
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用领域本体优化文档检索的研究* ——基于KIM平台的设计与实现
[金碧漪1 , 郭金龙2 , 许鑫1  ]
]
]
|
|


提出本体实体的语义标注策略。为验证此策略对于文档搜索结果的优化效果,借助于KIM平台,利用中华烹饪文化领域本体,首先将文档中实体与本体知识库中实例相互映射实现语义标注,接着通过索引用户查询条件与实例来实现语义查询,最后对结果进行测评,并融合关键词搜索结果对文档结果进行排序。研究表明基于本体的实体标注策略所达到的文档语义搜索能实现较良好的文档检索效果。
This paper proposes the strategy of entities label annotation based on Ontology. In order to verify the effectiveness of this strategy, by means of KIM platform, this paper uses Chinese cuisine culture domain Ontology as experimental data, mapping entities in document to the instances in Ontology knowledge base to achieve semantic annotation firstly, and then indexs the user query with instances to achieve the semantic retrieval. At last, the experimental results are evaluated. The study shows that the proposed strategy has a better performance on document retrieval.
随着全球信息化建设的力度加大,互联网上的信息资源呈现指数级的增长趋势,如何使用户在海量信息中快速而准确地找寻到所需信息,已成为一个非常有必要解决的问题。因此提升信息检索技术已经成为全世界范围内的热点和重点问题。传统关键词检索虽有简单、便捷的优点,但存在“言不达意”、“词汇孤岛”、“表达差异”、“机械匹配”等几方面明显的问题[ 1, 2],尤其体现在文档的检索结果上。所以,难以良好地解决网络信息量激增与用户对高质量文档需求之间的矛盾。针对此问题,有学者将本体概念引入检索领域,提出了语义检索。本体具有良好的层次概念结构和逻辑推理支持性,而领域本体更是对领域内知识概念与关系做了更精准的概括,基于领域本体的语义检索相对于关键词检索来说具有更加良好的检索效率,在文档的查全率与查准率方面都有比较大的提升。
本文从实践的角度,通过实验将中华烹饪文化领域本体映射至KIM平台的顶级本体系统中,研究了基于领域本体进行文档信息检索的关键技术,最后对文档检索效果进行测评,并指出不足。
