




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向关联数据的引文知识链接模式研究*
引用本文
高劲松, 梁艳琪, 马倩倩, 周习曼, 付旭雄. 面向关联数据的引文知识链接模式研究*. 现代图书情报技术, 2013, 29(3): 21-26
Gao Jinsong, Liang Yanqi, Ma Qianqian, Zhou Ximan, Fu Xuxiong. Citation Knowledge Linking Mode for Linked Data. New Technology of Library and Information Service, 2013, 29(3): 21-26
Permissions
Gao Jinsong, Liang Yanqi, Ma Qianqian, Zhou Ximan, Fu Xuxiong. Citation Knowledge Linking Mode for Linked Data. New Technology of Library and Information Service, 2013, 29(3): 21-26
面向关联数据的引文知识链接模式研究*
摘要
在分析传统引文知识链接模式的基础上,提出基于关联数据的引文知识链接模式,利用文献知识点抽取、文献信息语义化、知识链接发布、知识源链接及获取技术整合不同学科知识资源,构建语义Web环境下的知识网络。最后结合Parliament和OpenURL对该模式进行实验验证。
关键词:
关联数据; 知识链接; 引用文献
Citation Knowledge Linking Mode for Linked Data
Abstract
This paper proposes a citation knowledge linking mode based on linked data after analyzing the traditional citation knowledge linking, which integrates knowledge sources of different disciplines to build knowledge network in the Semantic Web environment by using technologies of literature knowledge extraction,literature semantization, knowledge linking publishing,knowledge source linking and obtaining. Finally, an experiment which unites Parliament and OpenURL is given to test this mode.
Keyword:
Linked data; Knowledge linking; Citation
1 引 言
知识链接是指将具有同一、隶属、相关、类似等关系的知识节点或者由知识节点组成的知识单元按照一定的规则关联后形成有序的、结构化的知识网络。引用文献(Citations),又称参考文献(Bibliographic References),是专业人员为撰写或编辑论著而引用或参考的其他专业人员的文献资料[ 1]。而引用文献知识链接(简称引文知识链接)是指利用文献之间的互引关系建立的文献知识网络。
从目前学术资源网站的内容组织中可以看出,当前引文链接所链接的知识包括引用文献的元数据信息、引用文献的链接信息(包括文献知识单元、知识单元的关系等),所采用的链接方式主要是对原始文章到其所引用文献的前向链接和后向链接,通过引证关系来建立知识之间的关联关系。这种链接模式通常将引文知识链接的相关信息保存在后台数据库中,使得这些信息无法有效共享和显性表达,从而导致不同文献的知识整合和互联的困
难,形成文献知识孤岛,因此难以形成包含语义的、互联的学术知识网络。
语义Web技术的发展为引文知识链接提供了新的构建模式。首先,本体技术能够为引文知识链接显性地定义丰富的语义信息,并将这些信息以文件形式进行存储,通过模式匹配等方式对不同文献资源库进行整合和互联;其次,关联数据提供一种将引文知识链接本体和本体相关的引文知识链接数据进行发布和有效链接的方法,发布的数据具有明确的语义信息,从而能够进行正确、有效的互联互通,最终形成一个语义化的、互联互通的引文知识网络,从而更加有效地分享和获取引用文献学术资源。相关研究包括Sanderson等[ 2]总结出RDF是建立表达语义和知识关系的模型,DOI和CrossRef可以用所建立的数字物体唯一标识体系来固化相互之间的引用关系;贺德方等[ 3]提出以引文链接为基础,结合主题链接、行为关联链接、本体链接等关联方式实现基于引文的知识链接;赵火军等[ 4]提出利用科学文献引文链提取文献特征句子和参考文献特征句子,并表示成本体,准确表达文献中的知识单元;姜永常[ 5]提出利用Protégé技术实现基于知识元语义链接的知识网络。
近年来,基于知识链接、关联数据、引文分析的理论研究比较多,而基于关联数据的引文知识链接研究相对缺乏,没有将关联数据、引文知识链接较好地引入到知识服务领域。因此,本文在传统引文链接模式的基础上,将关联数据引入到引文链接构建中,并定义其构成模块,从而提出一种新的引文链接模式,为建立语义的、互联的学术知识网络提供一种新的思路和方法。
2 传统引文知识链接模式
.
