
{kind=link}
{kind=link}
{kind=link}
融合语义相似度的商务情报链接分析算法研究
引用本文
何超, 张玉峰. 融合语义相似度的商务情报链接分析算法研究. 现代图书情报技术, 2013, 29(3): 27-32
He Chao, Zhang Yufeng. Research on Business Intelligence Link Analysis Algorithm Combining Semantic Similarity. New Technology of Library and Information Service, 2013, 29(3): 27-32
Permissions
He Chao, Zhang Yufeng. Research on Business Intelligence Link Analysis Algorithm Combining Semantic Similarity. New Technology of Library and Information Service, 2013, 29(3): 27-32
融合语义相似度的商务情报链接分析算法研究
摘要
针对传统链接分析算法存在的链接丢失问题和语义异构问题, 设计基于语义相似度的商务情报链接分析算法。该算法综合应用锚链文本和锚链结构信息解决链接丢失问题, 应用领域本体提供语义知识解决语义异构问题。实验结果表明, 该算法能够显著提高商务情报分析结果的准确性。
关键词:
商务情报; 语义相似度; 链接分析
Research on Business Intelligence Link Analysis Algorithm Combining Semantic Similarity
Abstract
A business intelligence link analysis algorithm based on semantic similarity is designed for the problem of link lost and semantic heterogeneity in the traditional link analysis algorithm. The algorithm exploits anchor chain text and structure synthetically to solve link lost, uses semantic knowledge presented by domain Ontology to solve semantic heterogeneity. The experiment results show that the model and the algorithm achieve a good expected effect and can raise the accuracy and efficiency of business intelligence analysis.
Keyword:
Business intelligence; Semantic similarity; Link analysis
1 引 言
链接分析是指利用数据挖掘技术对Web结构中的超链接进行深入挖掘分析, 获取链接中隐含知识的一种智能化挖掘方法[ 1]。目前, 链接分析作为一种重要的智能信息分析方法, 在许多领域都有广泛的研究和应用, 显示出巨大的商业价值和发展潜力[ 2, 3]。然而, 传统的链接分析算法, 如HITS算法[ 4]、PageRank算法[ 5]等, 由于没有充分考虑页面的语义信息, 在实践中易受无关链接的影响而产生主题偏移和垃圾链接, 并且在进行主题相似度的计算过程中, 由于存在语义异构问题, 导致计算结果局限在关键词层次, 无法提供语义层次的概念计算[ 6]。不同领域的专家学者对此提出了一些改进算法, 如马丽[ 7]提出的融合语义相似度的HITS算法, 利用知网提供语义知识进行链接锚相关文本与特定查询主题的相似度计算;马慧芳等[ 8]提出的增量PHITS模型能够将链接结构的动态变化信息融入主题相似度计算中, 解决传统链接分析过程中的链接丢失问题。目前研究存在的主要问题是链接分析过程中仅仅依靠锚链文本、URL字符串、链接环境进行主题相似度分析[ 9], 虽然可以快速确定当前链接与目
标信息是否主题相关, 但在实际的情报分析过程中, 有些重要链接虽然和当前主题无关, 但经过若干链接后又会到达目标页面, 从而导致传统的链接分析算法在执行过程中常常会丢失一些重要的链接, 影响情报分析结果的准确性和全面性。针对上述问题, 本文利用课题组前期构建的领域本体[ 10]提供语义知识, 综合利用当前锚链文本和锚链结构方面的研究成果分别计算其对应的主题相似度, 然后将两者的计算结果进行综合, 得到整体的主题相似度值, 解决传统链接分析算法中的重要链接丢失问题和语义异构问题, 实现商务情报语义链接挖掘和综合分析。
2 商务情报语义链接分析算法
基于语义相似度的商务情报链接分析算法 (Business Intelligence Link Analysis Algorithm Based on Semantic Similarity, BILAABSS) , 针对传统的链接分析算法主要利用锚链文本或锚链结构进行链接主题相似度分析所存在的链接丢失问题和语义异构问题, 借助领域本体提供语义知识, 利用锚链文本进行当前页面链接与主题的语义相似度计算, 利用锚链结构进行页面链接的趋势分析, 综合两者的相似度分析结果得到最终的链接主题语义相似度。锚链文本与主题的语义相似度计算方法, 主要根据课题组前期所研究的文本相似度计算方法进行实现;锚链结构与主题的语义相似度计算方法, 主要借鉴张乃洲等[ 11]提出的Q学习算法进行实现。
2.1 商务情报语义链接分析流程
.
