
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
RDB2RDF标准及应用研究*
引用本文
夏翠娟. RDB2RDF标准及应用研究* . 现代图书情报技术, 2013, 29(4): 10-17
Xia Cuijuan. Research on RDB2RDF Standards and Applications. New Technology of Library and Information Service, 2013, 29(4): 10-17
Permissions
Xia Cuijuan. Research on RDB2RDF Standards and Applications. New Technology of Library and Information Service, 2013, 29(4): 10-17
RDB2RDF标准及应用研究*
摘要
在对RDB2RDF映射语言的功能需求和Direct Mapping、R2RML这两种映射语言进行文献调研和试验研究的基础上, 分析RDB2RDF的功能需求, 研究Direct Mapping和R2RML的逻辑框架、语法规则、使用方法和实施方案, 展望其应用前景, 得出这两种映射语言互为补充、将提高数据转换的质量和促进关联数据应用的结论。
关键词:
RDB2RDF; Direct Mapping; R2RML; 关联数据
Research on RDB2RDF Standards and Applications
Abstract
In this paper, the requirements of RDB2RDF mapping language, the logical framework, the syntax specification, the implementation solutions and the application outlook of W3C’s two RDB2RDF mapping languages, Direct Mapping and R2RML, are analyzed based on literal reviews and experimental investigations. With the standardized syntax, logical framework and the reasonable workflow, the two mapping languages are expected to enhance the data quality of RDB2RDF and promote the application of Linked Data.
Keyword:
RDB2RDF; Direct mapping; R2RML; Linked data
1 引 言
自1970年诞生以来, 关系型数据库 (Relational DataBase, RDB) 技术得到了非常广泛的应用, 目前已有海量的结构化数据存储在各类关系数据库系统中。随着万维网尤其是语义网的发展, 数据之间的互操作变得尤为重要, 整个Web逐步发展成一个巨大的、整体的数据空间[ 1], 关系数据库相对于语义网的一些固有缺点逐渐浮现出来, 如每个数据库的数据结构各不相同导致互操作困难、只有结构没有语义等。而资源描述框架 (Resource Description Framework, RDF) 是更适合于语义网的数据模型, 为了使存储在关系数据库中的数据更好地融入语义网, 需要将关系数据库中的数据转换成RDF数据, 这一转换过程被称为RDB2RDF, 指的是关系数据库的数据结构和数据转换成RDF的“三元组 (Triple) ”模型和RDF数据。RDB2RDF的方法和技术在过去的数年间一直被广为关注, 尤其是关联数据作为语义网的一种轻量级的实现方式大量应用后。根据关联数据的四原则, 数据要采用RDF数据模型[ 2], 要实现关系数据库发布为关联数据, RDB2RDF是至关重要的一步。一方面, 关系数据库发布为关联数据, 不仅能为关系数据库中的数据赋予语义, 也是将传统的、封闭的数据引入广袤的Web数据海洋的一种方式和途径;另一方面, 随着“大数据 (Big Data) ”的兴起, NoSQL (Not Only SQL) 作为大数据的关键技术, 必然会迅速发展, 得到更广泛的关注和应用, 目前许多NoSQL产品支持RDF数据的存储[ 3], RDB2RDF为基于关系数据库的传
