
{kind=link}
{kind=link}
{kind=link}
面向汉语句法功能分布知识库的词汇类别知识挖掘研究*
引用本文
王东波, 朱丹浩. 面向汉语句法功能分布知识库的词汇类别知识挖掘研究&*. 现代图书情报技术, 2013, 29(3): 33-37
Wang Dongbo, Zhu Danhao. Research of Mining the Word Category Knowledge for Chinese Syntactic Function Distribution Knowledge Base. New Technology of Library and Information Service, 2013, 29(3): 33-37
Permissions
Wang Dongbo, Zhu Danhao. Research of Mining the Word Category Knowledge for Chinese Syntactic Function Distribution Knowledge Base. New Technology of Library and Information Service, 2013, 29(3): 33-37
面向汉语句法功能分布知识库的词汇类别知识挖掘研究*
摘要
基于清华大学汉语树库,通过多叉树存储结构,构建汉语词汇的句法功能分布知识库。在构建的句法功能分布知识库基础上,利用Sparse Feature Clustering(SFC)中的K-medoids聚类算法,对汉语词汇的类别知识进行挖掘探究。
关键词:
树库; 词汇句法功能; 知识库; SFC
Research of Mining the Word Category Knowledge for Chinese Syntactic Function Distribution Knowledge Base
Abstract
According to the Chinese word syntactic function distribution, the paper constructs syntactic function distribution knowledge in multi-way tree storage structure base based on Tsinghua treebank. The Chinese word category knowledge is mined by using the K-medoids clustering algorithm of Sparse Feature Clustering based on syntactic function distribution knowledge base.
Keyword:
Treebank; Word syntactic function; Knowledge base; SFC
1 引 言
随着自然语言处理和文本挖掘技术的发展,从非结构化文本中挖掘和抽取相应的专门或通用知识以便更好地服务于基础和应用研究日益成为一种趋势。本文基于清华大学树库,通过SFC(Sparse Feature Clustering)中的K-medoids聚类算法,在汉语词汇句法功能知识库的基础上,挖掘词汇具体类别知识;挖掘的类别知识不仅可以应用到中文信息处理的汉语句法结构歧义消解上,而且对于构建大规模精确度更高的汉语树库具有重要的促进作用。
