{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于领域本体的知识库多层次文本聚类研究* ——以中华烹饪文化知识库为例
[洪韵佳 ]
]
]
|
|


基于领域本体提出一种适用于知识库树状结构的多层次文本聚类方法。该方法利用领域本体将词映射为各层级的概念,先以高层级的概念实现粗粒度聚类,以识别不同题材的文本,形成知识库的主体分类框架;再结合各层级的概念与未能映射的非概念特征词实现细粒度聚类,以揭示不同深度的文本主题信息,从而实现从粗粒度到细粒度的多层次聚类。
The paper puts forward a kind of multi-level text clustering method for the tree structure of knowledge base. In this method, the words are mapped as concepts by the domain Ontology. First the texts are represented by the top-level concepts to realize the big-size clustering, identify the different subjects of texts and formulate the main classification framework. Then the texts are represented by all concepts and non-concept feature words to further realize the small-size clustering and reveal the subjects of the texts with different depth. Finally, this method realizes the multi-level text clustering from big size to small size.
知识库中除了包括由专家、管理员组织入库的信息外,还包括由用户生成、来源于互联网等外部信息源的信息,如何对这些源于外部的大量信息快速进行自动组织、发现其中有用的信息,是知识库不断扩充、有序组织的关键问题,也是进一步提供知识服务、可视化导航、优化检索的重要基础。
文本聚类作为一种重要的无指导的信息自动组织方法,对知识库的建设与发展有着重要的意义。目前,文本聚类研究大多采用向量空间模型(VSM)[ 1]。在VSM中,向量的每一维通常由一个词来表示,词与词之间是相互独立的,这导致向量维度通常很高,并割裂了文本原有的语义关系。针对VSM的不足,近年来学者们将本体引入文本聚类中,通过将词转换为概念,大大降低了文本向量的维度;同时,利用本体所具有的语义结构,更好地反映了文本的内容特征。
然而,与普通文本集平面组织结构不同,在知识库(如上海图书馆网上联合知识导航站知识库[ 2]等)中信息往往呈树状组织结构。为了实现这种多层级的文本自动组织,本文提出了一种基于领域本体的多层次文本聚类方法,通过领域本体将词映射为不同层级的概念,并对文本中未能转换为概念的词进行了进一步的特征选择,利用不同层级的概念与非概念特征词的组配,实现了不同粒度的多层次聚类。
