{kind=link}
{kind=link}
中文网络评论中产品特征提取方法研究*
[王永 , 张勤
, 张勤
, 张勤|
|


针对中文网络客户评论中产品特征提取问题,提出采用FP增长算法获取候选产品特征集,再根据独立支持度、频繁项名词非特征规则及PMI阈值过滤技术对候选产品特征进行筛选,得到最终产品特征集,从而实现对中文网络客户评论中产品特征信息的自动挖掘。采用数据堂提供的手机评论语料,对该方法进行数据实验,实验结果可以验证该方法的有效性。
Aim for better solving the problem of extracting features from Chinese product reviews on the Internet, an approach using FP-growth algorithm is proposed to obtain the set of candidate product features. Then, the candidate product features are filtered according to the rules of p-support, non-features frequent nouns and PMI threshold filtering technology. Finally, the final product features set are obtained. Thus, the automatic mining of product features information from Chinese customer reviews on the Internet is achieved. The proposed method is tested with the cell phone reviews from Datatang and the results show that the presented method is valid and effective.
随着大数据时代的到来,数据成为商业活动中的一种重要资源,基于数据的科学决策和精细化管理将成为现代商业管理发展的必然趋势。在电子商务领域,海量的商品评论数据蕴含着巨大的社会价值和商业价值。对海量商品评论中产品特征数据进行分析挖掘,可为潜在消费者提供商品属性粒度级别的购买决策依据;为企业提供产品设计的依据和其他企业的竞争情报,还能对用户的需求和产品的改进方向做出有效反应[ 1],提高企业竞争力。
目前产品特征提取的研究方法主要分为人工定义和自动提取两类。Zhuang等[ 2]、Kobayashi等[ 3]、娄德成等[ 4]采用人工或半自动的方式对电影、游戏和中文汽车领域进行产品特征提取研究。Shi等[ 5]人工定义了基于产品属性的概念模型,并以此模型对中文领域产品特征进行研究。但是这些方法移植性较差,当产品功能发生改变时,需要重新构建产品特征集合,效率不高。Yi等[ 6]提出产品特征词一般是具有BNP(Base Noun Phrase)结构的名词或名词短语,并采用信息检索算法判别该特征与指定产品是否相关。余传明[ 7]采用基于 SOM 的产品属性挖掘方法对餐馆评论进行研究,取得了较好的效果。Hu等[ 8]首先提出使用关联规则分类方法Apriori算法对英文评论中的产品特征进行提取。李实等[ 9, 10]参考Hu等的研究方法,针对中文语言特点,提出中文文本评论中的产品特征提取方法。虽然上述方法结构简单便于实现,也具有良好的移植性,但是由于没有充分考虑短语评价对象的结构特征以及评价对象的领域相关性,会产生较多噪声信息,因此准确率有待提高,而且Apriori算法会产生大量的候选项集,并反复扫描数据库,其运算效率不高。
鉴于此,本文提出了一种新的产品特征提取方法。该方法针对中文产品评论,以效率远高于Apriori算法的FP增长算法[ 11]来提取候选产品特征;然后从产品和属性之间的语义关系角度出发,进行产品特征的筛选,弥补了关联规则算法只从数量上考虑关注程度的不足。实验结果表明,本文提出的方法能有效降低噪声,提高中文产品评论领域特征提取的挖掘性能。
在本文的方法中,首先使用FP增长算法提取候选产品特征,并根据独立支持度规则对候选产品特征进行初步筛选;然后制定频繁名词非特征规则,并建立相应名词集合,从中文语义角度进一步筛选产品特征;最后采用PMI算法从语义相关角度降低噪声,得出最终的产品特征集合。
本文提出的面向中文网络客户评论的产品特征提取过程如图1所示:
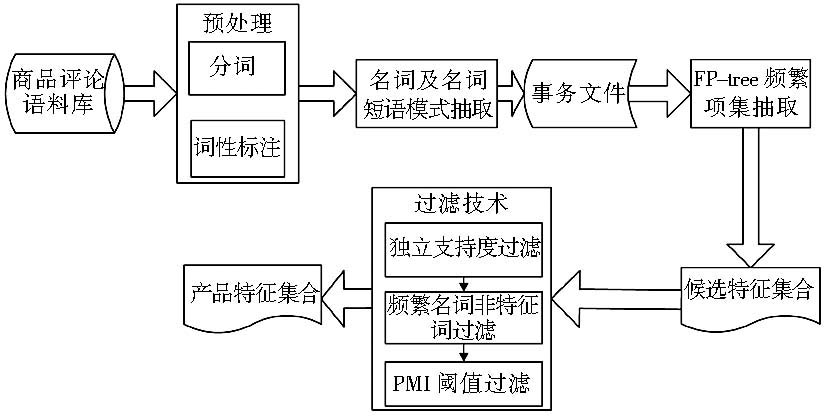 | 图1 产品特征提取过程 |
