{kind=link}
{kind=link}
科研本体知识库数据建设研究*
[李建伟1  , 宋文
, 宋文1 , 汤怡洁2 , 刘毅2 , 王兴兰1 ]
, 宋文|
|


为将国内外科研领域重要资源进行统一规范和有机组织,搭建基于科研本体的知识库, 其建设目标是实现各类资源的采集、规范、组织、保存和展示,以支持知识发现。设计数据采集、数据规范和数据集成的方法及相关工具,通过数据建设实践进行验证,形成初具规模的科学家网络。最后,对该方法在知识库可持续建设方面的应用做出展望。
In order to specify and organize major resources in domestic and foreign research areas, the authors build the knowledge base based on scientific research Ontology. The purpose is to accomplish resources’collection, specification, organization, preservation and showing to support knowledge discovery. This paper develops the methods and related tools for data collection, data specification, and data integration, and then tests the effect by the practice of construction data, forming a certain scale of scientist network.At last, the perspectives of these methods are discussed about the sustainable building for knowledge base.
目前,国内外科研领域比较成熟的知识库可概括为两类:机构本体知识库和基于某学科领域本体的知识库。前者一般以科研机构作为构建主体和界限,后者以某一具体学科领域为主体和边界,两者都只支持各自主体范围内的资源管理[ 1]。本文研究的科研本体知识库则是综合上述两类知识库的特点,面向多学科多机构,以科研本体作为知识组织体系,通过本体概念间的各种关系,建立数据间的语义关系,形成一个立体网状的知识库,从而揭示和反映各学科领域科研活动主体和科研对象之间的联系[ 2]。该科研本体知识库是利用康奈尔大学2012年开发的VIVO1.5.1系统所搭建[ 3],其建设内容可分为两部分:科研本体建设和数据建设。本文主要论述该科研本体知识库数据建设的方法和相关工具,并通过数据建设实践进行验证。
科研本体知识库使用VIVO系统自带的本体编辑器——Vitro来实现科研本体的创建与修改、类和属性的添加。Vitro是一个开源知识建模工具,具有与Protégé基本相同的本体编辑和可视化功能,同时Vitro还提供了基于本体的系统架构功能,能够快速搭建知识库系统。科研本体建设的原则是:尽量重用VIVO本体,从中选择相关类和属性,保持原有定义和URI;同时建设具有新命名空间的当地本体(Local Ontology)。VIVO1.5.1的本体由核心本体(VIVO Core[ 4])和一些大众本体(BIBO、ERO、FOAF、FAO等)[ 5, 6]构成。由于VIVO本体结构是以欧美教育体系为原型,因此当地本体主要依据中国科学院专业领域知识环境[ 7]的本体来补充国内科研系统类目,从而形成一个涵盖国内外科研体系的科研本体。
