{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合关键词增补与领域本体的共词分析方法研究*
[唐晓波 ]
]
]
|
|


针对传统共词分析中的不足,提出一个新的共词分析过程模型,该模型从两个方面对传统共词分析方法进行改进。首先,自标引关键词不能全面描述论文主题内容,需对其进行增补。选择高频自标引关键词构成增补词典,利用基于增补词典的分词技术从标题中提取论文候选关键词,按一定规则进行增补。其次,针对共现频次较难准确描述词对相似度,引入领域本体来计算高频关键词对的语义相似度,综合考虑共现频次和语义相似度值得到词对的相关度值。用相关度来描述词对相似度,并作为构建共词矩阵的依据。最后通过实验证明改进方法的有效性。
This paper puts forward a new co-word analysis process model according to the deficiency in tradition co-word analysis. This model improves the traditional methods of co-word analysis from two aspects. At first, this paper supplements the indexing keywords because they cannot fully describe the topic content of the thesis. High frequency words from indexing key words are chosen to constitute a supplementary dictionary. Paper candidate keywords are extracted from the title by the word segmentation technology based on the supplement dictionary, and then the candidate keywords are supplemented according to certain rules. Secondly,domain Ontology is introduced to calculate the high frequency keywords for semantic similarity because the co-occurrence frequencies are difficult to accurately describe the similarity between two words,considering the co-occurrence frequency and semantic