 消费经验” 的总和, 与用户预期、价值感知和用户满意的关系可能是非线性的。用户经验越丰富, 对产品或服务本身就越了解, 认识和定位就更准确、更理性; 相反, 如果用户经验不够丰富, 可能会对产品或服务抱有不切实际的预期(预期过高或过低), 进而影响“ 价值感知” 和“ 用户满意” , 因此用户经验与用户预期、价值感知和用户满意的关系可能是非线性的。
③B(用户需要)对E(价值感知)和F(用户满意)的关系是非线性的。当用户需要对产品或服务需要程度很高时, 可能对产品或服务的质量等方面要求也很高, 这时衡量标准也会提高, 产品或服务可能很难让用户达到很高的满意程度; 当用户需要对产品或服务需要程度一般时(觉得可有可无), 可能对产品或服务的质量等方面要求一般不会很高, 这时衡量标准也不会很高, 产品或服务比较容易让用户觉得满意; 而当用户需要对产品或服务需要程度不高时(可能是其他方面的原因促使了消费活动的发生), 根据“ 需要即价值” 判断, 用户对产品或服务的价值感知可能不高, 用户满意程度也不会很高。因此B(用户需要)对E(价值感知)和F(用户满意)的关系可能是非线性的。
(2)C(用户预期)对E(价值感知)和F(用户满意)的路径系数不显著。根据路径分析可知, C→ E的路径系数为-0.07, T-Statistics值为0.63; C→ F的路径系数为0.02, T-Statistics值为0.23。这两个路径系数均不显著。主要原因是:
①本模型采用“ 对内容的预期” 、“ 对服务的预期” 和“ 对功能的预期” 三个显变量来表征用户预期这个隐变量, 而这三个显变量主要都是“ 关于产品、服务特性的期望” 。而价值感知使用价值判断来度量产品或服务的表现, 与用户预期在内涵上具有一定的差异。
②C(用户预期)对F(用户满意)具有非线性关系。关于用户期望对用户满意的非线性关系具有理论上的支持, Kano等[24]认为需要的满足与顾客感觉到满意或者不满意之间不一定是线性关系, 并将需要归纳为三种类型:必备性质量、期望性质量和吸引性质量, 不同需要的满足度具有不同的影响。同时, 在CCSI模型(空调行业)的实证结果中, 用户预期对用户满意的直接影响为-0.004[ 25], 为负的不显著的直接影响。ACSI数据也表明, 用户预期对用户满意的影响也较小, 直接影响中最大的是公共事业/政府部门, 仅为0.09, 其他服务行业直接影响小于0.04, 金融/保险业甚至出现了负的不显著的直接影响。这均在一定程度上说明用户预期和用户满意之间的非线性关系。