科研本体知识库数据建设流程如图1所示:
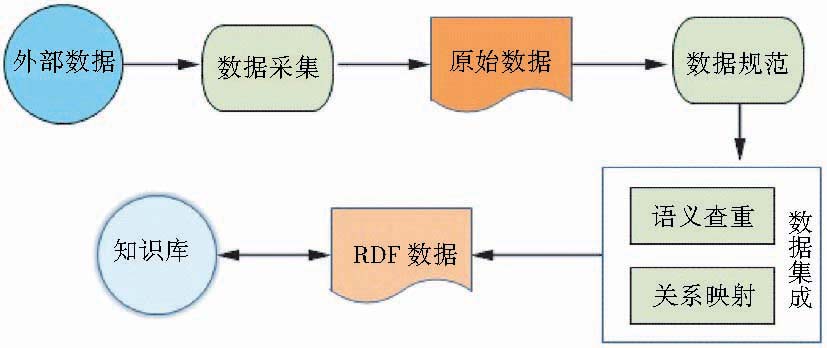 | 图1 数据建设流程 |
首先遴选不同来源的外部数据,采集得到结构化的原始数据,然后对原始数据进行数据规范和数据集成,最终转换为RDF数据导入科研本体知识库系统,提供检索和查询[ 8]。
由于不同来源数据的属性定义与规范格式互不相同,而同一数据在不同来源中的表现形式也可能不一致,因此需要将采集到的原始数据按照一定的标准进行规范统一和查重处理,并与科研本体知识库所对应的类和属性进行映射匹配。如何对数据进行规范、语义查重和关系映射将直接影响数据的关联效果[ 9],是知识库系统数据建设的关键。通过分析不同来源原始数据特征以及科研本体结构,本文设计了语义查重规则与数据规范方案,以保证知识库系统的数据质量。另外,针对数据采集、格式转换和数据导入设计开发了数据定向采集工具和数据集成工具,工具与系统之间利用标准接口相互调用,从而完成数据从采集、规范到集成等操作。
科研本体知识库所要建设的数据类型主要有6类,分别为:人员、机构、项目、学术活动、论文和专利。由于各类数据集成到知识库中,最终要形成相互关联的科研信息网络,因此数据采集工作不能彼此孤立进行。数据采集策略是:遴选机构、项目和学术活动数据进行采集;依据这些数据遴选人员数据进行采集;根据人员和机构数据检索论文和专利进行采集。具体采集顺序如下:
(1)遴选机构:人工采集并规范机构名称及上下级关系,利用数据集成工具将机构数据导入知识库。
(2)遴选人员:通过数据定向采集工具分批采集人员信息,进行规范后利用数据集成工具将人员数据导入知识库;同时,人员信息中涉及到的论文、项目、会议、书籍、专利等相关数据也进行采集,规范后逐批导入知识库。
(3)遴选科研项目:通过数据定向采集工具批量采集项目信息,规范出资助、项目等类型数据,利用数据集成工具逐批导入知识库;同时,科研项目所涉及的人员和机构信息也进行采集,规范后逐批导入知识库,导入时与知识库中已有人员、机构数据相查重。
(4)遴选学术会议:通过数据定向采集工具批量采集学术会议信息,规范出会议、系列会议和会议录等类型数据,利用数据集成工具逐批导入知识库;同时,学术会议所涉及的人员和机构信息也进行采集,规范后逐批导入知识库,导入时与知识库中已有人员、机构数据相查重。
(5)根据知识库中的人员和机构数据,利用数据定向采集工具访问SCI、NSTL和DII等数据库检索、采集论文和专利数据,规范后逐批导入知识库,导入时与知识库中已有论文、专利数据相查重。
科研本体知识库的数据来源有两方面:国内外知名大学、知名科研机构、知名资助机构的官方网站;国内外比较权威的数据库。目前,国内外比较权威的大学排名有:ARWU[ 10]、THE-QS[ 11]、USNWR[ 12]、CHE[ 13]等。这些排名均使用一些主客观指标以及来自大学或公共部门的数据,对大学的学科领域、学科或专业按各自之间的相对水平进行“质量评定”[ 14]。其中,ARWU作为首个多指标全球性大学排名,其评价体系客观、透明,在世界范围得到广泛报道和引用。