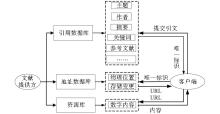
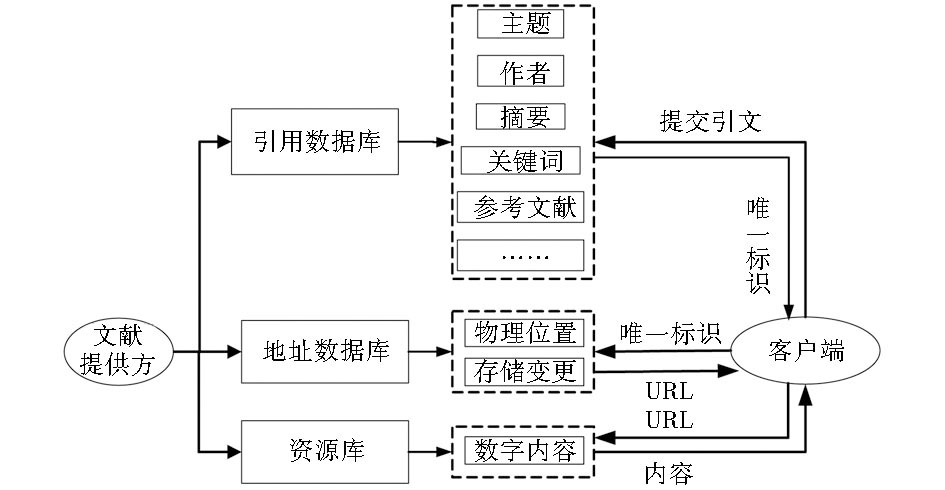 | 图1 引文知识链接的一般模式结构 |
如图1所示,传统引文链接模式结构包括引用数据库、地址数据库和资源库三个部分。引用数据库主要是对学术文献进行属性析取,即将原始文献中的主题、作者、摘要、关键词和参考文献等文献索引词汇抽离出来进行存储,客户端可通过对该库文献索引词汇的查询获取相应的文献唯一标识;地址数据库中存放着文献物理位置信息,用户可通过对该库的查询获得与某唯一标识符相对应的URL信息并通过修改其信息来反映物理位置的变化;资源库中存放着链接对象即文献本身,可通过URL直接定位获取。这样用户通过对这三个数据库的查询,可从文献元数据信息中得到其唯一标识符,从而得到其URL地址信息以最终实现对该文献的定位及访问。
从图1可以看出该模式方便易行,有利于学术资源的获取,但也有不足之处:
(1)缺乏对引用文献知识节点的语义描述。传统引文知识链接模式中,引用文献知识节点的关联方便用户获取更多信息,但是并没有实现语义链接。由于引用文献知识节点缺乏有效的语义描述,引用文献的相关信息如文献的标题、关键词、摘要、作者信息、作者机构等不能被正确、全面地理解,从而导致不同知识源间融合和互联的困难。
(2)采用封闭式静态参考链接技术。引文链接模式构建的主要目的是为了实现检索的高效性和准确性,但是现有链接模式采用封闭式静态参考链接,链接目标在链接前已经生成并存储起来,而且链接资源局限于文献所及范围,链接系统对使用环境不具备开放式的适应性,资源链接仅靠链接信息提供者来设定[ 6]。
3 关联数据在引文知识链接中的作用
关联数据是国际互联网协会(World Wide Web Consortium, W3C)推荐的一种用来发布和链接各种数据、信息以及知识的规范,希望在当前Web的基础上,通过数据之间的关联性,构建一个映射所有自然、社会和精神世界的Web of Data[ 7]。关联数据已经被不少学者证明是可行且非常实用的,它在语义Web实现的过程中起到了不可或缺的作用。
关联数据主要利用URI、HTTP、RDF等技术对现有的Web信息资源进行整合分析,从而建立语义关联,实现Web上的各种数据、信息和知识的最佳共享性[ 8, 9],其在引文知识链接中的作用主要表现在三个方面:
(1)对文献知识单元进行有效的组织。关联数据在数据层建立了链接机制,数据的结构信息被很好地描述,并通过URI来确保机器能够链接各种数据,为信息聚合的智能化和自动化提供了基础[ 10]。图书馆利用关联数据中的关联关系,能够对文献知识单元进行有序组织、集成和关联,并深入分析知识单元内容的表示,实现不同类型知识单元的整合,为用户提供一种多样化的知识关联集成服务。
(2)实现引用文献之间的动态链接。关联数据利用分布数据集及其自主内容格式,采用标准的知识表达规则和检索协议,并结合知识资源可逐步扩展的机制来实现图书馆内学术期刊引用文献之间的动态链接,形成一个可动态关联的知识网络[ 11],并在此基础上对引文知识链接的知识组织和知识发现起到了一定作用。
