


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于领域本体的专题库构建* ——以中华烹饪文化知识库为例
[许鑫1  , 郭金龙
, 郭金龙2 ]
, 郭金龙|
|


提出一个新的基于本体的专题知识库构建模型。该模型利用本体为指导构建知识库的领域知识框架,同时利用基于本体的文档语义标注技术实现领域文档和领域知识的映射。以中华烹饪文化领域为例详细介绍基于本体的专题知识库构建流程,包括其中关键的本体建模和本体语义标注技术。最后,设计并实现中华烹饪文化知识检索原型系统,详细介绍利用语义网工具Jena等进行本体操纵的方法,以此验证基于本体的专题知识库模型在本体知识检索和文档语义检索方面的功能优势。
This paper proposes a new Ontology-based subject knowledge base model. This model uses Ontology as guidance to construct domain knowledge framework and uses Ontology-based semantic annotation technique to realize the mapping between domain document and domain concept. Taking the domain of Chinese Cuisine Culture as an example, the flow of constructing the knowledge base is detailed including the two key techniques, Ontology modeling and semantic annotation. Finally, a prototype system for Chinese Cuisine Culture knowledge retrieval is developed with detailed introduction to Ontology manipulation using Jena, which verifies the advantages of the Ontology-based subject knowledge base model in the aspect of knowledge retrieval and semantic retrieval.
随着信息的进一步激增,人们对高效组织与获取领域知识提出了更高的要求。在多个领域,人们构建了各种专题知识库来对领域知识进行组织与利用。然而基于传统的数据库构建的专题知识库实质只是一种资源库,对领域知识的揭示极其有限,因而无法实现知识检索、推理等更高层次的知识服务。
本体和语义网技术的引入,对知识管理的研究产生了重大的影响。由于本体强大的知识表示和关联推理机制,基于本体的知识库模型俨然成为了新一代知识管理系统的自然选择[ 1]。研究者们纷纷将其应用于各自领域的知识管理研究中,基于本体的领域知识管理经历了由模型构建到系统开发的发展过程。在农业[ 2]、医学[ 3, 4]、历史[ 5]、教育[ 6, 7]、旅游[ 8, 9]等多个领域出现了利用本体构建知识库的应用。
然而现有的大部分基于本体的知识库仅仅包含了本体库本身(概念和实例)。笔者认为,一个完整的领域专题库不仅应该包括组织良好的知识体系和知识实例,还应该包含相应的领域文档。基于本体的知识检索返回的结果是本体中的知识片段(实例、属性值等),不能完全满足用户的信息需求。完整的文档所包含的内容是不能简单地被碎片化知识的组合所替代的。因此,本文的专题库由本体知识库和领域资源库共同构成。
纵观现有的基于本体的知识库相关研究,发现目前本体应用的一个困境是研究本体构建的技术体系与研究检索的技术体系之间存在脱节问题。自动语义标注是本体大规模构建与应用的瓶颈。信息检索领域的研究者主要从本体如何改善文档检索的角度出发,利用本体进行文档语义标注。而本体领域的研究者则主要关注本体库构建本身。两者之间没有进行很好的结合。