统应用向基于NoSQL的大数据应用转变提供了一种可能的途径[ 4]。根据W3C的RDB2RDF孵化小组的调查报告《A Survey of Current Approaches for Mapping of Relational Databases to RDF》[ 5], 有15种工具平台支持RDB2RDF, 它们大多是开源的, 但由于缺少标准规范, 还处于“各自为政、各行其是”的状态, 不仅带来了互操作的问题, 也无益于RDB2RDF工具和平台的产品化, 难以得到推广和广泛应用, 因而制定一套RDB2RDF标准规范成为共识。W3C专门成立的RDB2RDF工作组制订的两种RDB2RDF映射语言规范已成为其推荐标准, 理解这两种规范的功能需求、逻辑框架、语法细节、应用前景是利用相关工具平台实施RDB2RDF的前提。
2 研究与应用现状
早在1998年, Berners-Lee[ 6]就深入探讨过关系数据库的数据模型和RDF数据模型之间的联系和区别, 他认为二者之间存在着天然的互为映射的联系, 关系数据库中的表 (Table) 相当于RDF数据模型中的类 (Class) , 字段 (Fields) 可看成是RDF数据模型中的属性 (Property) , 字段值相当于属性值 (Property Value) , 每条记录所指代的实例相当于RDF数据模型中的主体 (Subject) , 记录所包含的字段作为这个主体的谓词 (Predicate) , 字段的值相当于谓词的客体 (Object) , 二者都能对实体之间的关系进行建模, 不同的是RDF中的所有实体及实体间的关系都用URI来标识, 可以在Web范围内对不同数据源中的实体建立关联关系, 因而RDF是更适合语义网的数据模型。2003年, W3C发布了一篇调查报告《Mapping Semantic Web Data with RDBMSes》[ 7], 分析了RDB2RDF的映射方案需要解决的主要问题, 总结了已有的解决方案和相关工具, 并认识到RDB2RDF的关键是定义一种映射语言, 这种映射语言可以解决三个问题, 即定义关系数据库数据模型和RDF数据模型之间的映射关系、定义本地词汇表以及与外部领域本体的映射方法、为映射语言定义标准的可被机器读取和处理的编码格式, 从而达到表达关系数据库数据模型与RDF数据模型之间映射关系的目的, 支持机器自动将关系数据库数据转换成RDF数据。
从2007年W3C以“关系数据库的RDF存取”为主题的研讨会[ 8]可以看出, 对RDB2RDF的研究已经深入到应用层面, 出现了不少工具和案例, 其中Christian Bizer介绍了D2Rq映射语言, D2Rq是为D2R Server定义的映射语言, D2R Server目前已成为关系数据库发布为关联数据时应用最为广泛的平台之一, 它允许利用D2Rq映射语言自定义一个N3格式的映射文件, N3是既利于人读又可被机读的RDF序列化格式。在D2Rq映射文件中, 可以灵活地选择哪些表、哪些字段转换为RDF数据, 而哪些不转换, 还可以将表和字段映射到现有领域本体中的类和属性。W3C的推荐标准推出之前, D2Rq映射语言已经发展得较为成熟, 并得到了广泛的应用[ 9]。还有的RDB2RDF映射语言可用XSLT或XML表示, 能方便地被Web程序读取和处理, 如R2O和Virtuoso的元方案语言 (Meta-schema Language)[ 10], 如果映射方案是基于标准的、得到共识的领域本体, 又能以可被机器理解的表示格式编码, 就为在Web上得到共享和重用打下基础。
2008至2009年RDB2RDF孵化小组调查研究了当时各种项目和工具平台, 发布了调查报告《A Survey of Current Approaches for Mapping of Relational Databases to RDF》[ 5], 梳理了各种RDB2RDF的映射方法和实施方案, 发现各种自定义的映射语言互不相通, 得出了急需制订行业标准来支持各种工具和平台开发的结论, 并建议W3C成立专门的工作组, 研制RDB2RDF映射语言标准。W3C成立RDF2RDF工作组于2012年发布Direct Mapping和R2RML两个映射语言作为推荐标准, 吸取了D2Rq的许多成果, 最新版的D2R Server开始支持Direct Mapping。除上述两种映射语言外, W3C RDB2RDF工作组的成果还有用例和需求分析报告、测试用例报告和实施报告。需求分析报告通过几个典型用例, 详细分析了RDB2RDF映射语言标准规范的各项需求[ 11], 为制订Direct Mapping和R2RML两个映射语言提供依据;测试用例和实施报告中收集了对各种实现工具/平台的测试结果, 并在继续征集测试结果及意见和建议[ 12]。
3 RDB2RDF映射语言的功能需求
.