在传统网络信息资源检索方法的局限下,越来越多的国内外学者将关注点投向了各自相关研究领域中文档语义的挖掘上,把领域本体引入检索之中。例如 Kara等[ 3]开展了基于本体的信息提取和检索系统在足球领域的应用; Kawtrakul[ 4]采用本体构建、信息抽取的方法实现了一个农业领域的服务系统;杜建等[ 5]则研究了生物医学领域的语义检索机制。各个领域都有研究的范例,如学习教育领域[ 6, 7]、政务信息领域[ 8]、旅游信息领域[ 9]等。
而在基于领域本体的语义检索系统实现时,不同的研究采用不同的本体处理策略:
(1)基于本体的查询处理。文献[ 6, 7, 8, 9]都是获取查询条件的中心词,将本体作为词表引入查询条件的处理过程中,通过其所蕴含的同义、整分、上下位等词汇关系来实现查询扩展和消歧。
(2)基于本体的概念标注。文献[ 10, 11, 12]通过将文档的特征词汇与本体的概念词汇进行映射的方法来实现语义标注。
(3)基于本体的三元组规则标注。荆涛等[ 13]以三元组的表示方法将文档词汇与本体的映射关系通过本体桥表示出来,实现了文档间词汇关系的标注。
(4)基于本体的实体标注。Vallet等[ 14]以开发完全的本体和知识库(Knowledge Base, KB)为基础,利用本体和实例共同建立文档与实体之间的标注关系。
以上4种策略都为实现成功的语义检索提供了方法。基于本体的查询处理,虽然扩充丰富了查询条件,提升了检索的查全查准率,但却没有真正实现语义匹配检索,且过度扩展易造成检索效率低下。基于本体的概念标注是在语义标注时多数研究者选择的方法,做到了一定程度的语义匹配,但在文档词汇的属性、词汇与词汇之间的相互关系的标注上有欠缺。而基于本体的三元组规则标注方法则较好地实现了文档层面的语义推理,然而该方法对信息抽取的要求较高,不适用于对大规模文档集的三元组抽取。基于本体的实体标注策略利用本体和知识库中定义好的实例来表征文档内容,涵盖了文档词汇概念、属性、相互间关系,而文献[14]缺乏此策略在中文上的应用,也没有体现在某个具体领域。
本文在比较以上几种策略基础上,综合考虑了领域特点、技术的可实现性、本体的利用程度,提出了基于KIM平台结合本体的实体标注方法来构建中华烹饪文化领域的检索平台。
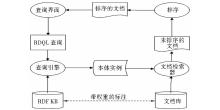
根据方案设计的总体思路,关键的4个环节为:
(1)领域本体构建和完善环节
实验中最为基础的一个环节,领域本体结构层次的完善合理、实例知识库中实例知识的丰富都为其他环节的运行提供依据。
(2)基于本体的实体语义标注环节
将采用基于本体对文档中的实体概念、概念属性、概念间关系进行标注索引的策略。本质上是把文本中出现的实体与本体知识库中的实例对应起来。实体也称命名实体(Named Entity),指人名、机构名、地点名以及其他所有以名称为标识的实体,此概念是从文档角度出发。而实例是指本体知识库中具体某类下面的例子,此概念是从本体角度出发。例如,“苹果即将发布操作系统ISO 7”一句中通过实体标注后,对应到知识库的实例中,能自动识别出这里的“苹果”为一家公司,包括其地点属性、员工属性等都将一一被识别出,而非一种水果。