信息检索领域的研究者开发了一些综合本体的知识库功能和语义标注功能的知识库平台,如KIM[ 10]、Mímir[ 11]等。两者共同的缺陷在于其主要从文档检索的视角出发,提供实体的标注与索引,而对领域本体中的知识与知识关联支持十分有限。本体领域的研究者主要关注本体库构建本身,构建了大量规模有限的领域本体,对如何高效地使用这些本体组织领域文档则研究较少。Almeida等[ 12]以某企业为例介绍了在企业知识管理中利用本体进行知识建模的方法,但该文没有涉及本体与文档的语义标注问题,因此并不能实现文档的大规模语义处理。
从专题库构建的视角,探讨本体在知识库构建中应用的相关研究如:Fensel[ 13]介绍了On-to-Knowledge项目,该项目设计了一个利用本体自动获取、维护、访问弱结构化数据的方法并提供了相应的工具。该项目主要从文档和数据利用的角度探讨了本体在知识管理中的应用,而没有从领域知识建模的角度进行讨论。钱智勇[ 14]以张骞研究专题知识库系统为例,探讨了基于本体的专题域知识库系统设计与实现。然而该文并没有对关键的语义标注环节进行详细论述,也未见完整的系统实现。钱智勇等[ 15]还探讨了基于本体的楚辞知识库构建,讨论了基于本体的知识组织在知识库构建中的应用。然而其语义提取部分则主要是通过人工操作。李景[ 16]研究了本体在农业领域的应用,开发了一个多人大规模本体建模与开发工具LODE,该工具可以提供利用领域本体自动标注文档的功能。然而现在可以得到的用于实验的本体只是轻量级本体,内部关系较简单,其知识领域模型理论需进一步认证。
综上所述,现有的大部分基于本体的知识库要么不提供任何与领域知识节点对应的领域文档资源,要么与领域知识节点对应的文档是通过手动方式添加的。鉴于此,本文将探讨领域本体指导下的专题库构建模式,并利用现有的相关开源工具,进行领域知识的建模,完成领域文档的自动语义标注,并最终实现一个基于领域本体的专题库,开发出相关原型系统。
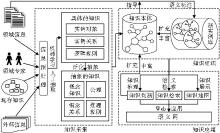
本体驱动的知识管理模型经过了较长时间的研究与探讨,王昊等[ 17]利用模型构建和功能分析的方法,对现有的本体驱动的知识管理系统模型进行了总结与分析,将本体驱动的知识管理系统模型分为三个环节:知识采集、知识组织、知识应用,如图1所示:
 | 图1 本体驱动的知识库一般模型[ 17] |
该系统模型首先对来自不同信息源的信息进行预处理,采用机器学习或者人工抽取的方式从信息源中采集出具体的知识,如实例对象、实例关系以及逻辑规则等,进而将具体知识泛化为抽象知识,例如概念知识、概念关系、公理和推理规则等。接着将采集的知识以本体的形式(如XML等)进行描述,形成领域知识本体库。该知识本体库可以用于指导领域信息的语义标注,以此获得领域新的实例,丰富和扩充原知识本体。在此基础上,领域本体可以提供知识应用服务,如知识地图、知识检索、知识推理和发现等。
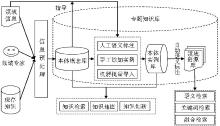
由图1可以看到,现有的本体驱动的知识库模型其本质就是本体库本身,即包括概念本体和本体实例库。模型的核心在于如何通过外部知识的采集去不断完善这个概念本体和本体实例库,以及挖掘这个本体库本身提供的知识服务功能。然而笔者认为,一个专题领域的知识库不仅应该包含相应的结构化的知识体系和知识片段,还应该包含相关领域的资源库。鉴于此,本文在现有的本体知识库一般模型的基础上,加入领域资源标注模块,提出了新的本体驱动的专题知识库模型,如图2所示:
 | 图2 本体驱动的专题知识库模型 |
该专题知识库由本体概念库、本体实例库、领域资源库三个部分组成。其中,本体概念库通过本体实例填充的方式与本体实例库关联。领域资源库通过文档自动语义标注的方法与本体实例库和本体概念库相关联。在此基础上,专题知识库可以提供知识检索、知识地图、知识创新等知识服务,以及语义检索、关键词检索、融合检索等领域资源检索方案。
王昊等[ 17]将知识管理模型分成知识采集、知识组织和知识应用三个相互关联的流程。本文在此基础上,结合基于本体的专题知识库模型,提出了一个更具体的基于本体的专题知识库构建流程,主要分6个步骤,如图3所示:
 | 图3 基于本体的专题知识库构建流程 |
(1)知识库范围界定
知识库范围的界定是非常关键的,这深刻影响到后面的知识体系构建,以及领域知识资源的搜集策略。由于知识库一般是面向应用的,因此知识库的范围往往由需求分析得到。