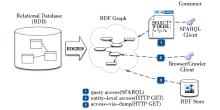
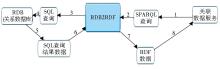
关系数据库转换成RDF一般需要定义RDB2RDF映射, 来指定一个具体的关系数据库中的表、字段、字段值映射为RDF数据模型中的类、属性、属性值的详细规则, 关系数据库转换为RDF图 (RDF Graph) 后, 可以三种方式提供服务:可供检索的SPARQL客户端、可供浏览的浏览器、可供下载的RDF数据包。关系数据库结构及其数据通过RDB2RDF映射转换成RDF图并在Web上提供服务, 流程如图1所示, 要完成这个过程, RDB2RDF映射需要满足一定的要求。
 | 图1 RDB2RDF映射流程[ 5] |
(1) RDB2RDF映射的方式一般有两种, 即直接映射和间接映射。直接映射是将关系数据库数据结构直接映射为RDF词表, RDF词表中的术语名称与关系数据库中的表名和字段名保持一致, 是一种本地本体 (Local Ontology) ;间接映射是先将关系数据库数据结构映射到现有的一种领域本体, 将关系数据库中的字段名映射为RDF的属性名称时, 该属性名来自于已有的一种领域本体, 而不是直接以字段名作为属性名。RDB2RDF映射语言需要支持这两种映射方式。
(2) URI是关联数据的构成要素。关系数据库数据转换成RDF数据后, 会产生RDF实体, 在RDB2RDF映射语言中, 需要定义RDF实体的URI, 因而RDB2RDF映射语言必须提供一种生成URI的机制, 该URI应符合关联数据四原则中的定义, RDB2RDF映射语言还应该尽可能地鼓励重用公开的URI, 如人、机构或地理位置的URI。
(3) 在许多RDB2RDF的应用中, 并不需要将关系数据库中的数据转换成RDF数据并存储在RDF Store中, 只需要提供一个虚拟的RDF数据视图和SPARQL查询接口及RDF数据的查询结果, 如图1中的第一种。这需要RDB2RDF映射语言还应提供足够的信息以支持SPARQL查询语言到SQL查询语言的转换, 并将SQL查询结果转换成RDF数据返回给前台。
(4) 在有的应用中, 用户需要得到一个可供下载的RDF数据包 (RDF Dump) , 因此RDB2RDF映射语言必须提供足够的信息以支持关系数据库结构和数据转换成一个RDF数据包, 如图1中的第三种, 也叫“抽取-转换-装载” (Extract-Transform-Load, ETL) 。
(5) 对数据类型 (DataType) 映射的定义, 即关系数据库中的数据类型与RDF数据类型之间的相互映射, 需遵循ISO IWD9075-14:2011 (E) 规范中的第 9.5条, 同时还应考虑到具体数据库厂商所定义的特定数据类型。
(6) 在将关系数据库中的字段值映射到RDF数据模型中的属性值时, 很多情况下, 不仅仅是值本身, 还需要对字段值进行处理和计算, 映射语言应支持这种映射前的处理和计算。
(7) 关系数据库的表之间可能存在一对一、一对多、多对多的关系, 映射语言应有一些机制将这种关联关系转换为RDF实体与实体之间的关系。
除此之外, 对申明命名空间及其前缀的支持、对知识产权申明的支持以及提供关于数据的元数据 (如Void) , 对于关系数据库发布为关联数据也至关重要, 是RDB2RDF映射语言应该支持的功能。
4 W3C的两种RDB2RDF映射语言
W3C推荐了两种映射语言Direct Mapping和R2RML。Direct Mapping是直接映射的方式, 它将关系数据库表结构和数据直接输出为RDF图, 完全是关系数据库数据结构的反映, RDF图中所用到的用于表示类和谓词的术语与关系数据库中的表名和字段名保持一致, 并不可更改;R2RML则有高度的可定制性, 一个R2RML映射可为一个具体的数据库结构和一个特定的词表量身定制, 通过R2RML映射, 一个关系数据库可输出为一个RDF数据集, 该RDF数据集中所用到的术语如类的名称、谓词可来自已有的词汇表, 如FOAF、DC等。Direct Mapping和R2RML配合使用, 前者为后者提供默认映射方案, 作为后者进一步按需定制的基础。
4.1 Direct Mapping
Direct Mapping于2012年6月成为W3C的推荐标准[ 13], 定义了将关系数据库 (包括数据结构和数据本身) 输出为一个RDF图的映射规则, 包括URI的生成、关系数据库中外键所形成的关联关系与RDF模型之间的映射、用于实现映射规则的详细算法等。Direct Mapping的最大特点在于转换而来的RDF数据中的类名、属性名与关系数据库中的表名和字段名保持一致, 因而其输出的RDF图被称为“Direct Graph”。
如下SQL代码片段用于创建一个简单的关系数据库, 有Addresses和People两张表, Addresses表中有一条记录, People表中有两条记录。
CREATE TABLE "Addresses" (.
