











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用作者关键词网络探测作者相似性*
[刘萍 , 郭月培
, 郭月培
, 郭月培|
|


准确识别作者研究内容的相似度,是探测学科知识结构和挖掘潜在合作关系的重要基础工作,也是近年来图书情报学的研究热点。现有的相似度计算方法大都依赖于属性的直接关联,忽略属性间的间接关联。提出一种新的基于作者关键词网络的作者相似度计算方法,通过向量空间模型计算出关键词之间的关联度,再利用图结构相似度算法P-Rank挖掘出作者间的间接关联关系。初步实验表明该方法能够有效地识别作者之间的相似度,相比于传统的关键词耦合和向量空间模型算法,该方法可以明显地提高作者相似度计算的准确性。
Accurately measuring the authors similarities is the fundamental work of detecting disciplinary knowledge structure and mining potential cooperative relationships, it is one of important research issues in library and information science. Current approaches rely on direct associations between properties,and the indirect associations between properties are ignored. This paper proposes a new measurement of authors similarities based on author-keyword network. Firstly the relatedness of keywords are calculated based on Vector Space Model, and then structure similarity algorithm P-Rank is used to calculate the similarities between authors.The initial experiment demonstrates the effectiveness of the proposed approach. Compared with keyword-coupling method and Vector Space Model method, this approach obtains more meaningful results.
作者相似度计算在学科知识结构探测[ 1]、社区划分[ 2]、挖掘潜在合作关系[ 3]等方面有广泛的应用,一直以来都是图书情报领域的重点研究问题。围绕这个问题,国内外研究人员已经展开了大量的研究工作,提出了许多计算方法,如作者共被引分析、作者文献耦合分析、作者关键词共现分析等。然而现有的作者相似度算法都是通过属性间的某种直接关联(如引用了相同的文章或标注了相同的关键词)来计算作者间的相似度,忽略了属性间的间接关联。本文提出一种新的基于作者关键词网络的作者相似度计算方法,在关键词关联度的基础之上,利用图结构相似度算法P-Rank挖掘出作者间的间接关联关系。通过选取武汉大学信息管理学院的学者作为对象进行实验,验证该算法能够更准确地识别作者之间的相似度。
研究人员从不同的角度,提出了不同的定量化方法来计算作者相似度,其中受到较多认可的有4种基本方法:合著分析(Co-authorship Analysis)、作者共被引分析(Author Co-citation Analysis)、作者文献耦合分析(Author Bibliographic Coupling Analysis)和作者关键词分析(Author Keyword Analysis)。
合著分析是通过作者之间的合著关系来研究作者相似度的一种方法。Ding[ 4]研究了信息检索领域中高产作者和高被引作者在合著倾向(如倾向于研究兴趣相同的作者合作)以及引用行为上的不同。Liu等[ 5]构建了数字图书馆领域的作者合著网络。虽然合著关系可以直接地反映作者关系,但是它更多地反映出学者之间的社会关系而远不止是学术结构[ 6]。
