


{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于CMeSH语义系统的领域自由词-主题词语义映射研究*
[孙海霞 , 李军莲
, 李军莲
, 李军莲|
|


基于CMeSH的语义关系和生物医学词汇字长特点,设计文献自由词到CMeSH主题词语义自动映射方案,包括文献自由词与CMeSH主题词的语义相似度计算模型和“最佳”目标主题词识别方案,并以疾病类和微生物类词汇为例进行实验效果分析。
Based on semantic relationship of CMeSH and characteristics of biomedical vocabulary words, a semantic auto-mapping from literature keyword to subject headings is presented, including semantic similarity calculation model between literature keyword and subject headings of CMeSH, and thebest subject heading identification scheme. Experimental results of disease and microbes vocabulary are analyzed.
自由词与主题词之间的对应关系是表达同一概念的自然语言词与人工语言词之间的关系,从信息检索角度来看,两者是一种等同关系,只是在自然语言中,一个概念可以用多个词(或词组)来表达;而在一种人工语言中,一个概念却只能用一个词(或词组)来表达[ 1]。因此,情报领域学者们主要通过同义词自动识别思想来实现自由词到主题词对应转换。常用的方法有:基于词汇相似度的方法、基于词汇共现的方法、基于规则的方法、基于信息检索的方法和基于链接分析的方法[ 1, 2, 3, 4, 5, 6]。其中,基于词汇的方法包括基于字面相似度的方法和基于语义词典或词汇体系语义的方法[ 7, 8, 9, 10, 11, 12, 13]。基于语义词典或词汇体系的方法,从相似度计算所采用的语义信息角度又可以分为基于字面(语素)的方法、基于词素的方法、基于释义的方法和基于路径长度的方法。本文从信息检索和文献标引角度出发,立足中文医学主题词表CMeSH体系结构,综合考虑词汇集合相似度计算和后续“最佳”目标主题词获取规则设计,提出了医学领域自由词-主题词语义映射方案,并进行了实现。
《中文医学主题词表》(CMeSH)[ 14]由中国医学科学院医学信息研究所编制,包括《医学主题词表》(MeSH)中文版和《中国中医药学主题词表》两部分。其中MeSH[ 15]由美国国立医学图书馆编制,是目前国际上最具代表性、使用最为广泛的受控医学叙词表。《中国中医药学主题词表》与MeSH具有相同的编排体例,是国内外第一部在医学及中医药学信息领域广泛采用的中医药学专业叙词表。与所有受控叙词表一样,CMeSH对其收录的所有主题词不仅进行了严格的词义规范、词类规范和词形规范,还通过清晰的树状结构及简明的参照系统来揭示主题词之间的语义关系,从知识体系的角度、以人工方式为医学及相关领域主题概念建立了较为丰富的概念空间。
