



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用查询重构识别查询意图*
引用本文
张晓娟, 陆伟. 利用查询重构识别查询意图*. 现代图书情报技术, 2013, 29(1): 8-14
Zhang Xiaojuan, Lu Wei. Identifying Query Intent by Exploiting Query Refinement. New Technology of Library and Information Service, 2013, 29(1): 8-14
Permissions
Zhang Xiaojuan, Lu Wei. Identifying Query Intent by Exploiting Query Refinement. New Technology of Library and Information Service, 2013, 29(1): 8-14
利用查询重构识别查询意图*
摘要
基于AOL查询日志数据集, 在不给定查询意图类目体系情况下, 尝试利用查询重构来识别用户查询意图。主要探讨如何识别出能表达原查询用户意图的查询重构以及如何对识别的查询意图进行聚类两个问题。人工评测结果表明, 该方法能够取得较好的实验效果。
关键词:
查询意图; 查询重构; 随机游走; 查询意图聚类
Identifying Query Intent by Exploiting Query Refinement
Abstract
Based on the AOL log dataset, this paper tries to exploit query reformation to identify the concrete query intent of users without given query intent category system. This paper mainly discusses how to identify the query reformation which can express the user intent of original query and how to cluster the query intent. The final results evaluated manually show that this experiment achieves a good effect.
Keyword:
Query intent; Query refinement; Random walk; Query intent clustering
1 引 言
因搜索引擎的搜索方式大多基于关键词组合, 而用户提交给搜索引擎的有限关键词常常不能完整地表达用户信息需求, 自动识别查询中所包含的用户意图对提高搜索引擎质量有重要意义, 其识别结果可用于搜索引擎中的网页排序、查询结果聚类和查询结果呈现等方面。鉴于此, 学界对查询意图识别进行了广泛探讨, 其研究主要分为给定类目体系的查询意图识别与不给定类目体系的查询意图识别两类, 前一类研究主要探讨如何将用户查询映射到某一意图类别, 而后一类研究主要探讨用户想要查找的具体内容, 如给定查询“ 汽车” 。前一类研究的查询意图识别结果可能是“ 信息类” 、“ 导航类” 、“ 事务类” 或其他类别, 而后一类研究的查询意图识别结果可能是“ 汽车修理” 、“ 汽车清洗” 或者“ 汽车广告” 等。因后一类研究能识别更具体的用户查询意图, 该研究逐渐成为查询意图识别领域探讨的重点, 而如何对查询意图识别结果进行聚类是此类研究的难点[1]。
