{kind=link}
{kind=link}
专利文本分类的基础问题研究*
引用本文
屈鹏, 王惠临. 专利文本分类的基础问题研究*. 现代图书情报技术, 2013, 29(3): 38-44
Qu Peng, Wang Huilin. Fundamental Research Questions in Patent Text Categorization. New Technology of Library and Information Service, 2013, 29(3): 38-44
Permissions
Qu Peng, Wang Huilin. Fundamental Research Questions in Patent Text Categorization. New Technology of Library and Information Service, 2013, 29(3): 38-44
专利文本分类的基础问题研究*
摘要
对专利文本分类中的基础问题进行研究,包括术语作为专利文本分类特征的适用性,主权项字段分类研究和相近主题对分类结果的影响等。研究在两种朴素贝叶斯分类器、kNN、Racchio和支持向量机等5个分类器上进行,测试主要采用交叉验证的方法。研究结果显示,在同样的设定下,采用术语作为特征的分类结果优于使用一般特征词;使用摘要训练,对主权项进行分类有助于改善主权项的分类效果;相近主题会降低分准率,有必要设计层次的分类器进行分类试验。研究结果可以为专利文本分类研究和实践提供参考数据,并可作为信息分析等工作使用专利文本分类技术的参考。
关键词:
专利; 文本分类; 文本挖掘
Fundamental Research Questions in Patent Text Categorization
Abstract
The paper focuses on some fundamental problems in patent text categorization, including the feasibility of using terms for automatic categorization, the research on claim categorization, and the effect of classes with close-related topics on the categorization result. The research is executed on two Naive Bayesian classifiers, kNN, Racchio and SVM classifier, and cross validation is used for testing. The results of the paper are that terms are better than common features under the same settings, that training a classifier with abstracts can improve the claim categorization results, and that classes with close-related topics result in low precision and hierarchical design of classifier is necessary, correspondingly. The paper provides fundamental data for patent text categorization and can be referred by information analysis and other applications using patents.
Keyword:
Patent Text; categorization; Text mining
1 引 言
近年来,专利得到信息分析工作的重视,其重要性不亚于科技论文和科技报告。信息分析工作对专利文本挖掘的需求也更深入广泛。这种面向具体应用的文本挖掘研究通常带有“工程”性质——将已有的模型、方法应用于研究对象,验证所提出算法的有效性。但是,专利具有一定的特殊性,专利文本挖掘也因此需要解决特有的问题。
本文研究三个与专利文本分类相关的问题:
(1)使用术语作为特征与使用一般特征词的分类效果比较。通常认为术语比一般特征词具有更高的专指性,其用于分类的效果也更好。但这仅是理论推断,缺乏必要的数据支持。文本自动分类的特征选取原则是优化分
类效果,而非特征本身具有很好的性质(如专指性)。因此,有必要对术语作为特征的分类效果进行研究。
(2)主权项分类的相关问题。主权项是专利特有的字段,通常认为其用于文本挖掘的价值高于摘要。但是,主权项本身较为特殊,如它仅由一个长句子构成,在分类时可能存在特征数量不足的问题。因此,需要研究主权项分类的效果和改善等相关问题。
