{kind=link}
{kind=link}
{kind=link}
虚拟社区中基于Tag的知识协同伙伴选择策略*
[邓卫华1  , 易明
, 易明2 ]
, 易明|
|


基于Tag探讨一种虚拟社区中知识协同伙伴选择策略。首先通过Tag聚类划分虚拟社区知识领域,识别较强的知识关联;其次借鉴二分图理论,投影构建优化的知识关联图;然后运用图结构分析确定候选伙伴集,并完成候选伙伴评价与选取。最后给出一个实验阐述该策略的应用,进一步验证研究结论。
This paper explores a new method of selecting partner of knowledge collaboration in virtual community based on Tag. It differentiates virtual community domain by tag clustering firstly, then projects and constructs new relational diagram of users and strengthens simply user knowledge relation based on the two branch of graph theory, and applies the network analysis method to determine the candidate partners set and to finish the candidate partner evaluation and selection. The experiment validates the conclusion of this paper.
当知识管理进入了以“知识协同”为标志的发展阶段,许多组织以协同/协作、共享、合作创新为主题,凭借形态各异的虚拟社区进行知识的协同和交互[ 1]。然而,虚拟社区链接了无数用户,如何选择那些具有较高价值的用户成为协同伙伴,并利用他们进行知识协同,快速实现知识创新,是虚拟社区知识协同中的关键问题之一。至今为止,伙伴选择的研究曾出现在动态联盟[ 2]、供应链[ 3]和虚拟企业[ 4]等研究领域中,但由于研究领域的特定性,其研究成果不能完全照搬“虚拟社区”这一特殊背景。Tag作为Web2.0的表示形式之一,为虚拟社区知识协同伙伴选择创造了契机。目前,基于Tag的虚拟社区知识协同活动已初步展开,但研究表明由此所最终实现的知识协同效应还十分有限[ 5]。本文试图深度挖掘Tag理论,探索一种较优的虚拟社区知识协同伙伴选择方法,为用户提供更优的知识协同支持和服务,以提升虚拟社区知识协同效应。
知识协同是一个以知识创新为目标,由多个拥有知识资源的行为主体协同参与的知识活动过程[ 6]。作为知识协同的一个分支,虚拟社区知识协同可以形象地描述为一个社区知识资源(包括知识主体和知识客体)及其关联所构成的三元组集合:G={g,p,l/(g1,g2,…,gi)(p1,p2,…,pi)(l1,l2,…,li)},其中,G表示虚拟社区知识协同, g表示虚拟社区知识客体,例如论坛帖子、博文、社区地图、发帖规则等;p表示虚拟社区知识主体,即虚拟社区用户;l表示虚拟社区知识主体之间的知识关联,例如社区用户间的互引、回帖、分享、关注、订阅和收藏等互动行为[ 5]。在该集合中,知识关联是个尤为重要的因素,其关联强度将直接影响知识协同效应的高低。因此,在虚拟社区知识协同过程中,为了实现较高的知识协同效应,应该选取知识关联较强的知识主体作为协同伙伴,即本文所谓的虚拟社区知识协同伙伴选择。