本文在调查国内现有烹饪院校的相关网站的基础上,将中华烹饪文化知识库界定为与中华烹饪美食相关的技巧、文化、历史典故、营养信息等知识与知识文档。其中,知识内容分为五大部分:菜肴、食材、名人、餐馆、技法。菜肴包括八大菜系十六帮别的典型菜品、烹饪技艺、历史典故等知识。食材包括常用食材的特性、科属、处理方法、功能、口味、营养信息等知识。名人包含与菜肴相关的创始人、大厨以及历朝历代相关的帝王将相、文化名流和神话名人等。餐馆则搜集了提供相关特色菜肴的知名老店、老字号,包括它们的地址、招牌菜等信息。技法搜集了与菜肴烹饪相关的常用技巧,如炒、爆、熘、炸、烹、煎、贴、烧等。
(2)领域知识资源采集
领域知识资源有两个用途:为专题知识库填充了领域文档资源;为领域本体概念的搜集提供了文档基础。知识资源的采集应尽可能全面,以覆盖更多的领域概念。
按照知识库范围的界定,确立了领域知识资源的搜集策略。除了中华职业学校提供的相关领域资源,还根据菜肴、食材、名人、餐馆、技法5个大类,分别从互联网、数据库、已有资料文档中搜集相关知识资源,较全面地采集了领域的知识资源,包括与中华烹饪文化相关的典籍(电子书)、论文、报道等。
(3)基于本体的知识体系构建
本体知识体系的构建是整个专题知识库的核心,因为整个知识库建设都是在本体知识体系的指导下进行的。本文中本体知识体系(即概念及概念关系)的构建采用自底向上与自顶向下相结合的方式。即,首先通过搜集的领域文档获取领域的主要概念,其次通过自顶向下的方式整合领域概念,进而识别概念层次、属性、关系等。关于中华烹饪文化知识体系(本体)构建的详细过程参见本专题中《中华烹饪文化领域本体构建及其应用》一文。
(4)本体知识实例填充
这一步工作主要是为前面构建的本体知识体系添加领域实例,以丰富本体库。本体实例填充的方法有多种,本文综合利用了直接手工添加实例、机器批量导入实例以及对文档进行人工语义标注的方式填充领域实例。本体实例填充的详细过程参见本专题中《中华烹饪文化领域本体构建及其应用》一文。
(5)基于本体的领域资源标注
这一步主要是为专题知识库添加领域资源,将之映射到本体知识库。用到的方法是基于本体的文档自动语义标注,即将文档中提及的本体实例与本体知识库中的概念关联起来。
领域文档是领域资源最重要的组成部分,本文中华烹饪文化专题知识库的领域资源标注部分主要以领域文档为例,利用文本工程通用框架GATE实现了基于本体的文档自动语义标注。领域文档自动语义标注的细节参见本专题中《中华烹饪文化领域本体构建及其应用》一文。
(6)知识库服务
在本体知识库构建以及领域资源库标注的基础上,专题知识库可以提供诸如知识检索、知识推理与可视化、文档语义检索等知识服务。
在中华烹饪文化专题库构建的基础上,笔者开发了一个知识检索原型系统,提供本体知识检索、文档资源语义检索等功能。
基于本文构建的专题知识库,可以提供多种形式的知识服务。其中,知识检索是知识库最重要的功能之一,也是其他知识服务的基础。鉴于此,在本体库构建以及领域文档语义标注的基础上,开发了中华烹饪文化专题知识库检索原型系统,包括本体知识库检索和领域资源库检索两大模块。
(1)本体知识库检索
本体检索模块开发了一个检索本体库的知识检索界面。该检索界面提供了相关知识检索的功能,包括实例检索、属性检索、关系检索等。该模块的核心部件使用了Jena,用来对构建好的中华烹饪文化本体库进行解析和操纵。本体的查询语言选择SPARQL,这是目前W3C推荐的本体查询语言。Jena工具包提供了对SPARQL查询语言的支持,可以方便地在开发程序中进行使用。
(2)领域资源库检索
领域资源库检索模块提供了检索专题知识库中领域资源(主要是文档)的接口。这其中包括三个检索选项:文档语义检索、文档关键词检索、文档综合检索。
①文档语义检索模块提供通过语义标注检索领域文档的功能。在《中华烹饪文化领域本体构建及其应用》一文中,详细介绍了利用本体的概念对文档进行语义标注的方法,本文将借助GATE的语义检索API实现对标注文档的语义检索,提供一定的结构化查询功能。
②文档关键词检索模块提供了基于Lucene的全文检索功能。尽管基于本体的文档标注实现了语义层面的匹配,在一定程度上提升了文档检索的查全率和查准率,然而若文档未匹配到本体中的相关实例,则会出现漏检的情况。因此在本体中的资源还不够丰富,以及标注技术尚未成熟的情况下,传统的关键词检索依然起着不可取代的作用。