(3)相近主题对专利文本分类结果的影响。专利文本分类由实际需求驱动,其类目设置与专利的使用密切相关,具有相近的主题。这些相近的主题对分类结果是否有影响以及如何解决这一问题,是本文所要讨论的内容之一。同时,它又与使用《国际专利分类表》(International Patent Classification, IPC)作为分类体系有紧密关系。
尽管本文从信息分析工作出发研究专利文本挖掘的问题,但是这些问题对专利而言是基础性的,从任何角度研究专利文本内容时均不可回避。因此,本文并未冠以“面向信息分析”的定语;研究结论也基本适用于面向其他应用的专利文本挖掘。
2 本领域研究概况
目前,大部分专利文本分类研究仍注重改造已有的算法并将其应用于专利;分类体系主要参考IPC;数据来源有三种:NTCIR的数据、从专利局申请数据或从数据库下载数据。以下相关研究按其采用的类目水平由部到组的顺序做一概述。
李程雄等[ 1]使用SVM和kNN结合的方法,在7个部的8个大类下进行试验,是IPC部水平的分类研究。华南理工大学的研究团队分别使用核向量空间[ 2]和贝叶斯模型[ 3],对从广东省知识产权局获取的14 400篇专利进行分类。类目体系分别在A01、A23、A43和A61下各选取一个小类,是IPC大类水平的分类研究。蒋健安等[ 4]的层次分类法在IPC大类水平上使用余弦相似度,小类水平上使用kNN。他们的数据来自于中国专利数据库,共1 500篇;其类目体系分别选取三个大类下的各两个小类,分类结果在大类和部分小类上理想,但是在另外一些小类上分准率不高。李生珍等[ 5]使用BP神经网络,对从国家知识产权局网下载的800篇专利进行分类,其类目体系达到了IPC主组的水平。季铎等[ 6]使用kNN及其改进算法,按照NTCIR-8的规范进行分类研究,评测深度达到IPC子组,评价指标采用MAP,在小类上得到较好的结果。上海交通大学的研究团队提出一种M3SVM的分类方法,并按照NCTIR规范进行分类研究[ 7, 8]。Li等[ 9]以SVM为基础完成了NCTIR-6的F术语专利分类子任务,并认为F术语提供的信息有助于分类结果的改善。Fall等[ 10]使用SVM、朴素贝叶斯、kNN和SNoW等分类器在WIPO-alpha集合上进行试验。该集合包括114个大类、451个小类的75 250篇专利。研究结果显示:在同样的试验设置下,SVM的效果最好;IPC小类分类的结果不如IPC大类分类的结果。
除上述基于内容的专利文本分类研究之外,还有基于引用关系的分类。Lai等[ 11]依据专利之间的同引关系,使用主成份分析的方法对专利文本进行分类。Li等[ 12]则结合使用核函数和引用网络对纳米技术的专利进行分类。
以上研究虽然提供了重要的参考数据与结论,但仍是围绕模型或算法,对专利在文本分类中体现出的特点研究较少,本文则尝试在这一方面进行研究。
3 研究内容与研究方法
3.1 研究过程与试验设定
本研究由一系列分类试验构成,评价指标主要采用平均分准率。
首先实现试验所需的分类器,然后通过调节参数,使分类器达到在目前试验条件下的最优状态,在确认其能够基本满足后续研究要求的基础上,使用这些分类器进行研究。
除主权项的分类外,其余研究均使用交叉验证的方法。即在本试验中将每个类目下的专利平均分成5份,每次试验抽取其中的4份作为训练集,剩余1份作为测试集。多次试验后计算平均分准率。
本试验获得的数据集存在类目间分布不均匀的问题,采用随机抽样的方法解决该问题。即每次抽取N篇(N小于各类目下可用于训练的文档数的最小值),使每次训练时各类下的文档数量均衡。N是后续研究所使用的一个重要参数。
在主权项分类的研究中,训练集(摘要)和测试集(主权项)自然分离,没有必要使用交叉验证的方法,直接在摘要中抽取样本,同时使用全部专利的主权项用于测试。
3.2 评测集合
实验所用数据由信息分析专家根据实际需求提供,来自Innography数据库,共有与电动汽车相关的电池(Battery)、电池管理(Battery Management)、引擎(Motor)、引擎控制(Motor Control)和整车控制(VCU)5个小类共5 405条专利数据。其中,电池主要讨论电池的材料和电极等内容,电池管理则主要讨论控制电路方面的内容,因此这两个类目是并列而非上下位关系。类似地,引擎和引擎控制也属并列关系。词干还原工具采用Porter Stemmer[ 13]。
3.3 分类器
.
(1)特征选取方法.
特征选取分为三步:文本预处理,去掉无意义字符和停用词,还原词干;以词频和字符串之间的包含关系为依据,提取候选特征词(或特征术语);计算候选特征词(或特征术语)的权重,以确定用于分类的特征词(或特征术语)。
根据文献[14]定义,结合专利文本分类的试验设定,对特征术语规定如下:
①特征术语是名词词组,而一般特征词未必是名词词组。
②为达到一定程度的专指性,特征术语需要达到三个词以上的长度;对应地,一般特征词可以是任意长度。
根据此前对术语研究的结果和信息分析专家的反馈,将词长限制在5个英文单词以内。因此,术语的词长为3-5个单词;一般特征词的词长可以为1-5个单词。
候选特征采用卡方(或互信息本研究结果显示卡方和互信息的结果仅改变候选特征(候选术语)的局部排序,对结果影响不显著。因此,仅汇报使用卡方的结果。)和TF-IDF两种方法计算其权重。具体采用何种权重计算方法,以及选用特征的数量均由试验结果确定。
(2)分类器及其实现.