目前,Tag已广泛运用于虚拟社区知识协同中。在学术领域,部分学者对此展开了较深入的探讨,并取得一定进展。根据选择方法的不同,可将其分为基于矩阵的方法[ 7]、基于聚类的方法[ 8]、基于图论的方法[ 9]及其他方法[ 10]等。在实践领域,社区普遍采用的形式是:系统自动记录并依据用户间的“相同Tag”特征来选取与之对应的协同伙伴,并予以推荐以协助其知识活动。例如,某英语学习社区中,当用户向系统提出寻求协同伙伴的需求时,系统将利用先前已建好的基于“相同Tag”的社区知识库对该需求进行分析,当知识库中的分析结果能够满足其需求时,则通过电子邮件将该信息以候选知识协同伙伴的形式传递给该用户。总之,上述应用在社区用户创造及共享知识方面起到了一定的促进作用,同时也暴露出一些明显不足:知识协同伙伴结果中存在许多“噪声”信息,降低了其精度;所发掘的知识协同伙伴数量十分有限[ 5]。究其根源,从知识信息组织的语法、语义和语用三个层次来看,现有应用大多停留在语法和语义的较低层次,而较少考虑到语用层次,由此所选取的知识协同伙伴往往只具有初级知识关联(例如标注相同Tag的关联),从而降低了最终的知识协同效应。
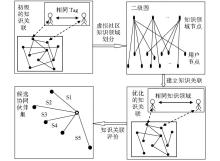
从语用层次出发,虚拟社区知识协同伙伴选择的重点集中于强化知识关联上。根据Beckmann[ 11]的研究,知识关联可以理解为知识距离,即知识主体所涉及的知识领域(例如学科领域)间的距离。通常情况下,知识距离越小,知识关联强度越强。由此,本文将基于Tag的知识协同伙伴选择策略聚集于建立和评价社区用户间基于“相同知识领域”的知识关联。其中,划分知识领域和知识关联评价是两个关键问题。虚拟社区知识领域是对应于专业知识体系“学科领域”的概念,它是对社区知识资源集合(即所有社区用户及相关知识客体的集合)的分门别类,但不同于“学科领域”的规范性、准确性,具有明显的“用户生产”特征[ 12]。Tag作为社区用户赋予相关知识资源的元数据,可以应用于社区知识领域的划分,其具体实现是:依次对用户层次和社区层次的Tag系统进行聚类,从而自下而上地划分出社区知识领域[ 13]。同时,知识关联评价可以采用传统伙伴选择方法中的评分制,但现行的评价指标体系在此并不适用。事实上,从图论视角来看,基于“相同知识领域”的知识关联是社区Tag系统中的一种隐性用户关系边,可以科学运用二分图投影法将其显化出来,而知识关联度的评分则可以转化为对该边权值的计量。基于此,本文所提出的策略将由虚拟社区知识领域划分、建立优化的知识关联和知识关联评价三个部分组成,具体框架如图1所示:
 | 图1 虚拟社区中基于Tag的知识协同伙伴选择策略框架 |
(1)单个用户所关注的知识领域发现
对单个用户而言,随着使用Tag的数量累积,会形成一个较稳定的个体Tag系统,可表示为:Dui=(Kui,Tui,Aui)。其中,ui表示用户ui,Kui={kui1,kui2,…,kuil}为用户ui标注的知识客体集合,Tui={tui1,tui2,…,tuig}为用户ui使用的Tag集合,Aui={a=(ku,tu)|ku∈Kui,tu∈Tui}为用户ui标注的知识和使用的Tag之间的连接关系。在此基础上,单个用户的知识领域发现是指运用Tag聚类对用户ui的知识客体集合进行类别化处理,聚类的依据是各个知识对应的Tag之间的相似性,聚类的结果是将其分为k个知识领域。用户ui的第k个知识领域为ckuik={kui,tui|(kui1,kui2,…,kuin)(tui1,tui2,…,tuim),kuin∈kuij& tuim∈tuig},其中kui表示第k个知识领域中所包含的知识客体集合,tui表示这些知识客体所对应的标签集合。当完成对所有用户的知识领域发现后,即可形成虚拟社区中所有用户的知识领域集合AKG={(u,cku)|(u1,u2,…,ui)(ckui1,ckui2,…,ckuik)}。
(2)虚拟社区知识领域划分
对虚拟社区中所有用户的知识领域集合AKG进一步划分,聚类的依据是单个用户知识领域对应标签云之间的相似性,聚类的结果就是划分出虚拟社区知识领域。由此,虚拟社区知识库可以表示为:FG={Fg1,Fg2,…,Fgi},其中,FG为虚拟社区知识客体集合,Fgi为知识领域。当虚拟社区知识领域划分完成后,并不是每一个划分所得知识领域都有意义,还需要分析知识领域的基本属性(如包含的用户数量、知识数量等)以评价知识领域的相对成熟度[ 14],从而过滤掉那些成熟度相对较低的知识领域。
(1)构造包含“知识领域”与“用户”两类节点的二分图