(3)F(用户满意)对G(用户抱怨)的路径系数不显著。根据路径分析可知, F→ G的路径系数为0.18, T-Statistics值为0.91, 检验结果为不显著。因为用户满意与用户抱怨的关系不明确。ECSI和CCSI中均无此路径, 在一定程度上佐证了用户满意与用户抱怨的关系不明显。
(4)G(用户抱怨)对H(用户忠诚)的路径系数不显著。根据路径分析可知, G→ H的路径系数为-0.08, T-Statistics值为0.86, 检验结果为不显著。这可能是因为用户对产品或服务的可选择性较小, 即使抱怨程度较高, 仍然不得不选择使用该产品或服务, 例如学生受课程体系结构、考试或学习时间等因素限制, 只会选择使用本校的精品课程资源, 基本不会选择其他学校的同类课程, 所以即使对本校课程不满意, 仍然不得不选择继续使用本校的精品课程资源。
6 最终模型及其应用前景
根据上面验证分析, 得出最终模型如图2所示, 全部T- Statistic通过假设检验, 均表现为显著性。因此所构建的模型具有良好的解释能力和预测性。
利用“ 最终模型” , 得到隐变量联立方程和隐变量与显变量间的联立方程, 可以计算出国家精品课程网上资源用户满意指数、全部隐变量及显变量的指数和均数, 以及影响系数(重要性)等。这样可以对课程进行横向比较, 发现国家精品课程网上资源建设中存在的问题; 还可以进行教师用户与学生用户的纵向比较, 发现不同用户对课程资源的需求特点及关注的重点。
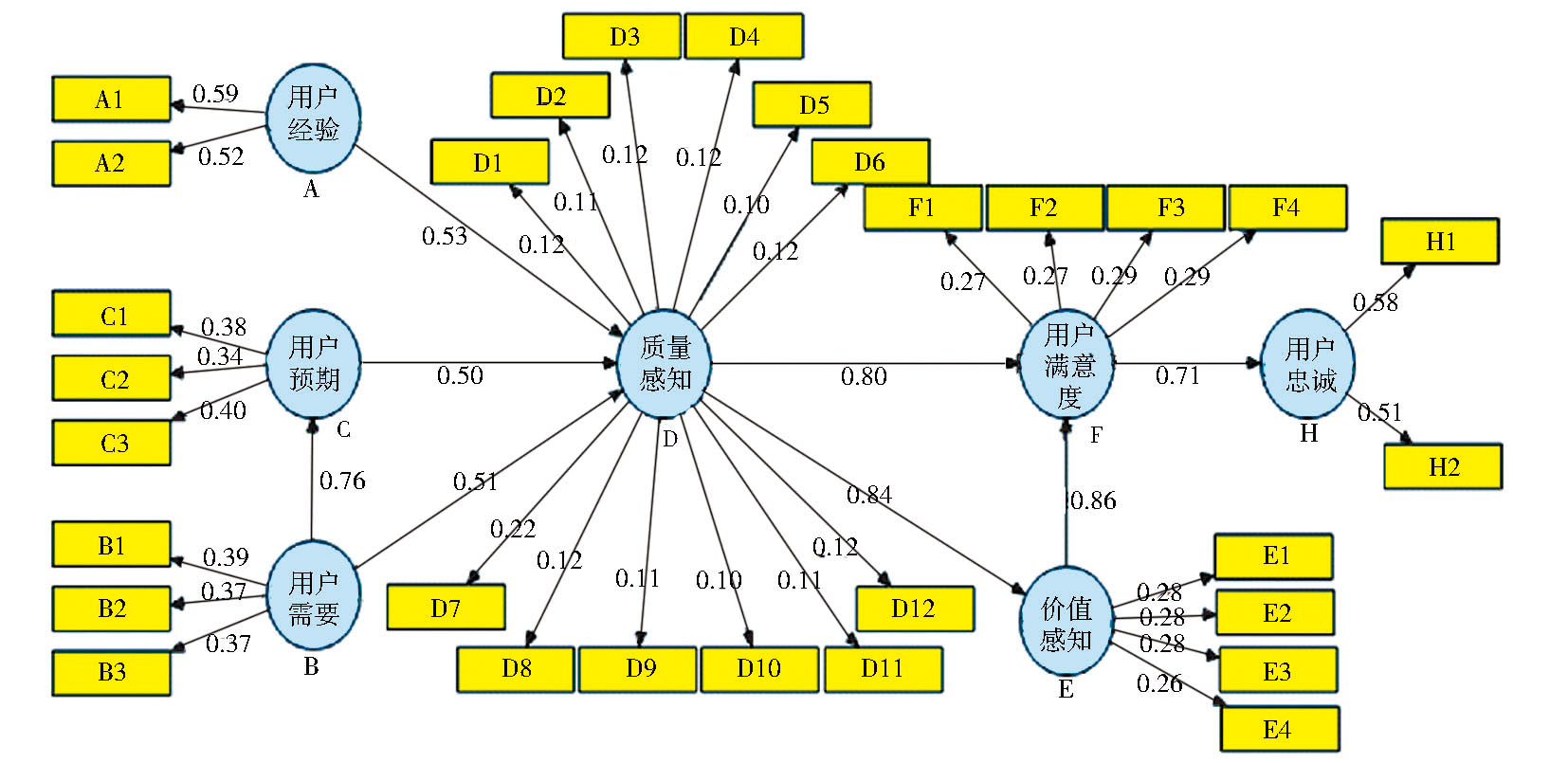 | 图2 国家精品课程网上资源用户满意度评价模型 |
(注:圆圈代表隐变量, 方框代表显变量, 隐变量之间为相关系数, 隐变量与显变量之间为权重。)
因此该模型具有广泛的应用前景, 可以比较分析国家精品课程网上资源的建设现状, 找出各自的优势和不足, 发现存在的问题和影响因素, 从而提高国家精品课程网上资源的建设水平, 促进我国国家精品课程建设良性健康有序的发展。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|