在查询意图识别过程中, 因查询数据具有稀疏性, 一般无法直接通过原查询而需通过其他途径来探测用户查询意图。已有研究表明, 用户所从事的交互行为(如网页点击、用户反馈、重构查询等)能表达其意图, 用户交互行为信息是查询意图识别的主要途径, 且目前已有研究大多集中在如何通过用户点击和用户反馈行为信息来识别查询意图, 但对重构查询信息探讨甚少。Strohmaier等[2]研究发现, 用户向检索系统表达信息需求的主要方式是不断重构查询, 用户重构的相关查询是用户意图的直接表达, 则查询重构是识别查询意图另一重要途径[3]。
本文在不给定查询意图类目体系情况下, 利用查询重构来识别查询意图, 并对查询意图进行聚类。
2 相关研究
查询意图识别研究主要分为给定类目体系下的查询意图识别与不给定类目体系的查询意图识别两类。其中, 前一类研究的主体思想是:通过预先给定的分类体系, 选取分类特征、采用自动分类方法将用户查询意图映射到某一类别。其中, 陆伟等[4]对此类研究做了大量文献综述。该类方法的最大缺陷是无法获得用户想要查找的具体内容, 于是, 一些学者尝试在不给定类目体系情况下, 自动识别原查询的具体查询意图。而当前此类研究大都基于如下假设:用户在头脑中常常通过“ 动词+ 名词” 形式(如“ buy a car” , “ repair a car” )表达其意图, 于是, 扩展与名词相关动词成为后一类研究的主要方法。如Strohmaier等[5]根据查询中是否包含动词将查询分为显式意图查询和隐式意图查询, 并在此基础上, 通过对隐式查询扩展相应动词来识别查询包含的用户意图[6]; Duan等[1]利用verb-noun之间的依存关系来识别非导航类查询的具体意图; He等[7]利用查询返回的文档片段来获取与该查询相关动词来探测用户查询意图。综合已有相关研究, 此类方法虽能识别更加具体的用户查询意图, 由于动词之间存在近义词与同义词现象, 该方法识别出的结果常常存在概念上的交叉重叠现象, 如识别结果“ repair a car” 与“ mend a car” 都表达同一查询意图。但又因该方法一般借助相关反馈思想来扩展动词, 难以对最终的意图表达形式选取特征对其进行聚类。
关于查询意图识别的途径, 相关学者主要探讨了用户点击信息和用户反馈信息, 其相关研究主要体现在给定类目体系下的查询意图识别中。如Lee等[8]统计得到导航类查询的平均点击次数小于1.5, 信息类的则较大; Liu等[9]根据Sogou搜索引擎日志里查询的点击情况提出两个假设:在执行导航类检索时, 用户倾向于进行为数不多的点击, 这些被点击的结果往往是靠前的检索结果; Ashkan等[10]发现商业类查询的广告点击率较大, 如果查询为商业导航类点击热度更高; Mendoza等[11]发现用户花费在导航类查询上的时间比信息类少。总之, 目前几乎没有将查询重构行为信息应用到查询意图识别的相关研究, 而当前查询重构行为信息主要应用在查询推荐中, 如Shi等[12]提出了一种基于关联规则的模型来挖掘与原查询相关的查询重构, 以此生成候选查询; Jones等[13]利用根据查询重构与原查询共现信息, 利用互信息度量查询间相似性, 以此生成候选查询。
本文利用查询重构来表达用户查询意图, 将查询意图聚类问题转化为查询聚类问题, 则查询聚类是探讨的另一重要问题, 其中, 如何构建查询向量是研究重点, 已有相关研究有:Wen等[14]利用查询点击文档以及查询点击文档所包含的查询词为查询构建向量; Hosseini等[15]与Yi等[16]通过查询以及文档的点击信息来构建二分图, 从而对查询进行聚类, 在此基础上, Chan等[17]通过剔除噪声点击数据来对查询进行向量构建; Baeza-Yates等[18]通过为查询词加权以此来构建查询的向量, 其中查询词权值主要利用查询词在日志中出现频次以及该查询词所出现文档被点击的频次来衡量; Huang等[19]通过扩展查询内容以及选择URL对建立查询词与点击URL之间的语义关联为查询构建向量。以上方法适用于对较大数量查询选取特征构建向量, 而对较少数量查询聚类时存在局限性。
