引用本文
Michael Lesk. Curators of the Future. New Technology of Library and Information Service, 2013, 29(3): 1-7

关键词:
Curators of the Future
Abstract
Is there such a thing as too much data? If not, who is going to be responsible for selecting what we keep? There is only starting to be a profession of data curation. Data curation will need at least three skills: expertise from library, archive and museum studies about choosing, preserving and explaining to users; expertise from computer science and engineering about data processing, data exploration and data storage methods; and expertise from the subject area of the material, so as to know what the data means, where it came from, and what its significance is. Will we do this work with a committee, or train one person to do everything; and if the latter, is that person likely to start from the library, computing, or subject domain?
Keyword:
Data curation; Data curation education; Trends in data related jobs


1 Introduction
Sensor technology is creating data on an unheard of scale[ 1]. Despite the continuing improvement in disk drive capacity of about 100% every 18 months, forecasts now say that we will increasingly be unable to store all the data we have. To look at one particularly large project, the Large Hadron Collider produces data at 2 petabytes/second[ 2] and the data pipeline tries to reduce this by a factor of 10^11[ 3].
How will we decide what gets kept and what gets discarded? It might be the original collector, or the funding agency, or random chance. In the past, however, we have often relied on libraries and archivists to decide. For example, in the United Kingdom the National Archives (previously known as the Public Record Office) selects at most 5% of government documents for permanent preservation[ 4]. It evaluates each department’s records to decide what is most important for long-term preservation; some items not selected for the central archive may be preserved in local archives.
Identifying long-term preservation as a separate task separates the short-term needs of the organization or researcher creating information from the long-term benefits of that information to society. Researchers, for example, may not save their information for any number of practical reasons such as lack of time, or impending retirement, or, less altruistically, to minimize the loss of credit should some later researcher re-process their data and reach different or more ambitious conclusions.
Librarians have a long history of choosing what is important. The days are long past when more than a handful of libraries could boast of “comprehensive” collecting, meaning to buy everything in a particular area.
However, the preservation task has gotten more complex in two large areas.
(1) Material is no longer in boxes on shelves, but in digital media. A whole new set of both opportunities and challenges are facing us. Digital items are amenable to full text search, and they can be easily re-used for republication or other new purposes. On the other hand, they come on a variety of physical media whose lifetime needs to be understood, and in multiple software formats that sometimes become obsolete.
(2) Content may now be complex scientific data whose users are generally specialists, and whose format may be complex numerical tables, rather than text.
In addition, there is an increasing need for the use of data within libraries and archives themselves. The “curatorial institutions” are no longer restricted to a presence in a building, but now maintain websites and collaborate with national and international data systems. In addition to catalog data and other user-facing databases, they generate weblogs and other data for their own consumption .
2 Demand
Historically, there have been very large disciplinary repositories in many subject areas. Among them are groups such as the National Climate Data Center, the Protein Data Bank, the Virtual Observatory, the IRIS consortium (seismology) , and many others. However, these are now being supplemented by a great many efforts to save the data collected by smaller projects.
The US National Science Foundation, beginning in early 2011, now requires all proposals to explain how the data generated by the planned project will be preserved and made available. Throughout the US, university libraries are now building repositories for the storage of scientific data. We don’t know today the answers to many of the organizational questions being posed. Universities are still working out who will pay for this effort, how will the scientific cooperation with the libraries take place, will data be generally distributed or centralized around the campus, and so on. The trend is, however, away from the single-discipline and world-wide center to university-oriented and broad-coverage data centers, containing the work of numerous small projects.
Other scientific research groups are similarly encouraging large-scale data storage. The National Institutes of Health stores many large datasets itself in the National Center for Biotechnology Information, ranging from GenBank to the Visible Human. But there are also other medical databases around the country with NIH support, as for example Online Mendelian Inheritance in Man (created at Johns Hopkins University but maintained online by NCBI) or the Lung Image Database Consortium (Cornell, UCLA, and the Universities of Chicago, Michigan and Iowa) . NIH also asks all its researchers to support data distribution although it has not enacted exactly the same requirement for “data management plans” that NSF has promulgated.