③文档综合检索模块则整合了文档语义检索与文档关键词检索的结果,对结果根据一定策略进行合并,将最全面的结果展现给用户。
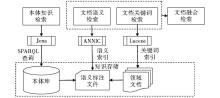
根据系统功能模块的设计,本系统的技术架构如图4所示:
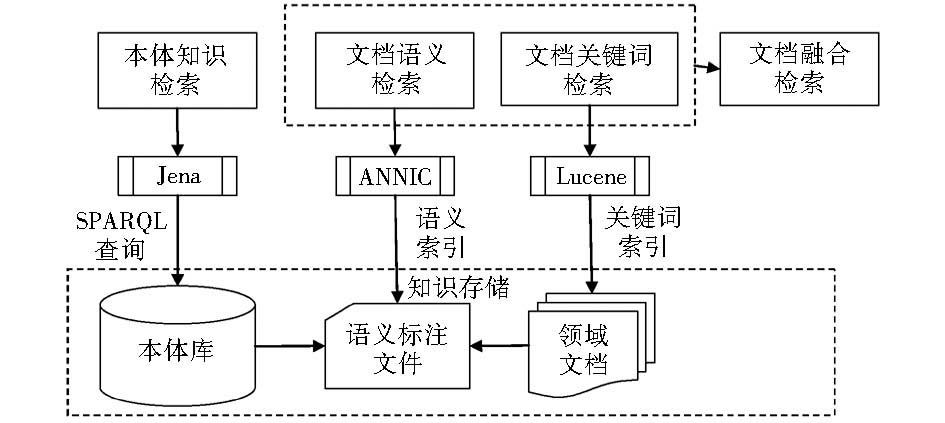 | 图4 中华烹饪文化知识库检索平台技术架构 |
其中本体库检索模块主要运用了Jena语义网工具包和SPARQL本体查询语言;文档语义检索模块主要运用了GATE DataStore的API;文档关键词检索模块运用了Lucene全文检索工具包。由于Lucene全文检索的功能已经比较完善,下面仅对其中涉及的Jena、SPARQL和GATE DataStore API三个关键技术进行详细介绍。
(1)Jena
Jena[ 18]是由惠普实验室开发的开源Java开发工具包,用于语义Web中的应用程序开发。Jena框架提供了操纵RDF、OWL的API,SPARQL查询接口以及推理支持。本文通过导入Jena的jar包,在MyEclipse开发环境中配置了Jena的开发环境。下面将通过几个具体的实例,介绍系统开发中用到的主要的Jena类和接口。
①创建模型
处理语义Web数据的第一步是要找到一个用于访问这些数据的地址。对于Jena来说,一切要从Model对象的创建开始。笔者首先创建了一个使用OWL语言的内存模型,代码如下:
OntModel ontModel= ModelFactory.createOntologyModel(OntModelSpec.OWL_MEM);
②填充模型
在有了对语义Web数据的参考之后,就需要用这些数据来填充模型。填充本体模型的方式有多种,如可以从文件或者URL来填充,也可以通过直接加入陈述来填充,还可以通过其他已经存在的模型来填充。这里选择直接读取OWL文件的方式填充模型。以下代码读取笔者创建的中华烹饪文化本体,若成功则输出“读取本体成功!”。
publicclass OntoHandler2 {
publicstaticvoid main(String[] args){
OntoRead("file:/中华烹饪文化本体.owl");
}
publicstaticvoid OntoRead(String source){
OntModel m = ModelFactory.createOntologyModel();
try{
m.read(source);
System.out.println("读取本体成功!");
}
catch(Exception ex){
System.out.println(ex);
System.out.println("读取本体失败!");
}
}
}
③查询模型
在对模型进行填充后,就可以对本体进行查询、编辑、修改等各种操作。这里演示一个读取某一个类的所有实例的操作。以下代码读取中华烹饪文化本体,并输出苏菜这个类下的所有实例。
publicclass OntoHandler2 {
publicstaticvoid main(String[] args){
OntoRead("file:/中华烹饪文化本体.owl");
}.
publicstaticvoid OntoRead(String source){
OntModel m = ModelFactory.createOntologyModel();
try{
m.read(source);
System.out.println("读取本体成功!");
ResIterator iter = m.listSubjectsWithProperty(RDF.type, m.getResource("http://www.semanticweb.org/dell/ontologies/2012/10/cuisine#苏菜"));
while (iter.hasNext()) {
Resource 苏菜 = (Resource) iter.next();
System.out.println(苏菜.getLocalName());
}
catch(Exception ex){
System.out.println(ex);
System.out.println("读取本体失败!");
}
}
}
程序的输出结果为:
读取本体成功!