similarity. Then the correlation is used to describe the word similarity, and is the basis of building co-word matrix. Finally, experiments prove the effectiveness of this improved method.
20世纪70年代中后期法国的文献计量学家Callon首次提出了共词分析方法,经过几十年的发展已基本成熟[ 1],并被广泛应用于学科热点分析、科学计量学、信息科学和信息系统及信息检索等领域[ 2]。共词分析主要通过统计分析能表征文献主题内容的关键词之间共现的次数,得到文献所属学科的研究热点与结构[ 3]。其核心是用表征论文主题内容的高频关键词的共现频次来描述词与词之间的相似度,并以此构建出词语相似矩阵(即共词矩阵),从而进行聚类分析。如此,带来两个问题:
(1)如何获取表征论文主题内容的关键词;
(2)获取高频关键词后,高频关键词对的共现频次是否可以准确描述词与词之间的相似度。
本文将从这两个方面分析传统共词分析方法的不足并给出改进方法,得到一个新的共词分析过程模型:
(1)作者自标引关键词是传统共词分析的重要数据源[ 4]。一篇论文大概包含3-5个自标引关键词,由作者根据文献内容人工确定。该类关键词能较准确反映论文研究内容,但其确定过程主观性强,且由于有数量的限制,在反映论文内容全面性上效果有限,从而影响了共词分析的效果。针对该问题,本文采用基于分词技术的关键词增补方法来对自标引关键词进行增补,获取能较全面描述论文内容的关键词。
(2)针对很多学者指出直接用词对共现频次来描述词对相似度不科学的问题,本文引入领域本体来计算词对语义相似度,综合考虑共现频次和语义相似度得到词对的相关度值,用相关度值来描述词语之间的相似度。
(3)以CNKI中2003年-2012年间关于数字图书馆的论文为数据源进行了对比实验,证明了改进方法的有效性。
文献[ 5]论述了从论文的题名和摘要中提取关键词来增补自标引关键词的优势与可行性,但仅通过人工分析题名和摘要来提取关键词,没有实现自动抽取。文献[ 6]指出可运用分词技术从标题、摘要或正文中自动抽取词语作为论文的关键词。分词技术对于词典的要求较高,没有一个专门性分词词典,容易将词进行细粒度的切分。表征论文内容的关键词大多为专业术语,当对包含这些专业术语的标题和摘要进行细粒度分词时,很可能破坏原本词语的含义。比如,当一篇论文的标题中包含专业术语“信息资源建设”,在进行分词时该词可能被切分为“信息”、“资源”、“建设”,从而失去原本的语义信息。文献[ 7]则在采用分词技术从标题和摘要中提取关键词时,给出了一个构建分词词典的方法。首先将作者自标引关键词和机标关键词提取出来构建词典,以该词典为基础对论文的标题和摘要进行分词处理,抽取出存在于标题和摘要中的关键词,将自标引关键词、机标关键词和抽取的关键词一起作为表征论文内容的关键词。