(3)基于本体的实体索引环节
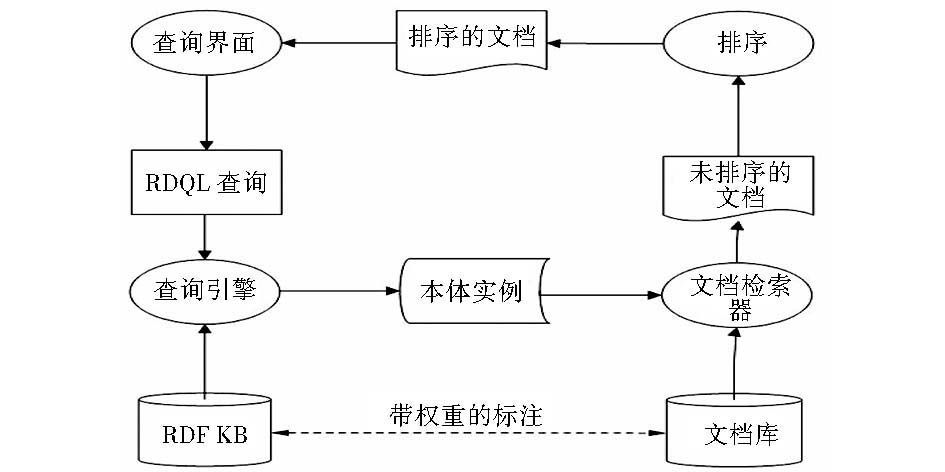
在对文档中的实体标注完成的基础上,用户可以通过复杂的语义组配进行实体或者文档的索引查询。与传统的关键词查询不同,用户在查询时可以定义类似“在某组织拥有某头衔的某人”这种复杂的提问。在索引过程中,系统将用户在查询界面所输入的条件转换为RDQL语言后,与本体知识库中的实例相匹配,若存在成功匹配,则将实例与文档库中的文档标注相匹配,返回相关文档。
(4)基于语义的检索结果排序环节
在排序环节的设计上,将采取语义检索结果与关键词检索结果相融合的方法,原因是虽然语义检索能良好解决关键词检索的各种问题,但是语义检索的效果直接受文档中实体标注的完善程度所影响,因此在有大量文档结果出现时,有必要对这两种检索模式下的检索结果进行融合排序,将与用户查询条件相关度从高到低返回给用户,优化文档检索效果。
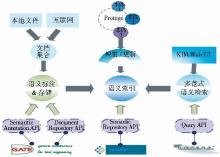
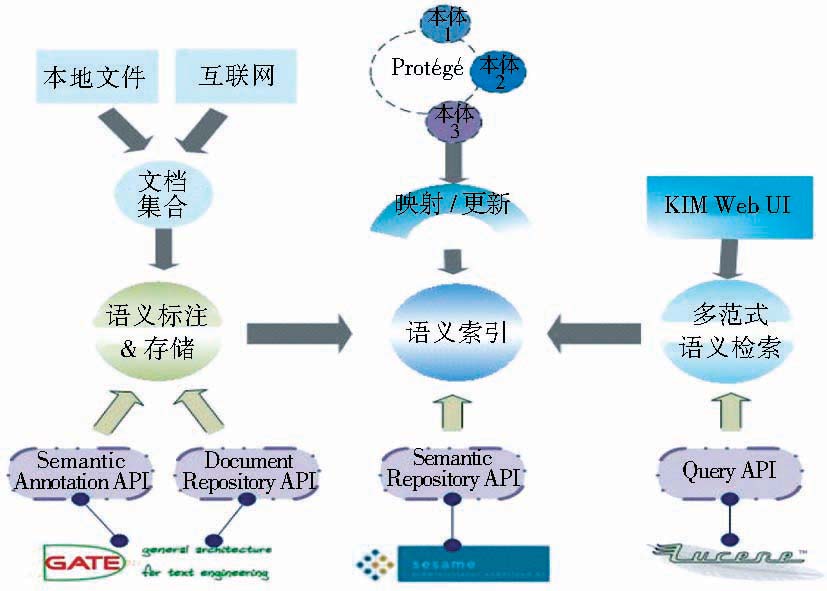
KIM(Knowledge and Information Management)是OntoText实验室开发的一个集语义标注、索引与检索功能为一体的语义检索平台[ 15]。KIM平台语义标注的原理与本文前面介绍的原理基本一致,即利用一个通用的上层本体(KIMO)以及相应的实体知识库(KB)对文档进行标注。
选择KIM平台作为实验平台主要基于以下三点考虑:
(1)KIM信息抽取策略在通用实体识别方面达到了较高的精度,如对Date、Person、Organization、Location、Percent、Money等通用实体类别识别的平均F值分别达到93.63%、90.87%、71.30%、89.77%、97.69%、98.72%[ 16]。
(2)KIM平台是一个强大的开源平台,体现在以下三个专门领域:RDF(S)存储库、信息抽取(IE)和信息检索(IR)。这三个领域的技术实现分别架构在Sesame、GATE和Lucene这三个开源项目上,因而可以根据实验需要定制规则,有利于实验展开。
(3)KIM的本体Proton作为上层本体,具有可扩展性,可较为简便地将本实验的领域本体映射进来,并基于新映射的领域本体进行标注与检索。
在中华烹饪文化本体数据的基础上,本文尝试构建一个语义搜索平台,将零散的烹饪文化知识组织起来,供用户查询搜索,一方面为本文的研究提供实验数据,另一方面让用户对中华烹饪文化有进一步的认识。
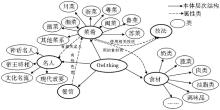
本文选用中华烹饪文化本体,其具体构建方法与流程参见本专题中《中华烹饪文化领域本体构建及其应用》一文。中华烹饪文化本体分为以下5个大类:菜肴、食材、技法、名人、餐馆。此实验本体的类和属性部分展示如图3所示:
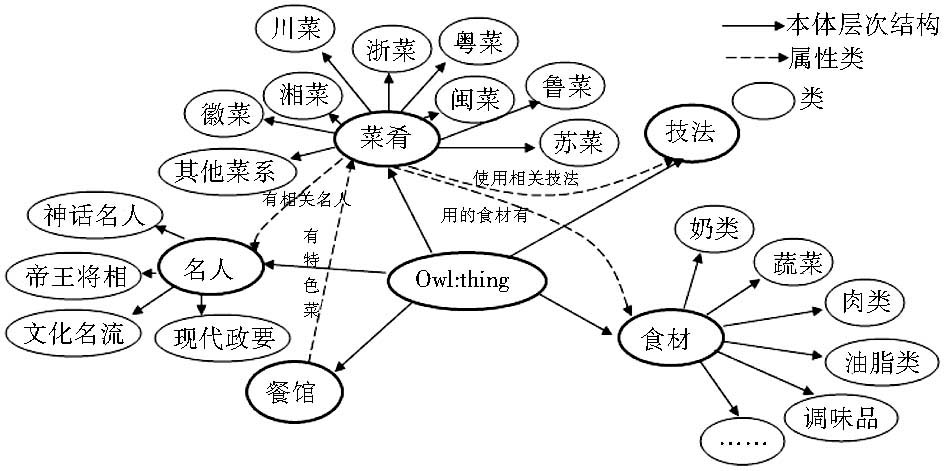 | 图3 烹饪文化领域本体部分展示图 |
(1)领域本体添加.