(1)应用中国科学院计算技术研究所的中文分词工具ICTCLAS对原始评论语料进行分词和词性标注。
(2)利用词性标注后的评论语料提取名词或名词短语并创建关联规则事务文件。ICTCLAS分词工具所使用的词性标注标记集中与名词相关的标记子集是{/an, /ng, /n, /nr, /ns, /nt, /nz, /vn},根据这些标记所代表的含义以及产品属性词的语法特点,本文选择{/n, /vn }子集作为抽取规则。使用计算机语言对每一条评论进行名词及动名词抽取,并生成一条记录插入到事务文件中。
(3)采用FP增长算法对事务文件进行扫描,将得到的频集生成一棵频繁模式树(FP-tree);随后再将 FP-tree分化成若干与长度为1的频集相关的条件库;再分别对每一个条件库进行频繁特征识别,得到频繁项集,并将它作为候选产品特征集合I0。
(4)采用独立支持度规则对候选产品特征集I0中的名词及名词短语进行过滤、修正,形成候选特征集I1。本文将评论中包含频繁特征名词或名词短语ftr且不包含ftr父集的句子数量称为ftr的独立支持度(P-support)。本研究采用最小支持度为1%进行实验。
(5)制定中文频繁项名词非产品特征规则,并建立相应的名词集合,从中文语义及语法知识角度过滤I1,形成特征集合I2。本研究将中文频繁项名词却非产品特征主要划定为以下几种情况:
①常见的抽象性名词,如“情况”、“事情”、“原因”等。
②所评价产品名称,如“酒店”、“宾馆”、“手机”等。
③用户口语化的评论名词,如“本子”、“机子”等。
④与产品无关的称呼类名词,如“网友”、“老板”、“同事”等。
⑤常见的集合类名词,如“人员”、“大家”等。
(6)使用基于网络搜索引擎的PMI算法[ 12]计算产品和特征集合I2中各个特征的共现度——PMI值,并按照PMI值从大到小进行排列,PMI 值越高,二者之间的关联程度越大,通过多次实验选择最佳阈值,过滤共现度低的特征,形成最后的产品特征集合I3。PMI计算公式定义如下:
其中,hit(x)是以词语 x 为关键词查询时搜索引擎所返回的页面数;hit(x and y)是同时以 x 和 y 作为关键词查询所返回的页面数。本文选取百度搜索引擎返回的页面数作为PMI计算的依据。
采用信息检索领域常用的性能评估指标:查准率P、查全率R和综合值F-score。其中,查全率和查准率分别度量性能的某个方面,忽略任何一个都有失偏颇,综合值F-score 是对性能的整体评估,具体计算方法如下:
其中,A表示算法识别出来的产品特征数量,B表示算法识别出来但不是产品特征的数量,C表示算法未识别出但是是产品特征的数量。
采用数据堂提供的手机评论语料(http://www.datatang.com/data/43824),选择其中的600篇作为实验数据。通过手工标注的方法获取产品特征提取实验的参照特征。结合“中关村在线”、“京东商城”等网站对手机的评定标准,并依据最小-最大覆盖原则[ 9],对语料进行手工标注,获得覆盖600篇评论中提到的该商品特征的集合,共得到手机产品特征 86 个,如表1所示:
| 表1 手工标注手机产品特征集合 |
(1)产品特征提取结果
从词频和语义相关两个角度,得出手机评论语料中客户关注程度居前10名的手机特征,如表2所示:
| 表2 手机产品特征提取结果(按PMI值排序) |
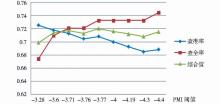
 | 图2 PMI值选择不同阈值时的性能变化情况 |
| 表3 手机评论挖掘性能 |
(2)对比分析
对于手机产品的评论特征挖掘,本文所提出的方法与其他方法的结果比较如表4所示:
| 表4 针对手机评论的产品特征挖掘结果比较 |
本文方法是基于FP增长算法设计的,由于FP算法的运行效率远高于Apriori算法[ 11],因此,本文方法的效率远高于文献[ 8]和文献[ 10]中方法的效率。
产品特征作为互联网海量商品评论信息的一个重要方面,是其他用户做出购买决策的参数,更是生产商和销售商改进商品和服务的关键指标。对产品特征进行提取是文本评论挖掘的重要任务之一,直接影响着评论挖掘的性能。在英文文本评论领域,研究者已初步取得一些成果,而针对中文网络产品评论的研究还处于探索阶段,存在诸多不足。本文从理论上对中文客户评论产品特征挖掘问题进行了探索,将关联规则分类方法FP增长算法应用于产品特征提取领域,并采用独立支持度规则、频繁名词非特征规则以及PMI算法,从多个角度筛选产品特征,拓展了基于关联规则的产品特征挖掘方法。数据实验结果表明,本文方法具有良好的性能,有望在一定程度上解决网络评论数据过载以及信息非结构化等问题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|