(3)采用开放式链接扩大引文知识链接的使用范围。图书馆引进的期刊文献库不仅要为用户提供高质量的知识资源,同时也要提供来自其他机构文献知识资源的相关链接,并且能够通过链接到这些知识资源的上下文信息来扩大引文知识链接的使用范围[ 12]。利用关联数据技术可以将不同机构的文献信息资源发布成关联数据,通过开放式链接扩大了用户获得引用文献的空间范围[ 13],同时链接目标可以综合反映链接信息提供者、客户端的信息环境等。
4 基于关联数据的引文知识链接模式
4.1 链接内容
.
与传统的引文知识链接不同,基于关联数据的引文知识链接具有丰富的语义信息,这些信息用于描述引文间的各种关系。这些包含语义信息的关系将各种引文以及引文中的知识单元进行链接,最终形成一个语义化的引文知识网络,从而能够优化引文知识查询,方便引文知识的集成。
基于关联数据的引文知识链接内容主要有:
(1)节点文献。节点文献在链接模式中比较特殊,具有自相关性,即节点文献既可以是知识链接的起源,也可以是知识链接的对象。在关联数据描述中,节点文献是三元组(Triple{Subject,Predicate,Object})中的Subject或Object。
(2)引文知识单元。引文知识单元是节点文献中有引用标识的特征句子。在关联数据描述中,引文知识单元通过“引用”和“被引用”与节点文献进行知识链接。
(3)引文知识链接。引文知识链接定义了节点文献、引文知识单元的各种描述特征和关系,是区别于传统引文知识链接的关键。引文知识链接的数据表现方式为引文知识本体及本体实例。
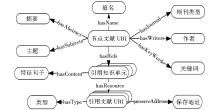
上述内容的关联结构如图2所示。每个节点文献可以引用多个引用知识单元,每个知识单元对应一个引文文献。通过这种关联单元,文献间建立起一个引用文献知识链接网络。
 | 图2 引文知识链接内容的关联结构 |
节点文献本身由一个唯一标识的URI来表示,节点文献的主题、作者、关键词、篇名等各种描述特征通过RDF三元组来表示。引用知识单元是一个用引用符号(如[N])标识的特征句子,将节点文献和引用文献进行关联。引用文献需要明确两点:类型,用于定义引文知识链接的上下文,即表明引用文献是哪种引用文献,如引证文献、共引文献、二级参考文献等类别;引用文献地址,用以记录引用文献的数字保存地址,通过该地址能够获取引用文献的电子版本。
4.2 链接方式
关联数据能够将引文知识链接赋予语义,并在Web上进行发布和关联,但其本身并不提供引文知识链接构建模式。因此,为了能够实现开放式引文知识链接,必须将依据关联数据设计和发布的引文链接数据同OpenURL结合。
OpenURL是一种开放链接环境下提供定位服务的服务组件和信息资源之间的互用性协议,是信息资源整合、关联的重要工具[ 14]。本文将OpenURL同关联数据进行结合,利用关联数据发布的语义化引文知识链接数据作为OpenURL的查询信源,通过OpenURL技术将语义化文献信息同外部资源进行知识链接。采用这种链接方式,用户获得的引文URI是一种动态、开放、语义化的URI。
4.3 链接模式结构
.
