

{kind=link}
{kind=link}
{kind=link}
{kind=link}
OPAC混搭关联数据应用研究*
引用本文
钟远薪, 李田章, 刘炜. OPAC混搭关联数据应用研究* . 现代图书情报技术, 2013, 29(4): 25-29
Zhong Yuanxin, Li Tianzhang, Liu Wei. A Research on Linked Data Mashup in OPAC. New Technology of Library and Information Service, 2013, 29(4): 25-29
Permissions
Zhong Yuanxin, Li Tianzhang, Liu Wei. A Research on Linked Data Mashup in OPAC. New Technology of Library and Information Service, 2013, 29(4): 25-29
OPAC混搭关联数据应用研究*
摘要
采用案例研究方法,介绍OPAC混搭关联数据的数据源选择、系统架构和实现技术。OPAC混搭关联数据是图书馆应用关联数据简便、有效的方式,可以向用户展示更丰富的信息,使OPAC更具可用性和拓展性,并为用户提供信息之间的关联,提高图书馆资源被发现的几率。
关键词:
关联数据; 混搭; OPAC
A Research on Linked Data Mashup in OPAC
Abstract
This paper introduces linked data sources selection, system architecture and implementation technology of linked data Mashup in OPAC based on case studies. It indicates that linked data Mashup in OPAC is a simple and effective way to consume linked data by libraries, which can integrate more related information and provide a better presentation in OPAC, then improve the probability of library resources discovery.
Keyword:
Linked data; Mashup; OPAC
1 引 言
通过关联数据把Web上相互独立的海量数据关联起来已经成为推动语义Web发展的重要力量之一,并得到科研机构、政府、图书馆等各方面的广泛关注。关联数据提供了一种新的数据分享方式,使得基于标准网络协议的、海量的Web数据富含语义,并提供面向人的界面和面向机器的数据消费接口[ 1]。截至2011年9月19日,LOD云图中已有包括DBpedia、DBLPB、Sensorpedia、FOAF(Friend of a Friend)、DOAP(Description of a Project)、OpenPSI等知名数据集在内的295个开放数据集合,提供了近316亿个RDF三元组,内容涉及地理、生命科学、医药、出版、媒体、社会网络等领域[ 2]。图书馆充分利用海量的关联数据,可以极大地提升相关信息服务的水平。但对于国内大部分图书馆而言,如何根据自身业务需求使用关联数据,仍缺乏技术实践的案例指导。因此,采用案例研究的方法,构建一个简便、有效的关联数据应用实验,可以为更多图书馆提供实践参考,从而促进关联数据研究与应用的进一步深入。
2 相关研究
自关联数据概念提出并在图书馆应用以来,我国图书情报界的学者对此积极展开研究。2010 年8 月,“图书馆前沿技术论坛:关联数据与书目数据的未来”专题会议在上海举行;2012年7月,上海图书馆学会举办了“从文献编目到知识编码:基于语义的信息组织基础”的专题研讨班。相关的研究成果陆续出现,研究范围涵盖关联数据的基本特征与应用展望、发布与消费技术、基于关联数据的资源整合与知识服务等。在实践方面,上海图书馆、中国科学技术信息研究所等机构搭建了用于实验的关联数据发布与消费系统。
混搭(Mashup)是一种通过脚本程序,将第三方Web站点或数据接口提供的数据整合到用户当前Web页面的技术。它可以将网络上多个资料来源或功能进行糅合,从而形成一个新的整体应用。在图书馆中,混搭主要应用在以下几个方面:.
(1)将馆藏信息制做成规范的接口或浏览器工具条,使用户在浏览一些书籍网站时,同步显示书籍在图书馆的馆藏信息,例如暨南大学图书馆豆瓣插件1.0[ 3];
(2)读者在OPAC系统查询图书时,显示图书封面、图书随书光盘和电子图书信息等[ 4, 5];
(3)将地图和图书馆的位置信息进行混搭,例如The LibMap UK[ 6]把地图和图书馆的位置信息进行了糅合,快速为用户呈现出馆藏分布。
OPAC是揭示馆藏信息的专用检索平台,是读者查找图书最常用的工具。在OPAC系统通过混搭来提供相关资源链接,丰富OPAC的展示内容,已经成为图书馆整合资源的有效方式之一。随着关联数据技术的兴起,海量的、高质量的数据集不断出现,为OPAC混搭提供了丰富的、更为可靠的数据来源,值得图书馆进行相关应用研究和推广。
据调研,国外已有不少关于混搭关联数据的研究成果出现,介绍了如何应用混搭技术在网站上集成关联数据,《通用计算机科学杂志》(Journal of Universal Computer Science, JUCS)网站利用DBpedia和DBLP的关联数据供作者发现功能,向用户展示了作者学术关系、个人基本情况、专业和贡献等信息,起到很好的资源揭示作用[ 7]。有文献提出OPAC系统中集成关联数据的设想,但并未给出具体的技术实现方式。在国内,尚未见OPAC混搭关联数据的相关研究成果和实践报告。
3 OPAC混搭关联数据的案例实现
3.1 关联数据源选取网络上有海量的关联数据,不同数据源的数据质量、开放程度及稳定性都不相同,每个图书馆的需求也不尽相同,因此必须认真地考虑数据源的选取问题。为了能够更好地阐述OPAC混搭关联数据的技术以及结合图书馆OPAC的功能需求,本文选取DBpedia、上海图书馆书目数据FRBR(Functional Requirements for Bibliographic Records)化、RDF化试验系统和本地发布的关联数据作为案例研究的数据来源。
(1)DBpedia.