Around the world there are many similar efforts, with (just as examples) the copies or derivatives of the Protein Data Bank at the European Molecular Biology Laboratory and the data pouring out of the Large Hadron Collider in Switzerland. Government policies requiring the retention and availability of research data are also in place in countries ranging from Australia to Finland.
We are, however, just beginning to face up to the problems of supporting such databases. The multiplicity of sensors is generating data faster than we can store it, we don’t have long term plans for funding data preservation, and we lack staff with the correct expertise .
3 A New Profession
Curators in the digital world are going to need multiple skills, ranging over technology, science, and librarianship.
(1) Technology
Digital material is stored in formats on media. Somebody working with pictures needs to understand what “jpg” is, for example, and a wide range of material will require knowledge of XML and related metadata languages. A curator will also need some background in databases, although the details of locking and updating are not relevant with read-only material. Curators will need to know about cloud storage vs. on-site storage, and the basics of system administration if the library is not outsourcing all its computing configuration. All of this information is independent of the kind of material being stored or the uses to which it is being put. The conventional education for such a position is an undergraduate computer science or information management degree, but these courses often include more programming than is really needed to be a data curator. In a smaller institution, the website design and maintenance may be done by the same staff that does data curation; in a larger institution these are likely to be separate, removing a major part of the additional technical knowledge requirements. Purely data curation is not likely to require a high level of programming expertise, needing only the abilities to use scripting languages to arrange to copy data or validate that a copy was done correctly.
(2) Subject Matter
Data from scientific projects is often created and used by people with a great deal of technical sophistication. Curators may not have to be astronomers, but if they do not know the meaning of terms like “right ascension” and “declination”, they will not know what the databases in astronomy are about. Taking librarianship itself as an example, understanding a MARC record requires knowledge of book formats, the conventional distinctions between authors, editors, and publishers, and the meaning of terms like “quarto” and “12mo”. This part of the curator’s knowledge base is the most fragile, since often a researcher will be trying to preserve data where many of the details of the data collection are only in the researcher’s mind. A pile of questionnaires, to be preserved properly, needs to come along with an explanation of who answered them and how those people were selected. That means that a data curator needs an understanding of research procedures in the relevant scientific area, as well as an understanding of how to use research results. This kind of knowledge traditionally comes with training in the specific subject area, and perhaps even an advanced degree. Again, however, some of the training required to perform one’s own experiments in chemistry or biology is beyond what is needed to understand, exploit, and preserve the datasets that result from those experiments.
(3) Librarianship and Archiving
A digital collection needs to have users in the future. Otherwise, there may be no point in preserving it. How can someone today judge what is needed tomorrow? So curators need the skills of interacting with users, of choosing material that tomorrow’s users will want, and of organizing information so that users can find it and assess its value for their purposes. Particularly for numerical scientific data, some creation of metadata is needed. Textual data can usually be searched by simple string matching, with some minimal contextual help (in the area of the English stage, Alan Ayckbourn’s name is unique, while Neil Simon has to be distinguished from Paul Simon) . Numbers are much less amenable to string search; 72 could be a temperature, a price, a distance, or a vast set of other possibilities. So although we see libraries skimping on metadata for conventional book and journal collections where text search will substitute, scientific data files will require considerable library-generated metadata. Conventionally, the skills of selection, user interaction, and metadata are taught in a library and information science program at the master’s level. Those programs often teach some skills, such as children’s librarianship, that will not be frequently used by a curator of advanced scientific data archives.
So what will be the background of a data curator in the future?.
One possibility is that all curatorial institutions in the digital future will employ teams of at least three people, dividing the necessary skills among them. This will imply that data curation is a task only for fairly large institutions, something which poses difficulties of its own. Individual scientists in small colleges and universities still have their own research projects; we would not like to forget the history of geniuses like Darwin, working alone in his house outside London, or Mendel, minding his peapatch by himself. How will their data be preserved if their local library has abandoned the idea of data curation because it can’t afford a team of experts? There is an administrative solution which involves consortia of libraries, and that may be the best solution, but it is not going to appeal to some libraries which want to advertise their individual contributions to knowledge preservation.