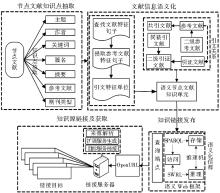
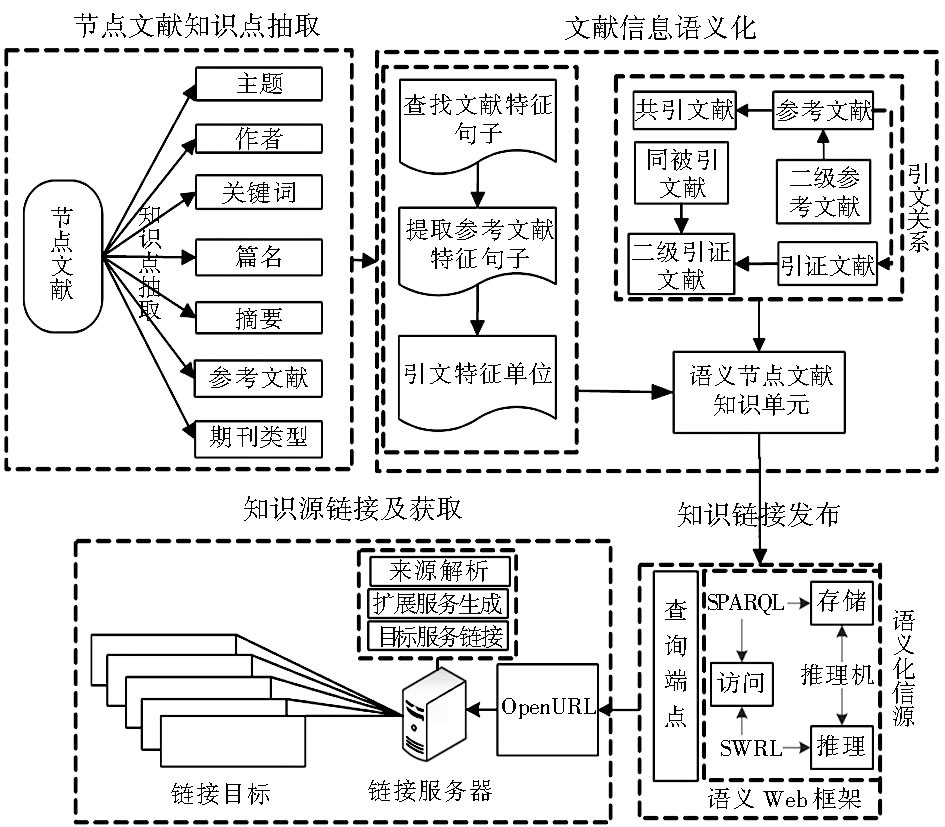
基于关联数据的引文知识链接模式如图3所示:
 | 图3 基于关联数据的引文知识链接模式结构 |
可以看出,这种新的引文知识链接模式主要分为4部分:节点文献知识点抽取、文献信息语义化、知识链接发布和知识源链接及获取。
(1)节点文献知识点抽取.
主要是对原始的节点文献进行知识点抽取,把节点文献的各个基本知识要素抽离出来进行最小知识单元分析,即将文献抽离为主题、作者、关键词、篇名、摘要、中图分类号以及期刊类型等能对文献分析起关键作用的几部分。
(2)文献信息语义化.
