


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
开源分析工具在中文文献分析中的应用
引用本文
侯月明, 乔晓东, 孙卫, 李颖. 开源分析工具在中文文献分析中的应用. 现代图书情报技术, 2013, 29(3): 71-76
Hou Yueming. Application of Open Source Analysis Tools in Chinese Literature Analysis. New Technology of Library and Information Service, 2013, 29(3): 71-76
Permissions
Hou Yueming. Application of Open Source Analysis Tools in Chinese Literature Analysis. New Technology of Library and Information Service, 2013, 29(3): 71-76
开源分析工具在中文文献分析中的应用
摘要
对开源分析工具进行初步的调研,按照工具的开放性和可扩展性选取部分分析工具,对其技术特点和功能进行简要介绍。综合分析工具的特点,提出基于中文文献的分析工具组合应用方案:根据国内主要文献数据库导出数据格式,对SciMat的数据导入和预处理模块进行扩展,使其能够直接处理中文文献;利用NWB和Sci2中集成的大量文献分析算法,对文献数据进行多角度、多层面分析;通过GUESS和VOSViewer完成分析结果的可视化,增加分析结果的可读性。最后,通过案例演示分析过程,验证该方案的可行性。
关键词:
中文文献; 文献分析工具; 文献分析; 开源软件
Application of Open Source Analysis Tools in Chinese Literature Analysis
Abstract
This paper conducts a preliminary investigation of open source analysis tools,selects part of them by openness and scalability and gives a brief introduction to their technical features and functions.After comprehensive analysis of the characteristics of the tools, this paper proposes the combined use of the tools for Chinese literature:the SciMat’s data import and pre-processing modules are expanded based on the export data formats of the main domestic literature databases,so that it can import and process the Chinese literature data directly. Integrated with a number of literature analysis algorithms, NWB and Sci2 are used to analyse literature from multi-scope and multi-level.The visualization of the results can increase the readability of the results,which is conducted by GUESS and VOSViewer. Finally, a case study demonstrates the analysis process and verifies the feasibility of the proposes.
Keyword:
Chinese literature; Literature analysis; tools Literature analysis; Open source software
1 引 言
随着我国图书情报事业的发展,中文数字文献的总量已初具规模,学位论文、会议论文和专利文献保持着高速的增长速度。研究人员在获取到更多文献资源的同时又承受着信息超载所带来的巨大压力。文献分析工作作为科学研究的基本环节,在海量信息的背景下并不轻松,文献分析工具作为一种辅助手段,可以协助研究人员完成文献分析工作,提高工作效率。随着我国文献服务水平的提高,数据开放程度不断提高,研究人员更容易获取
到所需的文献资源。以中国知网为例,可为用户提供单次500条以内的文献元数据导出服务,150条以内的文献分析服务[ 1],这为研究人员利用文献分析工具进行个性化分析工作奠定了很好的数据基础。然而,与情报分析工具相关的研究,国内还处于探索阶段,没有形成相对成熟的应用。文献分析工作更多借助于Excel、SPSS或国外的文献分析工具进行,对分析人员的专业技能要求较高。另外,现有的文献分析工具用于中文文献分析还存在一些问题:对中文文献数据库导出数据格式或中文编码支持不全面,不能实现导出数据和分析工具的直接对接;分析工具对分析人员的分析能力和计算机水平要求较高;国内相关研究相对滞后,没有形成相对成熟的分析工具。本文选取国外比较成熟的开源分析工具,针对上述问题,结合中文文献元数据特点,对现有分析工具进行扩展,探索将分析工具用于中文文献分析的可行方案,并通过简单的案例对工具的组合分析过程进行演示和实证研究。
2 相关研究
吴清强等[ 2]意识到当前情报分析过程中无法有效地集成各种不同资源、工具,提出情报复合应用框架,并从Web服务角度对情报复合框架进行初步研究。王小梅等[ 3]在现有分析工具基础上,根据各分析工具的不同特点,利用工具间的互补性,探索情报分析平台集成方案。张金柱[ 4]提出一种基于CIShell的情报分析集成框架雏形,对框架的具体实现过程没有再进行细化和深入研究。
国内相关研究相对较少,并以探索性研究为主,研究成果的开放性普遍较低,而国外相关研究较多,形成了一些相对成熟的工具。笔者从工具的开放性、可扩展性和功能互补几个角度选取部分工具,如表1所示:
| 表1 常用分析工具 |
其基本功能和特点简要介绍如下:
(1)NWB(Network Workbench)与Sci2 (Science of Science Tool).