"ID" INT, PRIMARY KEY ("ID") , .
"city" CHAR (10) , .
"state" CHAR (2) .
) .
CREATE TABLE "People" (.
"ID" INT, PRIMARY KEY ("ID") , .
"fname" CHAR (10) , .
"addr" INT, .
FOREIGN KEY ("addr") REFERENCES "Addresses" ("ID") .
) .
INSERT INTO "Addresses" ("ID", "city", "state") VALUES (18, ′Cambridge′, ′MA′) .
INSERT INTO "People" ("ID", "fname", "addr") VALUES (7, ′Bob′, 18) .
INSERT INTO "People" ("ID", "fname", "addr") VALUES (8, ′Sue′, NULL) .
以上数据库结构及其数据通过Direct Mapping的规则和语法生成的RDF数据是一个Direct Graph, 如下:.
@base <http://foo.example/DB/>.
@prefix xsd: <http://www.w3.org/2001/XMLSchema#>.
<People/ID=7> rdf:type <People>.
<People/ID=7><People#ID> 7.
<People/ID=7><People#fname> "Bob".
<People/ID=7><People#addr> 18.
<People/ID=7><People#ref-addr><Addresses/ID=18>.
<People/ID=8> rdf:type <People>.
<People/ID=8><People#ID> 8.
<People/ID=8><People#fname> "Sue".
<Addresses/ID=18> rdf:type <Addresses>.
<Addresses/ID=18><Addresses#ID> 18.
<Addresses/ID=18><Addresses#city> "Cambridge".
<Addresses/ID=18><Addresses#state> "MA".
Direct Mapping的语法只能为RDF图中的实体生成一个相对的IRI, 置于“< >”中, 如果要生成一个可解析的URI, 则需要根据RFC3987标准[ 14]申明base IRI, 从而构建一个标准的RDF图。如三元组的主体 (Subject) <People/ID=7>是一个相对的IRI, 通过语句@base <http://foo.example/DB/>.给定一个base IRI: http://foo.example/DB/, 则实体<People/ID=7>的URI就能被正确解析。假如一个表采用了多字段主键, 如将Department表的主键设为"name"、"city"两个字段的组合, 而不是ID, 那么ID为23的Department实体的IRI不再是<Department/ID=23>而是<Department/name=accounting;city=Cambridge>., 上述三元组则变成:<People/ID=7><People#ref-deptName;deptCity><Department/name=accounting;city=Cambridge>.。对于无主键的表, 每一条记录所生成的三元组共享一个主体, 该主体作为一个空节点 (Blank Node) 。没有主键的表仍然可以使用外键, 当一个表使用外键关联到另一个无主键表时, 生成的三元组会将空节点作为客体。主键的缺失可导致大量的空节点存在, 但不改变“直接图”的结构和其中谓词的命名规则。
关系数据库利用外键来实现各种关联关系, 基于Direct Mapping而生成的Direct Graph这样表达这种关联关系:三元组<People/ID=7><People#ref-addr><Addresses/ID=18> 中的客体是表Addresses对应的一个实体, 根据People表中定义的外键FOREIGN KEY ("addr") REFERENCES "Addresses" ("ID") 在两个表之间建立的关联关系, 就可以找到两个表实体之间的关联关系。对于复合外键的情况, 如People表中增加"deptName"、"deptCity"两个字段, 再增加一个"Department"表, 有"ID"、"name"、"city"三个字段, 在People表中两表之间外键的定义为FOREIGN KEY ("deptName", "deptCity") REFERENCES "Department" ("name", "city") , 生成的三元组是<People/ID=7><People#ref-deptName;deptCity><Department/ID=23>.。
4.2 R2RML
.
.
.
R2RML是一种将关系数据库映射为RDF数据集的规范[ 15], 于2012年成为W3C的推荐标准。与Direct Mapping映射语言相比, 它不仅定义了R2RML词汇表、R2RML映射规则及其语法, 还定义了R2RML工作的机制和 RDB2RDF映射的逻辑框架, 在流程和方法层面也进行了标准化, 更重要的是, 它提供了将关系数据库中的数据结构映射到外部领域本体的途径和方法。
(1) R2RML的工作机制.