根据图论科学,按照图中所包含的节点种类,可以将其分为:单模式图和双模式图,甚至更多模式的图。其中,单模式图只包含同一类节点,双模式图包含两类不同的节点[ 15]。二分图是双模式图中的一种,擅于同时讨论两种泾渭分明的节点。借此构造虚拟社区中包含“知识领域”与“用户”两类节点的二分图,初步描述虚拟社区中用户间的知识关联。其中,项目节点是虚拟社区知识领域,参与者节点是虚拟社区用户,一条二分图边表示一个用户关注一个知识领域。
(2)二分图投影与优化的知识关联图
在上述二分图中,以“知识领域”为桥梁间接地揭示了用户间的关系,即连接于同一知识领域节点的用户间具有较强的知识关联。根据二分图理论,可以采用投影法把该图向用户节点投影,得到表示用户节点之间在知识领域内相关联的单模式网络,从而得到优化的知识关联图[ 16]。该图可以表示为:WG=(WU,WV)。其中,WU为知识关联图的节点(用户)集合,WV={vx,y=(ux,uy)|u∈FU}为知识关联图中节点(用户)ux和节点(用户)uy之间的边权值。
在构建优化知识关联图中,一项重要的任务是确定用户节点间的边权值。在虚拟社区知识环境中,用户兴趣具有多元性的特征,同一用户节点会与多个知识领域节点相连,从而造成用户间关系的多重性。因此,在投影所得的知识关联图中,用户间的多重连接被合并为唯一连接,则以边权值来区分用户间多重关系的差异,即用户间关系的强弱[ 17]。根据Zhou等[ 18]所提出的方法,边权wji可理解为用户j通过某一次知识协同活动(边)传递给用户i的资源所占的比例,用如下公式表示: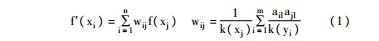
其中,f(xj)表示用户节点j在上述第一步分配到的资源,f′(xi)表示用户节点i最后分配到的资源,k(xj)表示用户节点j的度,k(yi)表示项目节点l的度,ail是二分图的邻接矩阵元,若xi用户与yl知识领域邻接(连边),则ail=1,否则为0,ajl定义同此。
(1)确定候选伙伴集
确定候选伙伴集是指从知识关联图的众多节点中筛选出与当前节点有着较强知识关联的多个节点,以组成候选伙伴集。根据知识关联图的邻接关系,对当前节点而言,与其具有邻接关系的多个节点,即为与其有着“相同知识领域”特征的节点;而与其具有两步及以上距离的节点,则为与其关注不同知识领域的节点。由此可见,确定候选伙伴集可以通过寻找知识关联图中当前节点的所有邻接节点来完成[ 19]。因此,对于当前节点而言,其协同候选伙伴集合可以表示为:CU={Cu1,Cu2,…,Cui}。其中,CU为特定虚拟社区用户的知识协同候选伙伴集合,Cui为协同候选伙伴。
(2)候选伙伴评价与选取
所谓的候选伙伴评价与选取是指对已确定的候选伙伴进行知识协同能力评价,以挑选出与当前节点具有较强知识关联的节点作为候选伙伴。根据二分图投影方法的“平均资源分配”假设,优化的知识关联图中的边权wji意味着用户j通过某种方式的协作(边)传递给用户i的资源。由此可见,边权值wji越大,则用户j与用户i间的关系越强,也就是说,对用户i而言,用户j具有较强的知识优势[ 18]。由此,对当前节点已确定的候选伙伴集,可以计算出每一个候选伙伴与当前节点间的边权值,作为每个候选伙伴的知识关联强度评价得分ss(j),公式如下所示:
ss(j)=wij (2)
依托于笔者所在课题组前期研究开发的“基于Web2.0的虚拟学习社区平台”[ 20],该平台构建于Apache应用服务器、MySQL数据库服务器、PHP语言环境之中。本次实验过程中共组织了55名本科生作为系统用户,分享了客户关系管理、数据库建设与应用、信息传播、英语等课程的知识信息。同时,为了模拟真实虚拟学习社区环境中的资源标注场景,要求每人至少对50篇帖子进行标注,每帖的Tag数量在3个左右,从而共形成6 894条接近真实应用场景的标注数据,存储于MySQL数据库中。为了避免“数据稀疏性”等问题,经过数据预处理,最终有35位用户的标注数据作为实验数据。
(1)单个用户的知识领域划分
从聚类方法来看,社会网络分析中的凝聚子群分析作为聚类分析的一种,比较适用于单个用户的知识领域划分。本实验首先利用单个用户使用的Tag的共现频次建立初级的知识关联图,然后依据社会网络中的凝聚子群分析对Tag进行聚类,进而将每个Tag聚类映射到相应的知识集合以完成对单个用户的知识领域划分。选择UCINET软件[ 21]进行分析,以n-clique为计算方法,同时设定最大距离为1、子群节点数最小为6的严格条件。