基于AOL查询日志, 在不给定分类体系情况下, 本文尝试一种新的途径, 即利用查询重构来识别原查询的具体用户意图, 并主要探讨了如何识别出能表达原查询用户意图的查询重构以及如何对识别出的查询意图进行聚类两个问题。其中, 在对用户查询意图进行聚类时, 为解决较少数量查询选取特征存在数据稀疏性问题, 利用随机游走遍历图思想为每个查询构建向量。需要说明的是:因用户重构查询行为信息主要体现在查询日志中同一Session的查询中, 在不考虑同一Session中查询出现的先后顺序情况下, 对查询q来说, 若某查询q′ 与其共现于同一Session中, 则q′ 称为查询q的查询重构, 并假设该查询可描述q的潜在查询意图; 另因同一查询相对不同用户会有不同意图, 本文所探讨的查询意图识别是指用户查询可能存在的潜在用户意图, 而非限定在某一特定用户可能的意图。
3 潜在查询意图识别
本文利用查询重构来表达潜在查询意图的前提假设为:同一Session中查询能表达相同的用户意图[20]。因所采用Session切分方法难免存在一定缺陷, 以及在同一Session中可能存在用户意图转移现象, 并非原查询的所有查询重构都能表达其潜在用户意图, 于是, 综合考虑从查询共现互信息与查询表达式相似性两个方面来识别能描述原查询潜在查询意图的查询重构。
3.1 查询共现互信息
考虑到某些查询重构与原查询共现是偶然现象, 假设当查询q与其查询重构q′ 共现次数大于其偶然共现次数, 则说明二者之间存在一定相关性, 且相关性越大, 则q′ 越有可能描述查询q的潜在查询意图。本文利用两查询之间在查询日志用户Session中互信息I(q, q′ )来确定查询之间的相关关系, 公式如下:

其中, Xq与Xq′ 分别表示某Session是否包含查询q或q′ 的二元值(0:没出现, 1:出现), P(Xq)表示包含或者不包含词q的Session数与总Session数的比值, 如P(Xq=1)表示包含查询q的Session数与总Session数的比值, P(Xq=0)表示不包含查询q的Session数与总Session数的比值。P(Xq′ )的意义与P(Xq)相同; P(Xq, Xq′ )表示查询q与q′ 在Session中的联合分布概率, 如P(Xq=1, Xq′ =1)表示同时包含查询q与q′ 的Session数占整个Session数的概率, P(Xq=0, Xq′ =1)表示不包含词q但包含词q′ 的Session所占的比例。I(q, q′ )值越大, 则表明两查询之间的相关性越大。
3.2 查询表达式相似性
基于如下事实:用户一般重构查询行为是在保持原查询某些词不变的情况下添加、删除与替换词来表达其潜在意图[2], 尽可能利用与原查询相似的查询表达式来表达其潜在意图, 因此, 本文假设若q′ 与q拥有相似词越多, 说明q′ 越能表达q的潜在意图。考虑到查询中某些词拼写错误以及词的前缀后缀现象会影响到这种相似性的计算, 综合利用文献[21]提出的计算字符串之间相似度的Di-gram Jaccard距离以及标准化编辑距离来计算两查询之间的相似性, 公式如下:

其中, min(ujac, ulevenstein)表示取ujac与ulevenstein二者之间较小值, ucontent值越大, 表明两查询之间的表达式相似性越大。