NWB(http://nwb.cns.iu.edu/)和Sci2(https://sci2.cns.iu.edu/)同为印第安纳大学网络科学中心研究成果。NWB是一个全面的网络分析、建模和可视化工具。该工具集成了生物医学、文献计量学、社会科学和物理学研究的一些常用分析算法。Sci2是对NWB在科学计量、文献计量分析领域的定制和扩展,支持基于时间序列、地理位置、网络分析等多层面的文献分析,提供科学文献的宏观、中观和微观的可视化分析。这两款工具很好地集成了许多常用的网络分析和科学计量的分析算法,用户可以进行分析对象和分析方法的任意组配,分析过程的灵活性较好,但是研究人员需要了解分析方法的使用,因此对使用人员的分析能力要求较高。
(2)SciMat.
SciMat(http://sci2s.ugr.es/scimat/)是一个开源的基于时间序列的知识图谱(Science Mapping)绘制工具。该工具采用Java编程语言开发,代码规范,可读性好;接口设置灵活,扩展性好;内置数据库用于文献元数据的管理,文献数据本地存储,有利于个人文献库管理。可视化采用基于密度和中心度的战略坐标图(Strategic Diagram)、聚类网络和演化图等,支持分析结果的导出。用户界面友好,操作简单,分析过程采用引导方式进行,每个过程提供相应的选项供用户选择。工具涵盖常用的文献分析方法,集成科学计量相关指数(如h指数),丰富了聚类过程中的测度指标。目前该工具支持的文献数据导入格式只有三种,中文文献数据源不支持相应格式数据的导出。
(3)VOSViewer.
VOSViewer(http://www.vosviewer.com)由荷兰雷登大学科学研究中心(CWTS)开发,支持大规模数据处理,主要用于科学图谱的绘制,可以构建期刊、作者等的共被引网络和基于关键词的共现网络。该工具界面友好,分析过程有引导提示,图形化展现方式较为丰富,分析结果可以通过标签视图(Label View)、密度视图(Density View)、聚类密度视图(Cluster Density View)和散点视图(Scatter View) 4种视图展示,显示清晰,分析结果易于解释,而且分析算法的选择空间相对较少,分析过程的透明性相对较差,使用简单,对使用者的专业知识要求相对较低。
(4)GUESS.
GUESS (http://graphexploration.cond.org)是一个网络可视化工具包,界面友好,可以通过界面和脚本控制网络的布局、位置、大小和颜色等,集成强大的图形操作语言,可以轻松实现对网络图中节点和边的操作。能够实现生成图的缩放,支持生成大型网络,集成多种网络分析算法,降低了网络分析的难度,生成图可以多种格式导出,操作简单,可视化效果较好。
3 分析工具组合策略研究
NWB和Sci2的优势在于其文献分析方法体系相对全面,集成了许多文献分析和网络处理算法,可以任意组配,从不同侧面对文献进行分析,分析功能相对全面,完成了对GUESS的集成。SciMat在数据管理和预处理方面表现优异,用户可以根据不同的分析问题构建不同的项目(Project),可以方便地实现项目数据和分析过程的导入导出。数据管理面板可以实现记录的删除和更新。元数据采用分组管理,分析过程以分组为基本单位,有效地解决了实体名称的规范问题、相同概念的甄别问题。采用内置数据库对文献数据实行本地化管理,因此该工具还可用于用户个人文献管理。在数据预处理方面,该工具内置数据批量管理和替换功能和一些相似概念的监测算法,辅助分析人员完成数据的分类和预处理工作。另外,该工具在文献计量网络的生成、相似度的测量、标准化和网络处理方面细节处理的较好,用户的选择相对更多。VOSViewer和GUESS在其图形化展示方式上互补性很强,表现方式各有侧重,可以在分析结果的可视化方面相互借鉴。
综合以上分析工具,针对国内主要文献数据库导出文献格式,对SciMat数据导入模块进行扩展,针对中文文献增加一些可行的数据预处理方法,提高数据预处理的效率和准确性;利用NWB和Sci2中的网络处理算法和文献计量分析算法,降低分析的难度;利用VOSViewer和GUESS增加分析结果的可读性。然后按照文献分析基本流程,对扩展和应用过程进行简要说明。
3.1 数据获取
(注:统计时间为2013年2月20日星期三。).