MARC记录中,极少提供作者简介、照片等相关信息。如果能通过关联数据将这部分信息混搭到OPAC中,就可以让读者对作者更为了解,以便于选择图书。DBpedia是从维基百科上抽取结构化内容并以关联数据规范发布的,允许用户查询、利用关联数据集,具有相当丰富、准确的信息。截至2012年8月6日,DBpedia3.8已发布了377万件事物(Thing)的数据,其中包括764 000个人(Person),573 000个地点(Places)及192 000个组织(Organization)等信息,并提供111种语言的本地化版本[ 8]。本文选取DBpedia作为国外知名、规范的关联数据集代表,进行混搭作者信息的案例研究。
(2)上海图书馆书目数据FRBR化、RDF化试验系统.
截至2012年7月20日,上海图书馆“书目数据FRBR化、RDF化试验系统”的关联数据集共有300条书目数据,1万多条规范档数据,1万多项作者信息,并且利用FOAF词表中的术语对作者之间的关系进行揭示[ 9]。图书作者之间的关系所展现出来的作者人际关系网络,对于揭示作者的思想脉络、学术合作关系与学术影响力具有十分重要的价值,若用于图书馆的OPAC,则可起到资源导航作用。利用传统的数据挖掘技术,要实现这样的知识图谱是比较困难的。本文选取上海图书馆书目数据FRBR化、RDF化试验系统作为国内图书馆的关联数据集代表,进行作者关系网络展现的案例研究。
(3)本地发布的关联数据.
本地书目数据的挖掘,对于图书馆开展深层次信息服务具有重要作用,但当前图书馆OPAC中展现出来的书目数据缺乏关联性。比如,读者在查看馆藏某本图书的详细信息时,无法同时查看到该书作者的其他著作或其他同主题的图书,不便于读者筛选利用。如果将书目发布成关联数据,就可以轻松地得到书目之间的关系并展示出来,从而使得OPAC更为人性化和智能化。例如,当读者在查看鲁迅的《汉文学史纲要》时,经过数据关联的计算,将馆藏的其他鲁迅著作如《阿Q正传》同步推荐给读者,以供读者选择。本文选取本地发布的关联数据为例,进行书目关联的案例研究。
3.2 混搭系统的架构
.
在这个OPAC混搭关联数据的案例中,OPAC系统分别同时向DBpedia、上海图书馆和本地数据的SPARQL端点发送数据查询请求,然后获取返回的数据,并通过脚本程序实时显示在OPAC的页面中,系统架构如图1所示:
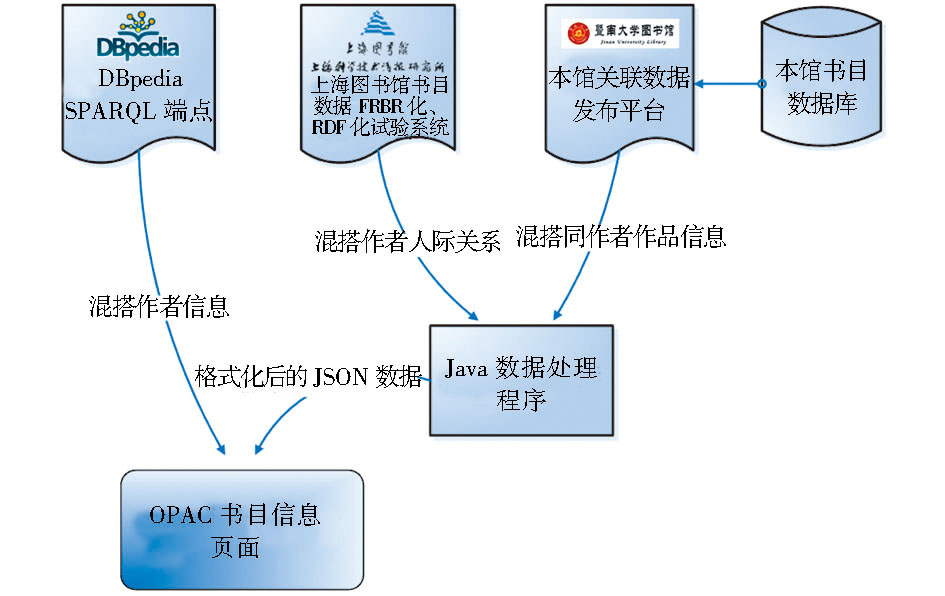 | 图1 OPAC混搭关联数据系统架构 |
3.3 混搭的实现及其关键技术
.