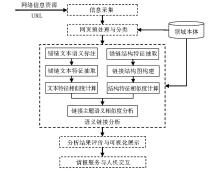
商务情报语义链接分析流程, 如图1所示:
 | 图1 商务情报语义链接分析流程 |
主要包括5部分内容:信息采集、网页预处理与分类、语义链接分析、分析结果评价与可视化展示、情报服务与人机交互。其中, 信息采集主要根据企业自身的经营战略和商务情报需求确定原始信息采集的主题、范围、信息源和种子URL, 借助智能代理软件Crawler进行自动化、系统化、连续的链接信息采集;网页预处理与分类主要是将采集到的网页进行初步清洗, 剔除Web页面中由于商业目的或其他原因而嵌入的诸如广告链接、导航栏、友情链接等与主题无关的链接, 利用基于SVM的分类技术进行分类, 发现和提取包含潜在主题相关的目标页面及其链接;语义链接分析利用领域本体提供语义知识, 综合利用锚链文本和锚链结构进行主题相似度计算和情报发现;分析结果评价与可视化展示主要是从分析结果中筛选出符合企业要求的、有意义的、能够满足战略决策需求的情报知识, 存储并以可视化的方式展现分析结果, 如利用本体提供的TGVizTab、OntoViz、OWL2Prefuse、Graphviz等插件从语义层面进行多层次的分析结果可视化展示, 揭示分析结果中存在的潜在语义模式和深层知识;情报服务与人机交互主要是将分析结果提供给企业用户实时检索与共享, 情报专家也可将检索结果作为人工分析的依据, 在此基础上进行情报可信性判断和情报价值增值。限于篇幅, 本文主要研究该流程中的语义链接分析方法, 该方法主要包括锚链文本与主题的语义相似度计算和锚链结构与主题的语义相似度计算两部分内容。
2.2 锚链文本与主题的语义相似度计算
锚链文本与主题的语义相似度计算过程主要由三部分组成:
(1) 利用领域本体丰富的概念层次结构和语义知识对锚链文本数据集进行语义标注, 识别和抽取重要的概念及其关系, 构建锚链文本的概念特征向量;
(2) 针对企业目标主题所存在的认识模糊性和局限性, 利用领域本体和通用本体相结合的方式进行主题特征向量的构建和优化, 使其能够在语义层面上反映企业的情报需求;
(3) 考虑到构建的锚链文本概念特征向量和主题特征向量可能存在维度差异, 利用领域本体指导锚链文本概念特征向量与主题特征向量的维度转换, 使其能够在相同维度上进行相似度计算, 在此基础上利用语义核函数进行锚链文本概念特征与主题特征的语义相似度计算。该过程的算法描述如下:
算法1 Semantic Similarity Computing between Anchor Text and Topic.
输入:锚链文本数据集D= (d1, d2, … , dD) ;领域本体H;通用本体O;主题特征概念集C= (c1, c2, … , cC) .
输出:锚链文本与主题的语义相似度Simanchor (dt, ci) .