关于依据词汇句法功能对整个汉语词汇进行分类,相关的研究者进行了多方面的探究。在朱德熙提出利用词汇的句法功能进行分类的设想基础上,从词汇句法功能要为汉语完全自动句法分析服务这一目的出发,陈小荷[ 1]给出了主要依据汉语词汇的句法功能分布对汉语主要实词词汇进行分类的理念。从上述词汇句法功能的设想和理念出发,基于人民日报大规模语料,徐艳华[ 2]在计算机的辅助下,通过手工逐一分析一般名词、动词、形容词以及高频副词的语法功能,并完成3 514个常用汉语词汇的简单语法功能数据库的构建。陈锋等[ 3]基于清华树库的短语结构在句法库中所充当的句法功能,详细考察介宾结构、主谓结构、定中结构、述宾结构、述补结构和状中结构的句法功能。卢俊之等[ 4]在获取词汇和短语结构句法功能分布的基础上,基于句法功能匹配的理论,主要使用消歧算法,构建汉语自动句法分析器。上述研究者在基于汉语词汇句法功能的基础上,从理念、人工分类和应用的角度,对整个汉语词汇的分类问题进行探索和研究,本文正是在上述研究基础上的一个延续。在具体的研究过程中,使用相应的聚类算法从词汇句法功能知识库中挖掘出相应的词汇知识。关于聚类算法,国内外研究者在单语和双语上都进行了多方面的探究。崔尚卿等[ 5]从基于密度的聚类算法本身存在的问题出发,提出不均匀密度的自动聚类算法。王伟[ 6]从各个角度对文本聚类的技术进行综述,关注文本聚类中的文本聚类定义、文本预处理、文本特征抽取和文本聚类的各种算法中的各方面问题。王舵等[ 7]针对聚类速度慢、初值对结果的影响大、易陷入局部最优等问题,提出基于相似度测度和覆盖方法来解决上述问题。潘章明[ 8]将基于差分进化的自动聚类算法和半监督方法结合起来,在具体的实验中,启发式地引入部分已经获得了带标签的数据,聚类的精确度也得到了有效的提高。于洪等[ 9]从面向知识的聚类框架出发,使用决策粗糙集理论对聚类算法进行研究,并且考虑了一种特定的损失函数。在单语文本的聚类研究中,国外的相关学者[ 10, 11, 12]给出了各种文本聚类的方法以及相应的改进算法,而双语文本或多语文本的聚类,则相对比较复杂。采用“先聚类后合并”的策略,Chen等[ 13]通过计算簇间相似度,把中文的名词、动词主要实词和命名实体译成对照的英语,在单语简单聚类和合并聚类簇的方法前提下完成了对英汉双语新闻的自动聚类。在机器翻译系统的基础上,结合双语词典,Leftin[ 14]在把Russian和English两种文本中的词汇完成全部对照的前提下,开发了面向这两种语言的文本自动聚类系统。在把目标语言翻译成英语的基础上,Evans等[ 15]设计了Columabia’s Newsblaster系统,用来进行新闻摘要和话题的自动生成。通过借助语言分析,Mathieu等[ 16]从文本中抽取相应的特征词,在相对应的双语词典基础上,完成了英文、法文和西班牙文混合文本的自动聚类。
2 汉语句法功能知识库构建
本文有关汉语词汇类别知识挖掘的研究是在清华汉语树库[ 17]上测试、验证的,同时研究构建了清华汉语句法功能知识库。
2.1 数据源简介
.
按照完整的层次结构描述方法,在16种汉语短语成分标记和27种句法结构关系的前提下,清华大学计算机系智能技术与系统国家重点实验室在以文学、学术、新闻、应用4种体裁构成的汉语平衡语料基础上构建了一个100万字的汉语树库。其短语句法结构分布如表1所示:
| 表1 清华汉语树库短语句法结构分布 |