.
(1)混搭DBpedia.
DBpedia关联数据集提供多种方式、多种功能、适应不同需求的数据消费接口,包括批量下载、SPARQL端点、专用Web Service接口、插件(Plugin)及小工具(Widget)等。在本案例中通过SPARQL端点以JSON(JavaScript Object Notation)格式来获取作者的个人简介和照片。
通过DBpedia获取某个作者的相关数据,首先需要在DBpedia中明确数据值对应的属性,在DBpedia关联数据集中对某一人(Person)的实体的URI(Uniform Resource Identifier)命名规则是“http://dbpedia.org/resource/人名”,若是中国人,人名是以“_”分隔的姓名拼音,例如鲁迅的URI是“http://dbpedia.org/resource/Lu_Xun/”,打开该URI,可以得到关于鲁迅的所有三元组数据,其中属性rdfs:label能有效判断某个人物(Things),属性dbpedia-owl:abstract表示人物的简介,属性foaf:depiction表示这个人物的照片。根据这些信息,可以构造获取作者个人简介和照片的SPARQL语句:.
SELECT ?s WHERE{.
?altName rdfs:label′Lu Xun′@en;
Dbpedia-owl: abstract ?s.
FILTER langMatches(lang(?s),′zh′).
}.
SELECT ?b WHERE{.
?altName rdfs:label′Lu Xun′@en;
Foaf:depiction ?b.
}.
通过脚本以HTTP协议向DBpedia的SPARQL端点发送上述语句,请求返回JSON格式的数据即可。
(2)混搭上海图书馆书目数据FRBR化、RDF化试验系统.
上海图书馆的关联数据集支持SPARQL端点的数据消费接口,访问地址为“http://lod.library.sh.cn:8080/bib/snorql/”,该数据集中对某一人(Person)的实体的URI命名规则是:“http://lod.library.sh.cn:8080/bib/page/人物ID号”,如茅盾的URI是“http://lod.library.sh.cn:8080/bib/page/PersonA000005”,在这个页面下有许多关于茅盾的三元组数据。经过分析发现,属性foaf:name对应人物的姓名,属性rel:friendOf是与其有关的人物信息。根据这些信息,就可以遍历某个作者的人际关系网络,获得所有与其有关的人物的ID号,再根据ID号就可以获得相关人物的姓名,Java处理程序的关键代码如下:.
//获取所有与巴金有关的人物的ID号.
String queryStr = "SELECT DISTINCT ?s ?author ?friend "+.
"WHERE {?s dc:creator ′巴金′."+.
"?s rdarole:author ?author."+.
"?author rel:friendOf ?friend.}";
Query query = QueryFactory.create(queryStr);
QueryExecution qexec = QueryExecutionFactory.sparqlService("
http://lod.library.sh.cn:8080/bib/snorql",query);
ResultSet rs = qexec.exeSelect();
…….
//根据ID号获得人物的姓名.
String queryStr2 = "PREFIX foaf: <http://xmlns.com/foaf/0.1/>"+"SELECT DISTINCT ?name WHERE {{<http://lod.library.sh.cn:8080/bib/resource/"+rs.get("friend")+">"+"foaf:name ?name }}";
Query query2 = QueryFactory.create(queryStr2);
…….
然后将获取的数据格式化为JSON数据返回给OPAC页面的脚本程序。
(3)混搭本地书目关联数据.
要混搭本地书目关联数据,首先要通过关联数据发布工具将书目数据映射为关联数据。这些工具的通用工作模式是将对关联数据的请求,如SPARQL查询等,转换为关系型数据库的SQL语言,并将SQL查询结果转换为RDF三元组,返回给调用程序[ 10]。在本案例中,采用D2R Server平台将书目数据发布为关联数据,并采用Java编程语言的RDF数据的开发包Jena,向SPARQL端点发起SPARQL查询、处理查询结果,并读写序列化的RDF数据文件,从而操作本馆书目关联数据。具体设计流程如下:.