R2RML的工作机制有三个要素:“输入数据库” (Input Database) 、R2RML映射文件、R2RML处理器。 “输入数据库”需要转换成RDF的关系数据库;R2RML映射文件是R2RML映射规则的物理表现, R2RML映射本身是以Turtle语法编写的RDF图, 称为R2RML映射图 (Mapping Graph) , 用R2RML词表中定义的词汇按照一定的规范写到映射文件中, 该文件既可机读也便于人的读写, 内容编码格式一般为text/turtle;charset=utf-8, 文档扩展名为.ttl;基于R2RML映射语言实现RDB2RDF的工具被称R2RML处理器, 它可看作是一个系统, “输入数据库”是R2RML处理器工作的原材料, R2RML映射文件是R2RML处理器工作的依据, R2RML处理器依据R2RML映射文件将“输入数据库”输出为一个可访问可获取的“输出数据集” (Output Dataset) 。初始的R2RML映射文件一般由R2RML处理器基于Direct Mapping的方式自动生成, 再依照具体需求遵循R2RML的语法自定义。
(2) R2RML的逻辑框架.
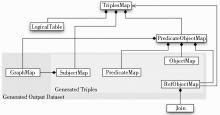
R2RML定义了RDB2RDF映射的逻辑框架, 如图2所示:
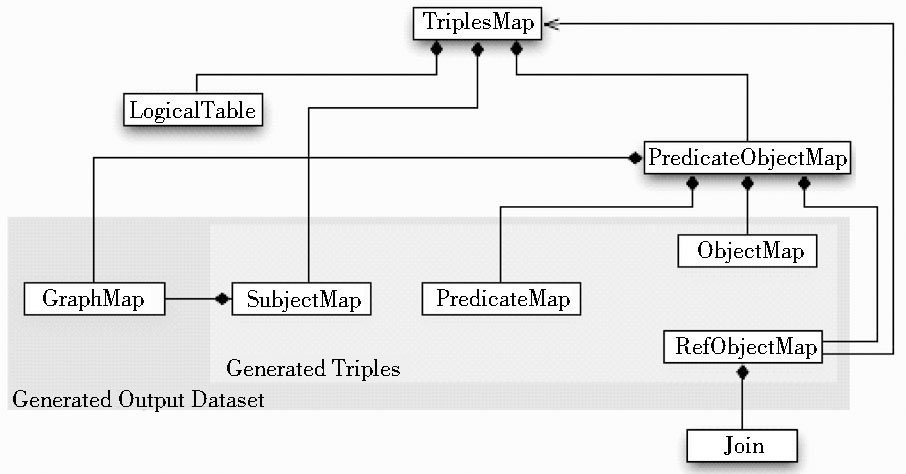 | 图2 R2RML的逻辑框架[ 15] |
它将关系数据库中的“一个表”、“一个视图”或“一个有效的SQL查询”定义为“一个逻辑表 (LogicalTable) ”, “逻辑表”再通过“三元组映射 (TriplesMap) ”所定义的规则映射为RDF三元组, 三元组中的“主体 (Subject) ”由一个“主体映射 (SubjectMap) ”所定义的规则生成, “主体”通常是基于表的主键和自定义的模板 (Template) 生成的IRI。“谓词-客体映射 (PredicateObjectMap) ”由“谓词映射 (PredicateMap) ”和“客体映射 (ObjectMap) ”或“引用客体映射 (RefObjectMap) ”组成, “引用客体映射”由“连接 (Join) ”定义映射的条件。默认情况下, 所有的RDF三元组都在“输出数据集”的“默认图 (Default Graph) ”中, 但一个“三元组映射”也可以包含“图映射 (GraphMap) ”, 将部分或全部的三元组映射为“命名图 (Named Graph) ”[ 16]。
下例说明了从employee表中生成的三元组:.