通过自己构建的词典克服一般分词技术容易造成细粒度切词的问题,尽量保持语词原本的语义信息,提高论文关键词抽取的准确性。该方法直接用自标引关键词和机标关键词来构建分词词典,没有进行关键词选择。自标引关键词和机标关键词中有一些低频词(例如:模型研究)对描述论文主题贡献不大,但经常出现在标题或摘要中,如果将其选为分词词典中的词容易影响分析效果。
自动标引是实现关键词增补的重要方法,包括关键词自动提取与自动赋词标引两种[ 8]。文献[ 9]在抽取关键词时引入条件随机场序列标注机器学习算法,构建出一个基于字角色标注的中文书目关键词标引模型。文献[ 10]提出一个基于词汇同现模型的关键词抽取方法,通过扩充传统词典得到优化词典,利用该词典进行分词,按一定指标选取出关键词。文献[ 11]引入本体实现对PDF文档的自标引,首先利用软件工具对PDF文档进行组块划分,再对组块进行标引。文献[ 12]采用逐点相对熵的方法构建了一个统计语言模型来进行关键词抽取。文献[13]选用有监督的机器学习算法从摘要中自动提取关键词,在进行文本表征时加入语法信息,提高文本表征准确性。
共词分析中词对相似度计算方法的改进主要集中在两方面:
(1)通过对自标引关键词进行加权处理,来提高关键词对的共现频次描述词对相似度的能力。文献[ 14]指出在对文献进行主题标引时存在主题词的主次之分,在统计共现频次时不能忽视这种区别。为了能更准确地描述主题词对之间的相似度,需对主要主题词进行加权。文献[ 4]提出以论文的标题和摘要为依据,对自标引关键词进行加权,将出现在标题和摘要中的自标引关键词赋予更高的权重。文献[ 15]则利用论文属性即论文的重要程度来对关键词进行加权,指出相较于影响因数低的论文,词对在影响因数高的论文中共现时,该词对关系更紧密。文献[ 16]通过改进的信息熵计算方法来对主题词进行加权选择。
(2)另一种改进研究则主要针对词对本身的语义相似度来进行。共现频次相同的两个关键词之间语义相似度很可能不一样,比如“微博文本”与“社会化媒体”的语义相似度较“微博文本”与“共词分析”更强,在进行词对相似度描述时需将这种差异考虑进去。文献[ 17]考虑用主题图描述词语之间的语义关系,通过计算共现词对在主题图中的最短路径确定其语义关系强度。综合词对语义关系强度和共现强度得到共词相关度,用该值来描述词对相似度,完成语义共词分析。文章利用词对在主题图中的路径长度计算其语义关系强度,忽略了路径中的关系类型。不同关系类型代表的关系强弱是不同的,在计算词对语义关系强度时忽略这种差异容易导致语义关系强度计算不准确。