(2)社区知识领域细分
采用数据挖掘工作平台Weka 3.7.0的DBSCAN密度聚类算法[ 13]进行实验。将参数Eps和MinPts分别设定为0.9和5,运行DBSCAN算法程序,结果49个知识子类被划分为8个知识领域,剩余45个知识子类作为“噪音”数据被过滤。考虑到知识领域6仅包含两位用户,知识领域成熟度相对较低,所以将其过滤。最终共计发现7个领域,包含了29个用户,如表1所示:
| 表1 虚拟社区知识领域划分 |
(1)构造二分图
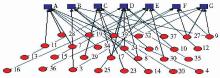
基于知识领域划分的结果,可以构造包含“知识领域”和“用户”两类节点的二分图。采用UCINET进行可视化处理,将NetDraw的选项设定为“2-mode netwok”,结果如图2所示:
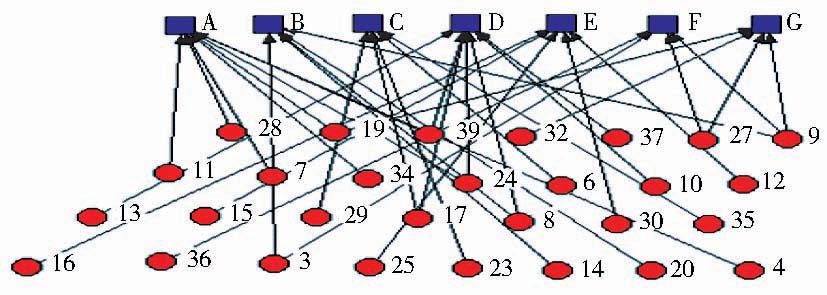 | 图2 “知识领域”与“用户”的二分图 |
其中,上排方点表示知识领域,下排圆点表示用户,不同类节点之间的边属于二分图。图2中,每个用户连接了一个或多个知识领域,这与用户兴趣多样化的事实相符。以用户3为例,同时连接了领域B和领域F。
(2)二分图投影
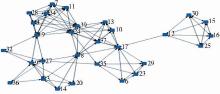
将二分图向用户节点一侧投影,从而实现优化的知识关联图,其中,图中的边权值依据公式(1)计算而得。采用UCINET对该图进行可视化处理,将NetDraw的选项设定为“1-mode netwok”,结果如图3所示:
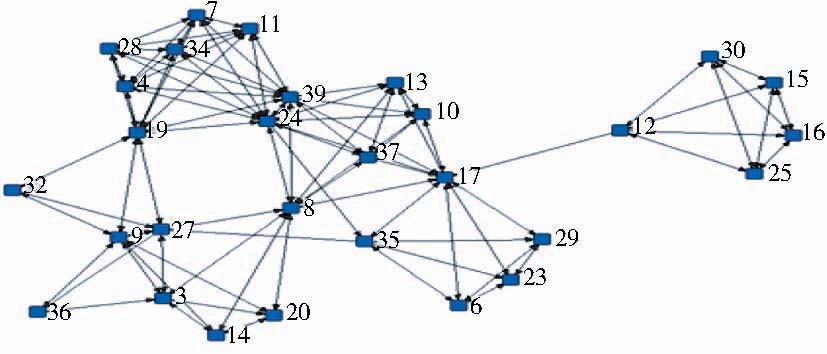 | 图3 优化的知识关联 |
图3中共计29个节点(用户),大部分节点之间联系密集,仅节点12、30、15、16、25较为孤立。
(1)确定候选伙伴集
根据优化知识关联图的结构分析,与当前节点“9”具有邻接关系的节点有20、8、14、3、27、36、19、32等8个节点,由此可得用户9的知识协同候选伙伴集:CU={20,8,14,3,27,36,19,32}。
(2)候选伙伴评价
利用公式(2)分别计算每一个候选伙伴的知识关联强度得分ss(j),评价的结果如表2所示:
| 表2 知识协同候选伙伴评价结果 |
在本实验中,笔者随机选取用户9为特定用户,进行知识协同伙伴选择。实验结果显示:该用户的知识协同候选伙伴集包括:3、27、20、19、8、36、32、14等8个用户,其推荐顺序依次为32、3、2、20和14、19、8、36,其中节点32为最理想的协同伙伴。根据用户反馈得知,较之以前基于“相同Tag”关联的知识协同伙伴选择方法,该结果所选取的协同伙伴的数量有所减少,但其对于该用户的知识协同活动更具有贡献性。由此可见,上述方法消除了协同伙伴选择的“噪音”,极大地提高了结果的精度,具有一定实用性。
知识关联是虚拟社区知识协同集合中的一个重要元素,识别较强的知识关联是提升知识协同效应的突破口。基于这一线索,本文从语用层次出发提出一种较优的基于Tag的虚拟社区知识协同伙伴选择策略,通过划分虚拟社区知识领域、建立与评价基于“相同知识领域”的知识关联,强化了现有应用中基于“相同Tag”的初级知识关联,并最终优化了协同伙伴选择结果。此外,虚拟社区知识协同本质上是在社区共同利益的驱动下,通过知识资源共享,有效地协同开发和利用各用户所拥有的知识资源而开展的知识创新活动。根据知识创新性问题解决理论,创新形式可分为两种:累积式知识创新和激进式知识创新。这两种形式对知识资源的倚重有所侧重:累积式创新意味着学习过程必须是连续的,要求所选取的协同伙伴应具有同一层次或较低层次高度相似的知识资源(亦即同质性知识);而激进式创新意味着知识创造的根本性变革,则更需要具有异质性和互补性的知识资源的协同伙伴。显然,本文研究的重点侧重于前者,通过发掘基于“相同知识领域”的同质性知识关联,以实现协同伙伴选择。今后的研究将沿着后一条路径展开,探索基于异质性和互补性知识关联的虚拟社区知识协同伙伴选择。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|