本文共实现5个分类器,分别是基于伯努力分布的朴素贝叶斯分类器(记作BerNB)、基于多项式分布的朴素贝叶斯分类器(记作MNNB)、Racchio分类器(记作Racchio)、kNN分类器(记作kNN)和支持多类分类的支持向量机分类器(记作SVM)。
其中,对BerNB、MNNB、Racchio和kNN分类器,笔者按照这些分类器的基本原理自行编写代码实现,没有对它们的基本算法和原理做理论层面的改动。SVM分类器在SVMLight[ 15]的基础上编写接口,调试参数,嵌入到整个专利文本分类系统之中。与通常采用径向基函数作为文本分类核函数有所不同,试验结果显示线性核函数更适应本文的专利文本分类任务,在此特别说明。
(3)现有分类器的效果.
为检验这些分类器的分类效果和适应性,选择合适的参数设置,在大量交叉验证试验的基础上得到在目前试验条件下最优平均分准率及参数设置,如表 1所示:
| 表1 当前试验条件下最优平均分准率及参数设置 |
以上结果表明这5种分类器均能适应本文试验所需的专利文本分类要求。但是,每种分类器均有提升空间。
4 结果分析
4.1 术语特征与一般特征的比较
可以看出,在同样的参数设定下,使用术语的分类效果优于使用一般特征词的分类效果。其中两种贝叶斯分类器尽管存在差别,但是使用一般特征词的分类结果基本可以接受,Racchio、kNN和SVM需要进一步对比研究。
.
该比较主要解决术语抽取对专利文本分类的意义问题。术语特征与一般特征的差别越大,说明术语抽取的研究价值越高;反之,仅使用简单切分和加权得到的短语作为分类特征即可。
参数设定与表 1相同,按照所定义的特征术语和一般特征词分别进行试验,结果如表 2所示:
平均分准率比较(%)
| 表2 使用特征术语和一般特征词分类的 |
由于表 1是按照特征术语达到最优时设置的参数,此时使用一般特征词分类可能并未达到其最优,因此使用SVM分类器对普通特征词和特征术语在平均分准率上的差别进行研究。样本数量为400,特征数量选择50、75、100、200、400、600、800和1 000。特征数量根据试验结果确定:SVM在50-1 000个特征时,其分类效果比较稳定。根据一般试验习惯,200以下的特征数量选择较为密集,其原因如下:假设最初有100个特征,减少10个特征,数量即变化10%,预计对结果会有显著影响;而当有1 000个特征时,减少10个特征的数量变化仅为1%,预计对结果的影响不显著。从图 1可知,使用术语作为分类特征的平均分准率远高于一般短语作为特征词的平均分准率。因此,在当前试验设定下,使用术语作为特征会对SVM分类器产生积极效果。Racchio和kNN的结果与此类似,但差别不如SVM显著。
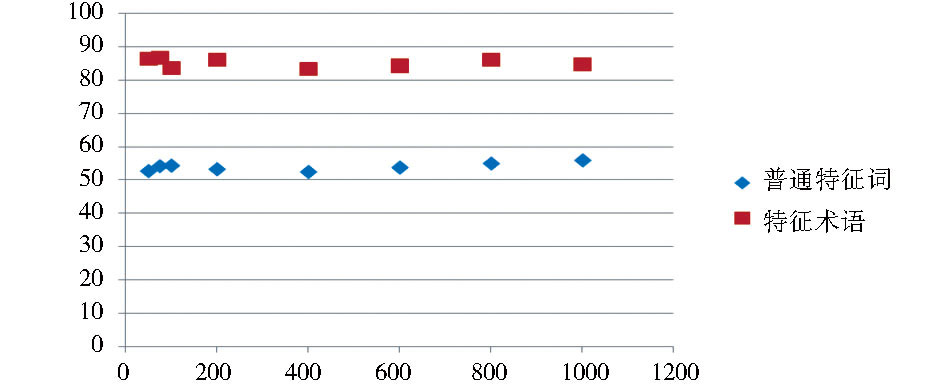 | 图1 一般短语和术语作为特征的平均分准率比较 |
(SVM,线性核函数,训练样本量400/类).