基于本实验的设计意图,需要将已经构建完成的领域本体映射到Proton里,具体配置方法可参照KIM的说明文档[ 18]。需注意统一UTF-8的编码格式,并且将类名、属性名等全部用英文字母来表示,这样KIM才能正确识别。部分代码如下:
<!--http://www.semanticweb.org/dell/ontologies/2012/10/
untitled-ontology-11#Zhecai -->
<Class rdf:about="&untitled-ontology-11;Zhecai">
<rdfs:label>浙菜</rdfs:label>
<rdfs:subClassOf rdf:resource="&untitled-ontology-11;dish"/>
</Class>
(2)本体实例扩充
在成功添加新的本体之后,需要向KIM的知识库中填充领域本体的实体。为了能让新添加的本体实体被KB识别,这些实体需要满足三个条件[ 18]:是protons:Entity的子类;有至少一个别名;来自于一个可信的来源。在本实验中,其具体的配置代码片段如图4所示,描述的是粤菜的一个实例:菠萝咕咾肉,用label来表达词实例的名称,用hasAlias的属性来表达此实例具有别称,可以将不同的名称指向同一实例。
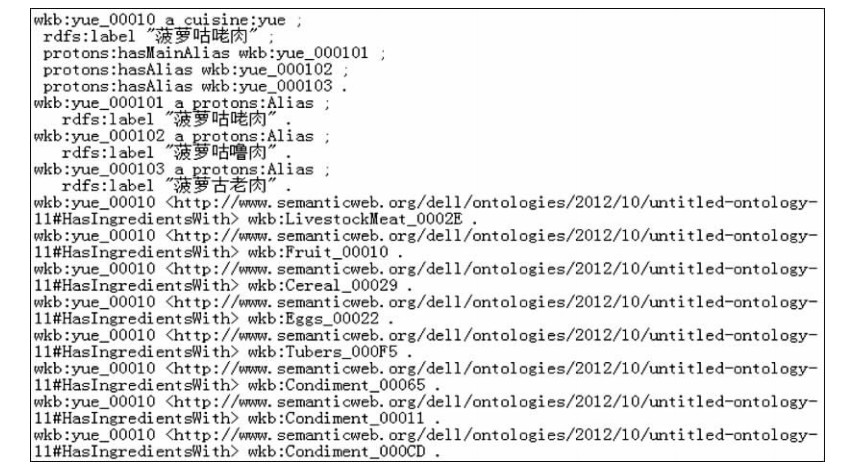 | 图4 实例文件部分代码 |
(3)实体语义标注配置
KIM的信息标注与抽取核心组件是基于GATE之上的,预先定义好了针对Proton各类的信息抽取的规则。其核心是Gazetteer和JAPE两个组件。Gazetteer的功能是将本体中的实例转换成GATE可处理的词典格式;而JAPE则是GATE中添加语义识别规则的工具。关于两者配置的详细过程可参考GATE相关文档[ 19]。本文利用KIM自动为新添加的实体和文档之间创建标注的方法为说明新的实体是Proton中某类的子类,并被标为可信实体。代码如下:
@prefix protont: <http://proton.semanticweb.org/2006/05/protont# >
@prefix cuisine: <http://www.semanticweb.org/dell/ontologies/2012/10/untitled-ontology-11# >
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema #>.cuisine:Cuisine rdfs:subClassOf protont:Object.