中文分词技术是将没有分割标志的汉字串即没有词的边界的汉字串转换成符合语言实际的词串即在书面汉语中建立词的边界[ 18]。该技术是中文信息处理中的关键技术,被广泛应用于文本分类、信息检索、信息过滤、文献自动标引、摘要自动生成等领域[ 19]。现有的分词算法可大致分为以下几类:基于词典的分词方法、基于理解的分词方法、基于语义的分词方法和基于统计的分词方法[ 18]、基于字序列标注的分词方法[ 20]。
根据本文关键词增补方法的需要,选用基于词典的分词方法对论文标题进行分词处理。基于词典的分词方法是指将待分析的字符串与给定词典中的词逐一进行匹配,匹配成功则切分出一个词。该分词方法需确定分词词典、文本匹配方向及匹配原则。常用的匹配方向有正向、逆向和双向匹配;常用匹配原则有最大、最小、最佳匹配。本文利用自标引关键词构建增补词典,在匹配方法和匹配原则上选用正向最大匹配法。
本体是一个哲学上的概念,是指对世界上客观事物所进行的系统描述[ 21]。目前最被认可的关于本体的定义是1993年由Gruber[ 22]给出的,即本体是概念模型的明确的规范说明。一般而言,领域本体是用来描述某个领域被大家共同认可的、明确的、唯一的概念及其概念间关系[ 23]。其中概念是领域内具有公认语义本质的词语,概念间关系是用于实现对领域内各语义的表达[ 24],主要有5类:
(1)同义关系(Synonymy-of):能表示出概念间的“一义多词”现象,可能帮助语义消歧。比如:“武汉大学图书馆”与“武大图书馆”之间存在同义关系。
(2)上下位关系(Kind-of):表示概念之间的类属关系,构成概念间的层次结构。比如:“图书馆”与“数字图书馆”之间存在上下位关系。
(3)实例关系(Instance-of):表示概念之间有实例与类的关系[ 24]。比如:“图书馆”与“武汉大学图书馆”之间存在实例关系。
(4)部分与整体关系(Part-of):表示概念之间的组成关系,即一个概念是另一个概念的构成要素。比如:“图书”与“图书馆”之间存在部分与整体关系。
(5)属性关系(Attribute-of):表示一个概念是另一个概念的属性[ 24]。比如:“图书馆”与“馆藏”之间存在属性关系。
概念的各种关系描述了概念间不同程度的语义关联,但这个语义关联是显性的由人工判断所得。将它与词对共现频次进行加权相加可得到概念的相关度,通过共词分析挖掘出更多潜在的关联。
针对传统共词分析中用自标引关键词共现频次来描述词对相似度的不足,本文将从自标引关键词的增补和高频关键词对相似度计算两个方面对其进行改进,从而构建出新的共词分析过程模型。
(1)通过改进文献[ 17]的方法实现论文关键词增补,即将所有待分析论文的自标引关键词提取出来,从中选取高频自标引关键词组成增补词典。以论文的标题为增补源,利用增补词典和分词技术,提取出候补关键词,按照一定规则进行论文关键词增补。
(2)在共现词对相似度准确计算上则通过引入领域本体来实现。领域本体通过领域专家人工构建,可标识出相关领域内概念之间的显性语义关系,但无法表示概念间的潜在语义关系,潜在语义关系可通过共词分析方法得到。利用领域本体计算高频共现关键词对语义相似度,综合考虑共现频次及语义相似度得到词对的相关度值,该值能比共现频次更准确描述词与词之间的相似程度。以词对相关度为基础构建共词矩阵,提高共词分析的准确性。