4.2 主权项分类
.
.
主权项是专利中特有的字段。该字段由一个句子构成,其中术语比摘要字段密度大,但总量小。主权项交叉分类验证试验结果如表 3所示:
| 表3 Claim字段分类平均分准率及参数设置 |
可见,对于BerNB、MNNB和SVM分类器,使用主权项训练分类器,再对主权项进行分类的效果并不十分理想。
为解决这一问题,使用摘要训练分类器,再对主权项进行分类。采用BerNB、MNNB和SVM进行分类的结果如表 4所示:
| 表4 使用摘要训练,对主权项分类的 平均分准率及参数设置 |
可以看出,对于这三种分类器,先使用摘要字段训练分类器,再对主权项进行分类的效果更好,能够达到表 3中Racchio和kNN两种分类器的效果。
尽管给出了解决方案,但仍有两个问题有待研究:
(1)使用主权项训练分类器后再进行分类的效果不佳的原因。
(2)使用主权项字段直接训练分类器时BerNB、MNNB和SVM不如Racchio和kNN的原因。
这可能均与主权项内特征的分布有关。但是目前仅为猜测,有待进一步研究。
4.3 相近主题对分类结果的影响
在本文所使用的评测数据中,电池和电池管理,引擎和引擎控制这两组类分别比较相似。由上文文献概述可知,当分类水平达到小类或者组时,分类效果会急剧下降。因此,在表 1的参数设置下,仅使用电池、引擎和整车控制这三个类进行分类试验,平均分准率如表 5所示:
| 表5 五类与三类平均分准率比较(%) |
由表 5可以看出,上述分类器对三类进行分类的效果比对五类进行分类的效果好。但是,仅此不能认为相近的类会带来噪声,降低平均分准率。表 5的结果有可能是由类的数量减少造成的。因此,选择电池、电池管理和整车控制三个类再进行试验,其中前两个类是相近的类,第三个与前两个的相似性较低。在同样的试验设定下,平均分准率如表 6所示:
| 表6 选择两个相近的类和一个非相近的类 进行分类时的平均分准率(%) |
可以看出,表 6中平均分准率与表 5中五类的平均分准率相近,而且,kNN和SVM两款分类器明显地显示出在相近的两个类中, 其中一个类分准率远高于另外一个类,这是由相近的类中特征相近所带来的噪声造成的。两种贝叶斯分类器则显示出整车控制这个
类别的分准率高于另外两个相近的类。由此,可以断定,表5中三类对五类的改善的主要原因不是由于类的数量减少(但是不排除会有微弱影响),而是去掉相近的类后噪声降低而带来的平均分准率的改善。
5 讨 论
5.1 对5种分类器的讨论
朴素贝叶斯分类器的特征数量也呈现出类似的特性,即平均分准率随候选特征数量的增加而提高。并且,不对特征进行筛选也能够达到较好的结果。
表1仅能说明分类器达到最优时的平均分准率和参数设置,但是无法说明这些分类器的特性。因此,需要进一步讨论这5种分类器的特性。
(1)两种朴素贝叶斯分类器能够达到的最优结果较为接近,其特性也十分相似。以下从特征选取和样本量两个方面讨论其特征。
在交叉验证试验的训练阶段,最小的类拥有约400多篇训练文档。因此,试验一般采用400篇作为训练样本量,以保证训练时每个类拥有相同的文档数,避免在后续分类中由训练文档数不同所导致的偏差。
但是,与预期相反,两种贝叶斯分类器均在不对训练集进行抽样,全部文档用于训练的情形下达到最优。试验数据反映出两种朴素贝叶斯分类器的平均分准率均随着训练文档数量的增加而提高。另外,从表 7中可以发现,这两种分类器仍然受到训练集合文档分布数量不均的影响,在训练文档数偏少的类上的平均分准率低于训练文档数偏多的类。
| 表7 在样本数量为1 000,不筛选特征. 的条件下每类的分准率(%) |