根据ARWU 2012年发布的学术500强大学名单,结合NSTL文献库中的机构,笔者遴选了国内外排名靠前的二百多所综合性大学,以及若干家国内外知名研究所、实验室。其中,国外大学主要选择美国、英国、澳大利亚等英语国家,国内大学主要选择“985”和“211”高校。机构数据的颗粒度一般细分到院和系,综合性大学中的课题组、实验室、研究中心、研究所,以及其他机构(公司、协会等),根据理、工、农、医各学科领域内的重要程度和排名进行选择。人员数据主要从所遴选的机构中,选择高校教师和科研人员两大系列,职称类型包括:研究员、副研究员、助教、讲师、副教授、教授等。利用人员和机构,通过SCI和DII数据库,检索得到2007年-2012年间的高被引论文和专利。
科研项目数据从NSF[ 15]、EU[ 16]、NSFC[ 17]以及科技部等资助机构网站,根据资助额、参与机构、重要程度来遴选。学术活动主要从NSTL文献库遴选理、工、农、医各学科领域2011年-2012年间有影响力的学术会议、学术报告、研讨会等。同时,从科研项目与学术活动中遴选所涉及的主要负责人和承担机构。
经分析,除机构和部分人员数据分布比较零散、需要人工采集外,其余各类数据都可批量采集。为了提高数据采集效率,基于网络爬虫原理开发了数据定向采集工具[ 18],利用网络爬行器获取各个页面的链接地址,再通过页面分析器解析页面采集数据。工具采用多线程触发形式,利用HttpClient进行解析处理。数据定向采集工具主要功能包括:采集源管理、采集参数配置、数据采集控制、数据后期处理。为了保证数据的完整性,各个采集源的数据属性都需要进行采集,采集源属性与知识库系统的规范属性如何匹配详见3.1节数据规范方案。
采集源管理和采集参数配置有两种配置模式:一种模式支持人工配置,需要人工确定采集数据的信息源,通过网页源代码获取各个采集信息点参数进行配置操作,主要用于人员、机构、项目和会议等信息的采集;另一种模式是针对固定信息源的自动化配置,用于论文和专利数据的定向采集。其工作过程如下:通过程序获取知识库系统的人员、机构信息作为检索词,再利用Web Browser控件自动模拟用户登录目标网站输入检索信息并返回相关采集源链接地址,根据预设好的采集信息点配置信息自动生成对应的采集配置文件;工具自动从配置好的数据源收割相关数据,通过网络页面分析方式获取数据,并将采集的数据进行后期处理,清洗数据中的网页符号等无用字符,最终将数据存储在Excel文件中。
为了将不同来源数据的类和属性准确映射到科研本体知识库中的类和属性,分别制定了人员、机构、项目、学术活动、论文以及专利等数据的规范方案。规范方案中将数据属性划分为:类名、实例名称、下级分类、数值属性和对象属性。将各类规范方案整合在一起,如表1所示,其中下级分类、数值属性和对象属性都只列出了部分信息。
| 表1 数据规范整合表 |
类名的规范分两种情况:人员和论文类,由于分类较少,规范为具体导入类的“本体_类名”;机构、会议和项目类,考虑到分类比较多,规范为具体导入类的“本体_上级类名”。
实例名称的标签为“Lable”,其内容为各实例在系统中的显示名称。在机构、会议和项目类的数据模板中添加“下级分类”属性,对应标签为“domainClass_C”,具体为每行中分类处的值,格式为“本体:类名”。
数值属性以“localname_D”形式作为标签,数值属性规范为普通文本格式。对象属性以“localname_O”形式作为标签,由于对象属性是生成一条新的记录,有的自身又有属性划分,需要按照规范格式来填写,如表2所示:
| 表2 部分对象属性的规范格式 |
以清华大学人员采集为例,采集源的人员属性和知识库系统中人员规范属性主要对应关系如表3所示,有的属性需要从源属性中拆分,如姓,名等,这里未做列举。