So the other choice is that we try to teach one curator something about all three areas. Should this involve training a librarian or archivist in database methods and a scientific subject area, or educating a scientist in librarianship, or teaching a computer expert about both science and archives? Some of this may be a question of the background the student already has, since given the amount to be learned this is going to be a graduate rather than undergraduate program.
My suspicion, however, is that the employment situation in the different areas will be determinative. As of summer 2012, to take an example, chemists have an average salary of ﹩75 000; “database administrators” are paid ﹩76 000; while librarians get ﹩57 000 and archivists ﹩50 000[ 5]. Meanwhile, typical salaries for digital curators are ﹩53 000[ 6]. People are not, in general, going to leave careers paying over ﹩70 000 to join a career paying ﹩53 000. So I would expect that the typical new digital curator will be from an archival/library background.
This is also a good match to where curation is likely to be done. Scientific research groups do not have experience with long-term preservation, and in fact are often short-term themselves. Every research group is familiar with pressures to be “transformative” rather than “incremental” and university administrators similarly want to develop new areas rather than strengthen old ones. Libraries and archives at least understand the concept of being around in fifty years. It’s acceptable for a researcher in chemistry or oceanography to think “Après moi, le deluge, ” but not for a librarian .
4 Career Path
In addition to the training history of data curators, it remains unclear what kind of career path will be available to them. Is data curation something to be done when starting out, when mature, or throughout a career? It is possible to imagine any of these as realistic. For example, scientists ending a research career could move on to data curation, as they sometimes now move on to education. Or, data curation could be a kind of training for new laboratory workers, as part of understanding the entire flow of research knowledge from its generation to its future users. Today, archiving is often intermixed with history, with archivists moving between history and archival studies. Allen Weinstein, the 9th Archivist of the United States, was formerly a history professor at Boston University and Georgetown University, while his predecessor Robert Warner became a professor at the University of Michigan after leaving NARA.
The situation today is sufficiently unknown that all one can realistically say is that we should not set up administrative roadblocks to any of these choices. A scientist who works in data curation should not be viewed as “leaving” science, nor should data handling be thought of as so specialized that its practitioners would be ineligible for library management positions.
An example of the current attitude is the following sentence about Helen Berman, the Director of the Protein Data Bank, written by a blogger who admired her but wrote “One of the remarkable things about Helen is that her life has been devoted to service within science rather than, as some might call it, doing real science”[ 7]. This sort of feeling will not encourage scientists to view working to preserve data as a suitable step in a career, as (for example) a temporary position at NSF or other government agencies might be viewed .
5 How Big is the Problem?
A key issue in planning for data curation is that we do not know how we will organize and fund the activity. To some extent, that depends on how expensive it is. A few years ago I looked for papers reporting the cost of data curation as a fraction of the cost of the original research whose data needed preservation. The numbers ranged from 3% to 30%, with the higher numbers representing cases where very sophisticated database systems were built to manage and deliver the data.
Among the larger numbers, Jim Gray commented[ 1] that the cost of the software for the Virtual Observatory was greater than the cost of the telescopes. Similarly an estimate for the cost of the software for the Square Kilometer Array radiotelescope was 20% of the project cost[ 8]. One physics experiment at Oxford incurred 73% of their cost collecting data, and then 24% on beginning the curation[ 9]. The ocean observatory (Project Neptune) puts 30% of its budget into cyberinfrastructure.