(2)Racchio和kNN是两种基于向量空间的分类器,它们的平均分准率基本相同。这两种分类器达到试验设定下的最好结果的条件是:
①训练时,各个类的文档数分布均匀;
②在满足均匀分布的前提下,样本量应尽可能最大;
③特征需要经过筛选,特征数量约控制在每类50个;
④筛选特征时依据卡方值,在加权时依据TF-IDF值;
⑤对于kNN分类器而言,达到最优的k值为3。
(3)SVM分类器也是一种基于向量的分类器,其平均分准率比Racchio和kNN更好。在为SVM分类器筛选特征时,通过卡方筛选得到的结果远不如TF-IDF,因而SVM通过TF-IDF筛选其特征。试验结果显示,在整个集合上为SVM分类器选择800个特征可以达到当前试验条件下的最优。需要说明的是,由于专利在不同类目的分布和重复特征等原因,不能通过“整个集合选择800个特征”而断定“每个类有160个特征”时达到最优。试验结果也显示,SVM可以在60至1 000个特征之间均达到良好的状态。
从平均分准率、样本数量和特征的数量看,在目前的试验设定下,朴素贝叶斯分类器和SVM比Racchio和kNN更加健壮。
5.2 IPC在专利文本自动分类中的作用
本文未使用IPC作为参考分类体系是由IPC本身的特点和实际数据情况决定的。信息分析专家认为一条专利拥有多个IPC分类号,同一专利在不同地区申请时,其分类号也可能不同,因此IPC更适合用于专利的检索而非分类。从实际数据看,尽管所获得的专利文本围绕电动汽车,但是其部从A至H均有,并且IPC小类所对应的专利文本数稀少,不适合用于训练。从已有的研究情况看,以IPC作为分类体系,只能在小类水平上达到理想的效果,难以深入到组一级。并且,大部分研究停留在部或者大类的水平,这相当于使用“中图法”作为自动分类的参考体系时停留在G3或者TP这样的水平上,对包括信息分析工作在内的实际应用价值不高。因此,从实际应用环境出发设置具有针对性的类目的价值更高。
5.3 分类器的适应性与层次分类
可以看出,5种分类器都能达到90%以上的平均分准率。这使得设计层次分类器成为可能。可以训练的分类器层次结构如图 2所示:
.
实际信息分析工作中需要对相近主题进行分类,常见的解决方法是设置层次分类器:先对电池相关、引擎相关和整车控制这三个类别训练分类器;然后在电池管理下训练区分电池和电池管理的分类器。
但是,上述设想取决于现有的分类器是否能够将电池和电池管理,引擎和引擎控制这种主题上相近的类区分开。理论上,由于进行具有针对性的训练和特征加权,选取的特征会不同于此前五类和顶层三类时选取的特征。试验上,在相似的参数设定下,主题相近两类分类的平均分准率如表 8所示:
| 表8 主题相近两类分类的平均分准率 |
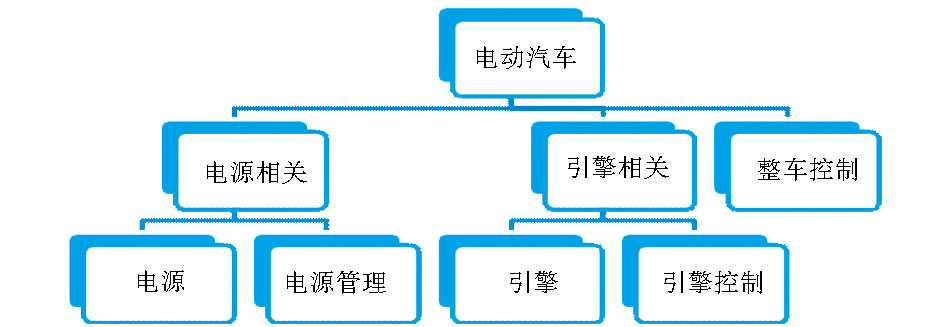 | 图2 本文研究可设计的层次分类器层次关系 |
6 结 语
对专利文本分类的部分基础问题进行研究,得到一些初步结果。专利的特殊性使专利文本分类拥有其特定的研究问题,具有理论研究的必要。本文所提的这些问题仅是专利文本分类中一些特有的需要解决的基础问题,还有其他特有的基础问题未被发现。解决这些问题,要从应用环境的角度出发,提出研究问题并给出相应的答案。
限于笔者水平和现有的试验条件,一些研究问题没有给出全面、完整的答案。在进一步的研究中,将着力解决这些问题。此外,本文的层次分类的研究尚不成熟,也将其留作进一步研究的对象。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|