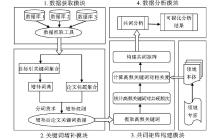
本文提出的共词分析过程模型分为4大块,即数据获取模块、关键词增补模块、共词矩阵构建模块和数据分析模块,具体如图1所示:
 | 图1 基于领域本体的共词分析过程模型 |
其中数据获取、分析等均采用传统方法,不再详述。本文重点介绍如何进行关键词增补及高频关键词对相关度计算。
关键词增补的数据源有论文标题、摘要、正文及参考文献等,考虑到时间复杂度选择标题作为增补数据源,具体增补过程如下:
(1)增补词典构建。将待分析论文的自标引关键词提取出来,统计每个自标引关键词的词频,设定阈值A,选择词频大于A的自标引关键词构成增补词典。
(2)分词处理。将增补词典加入相应的分词程序中,分别对每篇论文的标题进行分词处理,获取标题中潜在关键词。
(3)关键词增补。将潜在关键词按一定规则增补为论文关键词。其增补规则为增补后每篇论文的关键词不能重复,即对自标引关键词不再进行增补,潜在关键词中词频≥2的词只增补一次。
本文高频关键词对相关度由两个因素决定,即词对的共现频次和语义相似度。共现频次由词对出现在同一论文关键词中的次数确定,语义相似度值则借助领域本体来计算。具体过程如下:
(1)人工构建领域本体。领域本体用来描述词与词之间的语义关系,需要领域专家人工构建。
(2)高频关键词对共现频次计算。统计增补后论文关键词的词频,设定阈值B,选取词频大于B的关键词为高频关键词。依次组合高频关键词得到高频关键词对,统计每组词对在论文中的共现频次,并将关键词i与j的共现频次计为Xij。
(3)高频关键词对语义相似度计算。词对之间语义相似度由两个词在本体中的位置和它们之间关系类型决定。本体概念之间存在5种关系类型,即同义关系(Synonymy-of)、上下位关系(Kind-of)、实例关系(Instance-of)、部分与整体关系(Part-of)及属性关系(Attribute-of)。每种关系类型代表不同的相似度,首先为其设定一个相似度值,计为 Zn(n=1,…,5),相似度越高,该值越小。词对语义相似度计算过程如下:
①计算词对在领域本体中的最短路径,计为m;
②设定一个阈值C,并规定最短路径大于C的词对之间没有语义关联,即Yij=0,其中Yij表示关键词i与关键词j之间的语义相似度值;
③通过改进文献[ 17]的公式来计算有语义关联的词对的相似度值,词对相似度值等于该词对最短路径中所有关系类型相似度值和的倒数,具体公式为: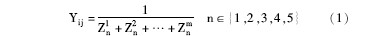