此外,本文结合中华烹饪文化本体所具有的特性,对文本概念映射、概念间语义相似度算法进行了优化,这些优化不仅在利用中华烹饪文化本体时起到了较好的效果,对于应用其他本体开展文本聚类也具有一定的借鉴价值。
本体作为描述概念及概念之间关系的概念模型,其实例与概念间所具有的抽象性有助于更好地表征文本内容并降低文本向量维度。此外,利用本体中概念间的语义关系能够进一步优化语义相似度计算和文本聚类算法,提升聚类效果。因此,近年来对基于本体的文本聚类研究主要涉及以下三个环节:
(1)基于本体的文本表示研究
Hotho等[ 3]、Sedding等[ 4]、Recupero[ 5]利用WordNet对同义词和多义词进行了概念转化与消歧处理;朱会峰等[ 6]、Luo等[ 7]也引入WordNet对文本进行了概念映射,通过概念节点及概念间的语义关系降低文本特征向量维度。此外,Hensman[ 8]在WordNet的基础上构建了表示文本的本体图;明均仁[ 9]利用本体图更好地表征了文本的语法结构和语义内容,优化了文本聚类效果。然而,WordNet作为英语通用本体,仅包括概念间简单关系,难以充分表征各领域概念间深层关系。因此,Hotho等[ 10]利用包含特定领域本体的SMES系统将特征词映射为领域概念;张玉峰等[ 11]利用英语竞争情报领域本体实现了语义层面的文本表示;龚光明等[ 12]引入中文生物医药领域本体的同时,进一步结合领域文本特点设定了判定条件。上述学者利用本体的文本表示更好地揭示文本语义层面的知识,并较好地降低了文本向量维度,然而在文本映射时未能对那些无法转换为概念的词加以利用,损失了部分文本内容。
(2)基于本体的概念间语义相似度研究
本体由概念和概念间的关系构成,不同关系的概念间具有不同的语义相似度。近年来,对于本体的概念间语义相似度算法的研究较多,主要可以分为4类[ 13]:基于距离的语义相似度算法、基于信息内容的语义相似度算法、基于属性的语义相似度算法以及基于混合式的语义相似度算法。在此基础上,赵捧未等[ 14]、吕刚等[ 15]对经典算法进行了修正;谢红薇等[ 16]提出了一种新的基于概念属性交集的加权相似度计算方法,优化了K-means聚类算法;王刚等[ 17, 18]考虑了概念特征间的相似情况,提出并逐步改进了一种基于语义元的概念相似度计算方法。在上述各类算法中,基于距离的语义相似度算法最为成熟、被引用率最高,因此,本文借鉴了该算法,并结合中华烹饪文化本体的特性,计算得到本体概念间的相似度。
(3)基于本体的聚类算法研究