| 表3 采集源属性与规范属性对应表 |
知识库系统中的语义操作利用语义化框架Jena API实现,通过Jena SDB进行数据库持久化存储[ 19]。根据Jena API的特性,对于重复数据(即重复实例)在导入系统时进行合并处理,以保证知识库中实例的唯一性和完整性,具体方法如下:
(1)实例重复时,将知识库中实例URI赋予待集成数据的唯一标识符URI。
(2)相同实例的数值属性:判断为重复时,抛弃待导入数据中的该属性,仅沿用知识库中的实例属性;判断为不重复时,为知识库中的实例新增一个相关数值属性的属性值。
(3)相同实例的对象属性:判断为重复时,将知识库中对象属性生成的实例URI赋予待集成数据的属性值;判断为不重复时,为待集成数据的属性生成新的实例URI。
由于人员一般是各类科研活动的主体,因此制定了以人员为核心的数据查重规则:若待导入数据中的人名与知识库中的人名相同,并且两者所属的机构名称也相同时,则认为是相同的人。
涉及人名的属性字段主要有:姓、名、中间名。人名比较就是将待导入人员数据和系统中已有的人员实例中的上述字段进行比较,判定规则为:
(1)如果“姓”、“名”和“中间名”全部相同,则认为人名相同;
(2)如果其中一个缺失中间名,但“姓”、“名” 相同,则认为人名相同;
(3)如果“中间名”一个为首字母缩写,一个为全拼,那么选取首字母进行匹配,如果相同,则认为“中间名”相同。
涉及机构名称的属性字段有:Lable、中文名称、英文名称、简称和其他名称。机构名称比较就是待导入数据中人员所属机构,与系统中对应人员的机构就上述字段进行比较,如果其中一个匹配,则认为是同一机构。比较判定时,机构名称进行如下压缩处理:剔除首冠词the,a,an;剔除名称中的标点符号。另外机构名称中出现的and和&认为相同。
导入科研项目、学术会议、论文等数据时,实例名也按照类似方法来进行数据查重。另外,项目、论文和专利数据里经常包含人员信息,例如项目负责人、论文作者等。由于这些数据中的人名一般只以一个属性字段,甚至简称的方式呈现,需要先切分人员的“姓、名、中间名”,然后与系统中人员实例的对应属性字段进行比较,此时除上文提到的判定规则外,如果“姓”相同,知识库中的人员实例“名”为全称,论文中的人员“名”为首字母缩写,也认为人名相同。
各类数据在遴选采集时都是按顺序依次进行的,同一个机构出现同名人的情况很少,为了保证数据质量,这种情况由人工判断处理。另外,在数据规范阶段,项目、机构和会议等名称都是按其官方标准名称来做规范,排除了名称误判的可能。
根据数据规范方案和语义查重规则进行数据集成实践,具体过程如下:根据数据规范方案制作各类数据的Excel表格模板,人工将不同分类的原始数据按各模板所要求的格式规范到Excel中;利用专门开发的数据集成工具与科研本体知识库系统挂接,将规范数据进行语义查重、关系映射和标准化转换,最后得到标准RDF数据并将其导入知识库系统。
数据集成工具的主要功能包括:数据验证、数据查重、数据转换以及RDF数据导入与导出,其工作过程如图2所示:
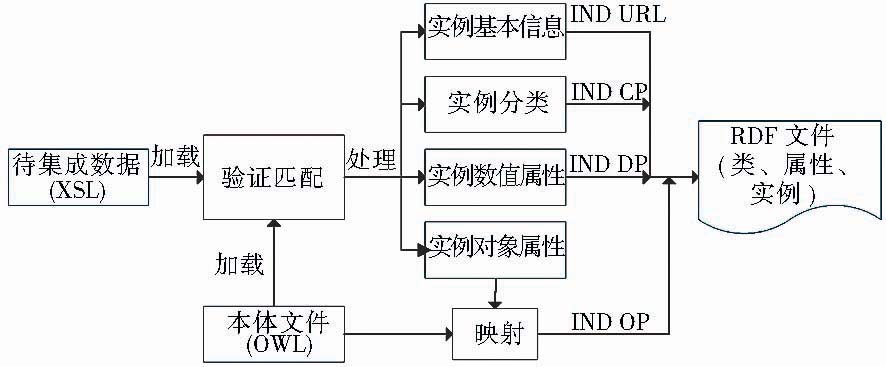 | 图2 数据转换过程 |
加载Excel数据文件和本体文件OWL后,通过验证匹配模块先将数据划分为4部分进行处理:根据“实例基本信息”创建实例,利用本体模板中的命名空间自动生成实例URI,并将该实例归属到某本体类中;根据“实例分类”将实例所属类别归入对应的本体上级类中;根据“实例数值属性”相关的属性值以字符串的形式写入对应的数值属性中;根据“实例对象属性”将相关的属性值以实例的形式写入对应的对象属性中。对象属性关系比较复杂,将单独通过属性映射模块进行处理。最后4类信息共同生成包含类、属性和实例的RDF文件。