目前CMeSH中主题词主要包括内容主题词、出版类型词、特征词、地理主题词。每一个主题词下设该主题词的英文主题词、树状结构编码(Tree Number)、主题范围(Scope Note)、入口词(Entry Term)、创建年代、历史注释及各种参照系统等来揭示主题词的历史变迁、族性类别及同其他同义词、近义词之间的逻辑关系。主题词“肺炎,细菌性”的详细描述片段[ 16]和所在属分树[ 17]分别如图1和图2所示:
 | 图1 主题词“肺炎,细菌性”描述示例 |
 | 图2 CMeSH树状结构示例 |
在CMeSH中,一个主题词可以对应多个入口词,但一个入口词只能对应一个主题词。此外,一般来讲,在后控词表中,相邻等级的主题词中,字长较长主题词表达的概念更为专指。基于上述条件和假设,本文提出了基于CMeSH的领域自由词到主题词语义自动映射技术方案,如图3所示:
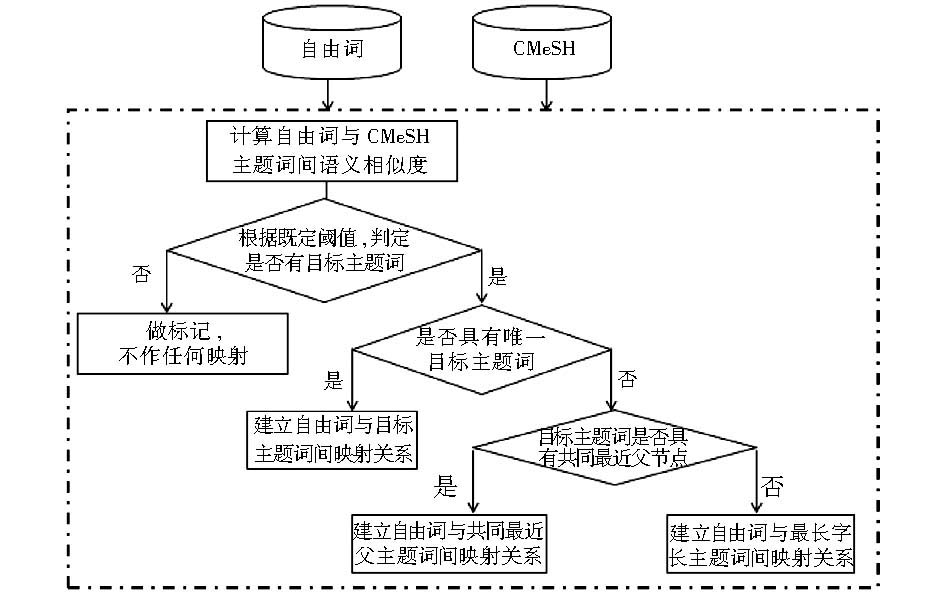 | 图3 基于CMeSH的自由词-主题词自动映射技术方案 |
该方案主要包含如下两个主要步骤:
(1)计算自由词与CMeSH主题词语义相似度(详见第4节),获取目标主题词集合,假设为T。
(2)从目标主题集合T中获取“最佳”目标主题词。如果T中只有一个主题词A,则建立自由词与A间的映射关系,即将自由词作为A的入口词。如果T中有多个主题词(A,B,…),则按如下方案获取“最佳”目标主题词:
方案一:直接取字长最长的主题词作为目标主题词。主要基于以下考虑:一般来讲,字长越长,所能表达的概念越明确;在生物医学领域,领域新词主要集中体现为复合词和衍生词。方案二中的相关设置也基于此。
方案二:考虑主题词的层级语义系统,具体提取原则如下:
①如有共同上位主题词,则取最近的共同上位主题词。
②如果最近的共同上位主题词有多个:
1)比较路径,取路径较长者。在CMeSH中,距离根节点越远,主题词所表达的主题概念就越明确,因而更能够满足精确检索和主题标引的需求。
2)如果路径长相同,优先选择最长字符串者。
3)如果路径长相同,字长也相同,随机取值。
③如果没有共同上位主题词,最长字符串主题词优先匹配。
词语相似度是反映两个词语之间的相似紧密程度或可替换程度[ 18]。在不同应用领域,词语相似度有不同的实际意义。在信息检索领域,词语相似度一般是反映文本与用户查询在意义上的符合程度[ 18]。
词语相似度计算研究的是用什么样的方法来计算或比较两个词语之间的相似性或相似程度[ 19],一般可分为字面相似度计算和语义相似度计算。字面相似度计算是建立在词项本身的基础上,以词形为切入点,将被比较对象看作是字符序列,两个字符串间相同的字符越多,相似度值就越大,从而对象间的相似程度就越大[ 20]。语义相似度则还考虑被比较对象的语义层面信息[ 7, 8, 10, 13]。
自由词与主题词之间的对应关系是表达同一概念的自然语言词与人工语言词之间的关系,从信息检索角度来看,两者是一种等同关系,只是在自然语言中,一个概念可以用多个词(或词组)来表达;而在一种人工语言中,一个概念却只能用一个词(或词组)来表达[ 1]。因此,在实现自由词向后控词表主题词或叙词的映射过程,仅考虑自由词与主题词本身的字面相似度远不够,应综合考虑如主题词的语境,采用语义相似度计算方法。