文献信息语义化是利用RDF和本体技术对文献信息进行描述,显性地、以机器可读的方式表达文献信息的属性特征和关联关系的过程。该过程分为三步:
①查找文献特征句子,通常在期刊文献中引用其他参考文献时会通过一系列标记符注明出处(如标记符[N]),那么就可以抽取文献中含有标记符的句子,如果句首是连词,抽取出该句及其前一句子;
②提取引用文献特征句子,利用特征句子中的标记符和文献结尾处参考文献的对应关系,查找到参考文献中与前面提取的某个句子对应的句子;
③根据抽取出来的参考文献特征句子定义为引用特征单位,作为引用知识元。
经过这三步就形成了语义化的节点文献知识单元,其结构见图2。此时语义节点文献中的知识单元之间存在了语义关系,从而便于机器的理解和辨识。
(3)知识链接发布.
主要是将语义节点文献进行知识发布。首先利用语义Web框架将语义化文献进行管理,包括对语义化文献的存储、推理、查询;然后通过关联数据技术在查询端点进行发布,实现Web环境下的数据浏览与检索。
关联数据浏览与检索通过SPARQL标准对RDF信息进行检索和解析来实现[ 15]。RDF浏览器、SPARQL查询客户端以及传统的HTML浏览器都可以是查询端点,一般情况下机构组织都是采用支持关联数据的浏览器来实现文献之间的检索和关联。
(4)知识源链接及获取.
知识源链接就是将以关联数据规则发布的知识源进行聚类、自动索引和分类处理,按照文献特征和知识属性进行链接关联。知识源链接及获取过程中主要涉及到的技术是OpenURL,将OpenURL嵌入到引文知识链接模式当中,能够实现文献资源外部关联化。本部分包括OpenURL模块、链接服务器模块和链接目标模块。
①OpenURL模块实现外部资源同语义化文献资源的通信[ 16]。本模块通过SPARQL语法进行关联数据的查询,并以符合OpenURL协议的格式进行包装,从而向用户发布OpenURL Hook。
②链接服务器模块对OpenURL进行解析,获得请求对象的元数据和上下文信息。同时利用设定的资源和推理规则,链接服务器利用扩展服务生成器构造链接服务列表。
③链接目标模块是链接服务器中存储的链接目标,一般是一个指向外部资源的链接,通过该链接可以获得语义化文献关联的外部资源。
4.4 链接模式实现
.
.
为了验证图3所示的链接模式,首先对实验环境进行搭建,即搭建语义服务器来对基于关联数据的引文知识链接数据进行管理和发布,搭建OpenURL环境并将其同语义服务器进行链接;需要依据图2构建基于关联数据的引文知识链接数据,包括引文知识链接的本体和实例数据,并将其存入语义服务器中;最后给出基于SPARQL语法的引文链接数据的查询实验,从而验证模式的可行性。
(1)实验环境搭建.
本实验采用的语义服务器为Parliament,它是语义Web框架,能对语义化文献进行存储、推理和查询,实现对语义化文献知识的管理。OpenURL是一种开放链接框架,它能够将外部资源同语义化文献资源进行链接,实现两者之间的通信。
①Parliament的配置。Parliament是在Apache-Tomcat服务器环境下运行的[ 17],首先在Windows7操作系统中运行Tomcat服务器进程,然后启动Parliament语义服务器。设置完成后在Web浏览器地址栏中输入:http://localhost:8080/parliament,进行本实验的验证。
②OpenURL的配置。本实验所使用的OpenURL参照校内用户的配置标准(华中师范大学数字图书馆数据库中的URL)进行配置。如 “https://vpn.ccnu.edu.cn/,DanaInfo=lks.cnki.net+index.html?title%3DResearch%netware%26sid%3DSc%20ChinaC”,呈现了解析器到一个/一组与资源有关的服务器地址“lks.cnki.net+”,包含创建OpenURL信息系统的信息 “vpn.ccnu.edu.cn”及资源描述部分 “title%3DResearch%……”。
(2)实验数据.