①书目数据生成关联数据。通过D2R平台直接连接馆藏书目关系型数据库,利用D2R自动生成书目数据的关联数据映射文件。映射文件主要是描述本馆书目数据字段与关联数据三元组格式的映射对应,具体流程如图2所示:
 | 图2 通过D2R平台将书目数据生成 |
关联数据映射文件.
②混搭本馆书目关联数据。采用Jena开发包,向本地SPARQL端点发起查询,同时通过D2R平台,根据映射文件自动生成SQL语句从本馆书目关联数据库中查找结果并以RDF格式返回给调用程序,调用程序以JSON格式输出,返回给OPAC页面的脚本。具体流程如图3所示:
 | 图3 通过D2R平台获取馆藏书目关联数据流程 |
实现OPAC混搭本馆书目关联数据的关键Java代码如下:.
ModelD@RQ m = new ModelD2RQ("file:"+CommonMethod.getRealPath().replace("\","/")+"webservice/test.ttl");
String sparql= "PREFIX vocab:<http://127.0.0.1/resource/vocab/>"+.
"SELECT ?id ?title ?callno ?author ?library ?isbn WHERE {?resoursevocab:item_id ?id."+.
"?resourcevocab:item_title ?title.? resourcevocab:item_callno ?callno."+.
"?resourcevocab:item_author ?author.? resourcevocab:item_isbn ?isbn."+.
"Filter(?author=’” + authorName + “;))";
Query q = QueryFactory.create(sparql);
ResultSet rs= QueryExecutionFactory.create(q,m).execSelect();
3.4 混搭的效果
.
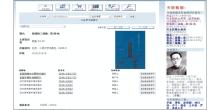
在OPAC页面通过脚本程序获得各个数据源返回的JSON数据之后,就可以更新当前用户浏览的页面,将关联数据呈现出来。在本案例中,通过混搭外部和内部的关联数据集,使得OPAC系统在向用户提供基本书目信息的同时,还向用户展示作者的简介、照片、与作者有关的人物以及本馆所藏的该作者的其他著作等信息,效果如图4所示:
 | 图4 OPAC混搭关联数据屏幕截图 |
4 讨 论
网络上有海量富含语义的关联数据可供免费消费,本文通过实验性案例介绍了一种图书馆应用关联数据的简便、有效的方式。在OPAC混搭关联数据,可以充分利用互联网上优质的信息资源,丰富了OPAC页面的内容,弥补了MARC数据揭示信息不够深入、关联不足的缺陷,为读者提供了与图书相关的更全面、更密切的数据,使OPAC更具可用性和拓展性,从而提高图书馆资源被发现的几率。这一做法具有较高的价值和实践意义,值得图书馆进一步研究、应用和推广。
由于关联数据的研究还不够深入,OPAC混搭关联数据还存在关联数据源选择、链接维护、用户交互等三个方面的挑战。
(1)数据源的选择。目前,许多关联数据在内容上仍不能完全适合OPAC,国内尚未有图书馆彻底将书目数据发布为关联数据集,DataHub中收录的中文关联数据集来源极少,准确性也有待提高。这在很大程度上限制了相关实践的开展,同时也对国内图书馆推进关联数据应用提出更实际的要求。
(2)链接维护。关联数据越来越受到各个领域的重视,关联数据的规模与来源日益壮大,而链接地址不是一成不变的。地址改变必将导致客户端发出大量无效的请求,但却无法获取到相应的数据。有效解决这一问题的办法首先是选择成熟、稳定的关联数据集来降低链接错误率,其次是定时对关联数据的URI 链接进行检查,及时更新或删除相关的链接。
(3)用户交互。OPAC混搭关联数据主要功能是单向地向用户推荐相关信息,如果某些相关信息不完整,或者用户发现相关信息不准确时,则无法及时主动地贡献相关内容,这需要图书馆进一步结合其他技术进行研究和完善。
5 结 语
关联数据作为语义网的一种实现方式,成为推动语义网发展的重要力量之一,正在世界范围内引发着一场深刻的网络革命。关联数据具有坚实的技术基础、完整的系统结构和简便的发布方式等优点,将会有越来越多的图书馆关注并应用关联数据。可以预见,关联数据将给图书馆带来巨大的变革。
由于案例的实验性质,相关的数据样本量较小,本文提出的OPAC混搭关联数据尚未展开大范围的应用,因此无法进一步提供使用效果的评价。未来笔者会进一步完善该系统,开放应用并进行用户测评,从而为相关的实践提供更多的参考。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|