2.2 汉语词汇句法功能获取和汉语句法功能知识库构建
.
.
.
基于词汇句法功能统计的需要,结合清华汉语句子树的特点,本文中多叉树被用来存放整个句法树,并使用树遍历算法遍历每一棵句法树,从而可以便捷地对句法树的短语结构或词汇功能进行存储、统计、编辑和删节等。
清华汉语句子树使用对称的标记符号“[ ]”标记了句法结构的起始和结尾。从多叉树数据结构特点出发,结合语料库标记,构建句法多叉树的流程如下:汉语句子构成一棵多叉树;每个短语结构标记构成多叉树中的非叶节点;每个词汇或者标点符号构成叶节点。基于已有的清华汉语句子树,在多叉树存储结构上,通过设计程序完成清华汉语句子多叉树的构建工作,算法流程如图1所示:
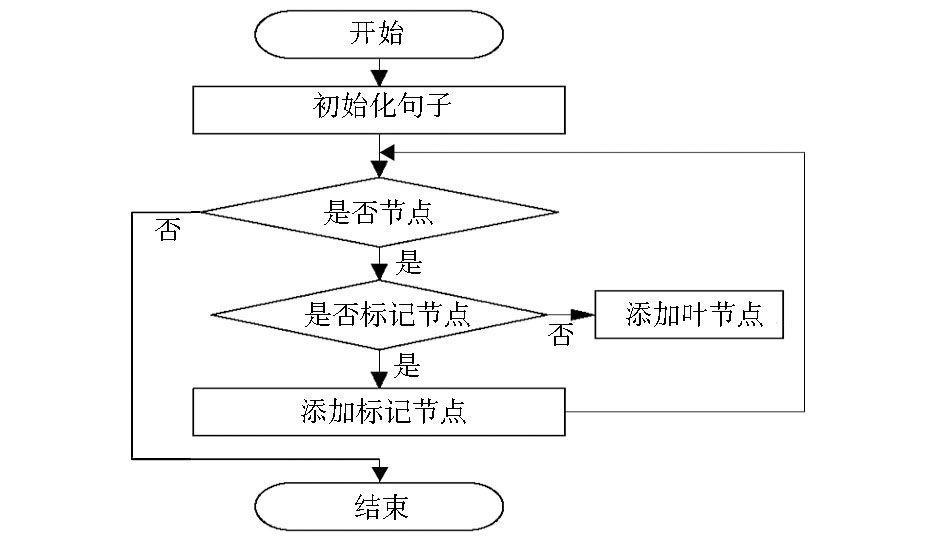 | 图1 汉语句子树生成流程 |
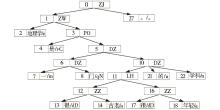
根据图1所示的流程和句法树构造算法,完成对汉语句子的树构造,具体例子如下:“ZJ [ZW 地理学/n [PO 是/vC [DZ [DZ 一/m 门/qN ] [DZ [LH [ZZ 很/dD 古老/a ] [很 /dD 年轻/a ] ] 的/u 学科/n ] ] ] ] 。/。 ]”,句法生成的树样例如图2所示:
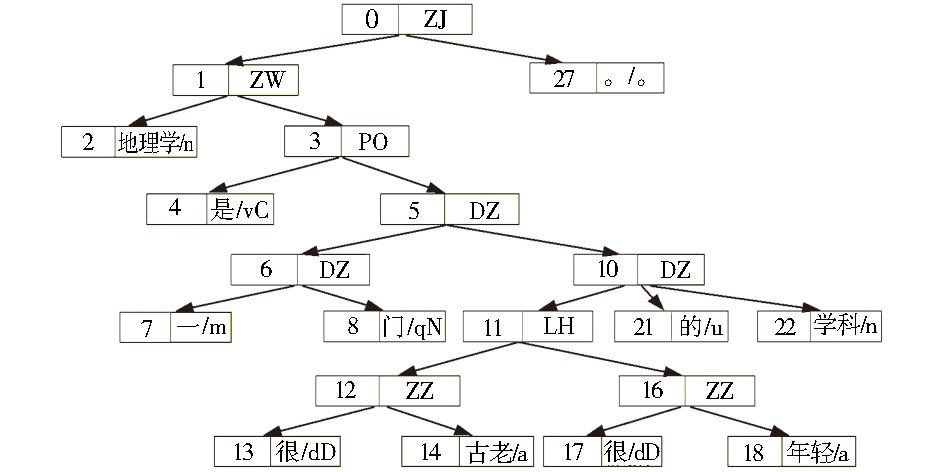 | 图2 句法树样例 |
基于汉语句子的句法生成树,使用根节点深度优先的方法,通过树检索遍历整个树结构,当遍历到叶子节点的时候,抽取词汇,并且记录其父节点所在的句法结构,如图2所示,当遍历到“一”这一词汇的时候,记录它充当句法功能的句法结构“DZ”。 在上述算法的基础上,获取了清华大学汉语词汇句法功能,并构建了词汇句法功能知识库,清华大学汉语词汇句法功能知识库的部分样例如表2所示。
| 表2 清华大学部分汉语词汇句法功能知识库样例 |
3 聚类算法简介
对汉语语法功能分布知识库进行聚类,可以将汉语词语按照其语法功能特征自然归类,从而实现基于句法功能知识库的类别知识挖掘。对建立的知识库进行观察可以发现,数据表中维度为40,共有数据51 455条,其中不为0的数据项共有104 035个。而表中总共拥有数据项40×51 455=2 058 200个,也就是说不为空的数据占总数据的5.05%。可以得出结论,该聚类问题是一个高维属性稀疏聚类问题,无法直接通过传统的低维聚类方法处理。
SFC[ 18]应用在各个维度的属性取值是区间变量的高维聚类问题上,SFC中使用K-medoids算法来聚类,在具体进行词汇类别知识挖掘的过程中,本文自定义并改进了获取medoids的算法:在每一个类U中,计算每一个对象i到其他任意对象j的距离之和s(i),选取拥有最小的距离和的节点作为新的medoid。距离和公式如下:
s(i)=j∈U,j≠id(i,j)(1).
由于在实际数据中可能存在这种情况:数据对象m和n所有值皆相同,按照稀疏相似性应该被分到一类中,然而如果初次随机抽取的medoids中既包括m又包括n,那么就会出现m和n被分到两类的情况,不符合实际情况。针对这个问题,本文在算法中改进了初始随机medoids的获取算法:设定一个阈值μ,在随机获得medoids时,如果获取的任意两个medoids的稀疏差异度小于μ,则删去一个medoid,并重新获取一个,直至任意两个medoids的稀疏差异度大于μ为止。
4 词汇类别挖掘过程和结果
4.1 词汇类别知识挖掘的过程
.