①主体:IRI模板为http://data.example.com/employee/{empno}, empno是表empno的主键, 取决于“主体映射”中定义的规则;
②谓词:ex:name 前缀ex表示本地词汇表, name是本地词汇表中的一个属性, 也可以从外部词表中选取合适的属性如foaf:name, 取决于在“谓词映射”中定义的规则;
③客体:为字段name的值, 是一个“RDF文本”[ 17], 取决于“客体映射”中定义的规则, 如果是一个引用客体, 就不是取某个字段的值, 而是与此主体相关联的另一个主体, 取决于“引用客体映射”中定义的规则。
(3) R2RML词汇表及映射文件.
R2RML定义了映射语言层面的词汇表, 作为R2RML规范的一部分, 包括一系列依据图2所示的逻辑框架定义的RDB2RDF映射关系的类和子类, 如rr:TriplesMap是“三元组映射”的类, rr:LogicalTable是“逻辑表”的类, 它有两个子类rr:R2RMLView和rr:BaseTableOrView, rr:R2RMLView类表示一个合法的SQL查询, rr:BaseTableOrView表示关系数据库中的表或视图。每个类都有自己的属性, 如rr:R2RMLView, 它用属性rr:sqlQuery来定义SQL查询的具体内容, 以表DEPT为例:.
CREATE TABLE "DEPT" (.
" DEPTNO" INT, PRIMARY KEY ("ID") , .
" DNAME" CHAR (30) , .
) .
INSERT INTO DEPT Values (10, ′APPSERVER′) .
对逻辑表的定义代码如下所示:.
[] rr:sqlQuery """
Select (′Department′||DEPTNO) AS DEPTID.
, DEPTNO.
, DNAME.
from SCOTT.DEPT.
""";
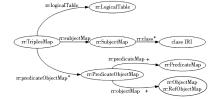
R2RML映射文件要解决的主要问题是利用R2RML词汇表中定义的类和属性将“逻辑表”映射为RDF, 图3展示了利用“三元组映射”将“逻辑表”映射为RDF的实现框架, 清单是实现上文例子的R2RML映射文件中的片段, 它定义了一个名为<#DEPTTripleMap>的“三元组映射”, 将名为“DEPT”的“逻辑表 (rr:LogicalTable) ”映射为RDF三元组, 这些三元组共享一个主体, 主体由“主体映射 (rr:SubjectMap) ”来定义, “主体映射”的rr:template属性定义主体的URI生成规则, 见清单中的rr:template http://data.example.com/department/{DEPTNO}, 大括号中的字符串是表department的主键字段名, 属性rr:class 定义主体所属的类, 在生成的RDF三元组中作为rdf:type的值。 “谓词客体映射 (rr:PredicateObjectMap) ”定义一对谓词和客体, 属性rr:predicateMap定义谓词所用到的术语, 属性rr:objectMap定义客体的取值, 取值可以是一个常量, 也可以是逻辑表中的一个指定字段的值, 用属性rr:column指定具体的字段名, 当客体是另一个主体时, 需要用“引用客体映射 (rr:RefObjectMap) ”来定义。
 | 图3 R2RML 逻辑表映射[ 15] |
以下为将表Dept转换为RDF而自定义的映射文件, 通过逻辑表映射, 可映射到外部的本体词汇, 如“rr:predicate foaf:name;”将字段DNAME映射到谓词foaf:name, 这是与Direct Mapping 在功能效果上的最大区别。
<#DEPTTripleMap>
rr:logicalTable [ rr:tableName "DEPT" ];
rr:subjectMap [.
rr:template http://data.example.com/department/{DEPTNO};
rr:class ex:Department.
];
rr:predicateObjectMap [.
rr:predicate foaf:name;
rr:objectMap [ rr:column "DNAME" ];
];
得到的RDF三元组如下:.
http://data.example.com/department/10 foaf:name APPSERVER.
(4) R2RML表间关系映射.