作者共被引分析由Small[ 7]在1973年首先提出,随后被大量地应用于相似度度量研究中[ 8, 9]。其思想是:两个作者发表的文献被相同文献引用的次数越多,则这两个作者的研究内容越相似。与此相对应,作者文献耦合分析的思想是:两个作者引用的相同文献数越多,则他们的研究方向越相近。作者文献耦合是Zhao等[ 10]在2008年首次提出的,是在原有的文献耦合[ 11]基础上做出的改进,使其应用于描述作者的研究内容。将引文分析用于作者相似度测量虽然被许多学者认同,但是由于受作者引用某一文献的引用动机、引用深度等影响[ 12],其计算结果有时会出现偏差。此外,一篇文献发表后需要经历一定的时间才被他人引用,因而通过作者共被引来计算相似度是有时滞的,无法反映出最新的结果[ 13]。而作者文献耦合方法考虑的是两个学者引用相同的参考文献数量,而忽略了文献内容的关联性。
上述几种方法均是通过文献外部特征进行作者相似度测度,与之对应的途径是分析文献内部信息,重点在于对关键词的分析。较合著和引文分析,关键词能更直观地反映出文献内容和学者的研究兴趣,从而揭示出不同作者之间的学术关系[ 3]。基于关键词的作者相似度计算方法有两种:第一种方法是将作者所标引的关键词集合作为对该作者的虚拟描述文档,从而利用传统的文档相似度计算方法(如向量空间模型[ 14])来对作者相似度进行测量;第二种方法是作者关键词耦合分析[ 15],该方法类似于作者文献耦合分析,是利用作者文献集关键词的耦合强度来分析作者间的关系。这两种方法虽然针对文献内容进行了分析,但都假设了词语的独立性,也就是未考虑词语之间的语义关联[ 16],因而不能准确识别那些研究主题相似但使用了不同关键词的作者关系。
鉴于上述方法的局限性,本文借鉴关联网络[ 17, 18]的思想来解决作者相似度的计算问题。关联网络的思想是:被相似实体指向的实体是相似的,同时指向相似实体的两个实体也是相似的。目前已有一些学者利用此思想来研究网页的相似度[ 19, 20, 21],本文将其应用于作者相似度的计算研究中,思想是:指向相似关键词的作者也是相似的。
本文通过作者-关键词关系构建作者的关联网络,以测度关键词间的相关程度和作者间的相似度。基于作者关联网络的相似度计算流程如图1所示:
 | 图1 基于作者关联网络的相似度计算流程 |
(1)构建作者表示模型。对于每个作者Ai,基于关键词的表示模型为:Ai={(k1,Wi1),(k2,Wi2),(k3,Wi3),…,{kn,Win)},其中{k1,k2,…,kn}为作者发表文献中所使用的关键词集合,而{Wi1,Wi2,…,Win}为对应关键词的权重,这里设为关键词出现的频率,未出现则为0。
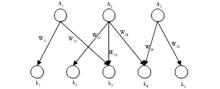
(2)作者-关键词关联网络构建。整个作者-关键词关联网络可以表示为一个有向的、带权重的异构网络图G=(V,E)。其中V是两种节点的集合,即V=V1∪V2,V1为作者集合V1={A1,A2,…,An},V2为关键词集合V2={k1,k2,…,km}。当一个作者Ai在一篇文章中使用了一个关键词ki,则表示从该作者到该关键词有一个有向的链接,即从Ai到ki有一条边,边的权重Wii为该作者Ai在其所有文章中使用关键词ki的次数。图2展示了一个由3位作者{A1,A2,A3}和5个关键词{k1,k2,k3,k4,k5}构成的作者-关键词关联网络。
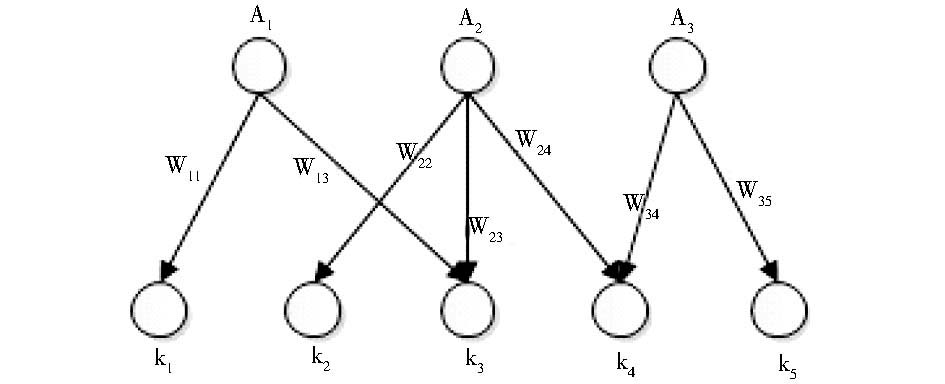 | 图2 作者-关键词关联网络图样例 |
(3)关键词间关联度的计算。关键词之间不是相互独立的,它们之间存在一定的语义关系。如果两个词被很多作者同时使用,就认为这两个词之间的关联很紧密。关键词间的关联度可以通过向量空间模型进行计算,具体计算方法将在3.2节中详细论述。
(4)作者相似度计算。根据作者-关键词网络计算作者相似度的基本思想是:同一个类型的两个对象,如果经常连接到相似的其他对象,那么这两个对象的相似性应该很高。在得到关键词间关联度的基础上,引入P-Rank[ 18]的计算公式来得到作者之间相似度。详细计算方法将在3.3节中论述。
从所构建的作者-关键词网络中,可以通过关键词的入链信息,得到每个关键词被哪些作者使用及其使用频次。根据这一信息,将关键词作为描述对象,用指向该关键词的作者和对应边的权重对该关键词进行描述。如关键词ki可以表示如下: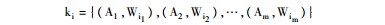
将所有关键词进行描述,即可得到一个关键词-作者矩阵。根据这一关键词的表示模型,可以运用向量空间模型对关键词间的关联度进行计算。
将每个作者当作空间向量中的一个维度,每个关键词对某一作者的权重即为在其对应维度上的值。为了使计算结果更为准确,本文不直接将词频作为对应维在每个作者维度上的值。