综合以上查询共现互信息与查询表达式相似性两方面因素, 利用pintent(q|q′ )衡量查询q′ 能表达查询q潜在意图的概率, 公式如下:
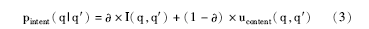
其中, I(q, q′ )表示两查询之间共现互信息,  表示两查询之间内容相似性; 表示权值, 本文将其设置为0.6。
表示两查询之间内容相似性; 表示权值, 本文将其设置为0.6。
4 查询意图聚类
不给定分类体系的查询意图识别结果虽能理解更加具体的查询意图, 但识别结果可能存在概念之间的交叉重叠现象, 如“ southwest airlines” 的潜在查询意图识别结果中, “ southwest airlines flights” 与“ southwest airlines schedules” 描述同一查询意图。因此, 对识别出的查询意图聚类显得尤为重要。本文将查询意图聚类问题转化为查询聚类问题, 而最终只对较少数量查询进行聚类, 数据存在稀疏性, 已有构建查询向量方法[14, 15, 16, 17, 18, 19]难以有效解决此问题。基于此, 本文通过查询以及查询所点击文档来构图, 利用随机游走模型[10]来遍历图以此为每个查询构建向量, 再对查询意图进行聚类。
4.1 转移概率设定
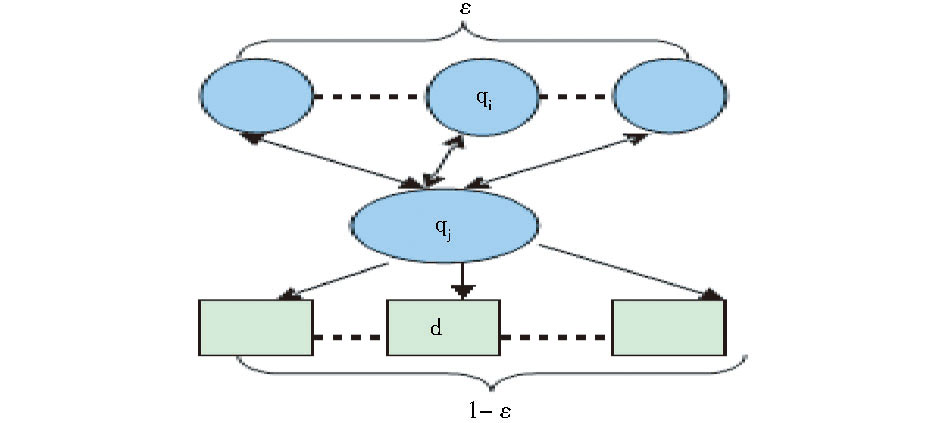 | 图1 查询状态与各状态转移情况 |
构图以及转移概率设定是随机游走模型中的关键部分。本文所构建的二元图G=(V, E) 中节点V由查询词及其所点击文档构成, E由查询与查询之间共现关系以及查询与文档之间的点击关系构成, 其中, 共现关系边权值为两查询共现Session数与总Session数的比值, 查询与某文档点击关系边权值为查询点击该文档次数与该查询所点击文档总数的比值。将每个节点当作一个马尔科夫状态, 其中, 图1表示查询状态与各状态之间的转移情况, 查询状态qj转移到自身概率为0, 以ε 的概率转移到文档状态, 而以1-ε 的概率转移到其他查询状态, ε 值的设定是为了在转移矩阵中查询节点qj链出的概率之和为1。从查询状态q转移到查询状态q′ 的概率计算公式如下:

其中, n(q, q′ )表示查询q与查询q′ 共同出现的频次, ∑ n(q, q″)表示所有与查询q共现的查询与q共现的频次之和。
在计算查询与文档之间转移概率时将URL加以区别对待, 若一个URL被多个查询点击, 则该URL具有模糊性, 反之, 若一个URL总是被一个特定查询点击, 表明该URL具有专指性。设定某查询转移到专指性URL的权值大于该查询转移到模糊类URL的权值。利用文献[22]提出的iqf衡量URL的权值, 其思想与文档的idf思想相似, 公式如下:
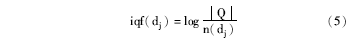
其中, n(dj)表示点击文档dj的查询频次之和, |Q|表示查询日志中总查询数。

其中, cfiqf[22]表示点击频次与iqf的乘积, cij表示查询qi点击文档dj的次数。则查询与文档之间的转移概率如下所示:
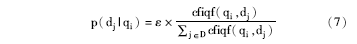
其中, ∑ j∈ Dcfiqf(qi, dj)表示查询qi所点击文档的cfiqf权值之和。
公式(8)表示文档状态是一个吸收状态(即自转移状态), 即转移到自身的概率为1, 而转移到查询状态的概率为0。根据马尔科夫吸收链的性质:当状态转移到文档状态后, 则会一直停留在此状态; 从每一个非吸收状态出发, 有限次转移后能以正的概率到达某个吸收状态。