(4)高频关键词对的相关度计算。词对的相关度由两个因素确定,即词对的共现频次和语义相似度。将步骤(2)和步骤(3)计算的词对共现频次和语义相似度值进行归一化处理,再加权相加得到词对的相关度,具体公式如下: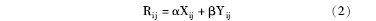
其中,Rij表示关键词i与关键词j之间的相关度值,α和β分别为词对共现频次和语义相似度值在描述词对相关度时的权重。
至此,完成了高频关键词对的相关度计算,用该值来代替共现频次描述词与词之间的相似度,从而构建共词矩阵,实现更准确的共词分析。
选择“数字图书馆”为分析对象验证本文提出方法的可行性与有效性,在CNKI中检索2003年-2012年间CSSCI索引期刊上标题或自标引关键词中包含“数字图书馆”这一关键词的论文共1 929篇。提取1 929篇论文的自标引关键词,去重并删除“数字图书馆”、“模型研究”等无效关键词,最终得到1 947个自标引关键词。本文从两个方面对共词分析进行改进,也将分别对两个改进方法进行验证。
首先将1 947个自标引关键词提取出来,选择词频≥2的词组成增补词典,按照3.1节的步骤对其进行处理。经统计原论文关键词总词频为4 947,标题增补后论文关键词总词频为6 513。原论文和增补后论文前20个高频关键词及词频如表1所示:
| 表1 高频关键词列表 |
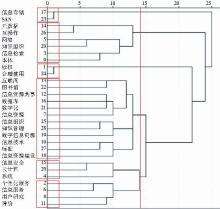
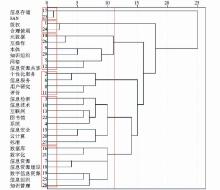
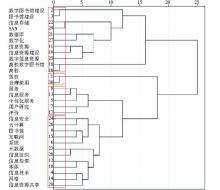
选择原论文中前29个高频词作为分析对象,根据这29个词在原论文和增补后论文中的共现频次进行共词聚类分析,得到如图2和图3所示的聚类效果图。总体上对比两个聚类效果图可以看到,相较原论文,增补后论文的聚类速度快且类团较紧密、大小较均匀。
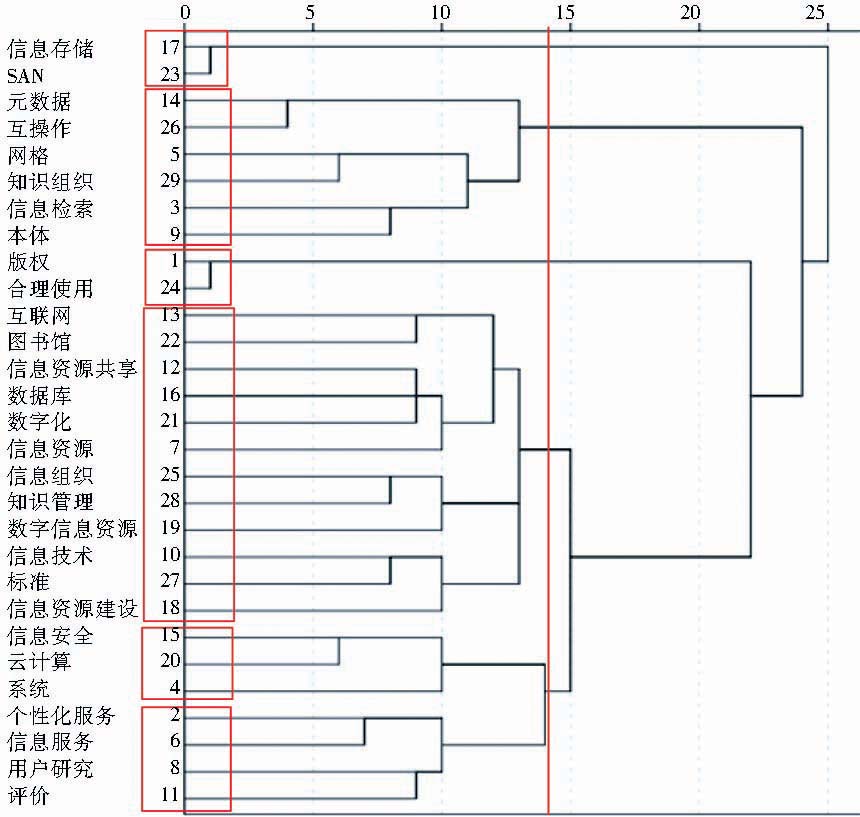 | 图2 原论文聚类效果 |
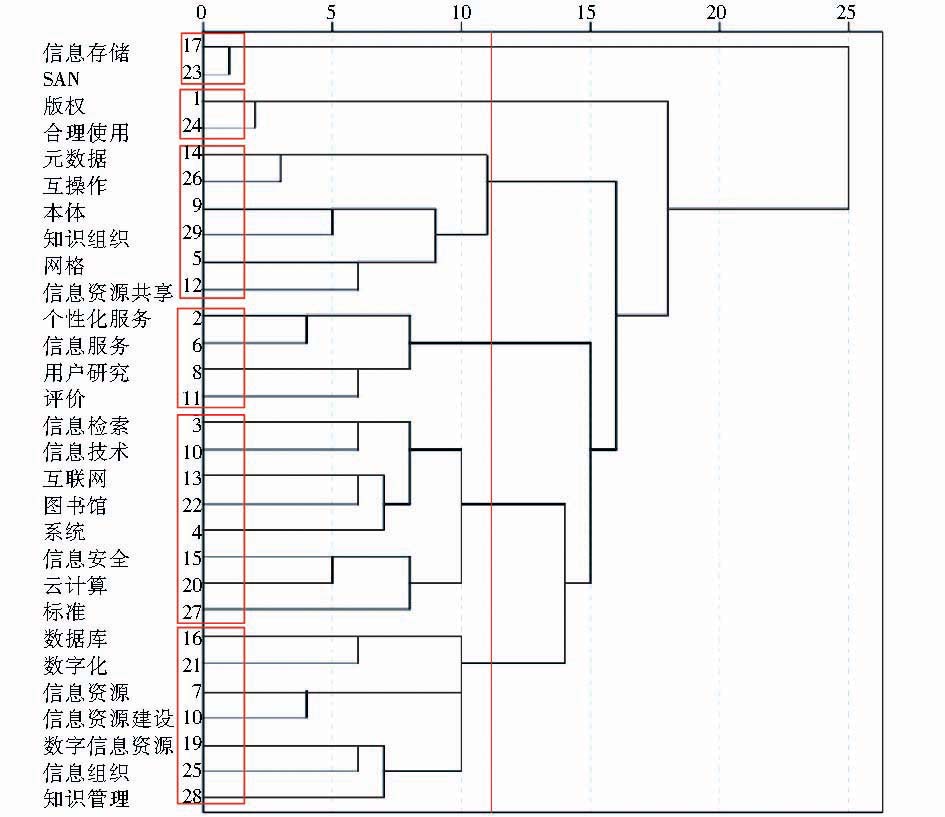 | 图3 增补后论文聚类效果 |
仔细分析两个聚类效果图,根据图2可将29个高频关键词分为“存储”、“技术1”、“版权”、“资源”、“技术2”和“服务”6大类;根据图3可将29个高频关键词分为“存储”、“版权”、“技术1”、“服务”、“技术2”、“资源”6大类。两个聚类图中的“存储”、“版权”、“服务”三个类团完全一致,这里不再比较。有较大区别的是“技术1”、“技术2”与“资源”三个类团。首先,图2中“信息技术”被聚到了“资源”一类,图3中该关键词被聚到了“技术2”一类。其次,图2中“信息资源共享”没有与“元数据”、“知识组织”等词聚在一起,图3中“元数据”和“知识组织”则与“信息资源共享”聚在一起。分析可知,元数据是信息资源共享中的一个重要技术,知识组织是信息资源共享的前提,把它们聚在一起更为合理。根据以上分析可知,论文关键词增补后的聚类效果优于增补前。