用k表示关键词实体,A表示作者实体,Vk表示关键词集合,VA表示作者集合,CAi,kj表示关键词kj对作者Ai的重要度。根据余弦相似度算法,当1≤i,j≤|Vk|,关键词ki和kj间的关联度计算公式如下:
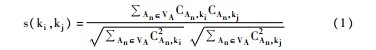
重要度CAi,kj的计算方法来源于TF-IDF思想,所谓重要度,即其值越高,则说明这个关键词对某作者的重要性越大,则越能代表该作者的核心研究内容。重要度可以从两方面体现:使用次数,作者使用某关键词的次数越高,则这个词对他的研究就越重要;该词占某作者使用关键词总数的比例,所占比例越大,则对该作者来说重要性就越高。根据这两个方面,将重要度C的计算方法定义如下: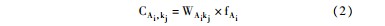
其中,WAikj,为作者-关键词网络中作者Ai指向关键词ki的边的权重,即作者Ai使用关键词ki的频次,fAi表示关键词ki占作者Ai使用的关键词总数的比例。fAi的具体计算方法如下: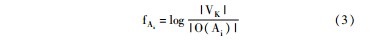
其中,|O(Ai)|表示作者Ai的出链个数,即作者Ai总共使用的关键词个数;|VK|为关键词总数。公式(3)是由TF-IDF算法中的倒排文档频率(IDF)思想类比而来。一个作者使用的关键词总数越多,他的关键词分布越广泛,则每个关键词对该作者的重要度就越低。反之,一个作者使用的关键词总数越少,则每个关键词占其关键词总数的比例就越大、对该作者的重要度就越高。
P-Rank[ 18]是一种利用图的结构信息计算对象间相似度的算法。P-Rank算法是在SimRank[ 17]基础上提出的改进算法。SimRank的基本思想是:被相似的两个实体指向的两个实体也是相似的。也就是说,两个节点间的相似度由这两个节点的入链邻节点间的相似度决定。由于SimRank存在有限信息问题,P-Rank算法在SimRank的基础上进行了改进,将出链信息也纳入相似度计算的信息来源,即被相似实体指向的实体是相似的,同时指向相似实体的实体也是相似的。设a和b为两个不同的实体,a,b之间的相似度可以计算如下[ 18]:
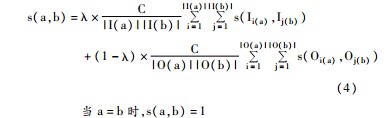
其中,入链和出链的相对权重由参数λ∈[0,1]调节。C是衰减系数。当入链(出链)部分无法计算时,只有出链(入链)部分对结果产生影响,反之亦然。
对于本文构建的作者-关键词网络而言,所有边都由作者指向关键词,因此作者只有出链没有入链,在使用P-Rank计算作者相似度时取λ=0。此时,作者所指向的关键词间的相似度决定作者间的相似度,而这个关键词间的相似度即为3.2节中所计算的关联度。令s(Ai,Aj)表示作者Ai,Aj间的相似度,则当Ai≠Aj时:
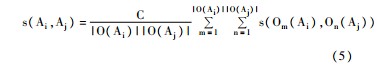
其中,s(Om(Ai),On(Aj))表示作者Ai,Aj所指向的两个关键词间的相似度,即通过向量空间模型计算得到的关键词关联度。通过公式(5)计算得到的结果即为基于关联网络的作者相似度。
(1)数据收集
选取的实验对象是武汉大学信息管理学院的学者。该院一共有72位教师(含退休教师),在组织结构上划分为5个系(图书馆学系、信息管理科学系、档案与政务信息学系、出版科学系、信息系统与电子商务系)和两个中心(信息资源研究中心、中国科学评价中心)。
为获取每位教师使用的关键词,选取中国知网全文数据库和维普数据库作为数据来源,以作者为搜索项(以第一作者为主),通过教师姓名进行检索,搜集1989年-2012年间发表的所有期刊文章,保存了“题名”、“作者”、“关键词”等题录信息,作为实验的原始数据集。对下载的题录信息进行去重、字符编码转换(中文编码使用UTF-8)等处理,使数据规范化。为得到构建作者-关键词网络的数据,将题录信息按照教师分类,得到72位教师的文献集合,再从中抽取每位教师使用的关键词并统计每个词的频次,共抽出了关键词6 917个。最终数据格式为以每个教师的姓名建立一个文本文件、文件中存储该教师使用的关键词及频次,关键词按词频降序排列。
(2)数据筛选与预处理
将每个教师使用的关键词中词频为1的词删除。因为词频为1的关键词很可能是某次研究中偶然涉及到的研究内容,不能充分代表作者的研究方向。然后,将一些对于描述研究方向无意义的词删除,如“实证研究”、“综述”、“对策”、“述评”等词。并将此时关键词集合为空或只有1个关键词的教师去除,得到63位教师和956个不同的关键词。最终确定将这63位教师及他们的关键词集合作为实验数据集。
(1)基于作者-关键词关联网络的作者相似度计算结果.