文本聚类是根据文本间的相似度将文本划分为多个簇或类的过程。因此,学者们对基于本体的聚类算法研究主要侧重于文本间相似度算法的研究。如Basili等[ 19]结合概念间的语义相似度与文本特征权值,提出了融合语义核的文本间相似度算法;Zhang等[ 20]鉴于不同特征在文本中不同的重要性,进一步利用本体语义关系对文本特征进行了加权,提出基于本体的特征权重聚类算法(OFW-Clustering)。针对K-means聚类算法,张玉峰等[ 21]、王刚等[ 18]将本体概念间语义关系融合到聚类过程中优化了簇心选择与孤立点剔除。此外,王晓东等[ 22]鉴于用户对聚类精度的不同需求,通过设定概念抽象度调节因子将本体中抽象度大于用户定义阈值的特征概念权值置零,从而实现了一种基于本体的抽象度可调文档聚类。在上述研究中,本体中的语义知识较好地优化了文本聚类算法,并考虑到了用户对不同聚类粒度的需求,然而,这些聚类结果往往是无层次的,无法直接应用于知识库树状组织结构中。
基于前人的研究成果与不足,本文针对知识库树状组织结构提出了一种基于领域本体的多层次文本聚类方法。在文本表示中,在将词映射到本体概念并融入概念间语义相似度的同时,对未能转换为概念的词进行了进一步的特征选择,结合文本特征概念与非概念特征词更充分地表征了文本内容。此外,在概念映射与概念间语义相似度计算的过程中,结合中华烹饪文化本体中同义词、类间关系较多等特性,在经典算法的基础上引入了标签匹配、对象属性关系计算等方法,获得了更好的聚类效果。
传统的基于VSM的文本聚类方法一般包括文本预处理(分词、去停用词等)、文本向量化表示、文本相似度计算、文本聚类计算等步骤。基于领域本体的文本聚类方法在此基础上,引入领域本体对文本表示与文本相似度计算进行了优化。
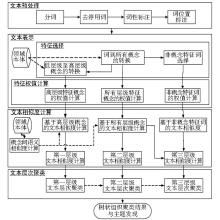
在上述流程中,通过将文本中的词映射为各层级的概念,并进一步结合那些未能映射概念的特征词,实现了从粗粒度到细粒度的多层次文本聚类。通过实验探讨,验证了该聚类方法能够较好地适用于知识库树状层次结构,实现知识库中文本的自动组织。本文的研究思路如图1所示,该研究框架对其他本体聚类研究也具有一定的借鉴价值。
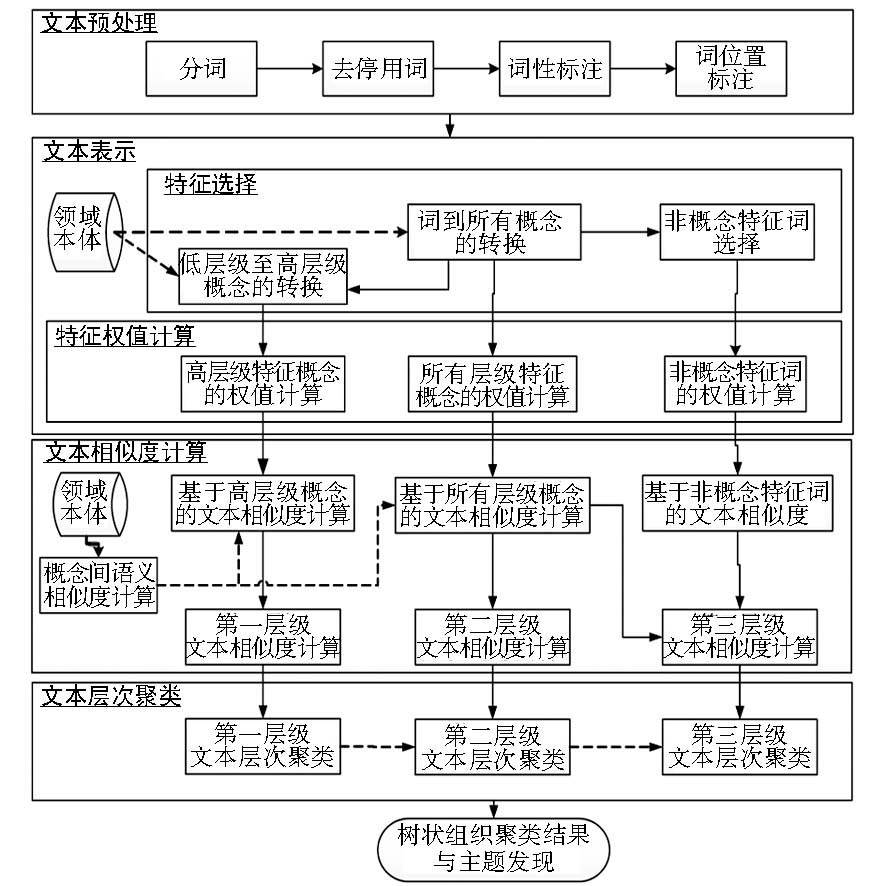 | 图1 基于领域本体的知识库多层次文本聚类框架 |
由于文本属于非结构化数据,为了将聚类算法应用在文本对象上,必须先对文本进行预处理。中文文本预处理的步骤一般包括分词、去停用词以及词性标注,本文利用中国科学院计算技术研究所分词系统ICTCLAS 5.0,在基本词库的基础上,加载中华烹饪文化本体中对应的词典,以完成上述三个步骤。
文本表示是将非结构化的数据转换为计算机可处理形式的过程。目前,常用的文本表示模型主要有向量空间模型、布尔模型与概率模型[ 23]。本文借鉴VSM将文本表示为由特征项及特征项的权值组成的向量。其中,将基于概念的文本表示为公式(1),将基于非概念特征词的文本表示为公式(2):
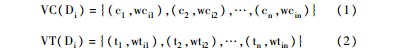
以下将对上述公式中概念的映射与概念权值的计算方法、非概念特征词选择与其权值计算方法进行详细的介绍。
(1)基于概念的文本表示
①概念的映射