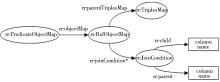
R2RML对外键等表间关系的处理利用了“引用客体映射 (rr:RefObjectMap) ”, 它将一个三元组的客体映射到另一个三元组的主体, 如图4所示, 这两个三元组很可能来自不同的“逻辑表”, 所以需要在不同的表中建立“连接 (Join) ”。 “引用客体映射”用属性rr:parentTriplesMap来指定要取哪个“三元组映射”的主体来作为它的客体, 一般用三元组映射的名称来表示, 如清单中的<#TriplesMap2>即是这个“三元组”的名称。而逻辑表之间的连接条件, 则用rr:JoinCondition来指定, rr:JoinCondition的两个属性rr:child和rr:parent指定一个表到另一个表的外键关联条件, 如果把“逻辑表”定义成一个有效的SQL查询, 能实现更复杂的需求。
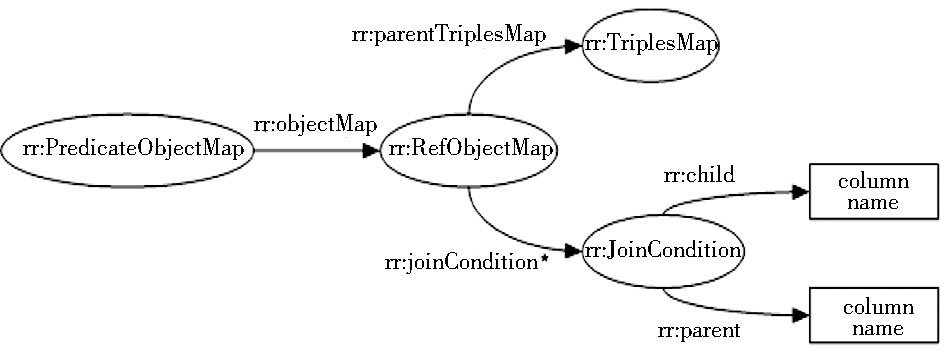 | 图4 R2RML对关系数据库外键的处理[ 15] |
(5) R2RML对空节点的处理.
R2RML对空节点的处理与Direct Mapping不同, 如果一个逻辑表没有定义主键, 在“直接图”中, 会为每一行生成一个空节点, 这样相同的重复行会生成多个不同的空节点, 而在R2RML的“默认图”中, 则可以为重复的行指定同一个空节点。在R2RML的“输出数据集”中, 如果同一个空节点标识符出现在同一个RDF图中的多个三元组中, 那么这些三元组将共用同一个空节点;如果同一空节点标识符出现在多个RDF图中, 它将被当作不同的空节点, 由R2RML创建的空节点将不能被不同的RDF图共用。这意味着某一个“逻辑表”行所生成的主体在不同的RDF图中会变成多个空节点。
4.3 两种RDB2RDF映射语言的实施和应用
.
根据W3C RDB2RDF工作组的《实施报告》[ 18], 目前已有许多开源或商用的工具和平台可以实施W3C的Direct Mapping和R2RML标准规范。有的工具和平台只支持两种映射语言中的一种, 如D2RQ只支持Direct Mapping, OpenLink Virtuoso只支持R2RML;而有的则两种都支持, 如RDF-RDB2RDF、XSPARQL、Ultrawrap、db2triples。这些工具平台一般有两种实现方式, 即ETL方式和动态转换方式, 前者会根据定义好的映射从具体的关系数据库中生成一个静态的RDF包, 可以导入RDF Store中, 如图5所示, 缺点是需要采取额外的措施 (如后台数据同步程序) 来保证数据的实时性;后者会根据前台的请求和定义好的映射自动适时地将关系数据库数据转换为RDF数据再返回给前台, 数据是实时的。在数据的查询时, 前者可直接用SPARQL查询, 后者则大多采用将前台SPARQL语言转换成SQL查询语言再将查询结果转换为RDF数据, 这是动态转换方式, 如图6所示, D2R Server就是一个典型的例子, 缺点是当数据量很大时, 不能保证查询性能和效率。
 | 图5 基于NoSQL型RDF Store的RDB2RDF实施方案 |
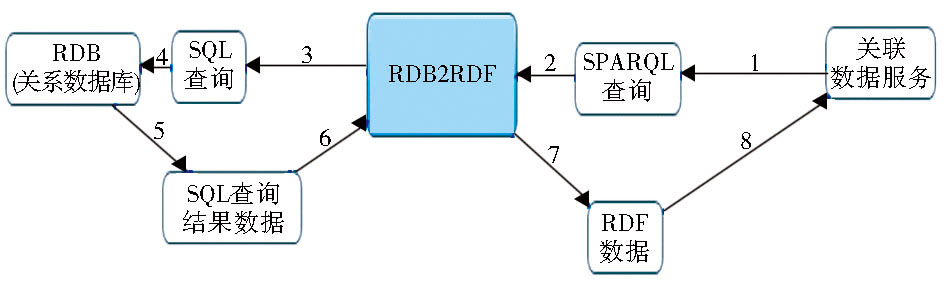 | 图6 基于SQL的RDB2RDF实施方案 |