首先,根据3.2节中描述的关键词间关联度的计算方法(公式(1)至公式(3)),得到关键词间的关联度矩阵(部分)如图3所示:
 | 图3 关键词关联度矩阵(部分) |
可以看出,虽然关联度为0的关键词对数量较多,但是相较于将词看作相互独立的个体,已经在一定程度上加强了对词间真实关系的反映。
根据上述关键词间的关联度,利用公式(5),得到作者相似度矩阵(部分)如图4所示:
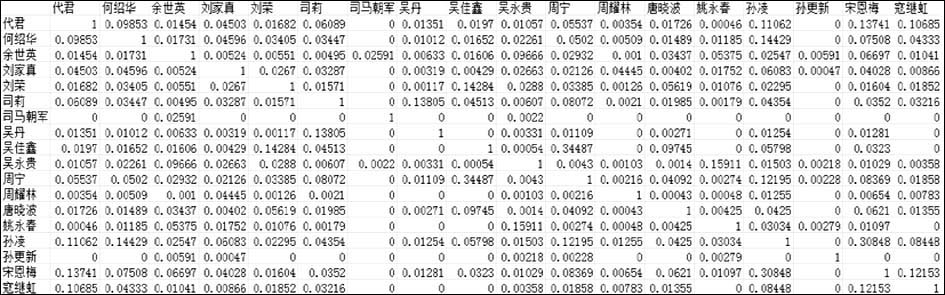 | 图4 基于作者关键词网络的作者相似度矩阵(部分) |
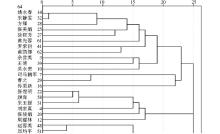
为了使结果便于观察和比较,使用SPSS19.0[ 22]的系统聚类法对相似度结果进行可视化,得到树状图(部分)如图5所示:
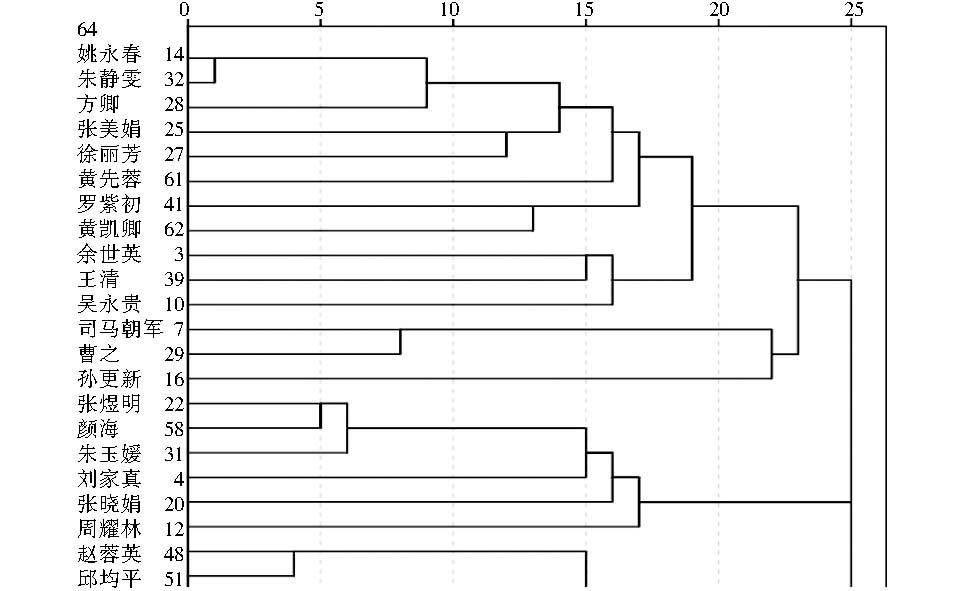 | 图5 基于作者-关键词网络的作者相似度系统聚类结果(1) |
由于完整的树状图较大,因此在本节内对实验结果进行分析时都截取其中的部分进行展示,完整的树状图见附录A(详见本篇论文的网络版本)。
(2)基于作者关键词耦合的作者相似度计算结果.