实验准备包括实验的本体和文档数据准备。本体数据准备已在前文做了说明,而在文档数据准备阶段,首先从网络资源(包括电子书、美食博客、美食网站等)筛选下载了200篇与中华烹饪文化相关的中文文章,包括“菜谱”、“各地美食攻略”、“美食故事”和“食材介绍”4个方面的文档各50个。以这200个文档内容和美食网站上的分类为基础,在KIM本体库和本体知识库中创建并定义了中华烹饪文化本体的50个类和188个实例。
接着,重新下载了540个网络文档,对这740个文档网页进行去除HTML标签等网页预处理工作,得到纯文本的.txt文件。然后,使用中国科学院计算技术研究所分词系统ICTCLAS[ 20]对这740个文档进行分词与词性标注处理。最后,将分词后的文档进行最后的处理,转换为KIM可识别标注的格式,利用KIM自带的Populater工具对测试文档进行自动语义标注,并在客户端的界面上进行文档检索实验。
实验过程用4.4节的配置方法进行配置,配置完成后启动KIM,便可实现语义检索。本实验的语义检索界面由结构化检索界面来展示,主要实现类查询和属性查询。
(1)类查询是指直接查询例如“川菜”、“调味品”等某类下的所有实例或所有相关文档,当然也可以直接精准查询某一实例,例如查询名称中包含“豆腐”的某菜肴。
(2)属性查询可以满足用户更加具体复杂的查询需求,包括类属性限制查询、类和类间的关系属性限制查询。
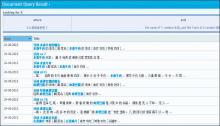
(3)也可将两种属性查询结合起来定义更加复杂的条件,比如查询某使用了“牛肉”食材的口味为“麻辣味”的菜肴,可以查询得到相应符合查询条件的食材名称或是菜肴名称及提到它们的文档。此例的文档查询结果如图5所示:
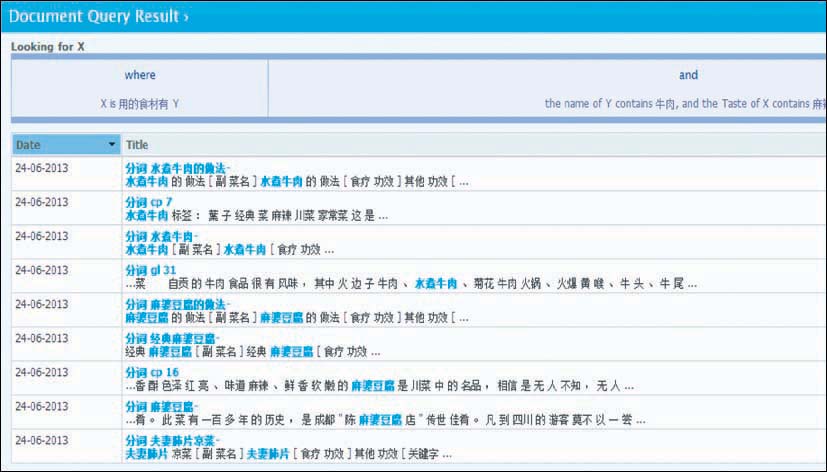 | 图5 文档查询结果界面 |
为了测试本文基于本体的文档语义检索的检索性能,在此引入查全率和查准率两个指标来进行与基于关键词的检索方案的对比测试说明。在关键词检索部分,选用Lucene3.6[ 21]的核心组件,在MyEclipse10的开发环境下,对这740个文档数据进行全文搜索。选定4组不同情况下的查询条件,查询结果的查全率、查准率以及F值对比如表1所示:
| 表1 基于本体和基于关键词的查询结果测评 |
而4组查询条件分别是:查询介绍川菜菜肴的文档、查询提到“红薯”的文档、查询以“鸡蛋”为食材且口味为“咸鲜”味的菜肴文档和查询以“豆瓣酱”为食材的菜肴文档,而具体的查询内容和结果如表2所示:
| 表2 4组查询条件内容及查询结果对比 |
本文的排序算法借鉴空间向量模型(SVM模型),将文档看成由各个权重不同的实例组成的特征向量。权重的计算根据实例在每篇文档中出现的频率,结合TF-IDF算法[ 19],计算公式为: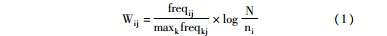
其中,Dj表示文档j, Ii表示某文档j中被标注出来的实例i,freqij表示在Dj中Ii的出现频次,maxkfreqkj则表示Dj中出现次数最多的Ik的频次,ni是带有Ii标注的文档数,N则是总共的文档数量。
相似地,将查询条件看作由权重不同的查询实例组成的查询向量。
在文档排序算法中,文档的排序优先性由该文档与查询向量的相似性来决定,相似度越高,排序越靠前。语义相似度的计算方法为: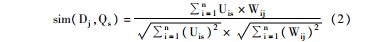
而当本体知识库中的实例数量有限或者某些标注失败时,语义检索的效果也会很差。在这种情况下,本文认为将关键词检索结果融入,综合计算文档与查询条件之间的相似度得分后再进行文档排序,能更好地为用户返回高相关性的文档结果。因此,最终的语义相似度得分的计算方法如下: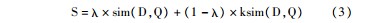