经过预处理后的文本可以看作词的集合,本文通过词与本体概念间的匹配,将词转换为概念,从而将文本表示为基于概念的向量模型。然而,由于中华烹饪文化本体中所包含的菜肴名、食材名常常包含许多同义词,如菜名“番茄炒蛋”又可叫做“西红柿炒蛋”、“西红柿炒鸡蛋”、“番茄炒鸡蛋”等,因此,如果将分词后的文本直接与本体概念/实例进行匹配,将会遗漏许多概念/实例。为解决这一问题,本文对中华烹饪文化本体中的各实例加注了标签(如“番茄炒蛋”包含label“西红柿炒蛋”、“西红柿炒鸡蛋”、“番茄炒鸡蛋”),通过将词与标签进行匹配来优化概念映射。具体匹配规则如下:
1)将词与大类下的概念(类)进行匹配,如果匹配,将词转换为相应的概念;如果不能匹配,执行步骤2);
2)将词与大类下的属性进行匹配,如果匹配,将词转换为属性所属的概念;如果不能匹配,执行步骤3);
3)将词与大类下的实例进行匹配,如果匹配,将词转换为实例所属的最低位概念;如果不能匹配,执行步骤4);
4)将词与大类下的各实例标签进行匹配,如果匹配,将词转换为相应实例所属的最低位概念;如果不能匹配,继续遍历下一个大类下的所有概念、属性、实例及实例标签,直至完成所有遍历后,执行步骤5);
5)将各文本中未能匹配的词标记为“未转换”,保存到新的向量中VTi = {t1, t2,…, tn},以待后续特征选择。
②高层级概念映射
在将词映射为本体概念后,为了实现不同粒度的聚类,进一步基于本体结构将低层级的概念映射为高层级的概念。在选择高层级概念时,可以根据领域本体结构与用户需求进行确定。鉴于中华烹饪文化本体所包含的概念层级较少,选用根节点下的第一层概念作为高层级概念,对该层之下的概念进行转换。
③特征概念的权值计算
在对高层级特征概念与所有层级特征概念进行权值计算时,为了消除文本长短对概念出现频次的影响,本文借鉴文献[24]的归一方法,将概念的权值定义为该概念在文本中出现的次数与该文本包含的所有概念出现次数的比值,公式如下所示: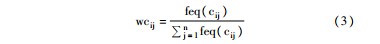
其中,feq(cij) 为概念cj在文本Di中出现的次数。
(2)基于非概念特征词的文本表示
①非概念特征词选择
在将文本表示为基于概念的向量后,本文对未能转换为概念的词进行了进一步的特征选择。首先,根据词性标注筛选出其中的名词;其次,利用文档频率(DF)算法过滤无效高频词及出现次数过少的词,最终保留在2%-90%的文本中出现过的名词作为特征词。
②非概念特征词的权值计算
本文采用经典的TF-IDF算法对非概念特征词加以权值,用词频和文档频率共同表示非概念特征词对文本的贡献,公式如下所示:
其中,tfij是特征词tj在文本Di中出现的次数,dfj是文本集中含有特征词tj的文档数目,N是文本集中文本的数目。
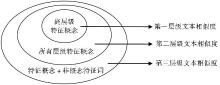
文本相似度是用来衡量两个文本之间的相似程度的度量,是后续文本聚类计算的基础。在上述基于高层级概念、所有层级概念与非概念特征词文本表示的基础上,本文分别计算了各自所表征的文本间相似程度。以基于高层级概念的文本相似度来表示第一层级文本相似度,以基于所有层级概念的文本相似度来表示第二层级文本相似度,并综合基于所有层级概念与非概念特征词的文本相似度结果,来表示第三层级的文本相似度,以更充分地表征文本内容,如图2所示:
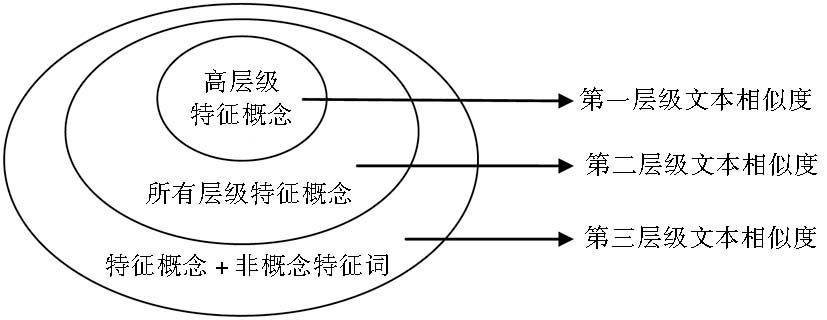 | 图2 各层级文本相似度计算方法 |
为了充分利用本体包含的语义优势,在计算基于高层级概念与所有层级概念的文本相似度时,本文借鉴了近年来学者普遍的研究思路[ 5, 6, 21],进一步考虑了特征概念间的相似度,以削弱传统文本相似度计算中词与词之间相互独立、缺乏语义关系的弊端。
(1)本体概念间语义相似度计算
在利用基于概念的文本表示计算文本间相似度时,除了对特征项权值进行运算外,本文进一步融入了本体概念间的语义相似度。在4类语义相似度计算方法中,借鉴了基于距离的语义相似度算法,通过计算两个概念在本体树状结构中的最短路径长度来量化它们之间的语义距离[ 14],如公式(5)所示。同时,考虑到概念在本体层次树中的位置(所在深度),对各路径边加以权值[ 25],如公式(6)和公式(7)所示: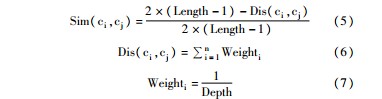
其中,Length表示本体树状结构的最大深度,令根节点的层级为1,Length即树状结构中最底层节点的最大层级数。Dis(ci,cj)表示概念ci和cj之间最短路径的长度,Weighti表示连接ci和cj的最短路径上第i条边的权值,Depth表示边所连接的上位概念所在的层级数。
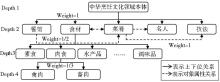
此外,除了考虑概念间的上下位关系,本文对概念间具有的对象属性(Object Properties)关系也加以考虑,设其路径权值为1,如图3所示,进一步完善了概念间的相似度。
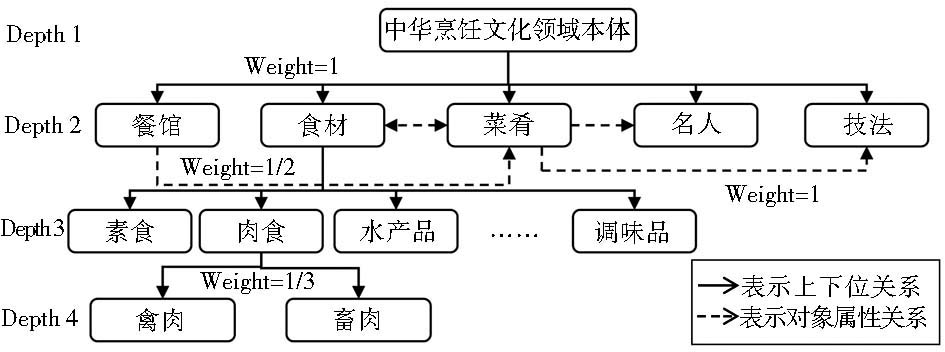 | 图3 本体概念间距离示意图 |
根据上述算法,“食材”与“餐馆”间的语义相似度为0.666 7,“食材”与“菜肴”间的语义相似度为0.833 3,高于其与“餐馆”间的相似度,与实际情况相似;“食材”与“禽肉”间的语义相似度为0.861 1,“食材”与“肉食”间的语义相似度为0.916 7,“肉食”与“禽肉”间的语义相似度为0.944 4,高于前两者,也与实际情况相似。从而可见,上述概念间语义相似度算法能够较好地运用于该领域本体。
(2)基于概念的文本相似度计算
基于概念的文本相似度是指借助于概念向量间的相似度来表示的文本内容间的相关程度。在三个层级的文本相似度计算中,无论是基于高层级概念还是所有层级概念,都涉及此基于概念的文本相似度算法。
本文借鉴Basili等[ 19]提出的文本相似核(Document Similarity Kernel)算法,结合上述概念间的语义相似度,对基于概念的文本相似度进行了计算,具体算法如下所示: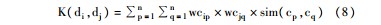
其中,wcip是文本di中概念cp的特征权值,wcjq是文本dj中概念cq的特征权值,sim(cp,cq)是概念cp与cq间的语义相似度。
为了避免不同文本长短对计算结果的影响,需要进一步对公式(8)进行归一化处理,如下所示: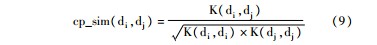