基于作者关键词耦合的作者相似度算法首先通过统计每两位教师所使用的相同关键词个数得到作者关键词耦合强度矩阵,部分矩阵如图6所示:
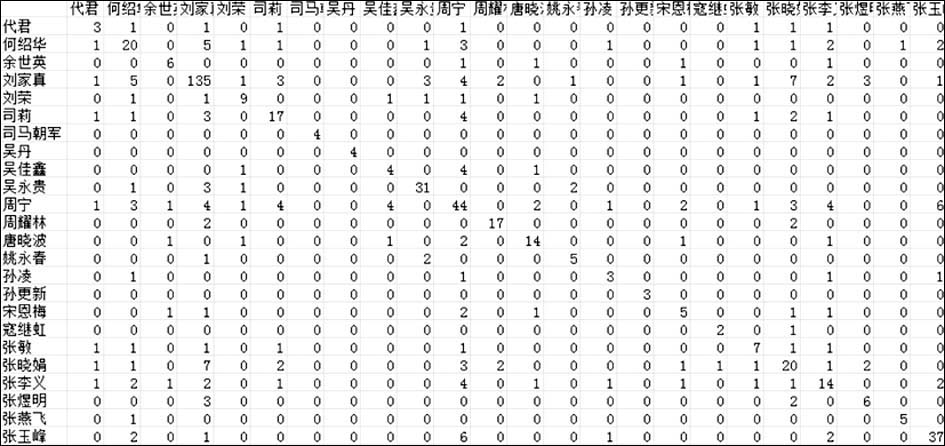 | 图6 作者关键词耦合强度矩阵(部分) |
从图6可以看到,有的老师使用的关键词个数远高于其他老师,如刘家真老师,这使得刘老师与其他老师的关键词耦合强度也相对较高,这对比较不同作者对间的相似度很不利。因此,通过相互包容系数法对耦合强度矩阵进行处理,得到作者的相似度矩阵,部分矩阵如图7所示:
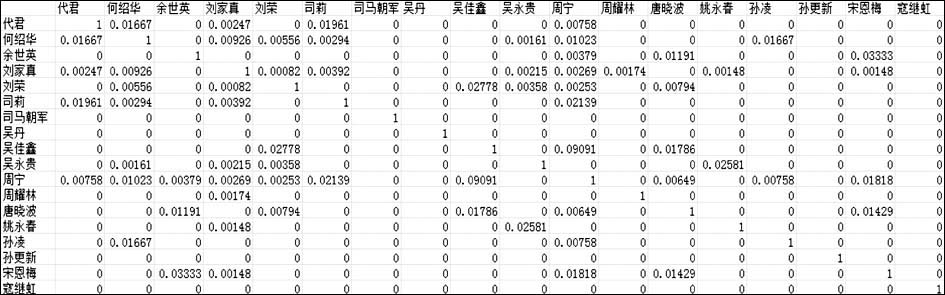 | 图7 基于作者关键词耦合的作者相似度矩阵(部分) |
与图4相比,可以很明显地看出,基于作者关键词耦合计算的作者相似度中值为0的教师对较多。这是由于作者关键词耦合算法中要求两位作者必须有完全匹配的关键词,否则两人间将没有耦合强度,也就没有相似度。
使用SPSS19.0对结果进行可视化,以与基于关联网络的作者相似度进行比较。通过系统聚类法得到树状图(部分)如图8所示,由于完整的树状图较大,图8及后文的分析中仅截取了部分树状图,完整的树状图见附录B(详见本篇论文的网络版本)。
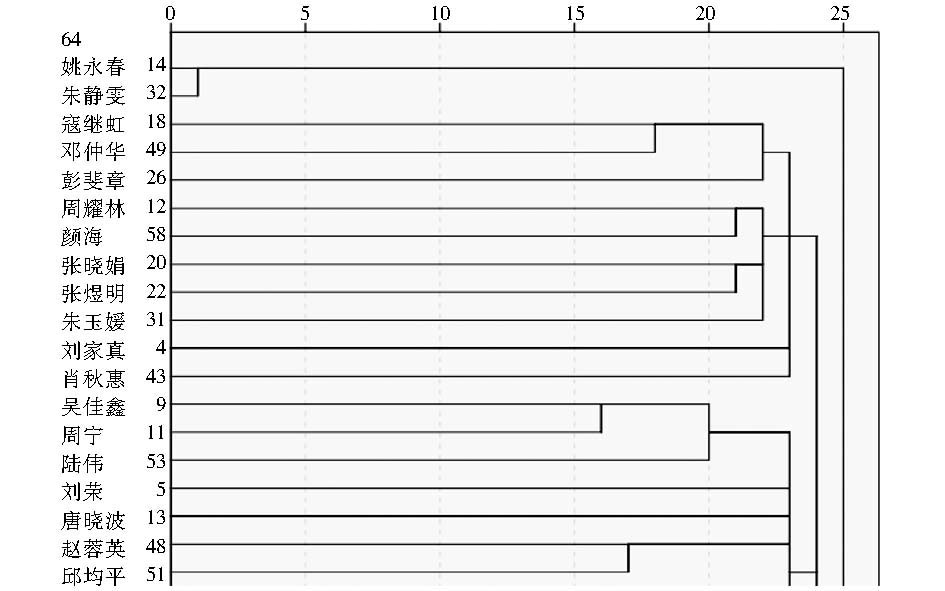 | 图8 基于作者关键词耦合的作者相似度系统聚类结果(1) |
可以看出,获取作者间有效聚类的距离普遍较远,对于结果的具体分析在下文中进行阐述。
(3)基于向量空间模型的作者相似度计算结果.