在数据处理过程中,为将待集成数据与知识库中已有数据进行查重,利用SPARQL Endpoint将待集成数据作为查询条件,结合语义查重规则对知识库中的实例进行查询,根据返回结果判断是否有重复。由于知识库系统还未提供对外开放的SPARQL查询终端,目前选用Joseki软件[ 20]作为外接的SPARQL Endpoint与系统挂接实现查重。
RDF文件导入、导出知识库系统有两种实现方式:利用集成工具直接调用数据库进行操作,所有导入、导出程序都在集成工具中实现,这种方式需要通过知识库系统接口,获取数据库链接和账号密码;利用知识库系统的Add/Remove RDF Data功能,通过系统接口,将集成工具构建好的本体模型传递到知识库系统中,利用知识库系统的存储单元写入数据库。集成工具的接口封装和知识库系统的接口调用利用Apache Axis实现[ 21]。数据导出主要是为采集论文和专利数据服务,利用定向采集工具采集论文和专利用到的检索词,就是由系统导出的人员和机构信息组成。另外,如果需要删除某批量导入的数据,可以通过导出功能将数据移除。
关系映射的目的是将待集成数据所涉及的属性关系按照知识库系统中的本体规则进行分类处理。在数据集成工具中,通过数据与科研本体之间的XML映射文件进行关系映射描述。数据转换时,自动调用XML映射文件获取属性关系,并根据不同分类进行处理,生成对应的实例和相关属性的属性值。当属性关系发生改变时,如新增属性、修改属性值域、删除属性等,只需在对应的映射文件中进行新增、修改、删除相关属性操作,即可保证工具处理的正确性。
在属性映射模块中根据对象属性名称进入本体文件进行匹配,利用Jena将OWL文件构建本体模型,从本体模型中获取对象属性的定义域和值域对应的类。读取定义域类名与数据类名标签进行比对,确保对象属性关联的正确性。然后在待集成数据中获取该对象属性的值,在值域类中生成对应的实例,同时将该实例的URI与原始实例利用对象属性进行关联,确保知识之间的关联完整性。
对象属性关联映射模块中包括两种特殊情况:
(1)对象属性中同时包含多个属性值或自身又有属性划分的(如项目贡献者有主要负责人和合作负责人),根据数据规范方案利用特殊符号进行属性值区分,分隔存储在哈希表中,通过解析哈希表依次在值域类中生成对应的实例,并分别利用URI进行关联;
(2)多层级关联的对象属性映射(如论文拥有作者、作者归属机构),需要筛选出所有多级关联的对象属性,根据循环递归算法将对象属性的定义域与直接关联的对象属性值域进行匹配,生成新实例并利用URI进行关联。
目前,科研本体知识库系统的数据建设经历了从遴选、采集、规范、查重到集成的整个过程,系统中已集成各类数据达8 000多条,可以支持浏览和检索。这些数据之间相互关联,能够有效生成人物关系网络和科学图谱[ 22]。同时,科研本体知识库还具备规范文档的作用,支持NSTL文献服务系统对各种学术对象的识别。当然,在数据建设过程中,也发现了一些问题,例如语义查重规则可能有个别不能涵盖的情况,还需要继续分析补充。另外,针对知识库系统数据的可持续建设、管理与维护,继续丰富当地本体的类和属性,改进集成工具,将是今后的研究重点。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|