K-medoids算法按一定的策略随机选择初始聚类中心medoids,聚类的结果受medoids随机选取的影响较大。因此,本文做了5组试验,设定聚类数为40。在平均经过迭代后,得到5组聚类结果。将结果按照其包含词条数目大小降序排列后,部分聚类结果统计如表3所示:
| 表3 SFC部分聚类结果统计 |
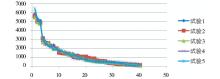
从表3的统计结果可以发现,最大分类的词条数目分别为5 805、5 611、5 466、6 010和6 425,误差在10%之内;最小分类的词条数目分别为59、98、97、204、50,最大误差为73.54。5次试验的标准差最低为1 313.368,最高为1 461.444,误差为10.13%,这说明分类结果的离散程度非常接近。图3给出了5次试验结果中分类所含词数的散点图,横轴表示分类序号,纵轴表示分类中所包含的词数。
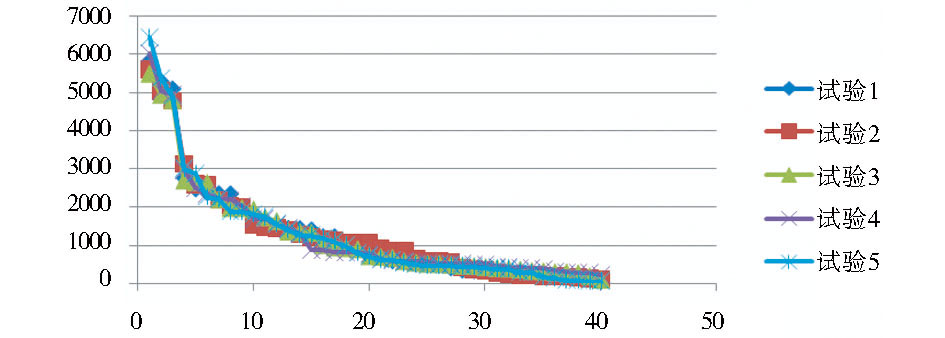 | 图3 5次试验结果分布 |
从图3中可以看出,5次试验结果中,每个分类所含词数的分布非常接近。这说明虽然medoids选取的随机性对于聚类结果有一定影响,但聚类所获得的分布还是很稳定的。
4.2 词汇类别知识挖掘的结果
在上述聚类实验的基础上,本文给出了基于词汇句法功能知识库挖掘出来的具体的词汇各类别下的前10个词汇样例,部分词汇类别知识挖掘的结果如表4所示:
| 表4 部分词汇类别知识挖掘的结果 |
通过表4所给出的10类词汇聚类结果样例可以看出,依据词汇句法功能挖掘出来的词汇类别虽然从具体的已有词性标注判断有些不属于同一类别,但从整体的分布上看,还是基本上符合句法功能分布的。如果从语义的角度考虑,通过本文的资源和方法挖掘出来的词汇类别有些确实不属于同一类别,这也从一定程度上说明仅仅依据词汇句法功能获取词汇类别知识的精确率有待提升。通过聚类方法挖掘出来的词汇类别知识是否符合汉语词汇的真实分布,需要在具体的消歧任务上进行测试,这也是下一步需要完成的工作。
5 结 语
本文基于清华汉语树库,通过多叉树存储结构,统计了汉语词汇的句法功能,并在此基础上构建汉语词汇句法功能知识库。基于SFC高维聚类下的K-medoids算法,在汉语词汇句法功能知识库的基础上,挖掘出清华汉语所有词汇的类别知识。在未来研究中,一方面将扩大树库的规模,比如把宾州汉语树库[ 19]通过结构转换增加到清华汉语树库中,同时把本文获取类别知识的方法,应用到以印欧语言为代表的英语当中;另一个方面将会把通过聚类方法挖掘到的类别知识应用到具体的句法结构消歧中,从而验证通过该方法获取的词汇类别知识的优越性。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|