根据所搜集的实验数据,可以利用作者的关键词集合构建作者-关键词矩阵。通过词频计算TF-IDF作为关键词在每个作者维度上的权重,以余弦相似度作为作者相似度计算结果,得到作者间的相似度矩阵,部分矩阵如图9所示:
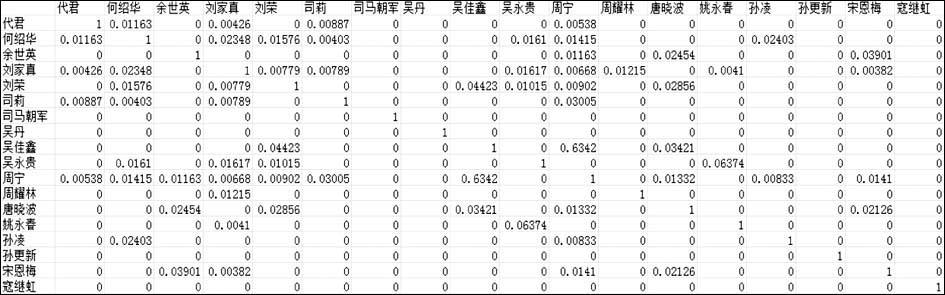 | 图9 基于向量空间模型的作者相似度矩阵(部分) |
使用SPSS19.0对结果进行可视化,以与基于关联网络的作者相似度进行比较。通过系统聚类法得到树状图(部分)如图10所示,由于完整的树状图较大,图10及后文的分析中仅截取了部分树状图,完整的树状图见附录C(详见本篇论文的网络版本)。
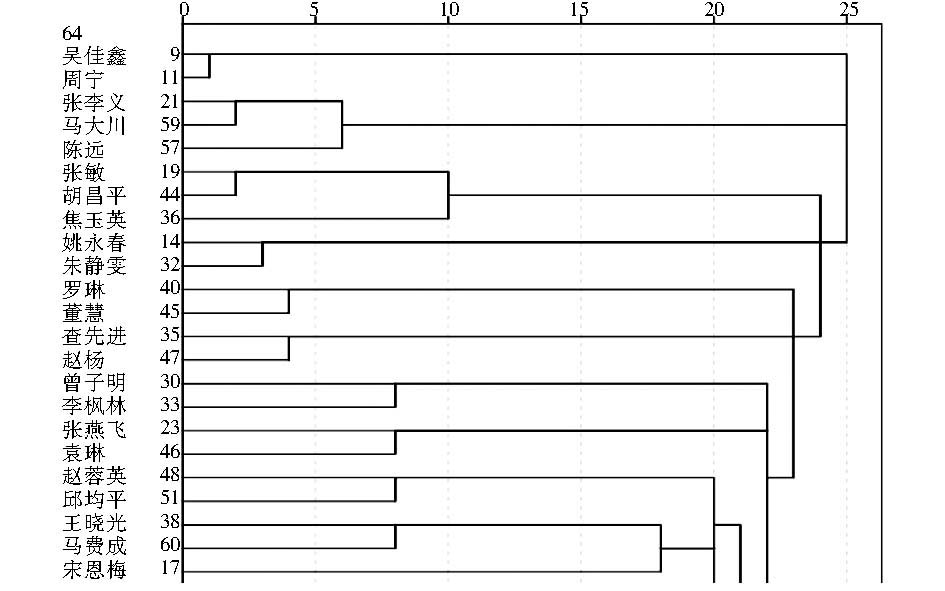 | 图10 基于向量空间模型的作者相似度系统聚类结果(部分) |
从这个树状图中可以看出,许多作者间两两关系紧密,但作者对之间关系较为疏远。
(4)实验结果对比分析
将基于关联网络的作者相似度计算结果与基于作者关键词耦合和向量空间模型这两种作者相似度计算结果的系统聚类树状图进行对比,可以看出基于关联网络的作者相似度的聚类结果更为紧密,而基于作者关键词耦合的作者相似度总体聚类距离最远。
图5、图8和图10中部分教师间的聚类结果始终较为一致,如马费成和王晓光、赵蓉英和邱均平等都被较为紧密地聚集在一类。同时,也有部分教师的聚类结果有较明显差异,下面对其中几个较为典型的案例进行具体分析:
①在基于作者关键词耦合的作者相似度计算结果中,可以看到吴丹、邱晓琳两位老师没有与其他老师聚在一类如图11所示:
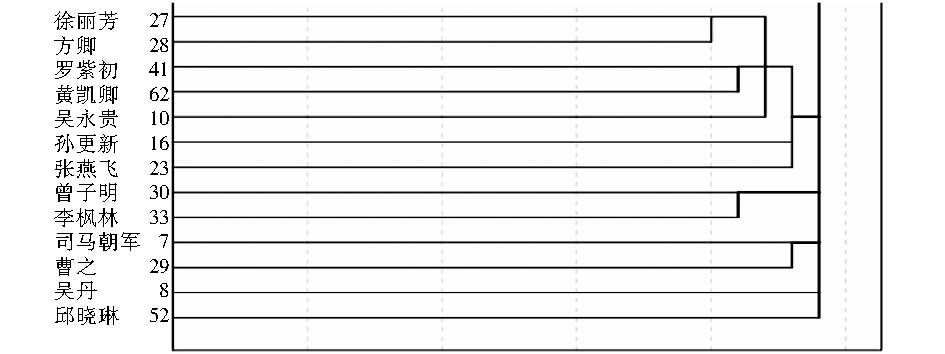 | 图11 基于作者关键词耦合的作者相似度系统聚类结果(2) |
通过在基于作者关键词耦合的耦合强度矩阵中进行查找,发现这两位老师的关键词集合中的词个数相对较少,均为4个,且与其余老师相匹配的关键词个数尤为少。因此,得到的相似度结果中,这两位老师与其他老师间相似度为0的情况非常多,使得在层次聚类结果中没有被聚到某一类别。
在基于向量空间模型的作者相似度计算结果中,吴丹、司马朝军老师也是类似情况。
然而,在基于作者-关键词关联网络的作者相似度计算结果中,这两位老师的层次聚类结果有明显差异。以邱晓琳老师为例,如图12所示,她与张玉峰、李纲老师聚在一起。
 | 图12 基于作者-关键词网络的作者相似度系统聚类结果(2) |