(3)基于非概念特征词的文本相似度计算
在第三层级文本相似度计算中,本文进一步考虑了非概念特征词对文本间相似度的影响,采用余弦相似度算法对基于非概念特征词的文本向量进行了相似度计算,具体算法如下所示: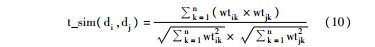
其中,wtik是文本di中特征词tk的特征权值,wtjk是文本dj中特征词tk的特征权值。如果某篇文本中未能包括任何被选择的特征词,则将这篇文本与其他文本间的相似度置为0。
(4)各层级文本间相似度计算
由于第一层级与第二层级文本相似度计算都仅仅基于概念的文本相似度。因此,第一层级与第二层级的文本间相似度算法皆如下所示: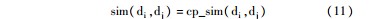
在第三层级的文本相似度计算中,本文综合考虑了基于概念的文本相似度与基于非概念特征词的文本相似度结果,第三层级的文本间相似度算法如下所示:
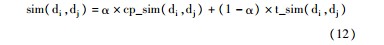
其中,α为调节因子,用以调节文本中概念与非概念特征词对文本相似度的影响,可通过实验或经验取得。
聚类算法主要可分为基于划分的方法、基于层次的方法、基于密度的方法等[ 23]。其中,基于层次的聚类算法可分为自下而上的凝聚式和自上而下的分裂式两种类型。鉴于本实验样本量较少,基于层次的聚类算法能取得更精确的结果,本文在三个层级的文本聚类中皆选择了自下而上的凝聚式层次聚类算法。
在凝聚式层次聚类过程中,类间相似度是聚类的依据。类间相似度是指两个类中所有文本两两间相似度之和的平均值[ 24]。具体算法如下所示:

其中,dm是类clusteri中的文本,dn是类clusterj中的文本,ni和nj分别是类clusteri和clusterj中包含的文本数。具体层次聚类过程如下:
输入:各层级文本间相似度矩阵Matrix_sim,希望达到的最终聚类数m。
输出:各层级聚类分析结果C1=(c1,c2,…,cm);C2=(c11,…,c1p,c21,…,c2p,…,cm1,…,cmp);C3=(c111,…,c11q,…,c1p1,…,c1pq,…,cm11,…,cm1q,…,cmp1,…,cmpq)。
①基于第一层级文本相似度对所有文本进行聚类;
②将每个文本看作一个类,构成类集(cluster1,cluster2,…,clustern);
③利用公式(13)计算每个类间的相似度;
④选择最大相似度的类对(clusteri, clusterj),将clusterj中的文本合并入clusteri中,构成新的类集(cluster1,cluseter2,…,clustern-1);
⑤不断重复步骤③和步骤④,直至剩余类数到达要求的第一层级聚类数目m;
⑥在第一层级聚类结果的基础上,利用第二层级文本相似度依次对第一层类下的文本进行第二次聚类,不断重复步骤③和步骤④,直至剩余类数到达要求的第二层级聚类数目p(当p大于各类中所含的文本数量n’时,聚类数目取n’-1);