对于一部具有语义关系的后控词表而言,一个主题词或叙词的语境信息一般包括:释义和所有表征其所在语义关系系统的属性。在CMeSH中,能够揭示CMeSH主题词既能表征其所在语义关系系统,又能参与相似度而非相关度计算的属性项主要有:
(1)树状结构编码(Tree Number):CMeSH中的树状结构编码能够揭示主题词所属学科分类树、在学科分类树中的位置(深度)、与其他主题词的上下位关系。
(2)入口词(Entry Term):是主题词的同义词、近义词、缩写、不同的拼写形式及其他用代形式。在CMeSH中,一个主题词可以对应多个入口词,但一个入口词只能对应一个主题词。
(3)注释(Scope Note):是对主题词所揭示的概念范畴的描述。
本文拟采用的文献自由词到CMeSH主题词语义相似度计算模型的计算公式如下:
Simsemantic(A,b)=Max{(Sim(A,b)),Max (Sim(Aj,b))} (1)
A表示CMeSH中的主题词,Aj表示主题词A对应的入口词,b表示自由词。Sim(A,b)表示主题词A本身和自由词b的字面相似度,Sim(Aj,b)表示主题词A的入口词与b的字面相似度,Max (Sim(Aj,b))表示从A的所有入口词与b的相似度中,取最大相似度值。
关于字面相似度的选择,拟采用Dice系数法(如公式(2)所示)[ 21]或Jaccard系数法(如公式(3)所示)[ 21]:
其中,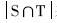 表示源字符串向量S和目标字符串T中包含的相同非零项的个数,
表示源字符串向量S和目标字符串T中包含的相同非零项的个数,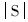 表示向量S中非零项数,
表示向量S中非零项数,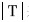 表示向量T中非零项的个数。
表示向量T中非零项的个数。
Dice系数法把相似度值限定在0-1之间,提高了相似度值的精确率,但其在针对具有较少相同词项的匹配问题时,就显得不足,Jaccard系数法填补了这一缺陷。但由于生物医学领域内自由词字长特点,具体选择哪种算法需根据实验结果决定。
(1)选择合适的基础相似度算法模型,即比较Dice系数法和Jaccard系数法在本研究中的适用性。
(2)确定最佳相似度阈值,即在怎样的阈值范围内能够获得较好的结果。
(3)区分不同“最佳”目标主题词获取方案的效果。
为保证实验数据与应用场景的一致性,所有自由词均来自中文生物医学数据库CBM中收录的期刊文献,年代跨度为1994年-2008年,共954 000条。CMeSH采用的是2008版本。
本研究实验方案和主要实现步骤如图4所示:
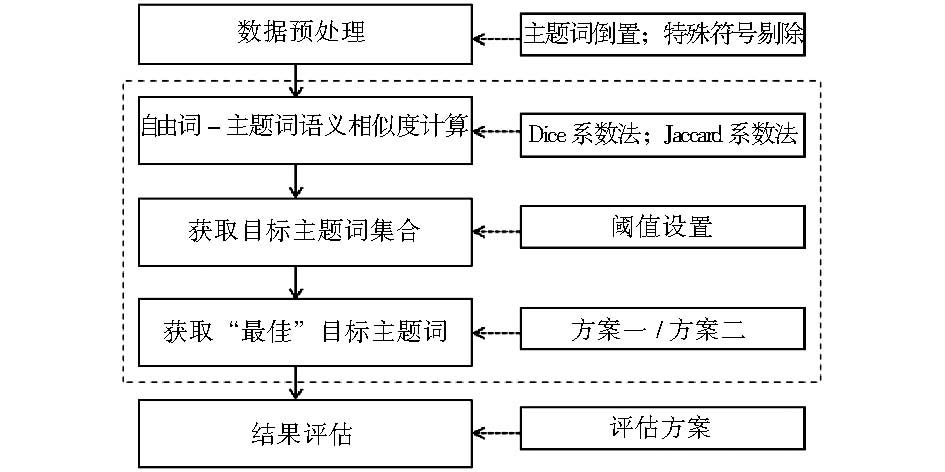 | 图4 基于CMeSH的领域自由词-主题词语义自动映射实验方案 |