三丁包
东海花生
什锦暖锅
全家福
八宝粥
凉拌八爪鱼
出骨八宝鸡
…
(2)SPARQL
SPARQL是SPARQL协定与RDF查询语言(SPARQL Protocol and RDF Query Language)的递归缩写形式,是为RDF开发的一种查询语言和数据获取协议。W3C于2008年1月15日正式把SPARQL作为一项推荐标准。关于SPARQL的详细使用方式,可参考其官方文档[ 19]。下面将结合本文开发中的具体例子,介绍SPARQL查询的用法。
①查询某类的实例.
下面的例子返回的结果与Jena的查询结果相同,即返回所有苏菜的实例。查询语句为:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX cuisine: <http://www.semanticweb.org/dell/ontologies/2012/10/cuisine#>
Select ?x where {?x rdf:type cuisine:苏菜. }
返回结果为:
三丁包
东海花生
什锦暖锅
全家福
八宝粥
凉拌八爪鱼
出骨八宝鸡
…
②查询某个实例的某个属性
下面的例子查询与“霸王别姬”这道菜相关的名人,返回的结果是“刘邦”“项羽”“虞姬”。查询语句为:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX cuisine: <http://www.semanticweb.org/dell/ontologies/2012/10/untitled-ontology-11#>
Select ?mingren
where{ cuisine:霸王别姬 cuisine:有相关名人 ?mingren}
返回结果为:
刘邦
项羽
虞姬
(3)GATE DataStore API
GATE中提供了一个用于存储并索引标注文档的DataStore API,同时提供了检索该标注文档的API,即ANNIC(ANNotations-In-Context)。ANNIC是一个功能齐全的标注索引和检索系统。
ANNIC可以索引GATE系统支持的任何形式的文档包括XML、HTML、RTF、E-mail、Text等。和其他查询系统相比,它具有一些额外的特征如可以对文档内容的语义信息进行全方位的索引,且独立于文档形式。同时,它还支持从重叠的标注和特征中抽取和索引信息。ANNIC是建立在Lucene全文检索框架的基础之上的。ANNIC改造并定制了Lucene,使其支持语义标注的索引和查询。关于这一过程的实施细节可以参考文献[ 20]。
本系统利用ANNIC API实现了对GATE标注结果的索引,而无需重新编写语义标注的索引,大大方便了原型系统的开发。
本文的本体构建与本体语义标注所使用的工具大都是利用Java开发的开源工具,为了让系统可以跨平台运行,中华烹饪文化知识库检索平台原型系统采用纯Java的开发环境。本系统的运行环境和主要开发工具如表1所示:
| 表1 系统的主要开发工具 |