⑦在第二层级聚类结果的基础上,利用第三层级文本相似度依次对第二层类下的文本进行第三次聚类,不断重复步骤③和步骤④,直至剩余类数到达要求的第三层级聚类数目q(当q大于各类中所含的文本数量n’’时,聚类数目取n’’-1)。
本文以《基于领域本体的专题库构建——以中华烹饪文化知识库为例》一文中所介绍的中华烹饪文化领域本体与其知识资源为例,从“菜谱”、“食材介绍”、“美食故事”、“各地美食攻略”4类文本集合中随机各抽取出50篇文本,构成实验数据,以验证上文所述聚类方法的有效性。
在对聚类质量评价中,本文选用熵的方法[ 26],以度量各类中包含相关语料库中已分好的类别的程度,如下所示: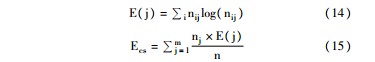
其中,nj为类Cj中文本的数目,nij为第i个语料库内类别Li被划分到第j个类Cj的文本对象的数目,即nij=|Li∩Cj|;n为所有实验样本的个数。熵值越小,表示类内部一致性越高,聚类结果越好。
首先对实验文本开展第一层级与第二层级的聚类,聚类结果如表1所示:
| 表1 第一层级与第二层级文本聚类结果 |
| 表2 聚类结果熵值对比(a) |
| 表2 聚类结果熵值对比(b) |
从表2可见,本文所提出的基于领域本体的文本聚类效果较好,与原始的知识库分组情况相似,能有效提高文本的聚类精度。
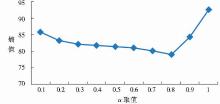
此外,在进行第三层级文本聚类时,为获得最好的聚类结果,笔者对第三层级文本间相似度算法中调节因子α的取值进行了研究。聚类数目为3、α取不同值时的基于领域本体的文本聚类算法的聚类效果如图4所示:
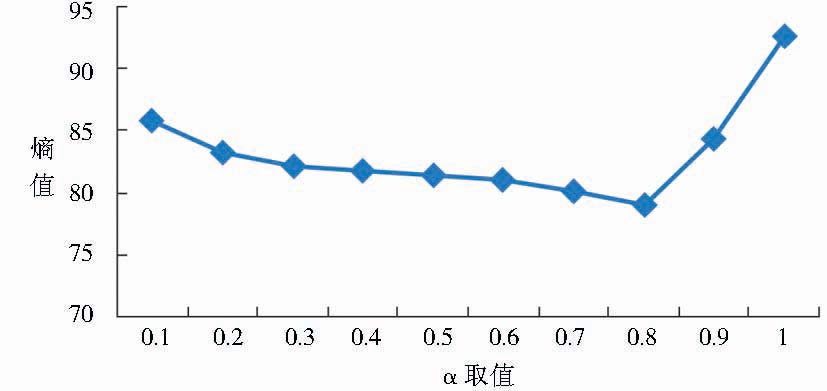 | 图4 调节因子与熵值对应关系 |
图4显示随着α取值的增大,熵值呈缓慢下降趋势,即聚类效果越来越好;当α取0.8时熵值最小,聚类效果最好;然而,随着α进一步增大,熵值呈上升趋势,聚类效果降低。可以发现,在第三层级聚类的过程中,基于概念的文本相似度对文本聚类效果的影响较大,然而非概念特征词的引入对聚类效果起到了较明显的优化作用,因此,综合概念及非概念特征词的算法对提高文本聚类精度确实能起到较好的效果。
本文基于领域本体提出了一种适用于知识库树状结构的多层次文本聚类方法。该方法利用领域本体将词映射为概念后,将低层级的概念进一步映射为高层级的概念,先以高层级的概念进行粗粒度聚类,以识别不同题材的文本,形成知识库的主体分类框架;再在第一层级聚类结果的基础上,用所有层级的概念进行二次聚类;并进一步结合各层级的概念与未能映射的非概念特征词实现了细粒度聚类,揭示不同深度的文本主题信息,从而实现了从粗粒度到细粒度的多层次聚类。
此外,在利用中华烹饪文化本体进行概念映射、概念间语义相似度计算的过程中,本文借鉴前人的研究,并结合中华烹饪文化本体的特性,对词与概念间匹配方式、基于距离的语义相似度算法进行部分优化,更好地降低了文本向量的维度,表征了文本内概念间的语义关系。同时,这些优化具有一定的通用性,对于应用其他本体开展文本聚类也有一定的借鉴价值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|