明显地,sim(D,Q)为基于本体实体的文档和查询条件之间的相似度,而ksim(D,Q)为基于关键词的文档和查询条件之间的相似度。λ∈[0,1],λ的值可视具体情况而定。
本实验以查询口味为“辣”的以“牛肉”为食材的文档为检索实例来演示排序算法。Q=(牛肉,辣),语义检索得到12篇文档,关键词检索得到17篇文档。查重后,得到共24篇文档。对这24篇文档依次进行相似度计算,λ取值为0.5,原因是知识库中实例的完善程度并不高。前15位的文档结果及其相似性得分如表3所示:
| 表3 文档语义排序前15篇结果 |
相较于关键词搜索,基于本体的文档检索策略能够优化文档搜索的关键在于让知识库中显性知识的概念、分类、结构、关系、规则等,与文档中相对应的知识产生映射,从而让文档较好地“被理解”,进而让索引器能够按照用户的需求去检索文档,呈现出让用户较为满意的检索结果。
从实验结果来看,与关键词检索相比,本文实验在以下几点实现了文档检索的优化:
(1)在查询某类的实例时有较好的查全率。查询条件1的对比结果验证了这一点,“川菜”二字即使不出现在文档中,只要出现被标注为“川菜”的词的文档也会被检索出来。
(2)在查询有多个别名的实例时有较好的查全率。“红薯”又可称为“地瓜”、“洋芋”,增强了文档中多个别称指向同一实例的查全率。
(3)在查询某上位概念类时有较好的查全率。举例来说,查询“食材”,返回的文档中包含有食材类下的子类:蔬菜、水产品等各类的实例。
(4)在用结构化查询条件时有较好的查准率。结构化的查询语句允许用户对查询需求进行更加细致准确的描述。例如,查询“用到五花肉为食材的菜肴”,而在关键词搜索中做不到这样具体的需求的表达。
(5)利用本体的分类结构有较好的查准率。在本体结构中,实例有明确的类别归属,例如在用户查询“霸王别姬”的菜肴时,返回的文档都是与这道菜肴相关的文档,而非有关于电影或者其他的文档。
基于本体的语义查询在查全和查准率上都比基于关键词要有所提升,但仍存在缺陷,具体体现在查询条件4的表现上。可能的原因有:
(1)烹饪领域本体本身的问题。实例在地域、文化各种影响下其称呼有很大的不一致性,并且很多菜肴的做法也有很大不同,故而为知识库填充增加难度,进而导致语义查全查准率不高。
(2)实验操作中存在不足。信息抽取规则不够完善,KIM的抽取规则主要适用于英文,在中文的表现上存在不足。
本文致力于探索基于本体的实体标注策略对文档搜索的优化效果,设计并实现了一个借助于KIM平台,利用烹饪文化领域本体及其知识库,对文档进行标注索引,并将索引结果融合关键词索引结果进行语义排序的实验,根据实验结果及讨论分析得出了以下结论:基于本体的实体标注策略所达到的文档语义检索的效果能够有效地优化文档检索。有两个重要影响因素:本体和知识库中本体类和实体语义描述的丰富程度、语义标注的完善程度。将基于本体的语义检索与关键词检索结果融合能很大程度上弥补本体知识库中本体实例不足的弊端。经过语义排序,将与用户查询条件最为相关的文档返回给用户,也弥补了查准率不如人意之处——相关程度较低或是误检的文档被排在后面。本文为构建更加精确的文档检索系统提供了可行方法,对提升检索效率具有现实意义。
当然,本文的实验探索也存在诸多不足。比如,本体知识库内容不足,即预先定义好的本体类、属性数量及知识库中实例数量规模偏小;实验平台KIM本身是英文的系统,如果能将其本身定义好的通用本体汉化,结合领域本体,将能更好地标注文档。不足之处还包括本文的信息自动抽取规则还不完善,主要依赖于KIM本身定义好的信息抽取规则,缺少针对领域特点的定制化的中文信息抽取规则的补充及定义,希望能在后续的研究中逐步完善。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|