中国知网、万方数据和维普数据库均支持不同程度的数据导出服务。国内主要文献数据库的文献导出格式统计表如表2所示:
| 表2 中文文献服务机构文献导出格式统计表 |
可知这些数据库均支持EndNote格式数据导出,为方便中文数据的导入分析,对SciMat导入数据支持格式进行扩展,增加EndNote数据导入格式。
扩展过程如下:
(1)获取SciMat的源代码,获取地址参考SciMat官方网站。
(2)增加EndNoteLoader类,结合EndNote元数据格式,实现GenericLoader中的相应方法。
(3)在MainFrame类中增加相应的监听方法,完成窗体按钮的初始化。
(4)在ImportFileTask类中增加相应调用方法。
(5)重新编译,导出项目。
3.2 数据预处理
数据预处理是文献分析的基本环节,数据预处理的水平直接影响到分析结果的准确性。由于中、英文语言的特点,中、英文文献的预处理方法存在很大差异,同时,国内文献数据服务商导出数据格式各异,针对英文的数据预处理方法并不完全适用于中文文献数据预处理,因此需要在SciMat基础上进行扩展,扩展工作如下:
(1)增加中文分词功能,主要针对共词分析,用于关键词(主题词)提取。
(2)增加中文词典库,主要包括术语库、地理信息库、学者库、机构库等。增加相关词典不但可以增加分词结果的准确性和规范性,而且有利于相同实体(概念)的监测和甄别。
(3)文本处理和抽取功能,主要包括批量查找、替换和更新,按照特定的规则完成特定字段的提取,如通讯地址中地名、机构名等的提取。
(4)增加数据格式转化功能,通过对数据格式的转化,保证与分析功能输入格式的一致性。
3.3 文献分析和可视化
完成数据的预处理后,文献分析阶段处理好数据的输入和输出问题。首先要了解分析方法的基本功能,保证分析方法的正确运用。其次要了解分析对象、数据格式和方法参数,保证数据输入的正确性。最后处理好数据的输出,保证分析结果的可读性和易读性。SciMat在数据的可视化方面表现一般,可将分析结果导出为Pajak格式,通过 GUESS和VOSViewer相关工具对分析结果进行解读。
4 案例分析
研究领域分析主要包括研究方向的把握,研究热点的监测,新兴研究主题的跟踪,核心作者、学术圈子的发现等,研究领域分析对科研人员研究方向的确定、研究工作的开展至关重要,而文献分析是研究领域分析的重要手段。通过对相关文献进行分析,以可视化的方式表现出来,给研究人员一个更加直观的参考。
以文献计量学、科学计量学和信息计量学(简称“三计学”)研究为例,简要说明文献分析的过程和方法。
4.1 数据获取与预处理
所用数据均源自中国知网中国学术期刊网络出版总库,假设该库检索结果涵盖全部相关文献。主题词为“文献计量学或科学计量学或信息计量学”,期刊为核心期刊,发表时间为1980年到2012年,相关文献共计1 777篇。中国知网允许每次最多导出500条,分4次导出,分别导入分析工具。为了对文献进行时间序列的分析,将文献按发布时间先后,每5年划分为一个时期,其中2011年和2012年为第7个时期。
数据预处理分为两步:第一步为去“脏”,第二步为原始数据再组织。该过程通过SciMat完成。
4.2 数据分析
.
.
.
.
.
(1)统计分析.
统计分析是文献分析的基础,SciMat提供基本的统计分析功能,图1为本文所用分析数据的关键词统计结果视图。
 | 图1 关键词统计表(通过SciMat生成) |
(2)主题分析.