Among smaller numbers, most high energy physicists estimated their curation costs at under 10%[ 10] and an archive of information about mice spent 13% of their funding on information handling[ 11]. There is a special NSF grant supporting the “Curation of National Antarctic Collections” at about ﹩300K per year while just one Antarctic project, the Dry Valley project, has more than ﹩1.5M per year in funding. At Cornell, 11 staff on the DataStar effort support more than 70 researchers. At the University of Essex, a data archive aiming to preserve all results from UK social science research spends about £8 million per year, which is about 4% of the total UK social science funding. Eric Snajdr recently described putting ornithological data into an archive, which he did part-time by himself for a group of ten people (implying a curation cost of 5% or so of the research cost) . The smallest number I have seen is an estimate that 2 staff out of 730 at the European Southern Observatory are doing curation, but in this case the curation is only the linking of telescopes to the papers published based on their use[ 12].
Lower costs are associated with projects that cover a large number of similar datasets, such as the UK economic and social data archive. This data set, as with the similar materials at ICPSR, are also somewhat less technical. What is harder for an outsider to judge is whether, when the archive is separate from the data gathering, considerable curation work is being done by the researchers and not reflected in the archival cost estimates.
Realistically numbers like 30% are not affordable; it is unlikely that we will be cutting back research by more than 1/4 in order to save the detailed data from the 3/4 that remains. Among other tasks, we need to learn how to streamline and simplify data curation. Libraries must develop the expertise not just to do this job, but to do it more economically. Fortunately, they have another related area in which to practice.
6 Analytics in Libraries
As mentioned earlier, libraries need to curate their own data. As many other websites do today, libraries can improve their web service by monitoring usage. Basic statistics include visits, page views, and the IP addresses of visitors. By looking at what parts of the site are most popular, a library can give readers quicker access to the parts of the site they most frequently visit. For example, the Rutgers Newark law library revised its website by replacing a list of headlines with the most viewed parts[ 13]. See below for an image of the old (left) and new (right) pages (Figure 1) .
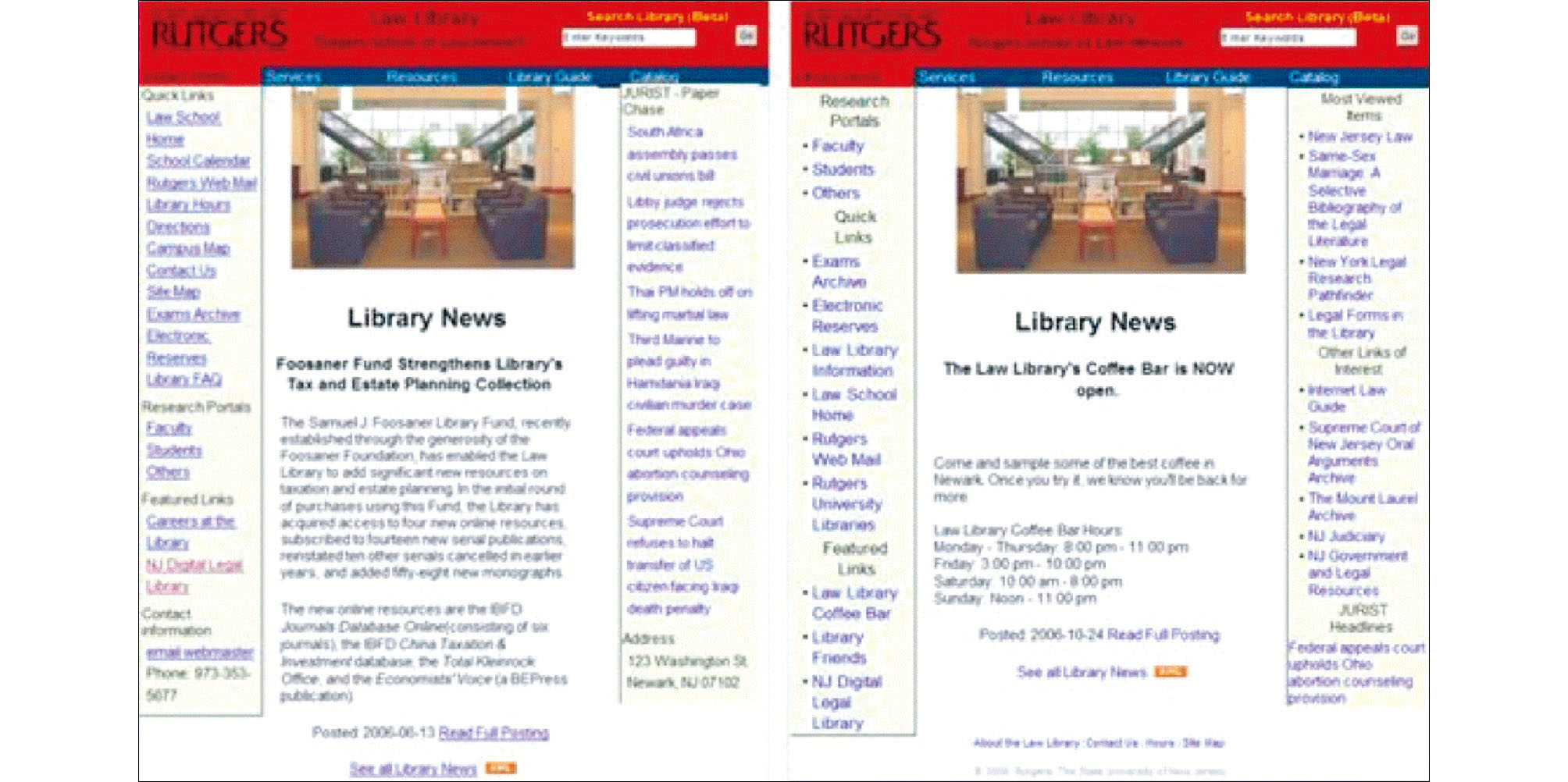 | Figure 1 Headline Web page changes through analyzing the usage of data: An example of Rutgers Law Library’s news page change |
{kind=link}