通过查看邱晓琳老师的关键词及其简介发现,其研究内容主要为竞争情报和知识管理。而张玉峰所发表的文献表明她的研究内容包括竞争情报,同时其个人主页表明其研究方向包括知识管理。李纲的研究内容同样包括竞争情报。因此,基于关联网络的作者相似度算法较好地体现了邱晓琳、张玉峰和李纲三者间的相似性,而通过作者关键词耦合得到的结果中则不能体现这三者间的关联。
同时,在基于作者关键词耦合的作者相似度计算结果中,张玉峰虽然使用的关键词个数为37个,但是与其他老师相匹配的词数不多,因此耦合强度较低,在层次聚类中的结果不佳。
在基于作者-关键词关联网络的作者相似度算法中,司马朝军与曹之距离较近,符合实际情况。而在基于向量空间模型的作者相似度算法中,司马朝军没有与其他老师聚在一类。
因此,在这几位学者间的相似度的计算上,基于作者-关键词关联网络的作者相似度计算效果更好。
②观察基于作者关键词耦合的作者相似度聚类结果,发现将陆泉、黄先蓉、陈传夫三位老师聚在一起如图13所示:
 | 图13 基于作者关键词耦合的作者相似度系统聚类结果(3) |
观察三位老师的关键词发现,陆泉的关键词个数仅为2,即“数字图书馆”和“维基”,而其中的“数字图书馆”一词三位老师均有使用,同时,黄先蓉和陈传夫有“著作权法”、“著作权”等相同的关键词,因此通过耦合强度进行测度时,陆泉与黄先蓉、陈传夫关系紧密。
而在基于作者-关键词关联网络的作者相似度计算结果中,这三位老师是分开的。黄先蓉与徐丽芳、方卿等出版科学系的老师距离较近(见图5),黄先蓉虽然有与著作权法相关的研究,但她的总体研究方向是从出版科学的角度出发。陆泉与焦玉英、董慧距离最近,他们的研究都与数字图书馆、维基、Web2.0等相关。陈传夫则与肖秋惠、肖希明等距离较近(见图12):与肖秋惠都有关于信息法的研究,与肖希明都有关于图书馆学的研究。
在基于向量空间模型的作者相似度结果中,陆泉没有被紧密地聚在某一类,而是基本独立存在。
经由上述分析,基于作者-关键词关联网络的作者相似度计算结果最为精确,与实际情况较为一致。
③由图11(基于作者关键词耦合的作者相似度计算结果)可以看出,李枫林与曾子明关系较为紧密,他们同属于信息系统与电子商务系,他们的研究都包括信息服务等,有相同的关键词使他们较为相似。然而,张李义与王新才、袁琳等聚在一类,这与他们各自的研究内容有所不符。张李义同属于信息系统与电子商务系,且与曾子明合著过文章。王新才主要研究档案学、电子政务等方向。袁琳主要研究图书馆学相关方向。因此,这三者间并没有明显的相似性。
在基于作者-关键词关联网络的作者相似度聚类结果中,李枫林与胡昌平最为相近如图14所示,同时,曾子明与张李义距离最近,袁琳则与肖希明、肖秋惠等图书馆学专业老师聚在一起(见图12)。
 | 图14 基于作者关键词网络的作者相似度系统聚类结果(3) |