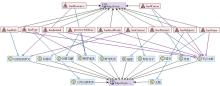
以Springer数据库中有关Computer Science的期刊论文作为数据源,并按照图2所示的关联结构在Protégé软件中构建引文知识链接数据。图4为根据本体构建原则构建的引文知识链接本体模型,图5为依据图4构建的部分实例数据。
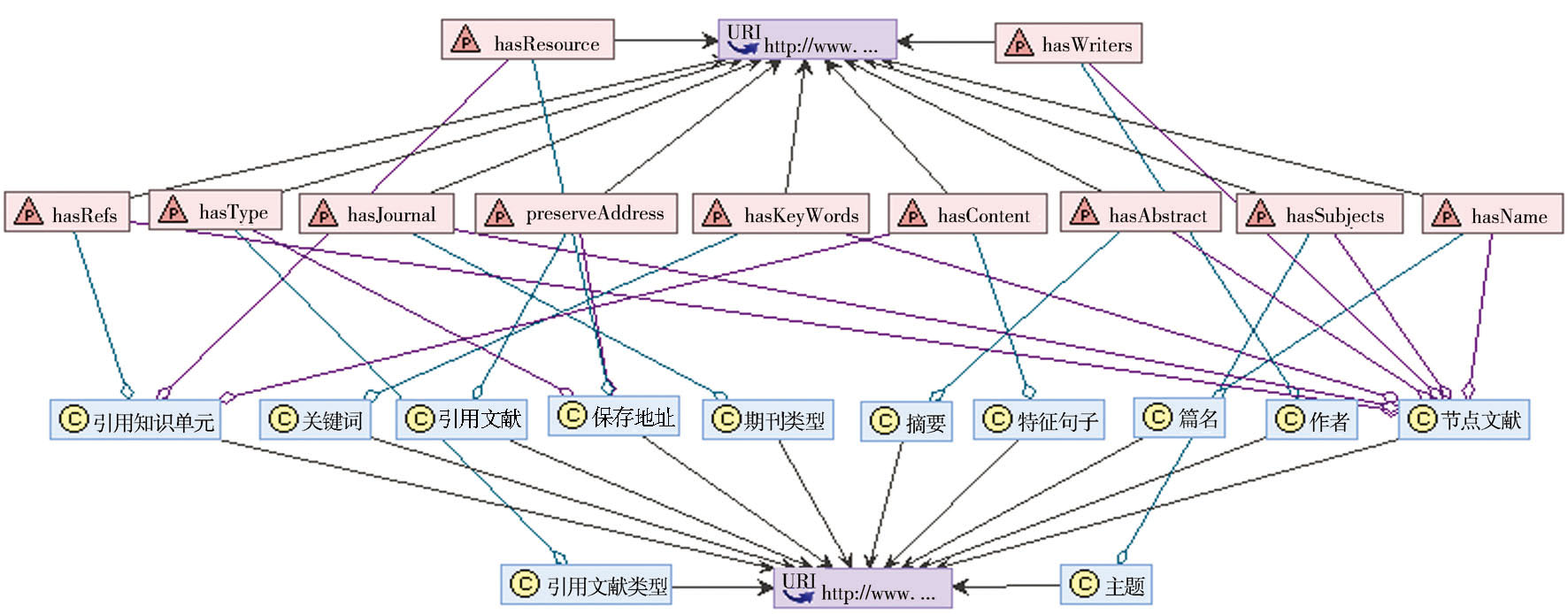 | 图4 引文知识链接本体模型 |
(3)基于SPARQL的数据查询.
图6至图8是在Parliament 语义服务器中分别以节点文献的作者、篇名、URI、引用知识单元、引用知识单元链接文献的URI作为检索词所呈现的部分查询结果片段。通过OpenURL协议标准对上述检索结果进行包装,并传输到OpenURL解析服务器,解析服务器通过解析OpenURL中带有的标准化参数,为用户提供引文知识链接的元数据和链接信息。
 | 图6 以作者、篇名、URI为检索词的检索结果 |
 | 图7 以引用知识单元为检索词的检索结果 |
 | 图8 以引用知识单元链接文献的URI |
为检索词的检索结果.
5 结 语
从知识服务的角度来看,基于关联数据的引文知识链接模式是一种新颖的、具备可行性的文献信息服务模式,弥补了现有的引文知识链接模式的不足,从而使用户更方便、直接、快速、有效地获取文献知识资源。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|