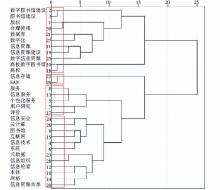
本节将验证词对相关度是否比共现频次能更准确描述词与词之间的相似度,以此进行的聚类分析效果是否更好。将标题增补后论文的前30个高频关键词提取出来进行聚类分析,得到聚类效果如图4所示:
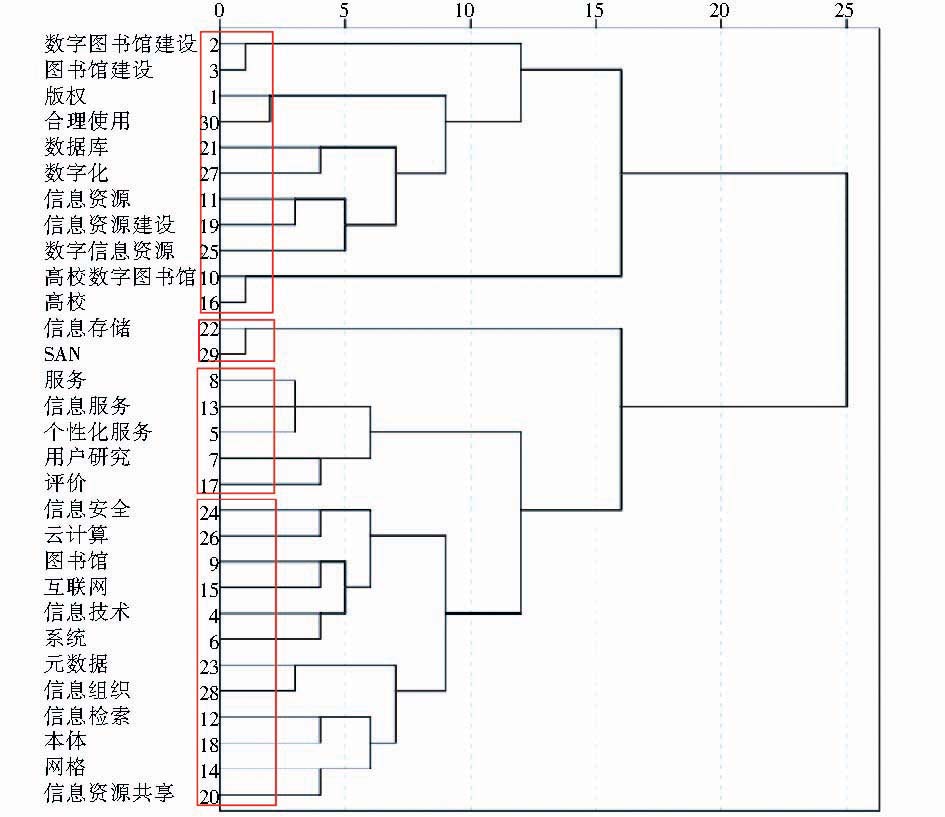 | 图4 增补后论文高频词聚类效果 |
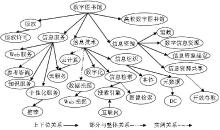
请专家构建“数字图书馆”领域的本体,具体构建过程如下:从增补后的关键词数据中提取词频≥7的关键词共124个,构成领域本体的候选概念;对候选概念进行人工选择;由专家确定概念间的关系并构建出“数字图书馆”领域本体。经统计最后得到实例关系8个,属性关系1个,部分与整体关系6个,上下位关系105个,部分领域本体如图5所示:
 | 图5 部分领域本体 |
以该领域本体为基础,按3.2节的方法计算30个词之间的相关度,据此构建共词矩阵并进行聚类分析,得到聚类效果如图6所示:
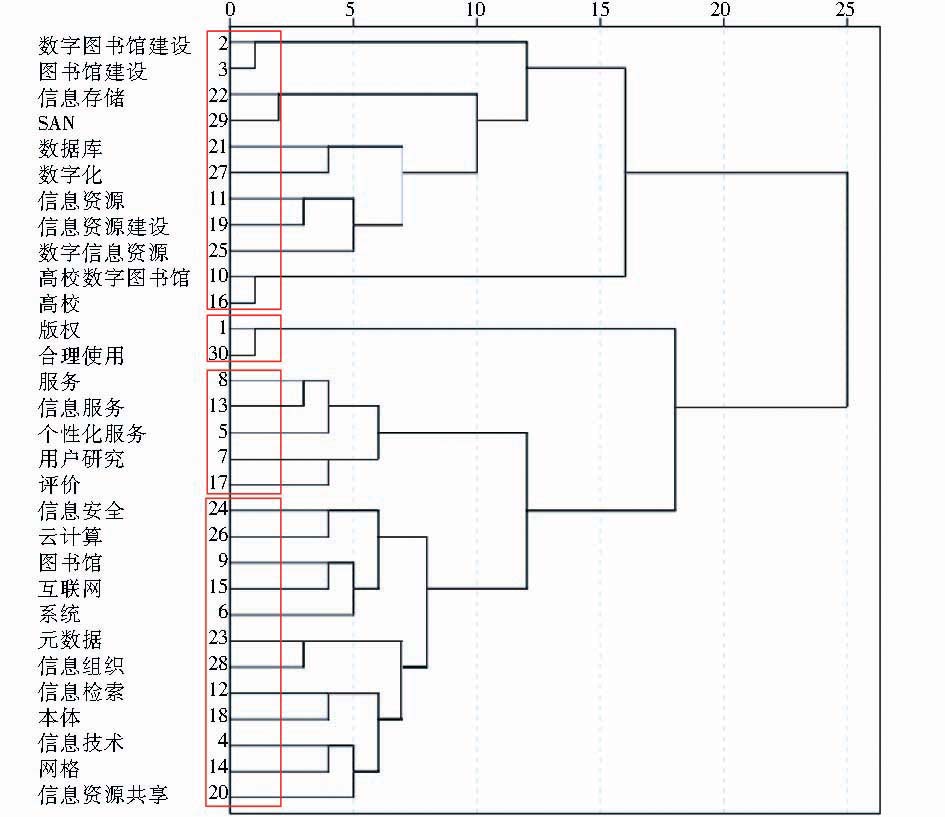 | 图6 加入领域本体后聚类效果 |
根据图4可将“数字图书馆”领域研究热点大致分为“资源”、“存储”、“服务”与“技术”4类;根据图6可将“数字图书馆”领域研究热点大致分为“资源”、“版权”、“服务”和“技术”4类。两个图的不同在于图4中“信息存储”与“SAN”被单独聚为“存储”类,“合理使用”与“版权”与其他资源相关词一起聚在“资源”类;图6中“合理使用”与“版权”被单独聚为“版权”类,“信息存储”与“SAN”则与其他资源相关词一起聚在“资源”类。分析可知,“信息存储”与“SAN”相较“合理使用”与“版权”与信息资源更相关,将其划入“资源”一类更为合适;“数字图书馆”领域对版权的研究较多,划出一个单独的子类更为合适。由此可知,图6的聚类效果优于图4,证明了本文提出的词对相关度计算方法的有效性。
近年来,共词分析被广泛应用于学科热点探测、人工智能、信息检索等领域且取得了不错的效果,但以自标引关键词共现频次为分析依据的方法存在一定缺陷。针对传统方法的不足,本文进行了两个方面的改进研究。首先,由于自标引关键词不能全面描述论文主题内容需对其进行增补。利用自标引关键词构建增补词典,以论文标题为数据源提取关键词实现增补。其次,用高频关键词对的相关度代替共现频次描述词对相似度。利用人工构建的领域本体计算高频关键词对的语义相似度,综合考虑词对语义相似度和共现频次得到词对相关度。本文在一定程度上解决了共词分析过程中存在的问题,但还有不足之处,如领域本体需人工构建耗时耗力且主观性较强,有待以后改进。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|