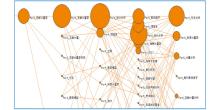
对于一个研究领域,要知道它主要研究什么,不同研究主题间的关系怎样以及与哪些学科相关等。通过相关文献主题词和提取关键词的共词分析得到“三计学”的知识图谱,如图2所示:
 | 图2 “三计学”知识图谱(通过NWB生成) |
图2中节点的大小表示主题的热度,节点间连线的粗细表示两个研究主题的关系的紧密程度。可知,文献计量学相关研究最多,以引文分析和统计分析为主,主要通过文献分析确定研究热点、预测研究前沿、描绘科学结构等。文献计量学与情报学关系最紧密,科学计量学、网络计量学次之。
主题演化过程如图3所示:
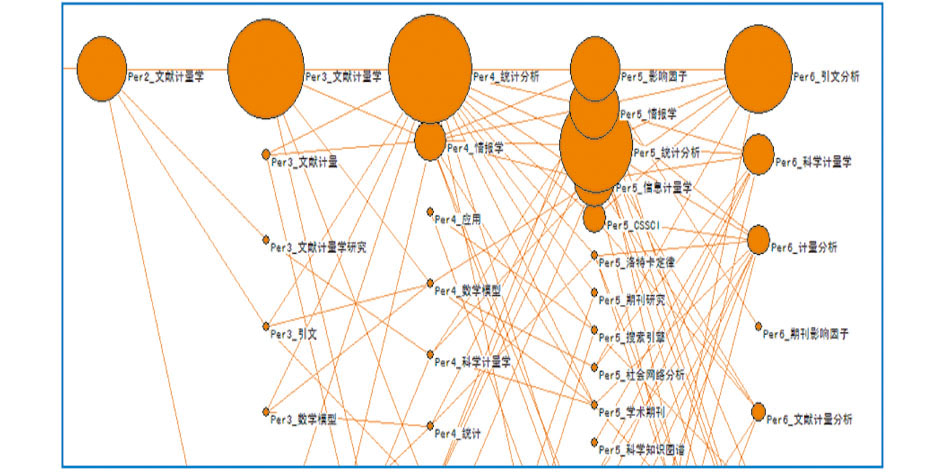 | 图3 主题演化图(从左到右依次为第2,3,4, |
5,6时期,通过SciMat生成).
图3中每个节点表示一个主题,节点的大小表示主题的热度,节点间的连线表示主题的演化。其中实线表示同一主题的转移,虚线表示不同主题的演化。可知,不同时期的研究热点各不相同,第2,3时期研究主题比较少,研究范围相对较大,到了第4,5时期研究主题逐步细化,出现一些新的研究主题, 如社会网络分析等。到第6时期,引文分析被广泛地应用于文献分析工作中,再次成为研究的热点。
新兴研究方向的监测、研究前沿的确定对研究方向的规划也至关重要,有利于抓住和把握重要的战略时机,产生新突破。图4为“三计学”领域新兴研究主题的检测结果,分析过程利用Sci2中集成的 KIeinberg 的突变检测(Burst Detection)算法[ 10]。
 | 图4 新兴主题监测(通过Sci2生成) |
其中横坐标表示年份,不同颜色的水平柱状条表示不同的主题,柱状条的纵向高度表示主题的研究热度,通过相关研究数量来衡量。柱状条的水平宽度表示主题的研究跨度。
(3)合著分析.
研究过程起核心作用的是人,对人的分析也是文献分析的重要内容。相关作者合著关系如图5所示:
 | 图5 合著关系网络图 |
图5左侧部分为VOSViewer的密度视图,图中节点的颜色根据作者合著关系的强弱依次由红色到蓝色,通过不同颜色表现在研究领域内相对活跃的一些研究团体,可以快速了解合著关系概貌。图5右侧部分通过GUESS生成,每个节点表示一位学者,节点大小表示发文量的多少,更能体现研究人员间的合著关系网络。通过分析,从宏观和微观两个层面把握相关领域的合著关系。
与作者合著关系分析类似,可以对机构信息、地理信息进行提取,进一步探索机构间、区域间的合作关系。另外还可以提取文献的学科信息,研究作者的跨学科程度,从而为跨领域专家的发现提供新思路。
5 结 语
文献分析是一个大课题,就中文文献分析而言,分析深度有待加深,分析手段有待加强。国外文献分析理论和方法值得学习,一些好的分析工具值得借鉴。在保证基本文献服务工作的同时,要研发相应的文献分析工具满足用户个性化需求,提高文献的揭示深度。本文在将国外开源文献分析工具应用于中文文献分析方面进行了一些尝试,通过对开源分析工具的扩展和组合应用,基本能够满足研究人员的分析需求。
未来工作需要进一步充实文献分析的理论基础,完善文献分析的方法体系,在学习国外文献分析工具分析框架的基础上,结合本土资源特点和国内研究需要,探索适合中国文献分析的工具体系。同时进一步提升文献分析的深度,利用好数据挖掘、文本处理和自然语言处理相关技术,从宏观、中观和微观多个层面,从主题词、引文和下载量等多个角度,挖掘文献不同分析对象间的潜在关系和规律,提升文献服务的水平,满足用户个性化分析需求。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|