李枫林虽然属于信息系统与电子商务系,但他的研究内容主要为信息服务,与胡昌平的研究方向较为吻合,两人还合著过《信息服务与用户》一书,因此将两人划分在一类是符合事实的。同时,张李义、袁琳的划分相较于作者关键词耦合得到的结果也更为符合事实。
在基于向量空间模型的作者相似度结果中,李枫林与曾子明关系紧密,同时张李义与其他几位电子商务系老师聚在一起。然而,胡昌平与其他研究方向相近的老师距离较远,且邓胜利与黄如花距离最近。
对比三种计算方法的聚类结果可以发现,基于作者-关键词网络的作者相似度算法的结果优于基于作者关键词耦合和向量空间模型的作者相似度结果。特别是对于使用关键词较少的作者,此时作者关键词耦合效果往往不够理想,因为耦合要求两人使用相同的关键词,而由于关键词是作者主观选择的,同样研究主题的文献作者可能选择表达相同意思的不同词汇作为关键词。此时,用关键词耦合得到的结果是不够完整的。同样,基于向量空间模型的作者相似度算法中,将不同的关键词看作不同的维度,而空间向量中的维度也是互相独立的。而通过建立作者-关键词网络并计算关键词间的关联关系,挖掘相近的关键词间的关系,使得计算作者相似度时结果更为准确。但对于产生学术成果多且涉及多个领域的作者来说,因为链出的关键词很多,所以采用本文提出的方法在某种程度上会降低该作者与其他作者的相似度,下一步将针对多领域作者相似度作进一步研究。
随着科学技术的发展,学者间的交流日益增多,学者间因不同类型的关联关系而形成复杂的关联网络。作者相似度的计算在学者网络的相关研究中有重要应用。本文通过构建作者-关键词关联网络,利用TF-IDF和向量空间模型的思想,提出了关键词间关联度的测度方法,使关键词不再是相互独立的个体,而是具有相关关系的词对。在此基础上,根据作者和关键词间的关联关系,运用P-Rank思想,进行基于关键词关联度的作者相似度计算。基于作者关键词网络的作者相似度计算结果比作者关键词耦合、向量空间模型等直接通过某种属性关联的计算方法效果更好。另外,选择关键词作为作者关联媒介,比作者同被引等基于引文的作者关系测度更为客观且无时滞。
但是,该研究还存在一些不足,所选的实验范围局限于一个学院的教师,因此对相似结果的评价采用的是人工评价,下一步将选择一个领域的核心研究人员为实验范围,探测核心研究人员的研究内容相似性,并与已有的研究结果做对比。另外词相似度计算也有多种方法,本文只考虑了一种方法,今后会针对不同计算方法(如谷歌距离[ 23]、基于维基的词语相似度[ 24]等)进行对比试验研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|