(1) 对锚链文本数据集D= (d1, d2, … , dD) 进行分词, 去除停用词等处理后, 得到锚链文本的概念特征向量V= (v1, v2, … , vV) ;
(2) 利用领域本体H和通用本体O相结合构建主题特征向量:
①获取所有主题对应的概念集合{Coni1, Coni2, … , Conin};
1) 对于主题领域强相关的类别ci, 采取自上而下的策略遍历领域本体H, 获取描述该类别名称的主要概念集合;
2) 对于主题领域弱相关的类别cj, 采取相同的方式遍历通用本体O, 获取描述该类别所对应的概念集合;
②对概念集合{Coni1, Coni2, … , Conin}中的每个元素, 解析领域本体或通用本体, 获取每个元素对应的所有直接或间接子类概念{Coni11, Coni12, … , Coni1m}和各个类或子类的属性集合{Proi1, Proi2, … , Proik};
③构建主题ci的类别向量{Coni1, Coni2, … , Conin, Coni11, Coni12, … , Coni1m , Proi1, Proi2, … , Proik };
④确定主题向量中各分量的权重值:
1) 针对每个向量利用本体逆映射技术获取概念特征对应于整个数据集中的词语特征;
2) 利用词语特征在已标注类别的训练数据集中的频率信息和权重调节因子确定与该特征对应的概念分量在类别向量中的权重取值, 计算公式为:
wij (Con/Pro) =∑nk=1tfidf (word, tik) n·δ.
其中, tik表示属于类别ci的第k个训练文本, n表示属于类别ci的训练文本数, tfidf (word, tik) 表示word在文本tik中的tfidf权重值, δ为权重调节因子。
⑤通过上述处理获取主题ci的向量空间模型可表示为ci={ (Coni1, wi1) , (Coni2, wi2) , … , (Conij, wij) , … , (Conis, wis) }, 其中Conij表示本体中的类或属性, wij表示该类或属性的权重取值;
(3) 基于语义相似性的锚链文本与主题的相似度计算:
①锚链文本概念特征向量与主题概念向量的维度转换;
②利用语义核函数进行概念特征dt与主题ci的语义相似度计算, 计算公式为[ 12]:
Simanchor (dt, ci) =K (dt, ci) K (dt, dt) , K (ci, ci)
K (dt, ci) =dTtPTPci.
其中, K (dt, ci) 表示语义核函数的表现形式, P为相似度矩阵, PT为P的转置矩阵。
2.3 锚链结构与主题的语义相似度计算
锚链结构特征的相似度计算主要利用网页预处理与分类模块得到的结果页面中的链接结构构建Web链接结构图, 通过基于Q学习的Web链接结构图增量学习算法进行链接与链接主题相似度之间的映射关系挖掘, 实现当前页面链接与Web链接结构图的链接空间映射, 获取当前链接的主题结构相似度。该过程算法描述如下:
算法2 Semantic Similarity Computing between Anchor Structure and Topic.
输入:锚链结构数据集S= (s1, s2, … , sS) ;领域本体H;通用本体O;主题特征概念集C= (c1, c2, … , cC) .
输出:锚链结构与主题的语义相似度Simstructure (si, ct) .
(1) 构建锚链链接结构图Gw:
①利用网页解析工具Htmlparse将Web页面解析为DOM树节点, 提取Anchor Text、URL、Context等特征信息构建任意链接的链接结构表示模型M<Anchor Text, URL , Context>, 其中, Anchor Text表示链接st的锚链文本, URL表示链接st对应的URL字符串, Context表示链接st在当前页面中的环境;
②通过对链接结构表示模型M进行解析, 获取链接结构信息LinkTable<ID, url, parentID, depth, anchor Text>和经过初步分析得到的结果页面ResultTable<ID, urlID>
③利用ResultTable中的urlID在LinkTable中找到与之对应的parentID, 然后在LinkTable中找到parentID的parentID, 通过这种类推方式反向构造出所有从结果页面到种子URL的路径, 实现链接结构图Gw的构建和优化;
(2) 采用与算法1中相同的方法将主题特征概念集映射为主题概念向量ci={ (Coni1, wi1) , (Coni2, wi2) , … , (Conij, wij) , … , (Conis, wis) };
(3) 基于Q学习算法的锚链结构与主题的相似度计算:
①初始化锚链链接结构图Gw, 对任意<si, sj>, 设置Q (si, <si, sj>) =0, 对Q (si, <si, sj>) 进行n次更新操作, 设置计数器Counter=0和更新标志bFlag=false;
②任取Gw中除叶节点外的未被计算的节点si, 计算Q (si, <si, sj>) , 计算公式为:
Q (si, <si, sj>) =r (si, <si, sj>) +γmax<sj, sm>∈EQ (sj, <sj, sm>) .