在国外, 基于NoSQL型RDF Store的关联数据解决方案得到越来越多的研究, 随着大数据的兴起, NoSQL作为大数据的关键技术得到越来越多的关注, 也吸引了关联数据领域的研究和应用。2011年, 欧洲的语义网研究机构DERI开始了一项题为“NoSQL Solutions for Linked Data Processing”[ 3]的调查研究, 发现许多NoSQL数据库有支持RDF的功能, 如Google的BigQuery, 支持导入N-Triples格式的RDF数据, Apache CouchDB支持JSON格式的RDF数据, N-Triples和JSON都是标准化的机器可读的RDF数据格式, Neo4j 是一个基于Java的“图形 (Graph) ”数据库, 图形数据库是NoSQL的一种, RDF数据处理是其内置的功能。2011年发表的《Practical Semantic Web and Linked Data Applications》[ 19]一书中, 系统性地探讨了图形数据库AllegroGraph实现关联数据的方法, 具有图形化结构的RDF数据更适合于存储在图形数据库中。
基于SQL的RDB2RDF实施方案较为适合将RDB的遗留系统数据转换为RDF数据, 基于NoSQL的RDB2RDF实施方案省去了SPARQL与SQL之间的双向转换的复杂过程, 将大大提高SPARQL查询的效率, 具有更为广阔的应用前景。
5 结 语
Direct Mapping的显著特点是将关系数据库的表名、字段名直接映射为与之同名的类名和属性名, 规则简单直接利于机器自动实现, 而R2RML则可将关系数据库的表名、字段名映射为已有领域本体中的类名和属性名, 提供更多的人工干预的机会, 为跨系统、跨领域的互操作提供途径和方法。这两种RDB2RDF映射语言并非相互替代而是互为补充, 前者提供机器自动转换的初始规则, 后者提供人工自定义的逻辑框架和语法规则, 一般的RDB2RDF工具平台会基于前者自动生成默认的RDF图, 后者则支持在默认的RDF图的基础上进行个性化定义和配置。
过去各种不同的RDB2RDF工具和平台都使用自定义的映射语言, 没有一致的标准规范, 因此带来了互操作问题, Direct Mapping和R2RML这两种映射语言系统而明确地定义了RDB数据模型和RDF数据模型之间的映射关系, 不仅从抽象的层面搭建二者之间转换的桥梁, 构建了RDB2RDF的整体逻辑框架, 还对各种具体应用场景进行了细致的定义和规范, 定义了明确的语义和语法, 将大大提高各种工具平台的互操作性。随着Direct Mapping和R2RML这两种映射语言成为W3C的推荐标准, 越来越多的RDB2RDF工具和平台将支持Direct Mapping和R2RML, 基于标准化的流程和工作机制, 将减少使用不同工具平台的应用者的学习成本, 有利于工具平台的产品化和应用普及。
自关联数据诞生之初开始, 数据的质量控制问题一直是影响关联数据得到更广泛应用的一个瓶颈, Direct Mapping和R2RML为RDB2RDF映射提供了一致的语义逻辑和语法规则, 转换而来的RDF数据将具备更高的质量和可靠性。Direct Mapping和R2RML为RDB2RDF提供了一致的语法以及标准化规范化的流程和机制, 输出的RDF数据具有一致的语义逻辑和标准化的数据格式, 有助于图书馆将RDB中的数据以标准化的RDF格式移植到NoSQL环境, 有望促进基于NoSQL的RDB2RDF实施方案的应用, 为传统应用系统中的数据移植到大数据环境提供了一种可能的途径, 是关联数据应用和发展的新方向。W3C的这两种RDB2RDF推荐标准刚刚推出, 距得到广泛的实际应用尚需时日, 笔者将继续跟踪研究其实施和应用情况, 通过在图书馆的关联数据研发项目中试验和实施, 进一步研究其应用场景和适用范围。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|