其中数据预处理主要包括两个步骤:对CMeSH中的后置式主题词进行倒置。如“曲菌球, 肺”倒置为“肺曲菌球”;剔除数学运算符(+、-、*、/、%、= 等)、标点符号、连字符(—、-、_)、键盘上已有特殊符号(@ # ¥…&等)、粗点号等,使之不计入字长计算和相似度计算。
经过初步过滤,将初始阈值设为大于0.6,并随机从疾病类和微生物类中分别抽取0.05%的数据进行分析与评估,获得疾病类自由词418条,微生物类自由词980条。然后重点对相似度值大于等于0.7的不同阈值范围进行了评估。
采用的评估方法是邀请专门从事标引工作人员和信息检索人员进行审核,引入了准确率(Precision)评估指标。采用第一种和第二种“最佳”目标主题词获取方案的分析结果分别如表1和表2所示:
| 表1 方案一下不同算法模型效果分析 |
| 表2 方案二下不同算法模型效果分析 |
(1)不同基础相似度算法模型适用性分析
就准确率而言,从表1看,在相同阈值情况下,无论是疾病类和微生物类,Dice系数法返回结果的准确率优于Jaccard系数的准确率。从表2看,当阈值取大于0.8时,Dice系数法返回结果的准确率优于Jaccard系数;当阈值取大于等于0.8时,疾病类Dice系数法返回结果的准确率优于Jaccard系数;当阈值取小于0.8时,则相反。
(2)最佳阈值分析
从表1和表2均可以看出,在相同算法模型和方案下,不同领域的映射效果对相同阈值反应不同,以Dice基础算法模型为例,如表3所示,在第一种“最佳”目标词选择方案下,其在微生物类下阈值设为大于等于0.7的表现效果还微优于疾病类下阈值设为大于等于0.8时的表现,但总体来看相似度阈值选择大于等于0.8时,表现效果均还较佳,可接受。
| 表3 不同领域内效果对比分析(以Dice为例) |
综合表1和表2来看,第二种方案的效果明显稍优于第一种方案,即当有多个目标主题词时,“考虑主题词的层级关系”方案的效果稍优于“直接取字长最长的主题词作为目标主题词”。
如上分析结果所示,从准确率看,本研究提出的领域自由词到主题词语义自动映射技术路线是可行的,但在具体方案的选择上建议:
(1)关于基础相似度算法模型的选择,建议选择Dice系数法。
(2)关于最佳相似度阈值,在应用中,建议在初始阈值设为0.8时,可根据具体领域的表现效果和人工干涉量的要求进行调整。
(3)关于 “最佳”目标主题词获取方案的效果,如仅考虑准确率和能够映射到主题词的自由词数量,“考虑主题词的层级关系”方案的效果稍优于“直接取字长最长的主题词作为目标主题词”。但如结合时间消耗的考虑,则建议选择第一种方案。
本文提出的基于CMeSH的自由词-主题词语义自动映射机制在本质上采用的是基于词典的语义相似度方法。虽然表现效果良好,但在实际应用中,如仅采用此方法,仍会有一定量的自由词无法映射到目标主题词上,且随着文献和新词的增长,完全靠人工解决是不现实的,因此应综合采用多种方法,以尽可能提高映射数量和映射结果的准确性。基于此,后续拟从基于统计的角度开展领域自由词-主题词自动映射机制研究,实现两种方法的互补。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|