The major issue for libraries is to preserve patron privacy, a more important consideration than in many commercial services. Libraries typically do not keep long-term records of who has read what books or articles, even though this would improve recommendations that could be given, and even though companies such as Amazon.com do this routinely. There are, however, many recommendations and improvements that can be based on overall statistics without reflecting information about individuals. As an amusing example, the travel site Orbitz recently reported that Mac users tended to book more expensive hotel rooms than PC users, and so it would be showing them higher-grade hotels. And libraries do count usage figures for their services to know which are candidates for expansion or cancellation.
Other aspects of user identity may be less controversial, such as approximate geographic location. Figure 2 shows which states dominate searches for the names of some authors using “Google Insights for Search”:
 | Figure 2 Visualization of searcher’s geographical.distribution from Google Insights for Search. |
{kind=link}
It is straightforward to gather information about the IP address and thus approximate location of a user and then tailor displays. For example, the Powerhouse Museum in Sydney will show the location and hours of the physical museum more prominently to a user in the local area than to one connecting from a different continent.
The significance of analytics for libraries is that the skills needed for this work are similar to data management skills, and if, as is likely, all large libraries are doing web analytics, they are employing people who have that set of skills, and combined with librarianship, are 2/3 of the way to being scientific data curators.
7 Conclusion
Data curators are going to be needed on a large scale. The ARL libraries in 2009 had a total budget of ﹩3.1B, while the budgets of NSF and NIH combined is about ﹩38B. Thus, if even 3% of the research budget is going to be spent on data curation, that would be over ﹩1B and would compare to about 1/3 of the ARL libraries budget. The need is going to be phased in, since many NSF data management plans do not provide for deposition of data in a repository until the project terminates. In addition, some part of the data curation may well be taken by various other institutes, whether government agencies such as NCBI or consortia such as the Virtual Observatory. Nevertheless, universities are likely to need substantial increases in data curation staff.
In addition to research data, there are many commercial data warehouses; the largest commercial systems are larger than the research systems. The Large Hadron Collider may be saving 15 petabytes/yr, but Google processes 24 petabytes/day. The National Climatic Data Center has 1.2 PB[ 14], but Wikipedia says that World of Warcraft has 1.3! So the demand for work in the “big data” area is likely to be growing rapidly, and departments of library and information science should be preparing to train the staff to do this work.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|