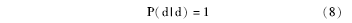
4.2 查询向量构建与聚类
基于如下假设:用户所点击文档能描述用户信息需求, 则点击同一文档的两查询具有相似查询意图[19], 根据每个查询所点击文档分布来构建查询向量。为了解决数据稀疏问题, 本文为查询构建向量的特点是不只是考虑某查询点击的文档, 而是查询到文档的整个路径, 即经过随机游走该查询可能到达的文档状态。查询状态与各状态转移情况见图1。
以图2为例, 图中节点由查询q1、q2、q3、q4、q5, 以及这些查询所点击的文档d1、d2、d3、d4、d5、d6构成, 其中, 图中查询与点击文档的实线边表示点击关系, 而虚线边表示经过随机游走后, 查询能到达该文档状态。由图2可知, 经过随机游走后, q1与q2最终到达文档状态相似, q3、q4、q5可到达的文档状态相似。根据每个查询所到达文档状态相似性对其进行聚类, 则对图2中查询进行聚类最终需达到的效果为:q1与q2属于同一类簇, q3、q4、q5属于同一类簇。本文利用KL距离[22]来计算两查询向量之间的相似性, 并采用Complete-link[22]来对查询向量进行聚类, 其中, 所需聚成的目标类簇数k是其探讨重点。
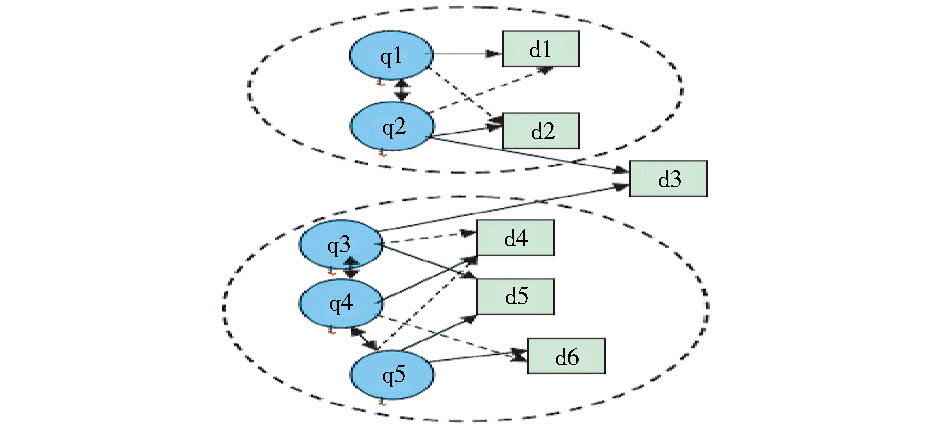 | 图2 随机游走后的查询聚类效果示例 |
5 实验及其结果分析
5.1 数据集
采用AOL[23]查询日志作为数据集, 其时间跨度为2006年3月1日到5月31日, 其格式如图3所示:
 | 图3 AOL数据集格式 |
从左到右分别表示用户ID、查询表达式、用户点击时间、被点击URL在结果列表中排序、点击的URL地址。原始数据集中包含许多噪音, 本实验首先对其进行清理:如剔除包含色情词查询、只包含单个字符的查询等。笔者通过“ 15分钟划分法” [24]识别Session边界。
笔者从查询日志中随机选取50个出现频次大于600且包含不多于4个查询词的非导航类查询作为用于识别用户查询意图的原查询。其中, 在进行查询聚类时, 首先获得每个原查询潜在意图识别中排名前20的查询重构, 再获得每个查询重构在查询日志中所点击的文档, 以此来构建每个查询重构的向量。其中, 随机游走中参数ε 决定了查询状态转移到文档状态的概率, 本实验中用于聚类的查询较少, 实验结果表明, 参数ε 的改变对实验效果影响不大, 如当ε =0.2时, 经过10步随机游走后大约90%达到了吸收状态; 当ε =0.8时, 经过3步约90%达到了吸收状态; 同时实验表明, ε 取值在[0.5, 0.7], 随机游走步数n设置在[3, 6]之间, 实验效果更佳。于是, 将ε 的值设定为0.6, n值设定为5。
5.2 实验结果评测
笔者选取三名专家对实验结果进行评测, 考虑到本实验主要由潜在意图识别和查询意图聚类两步完成, 定义以下三个指标来对每个原查询的识别结果与聚类结果进行评测:.
(1)准确度(Precision):能描述原查询意图的查询个数与该原查询识别结果的总查询数之比;
(2)内聚合度(Cohesion):能表达同一查询意图的类簇个数与原查询聚类结果的总类簇之比;
(3)覆盖度(Coverage):将识别结果中与类簇中查询相关的所有查询都包含在内的类簇数与该原查询聚类结果的总类簇数之比。
准确度指标用于评价第一步实验结果, 则将潜在查询意图识别出的每个查询作为评测对象; 而内聚合度、覆盖度指标用于评价查询意图聚类效果, 将聚类后的每个类簇作为评测对象。
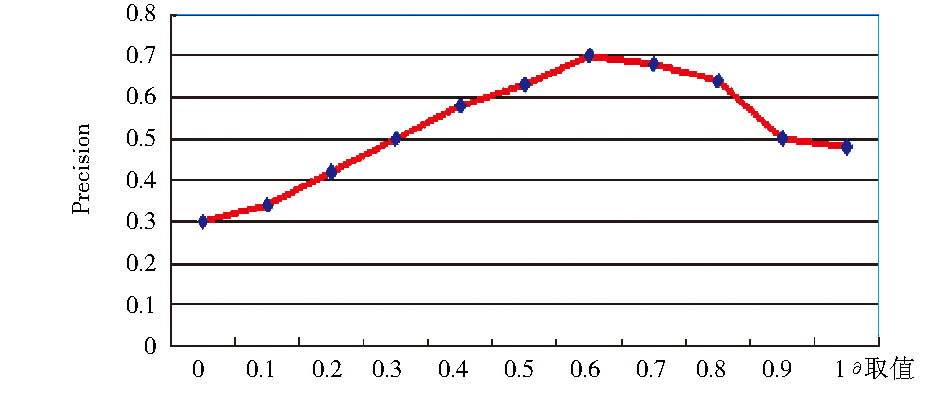 | 图4 值对Precision值的影响 |