③若回报函数r (si, <si, sj>) 中的sj∈T, 立即回报值设置为rd=k, 否则rd=0;若si的当前Q值与计算值不同, 则更新si的Q值, 并设置更新标志bFlag=true;
1) 判断更新标志bFlag=true是否成立, 若成立, 则判断Counter的值是否为n, 若成立, 则计算Q (si) , 其计算公式为:
Q (si) =max<si, sj>∈EQ (si, <si, sj>) .
2) 若更新标志bFlag=true不成立或Counter的值不为n, 则设置Counter=Counter+1, bFlag=false;
④经上述处理, Gw中除叶节点外所有节点都被计算后, 返回计算结果Q (si, <si, sj>) 和Q (si) , 则Simstructure (si, ct) 的值为:
Simstructure (si, ct) =Q (si) ×Simanchor (si, ct) .
3 实验与结果分析
为验证本文算法的有效性与效率, 在Eclipse平台上利用Java语言进行算法的原型系统设计与实现。实验环境如下:处理器Inter (R) Core (TM) 2CPU 4400 2.0GHz, 内存2GB, 硬盘120GB, 操作系统为Windows XP, 编程语言为Java (JDK 1.6.2) 。
3.1 实验数据
.
本文实验共有三个数据集:页面分类器训练数据集TrainSet、种子URL数据集URLSet、目标主题页面URL数据集TargetSet。为充分反映所设计的算法在不同领域的分析效果和质量, 选取三个主题域 (笔记本电脑、智能手机、数码相机) 进行实验。采用深度优先策略进行链接抓取;采用非递归策略利用队列进行链接管理来实现爬虫程序, 经过数据清洗与选择, 共获取9 000个页面和15 000个URL。三个数据集的基本构成情况分别如表1、表2和表3所示:
| 表1 页面分类器训练数据集TrainSet |
| 表2 种子URL数据集URLSet |
| 表3 目标主题页面URL数据集TargetSet |
3.2 实验设计
为了检验本文算法的实际运行效果, 选取链接分析领域常用的分析算法——HITS算法、PageRank算法、Hilltop算法与本文设计的BILAABSS算法在相同的实验环境和数据集上进行对比实验。利用平均收益准确率 (harvest_precision) 模拟准确率指标, 计算公式为[ 13]:
harvest_precision=∑i∈NpiN.
其中, N表示系统已经分析过的页面集合, pi表示页面与主题的相似度, 若页面i与主题相似, 则pi=1, 否则pi=0。
利用平均目标召回率 (target_recall) 模拟召回率指标, 计算公式为[ 13]:
target_recall=T∩CtT.
其中, T是指目标页面URL的数据集TargetSet, Ct表示系统分析结果页面所对应的URL集合。
3.3 实验结果
.
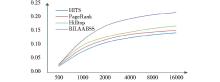
在上述实验数据集上进行4种算法的对比实验, 实验结果分别如表4、图2和表5、图3所示:
| 表4 不同算法在三个主题域上的平均收益准确率对比 |
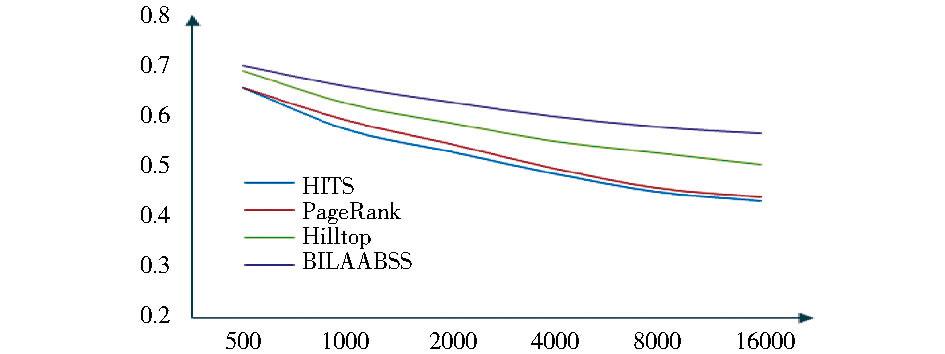 | 图2 平均收益准确率变化趋势 |
| 表5 不同算法在三个主题域上的平均目标召回率对比 |
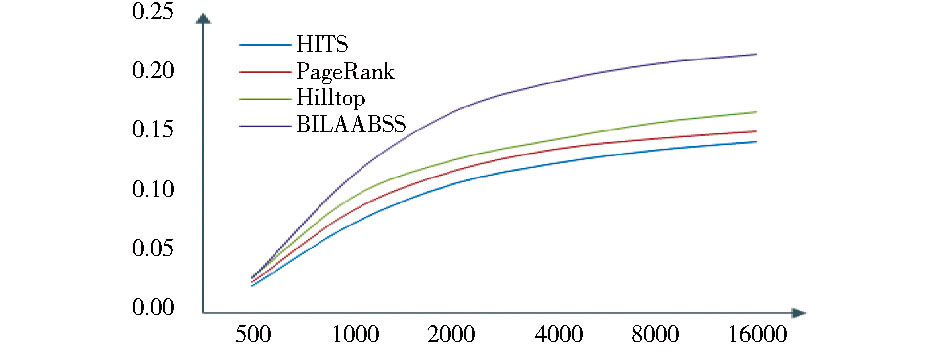 | 图3 平均目标召回率变化趋势 |
3.4 实验结果分析
本文主要从平均收益准确率和平均目标召回率两个方面对实验结果进行分析:
(1) 平均收益准确率分析.
表4和图2展示了4种不同的链接分析算法在三个不同主题域上取得的平均收益准确率及其变化趋势, 可以看出, 随着页面数量的增加, 4种链接分析算法的平均收益准确率都呈现下降的趋势, 但不同算法的下降幅度有所不同。其中, HITS算法和PageRank算法下降趋势较陡峭, Hilltop算法和BILAABSS算法下降趋势较平缓, 主要原因在于HITS算法在执行过程中仅根据网页之间的链接结构来分析页面的权威性和重要性, PageRank算法主要根据Rank值进行网页的重要性排序, 容易造成部分Rank值比较低但非常重要的网页丢失, 所以这两种算法的平均收益准确率随着页面数量的增加, 下降趋势比较明显。而Hilltop算法在执行过程中比较关注主题相关网页之间的链接对应权值计算的贡献, 能够避免通过增加无效链接来提高网页的Rank值, 所以其平均收益准确率的下降趋势较平缓;BILAABSS算法综合利用锚链文本和锚链结构进行链接页面与主题的综合性分析, 利用领域本体进行语义层面的相似度计算, 能够有效地提高平均收益准确率水平, 所以, 随着页面的增加, 其平均收益准确率的下降趋势最平缓。
(2) 平均目标召回率分析.
表5和图3展示了4种不同的链接分析算法在三个主题域上取得的平均目标召回率及其变化趋势, 可以看出, 随着页面数量的增加, 4种链接分析算法的平均目标召回率都呈现上升的趋势, 即算法执行过程中, 分析得到的主题相关页面的数量增加, 使得平均目标召回率总体上也随之增加。但不同算法的上升幅度有所不同, 其中, HITS算法、PageRank算法和Hilltop算法上升的幅度较平缓, BILAABSS算法的上升幅度最明显, 其主要原因在于随着网页数量的增加, BILAABSS算法比其他三种算法具有更高的准确度和分析深度, 能够获取的主题相关页面也越多, 分析结果页面所对应的URL集合增加程度高于其他算法, 即在T相同的情况下, BILAABSS算法的T∩Ct增加更快, 从而使得其执行效果相对于其他算法而言最好。
4 结 语
本文针对传统链接分析算法存在的链接丢失和语义异构问题, 设计了基于语义相似度的商务情报链接分析算法进行语义层面的商务情报链接挖掘和智能分析。该算法在领域本体的协助下, 综合应用锚链文本和锚链结构进行深层次的链接挖掘和深层情报知识发现。通过在三个主要域上进行实验表明, 该算法能够显著提高商务情报分析的准确性和效率, 在一定程度上实现了商务情报的智能分析和自动获取。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|