 | 图5 中华烹饪文化专题知识库检索原型系统主界面 |
系统提供了本体知识库检索与领域资源库检索两大模块。其中本体知识库检索提供了以下功能:菜肴查询、食材查询、名人查询、餐馆查询、技法查询、实例查询、属性查询、关系查询。领域资源库检索模块提供了文档语义检索模块、文档关键词检索模块以及基于两者融合的文档综合检索模块。
(1)本体知识库检索
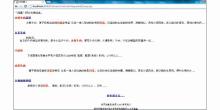
本体知识库检索从功能的角度提供了菜肴查询、食材查询、名人查询、餐馆查询、技法查询、实例查询、属性查询、关系查询等功能。以查询菜肴的属性为例从本体技术的角度展示本体知识库检索的功能,如图6所示:
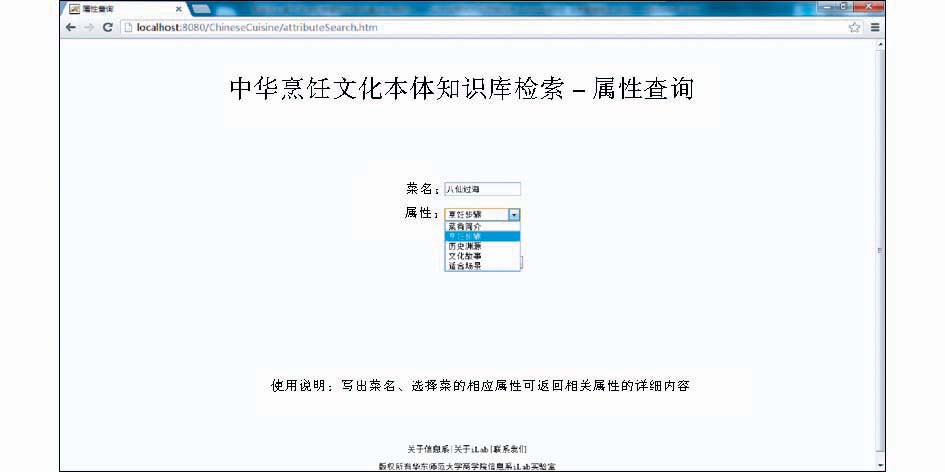 | 图6 属性查询示例 |
图6显示了查询菜肴属性的界面,下拉列表展示了菜肴的常见属性,包括菜肴简介、烹饪步骤、历史渊源、文化故事、适合场景。查询结果返回了“八仙过海”这道菜的烹饪步骤的详细描述。
(2)领域资源库检索
领域资源库检索提供了语义检索、关键词检索、综合检索三个选项。以检索“川菜”为例,三种方法返回了不同的结果。语义检索的结果中,所有包含川菜实例的文档均被检索出来,如包含“水煮牛肉”、“干烧鱼”、“水煮肉片”的相关文档。关键词检索的结果则仅返回了包含“川菜”关键词的文档。若本体中没有或者只有很少的实例,语义检索可能返回不完全的结果,这时候需要融合关键词检索的结果提供综合的检索结果。目前的综合检索策略是将语义检索和关键词检索的结果进行合并后去重,且将语义检索的结果排在前面,如图7所示:
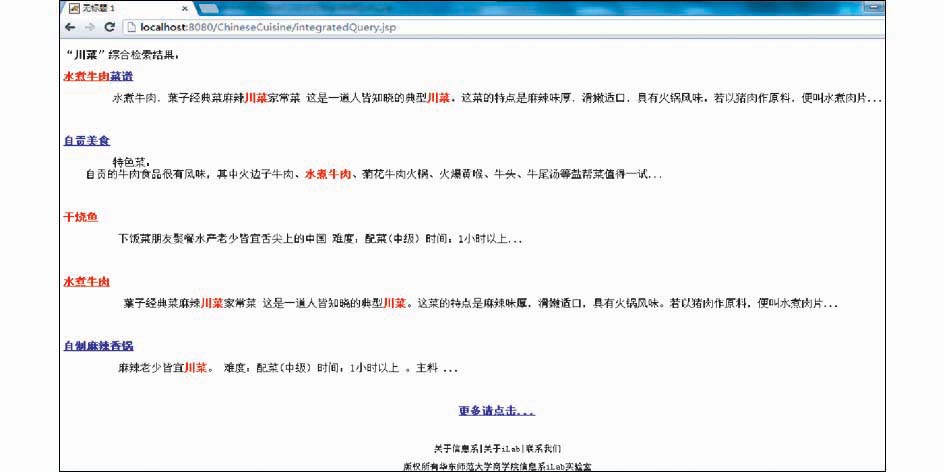 | 图7 查询“川菜”的综合检索返回结果示例 |
本专题中《利用领域本体优化文档检索的研究——基于KIM平台的设计与实现》一文则详细探讨了进行合并排序的策略。
本文在分析现有的基于本体的知识库模型以及专题知识库构建的缺陷的基础上,提出新的基于本体的专题知识库构建模型。该专题知识库既包含本体库,又包含与之对应的领域资源库。以中华烹饪文化领域为例,详细探讨了本体指导下的专题知识库构建流程与模式。在此基础上,利用相关开发工具,开发了中华烹饪文化知识库检索原型系统,详细介绍了其知识检索、文档语义检索等功能,验证了基于本体的专题知识库模型的有效性。
尽管实现了一部分功能,本文还存在许多不足。如中华烹饪文化知识库本体规模还较小,本体的实例有待进一步填充。另外,由于缺乏公开的语料集,因此本文基于本体的文档检索系统尚未通过大规模的检索实验。
基于本体的专题知识库构建中涉及的领域知识建模、语义标注技术等都是相对比较复杂的技术,如何将本体更好地用于专题知识库的构建还有许多问题待进一步深入研究,如本体建模的自动化、语义标注的智能化、知识库质量控制、知识库知识发现与可视化应用等。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|