其中, 一些参数值会影响到实验效果。如Precision值主要体现公式(3)从查询重构中识别潜在查询意图效果, 则值对Precision有一定影响作用。图4表示从0调节到1.0之间, 每次调节步长0.1而得到不同取值对实验Precision的影响, 其中, X轴表示的取值, 而Y轴表示Precision值, 其计算方法为:首先计算出每位专家的50个原查询的Precision平均值, 再对三位专家的Precision平均值再取均值, 可以看出, 在[0, 0.6]范围, 随着值的增加Precision值也不断增加, 在[0.6, 1.0]范围, Precision值随着的增加而减少, 在本实验中的最优值是0.6。
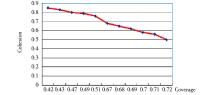
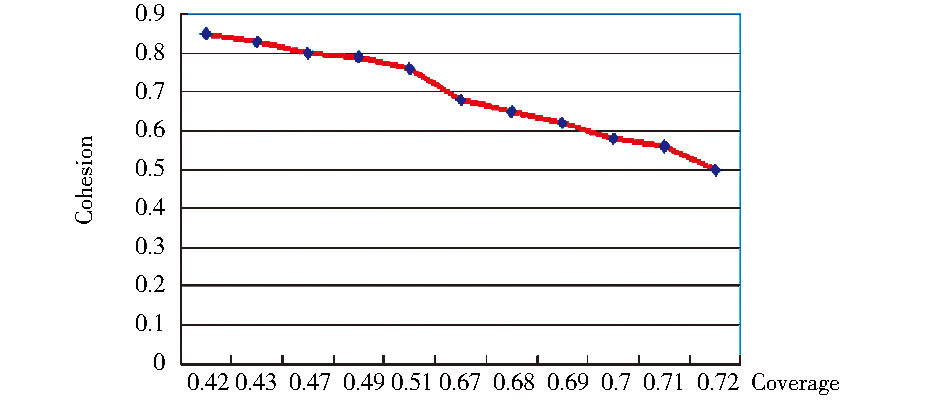 | 图5 k取不同值时其相应的Coverage与Cohesion值 |
图5表示目标类簇数k取不同值时对查询聚类效果的影响。其中, X轴表示Coverage取值, Y轴表示Cohesion取值, 二者计算方法与Precision值类似。其中, 曲线上的11个点从左到右分别表示类簇数取值从15以差值1递减到5过程中Coverage与Cohesion的取值情况。可以看出, 随着类簇数不断减少, Cohesion值不断减少, 而Coverage值不断增加。经综合对比, 当类簇数取值为10时, 该实验的Cohesion值与Coverage取得最优解。
当取值为0.6, k取值为10时, 三位专家针对以上三个指标对50个查询的评测结果, 如表1所示:
| 表1 三位专家的评测结果 |
可以看出, 三位专家的平均准确度、平均聚合度与平均覆盖度分别为0.70、0.67与0.68, 说明实验返回的20个查询中约7个与原查询的意图相关, 且聚类结果的10个类簇中约7个类簇能表达同一查询意图, 约7个类簇能包含与该类簇查询相关的所有查询, 以上数据说明本实验取得了较好的效果。
另外, 利用Cohen kappa(δ )[ 25]来获取评测者两两之间同意对方评测结果的概率, 公式如下:
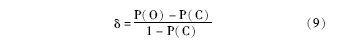
| 表2 三位专家两两之间的Cohen kappa(δ )值 |
当а值设置为0.6, 类簇数值设置为10时, 从50个原查询中随机选取两查询的最终实验结果示例如表3, 表4所示, 其中, 从表3的类簇C1与C2中可知, 用户分别想获得有关“ southwest airline” 的航班与工作信息; 另从表4的类簇C1与C2中可以得知, 用户想分别获得“ myspace layouts” 相关的颜色背景与设计者信息。
| 表3 查询“ southwest airlines” 的最终实验结果 |
| 表4 查询“ myspace layouts” 的最终实验结果 |
6 结 语
本文基于AOL查询日志, 利用查询共现互信息、查询内容相似性来识别潜在查询意图; 并通过查询与查询以及查询与文档之间关系来构图, 再对该图进行随机游走遍历, 以此来为每个查询构建向量, 最后对查询意图进行聚类, 并取得了较好的实验效果。但该实验仍存在一些不足之处, 也是笔者在以后工作中需深入研究的几个方面:
(1)同一Session中, 出现在某查询前一时间段或后一时间段的查询对表达该查询用户意图的不同作用;
(2)后续工作将利用众包思想来对结果进行评测;
(3)将识别结果应用到搜索引擎优化中, 如查询推荐与检索排序中。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|