{kind=link}
基于N-Gram的文本语种识别研究*
引用本文
王昊, 李思舒, 邓三鸿. 基于N-Gram的文本语种识别研究* . 现代图书情报技术, 2013, 29(4): 54-61
Wang Hao, Li Sishu, Deng Sanhong. Study on Text Language Recognition Based on N-Gram. New Technology of Library and Information Service, 2013, 29(4): 54-61
Permissions
Wang Hao, Li Sishu, Deng Sanhong. Study on Text Language Recognition Based on N-Gram. New Technology of Library and Information Service, 2013, 29(4): 54-61
基于N-Gram的文本语种识别研究*
摘要
基于N-Gram理论实现一个文本语种自动识别系统, 对中文简体、中文繁体、英语、法语、德语、俄语和韩语等在互联网中广泛使用的语种的文本进行语种自动识别研究。研究实验分为多语种语料库训练和语种识别两个阶段, 训练和测试文本均来自于开放式目录工程 (ODP) 。此外, 将笔者开发的识别系统与另一基于N-Gram的语种识别程序TextCat进行对比分析。实验结果表明, 该系统对中文简体、中文繁体、德语有较高且稳定的正确识别率, 对俄语、法语、英语的正确识别率其次, 对韩语识别容易受到汉语影响。
关键词:
N-Gram; 多语种识别; 语料库; 文本分类
Study on Text Language Recognition Based on N-Gram
Abstract
A language recognition program which is used to auto recognize the textures of the most popular languages on Internet including Chinese-simple, Chinese-traditional, English, French, German, Russian and Korean, is realized in this paper based on the N-Gram language module. The speech recognition experiments are divided into two stages of training of multilingual corpus and testing of language recognition, the texts of training and testing come from the Open Directory Project. The program is used to participate in the language recognition test, as well as to make contrast tests to another language recognition program based on N-Gram named TextCat. The result of the language recognition experiment proves that the program has a fine performance on recognizing Chinese-simple, Chinese-traditional and German, and the accuracy of recognition on Russian, French and English in the next place, the Korean is always interfered with Chinese in these experiments.
Keyword:
N-Gram; Language recognition; Corpus; Text classification
1 引 言
随着互联网的发展和普及, Web文本的数量激增, 且出现多语种并存的现象。自动识别Web文本所属的语种, 对一些有特定需求的自然语言处理过程, 如WWW索引 (WWW Indexing) 、询问 (Interrogation) 以及推荐阅读 (Reading Aids) 等, 都是必经的一道程序[ 1]。业界学者们普遍认为, 可以把语种识别问题看作是“基于某些特征进行文本分类”这一问题的一个特例[ 2]。随着跨语言检索技术的发展, 作为其核心技术的文本语种识别研究开始受到广泛关注。目前多语言识别研究还没有形成系统的理论阐述和实践论证, 多聚焦于算法模型的改进和具体领域的应用, 前者主要以语言学和机器学习方法作为实现手段[ 3, 4], 后者则主要以机器翻译[ 5]和多语言检索[ 6, 7]作为实践场所。更多可参考的知识则来源于在互联网上已经出现的一些典型的文本语种识别工具, 例如基于N-Gram理论的TextCat及其各种实现版本、Lextek Language Identifier、Languid等。以TextCat为例, 它包含74个语种类型的5-Gram语料库, 理论上可对此74种语言进行区分识别。
本文继承N-Gram理论思路, 从开放式目录工程 (Open Directory Project, ODP) 获取多语种文本数据, 尝试设计文本语种识别系统模型, 对中文简体、中文繁体、英语、德语、法语、俄语和韩语等7种Web常用语言建立N-Gram语料库, 进行多语种识别测试, 在实践中调整模型中的参数, 并将识别结果与使用相同测试用例的TextCat识别结果进行对比。以此来探索提高语种识别准确率的方法和多语种识别在跨语言检索系统中的位置和作用等。
2 N-Gram理论
N-Gram是指给定的文本或语音序列中包含N个最小分割单元的连续序列[ 8]。最小分割单元可以是音素、音节、字母、字或者是一些根据具体应用而自定义的基本对 (Basic Pairs) 。
N-Gram实际上是N-1阶马尔可夫语言模型的表示。假设一列随机变量S1, S2, …, Sm中, 如果其中任何一个随机变量Si发生的概率只与其前面的N-1个变量Si-1, Si-2, …, Si-n+1有关, 即:
P (Si|Si-n+1Si-n+2…Si-2Si-1) =P (Si|S1S2…Si-2Si-1) .
则称之为N-1阶马尔可夫过程[ 9]。N-Gram模型就是将所有连续可重叠的N个词作为一个单元, 并将其假设为一个N-1阶马尔可夫过程。这种假设的意义在于, 第N个词的出现只与前N-1个词相关, 而与其他任何词都不相关。整个句子的概率是各个词出现概率的乘积, 而这些单个词的概率可由语料库中统计N个词同时出现的次数得到。
N-Gram理论在信息检索研究中主要应用于检索预处理、索引、语种识别等先导性工作, 包括语音和文本分析领域。在语音分析领域, Torres-Carrasquillo等[ 10]使用音素标记化结合N-Gram将语言模型化来进行语言识别, 得到稳定的结果。在文本分析领域, Schmitt[ 11]提出一种基于三元文法判别语种类型的方法;郑敏[ 12]采用N-Grams方法对文本进行检索预处理, 主要依赖概率统计学的知识, 包括二元文法 (Bigrams) 和三元文法 (Trigrams) , 并特别指出N-Grams方法对未登录词的处理有独特的优势;Niels等[ 13]则采用基于关键词和N-Grams的方式对占据EuroGOV 语料库75%的语言类型未知的文档进行索引, 实验结果表明能有效消除不同语种之间的差异对待性。
3 基于N-Gram的文本语种识别模型设计
3.1 模型概要设计
.
本文设计的文本语种识别系统应用N-Gram理论, 分别对训练文本和测试文本进行词句单元抽取及词频统计, 然后通过相似度对比排序, 判断文本语种类型, 其模型流程如图1所示:
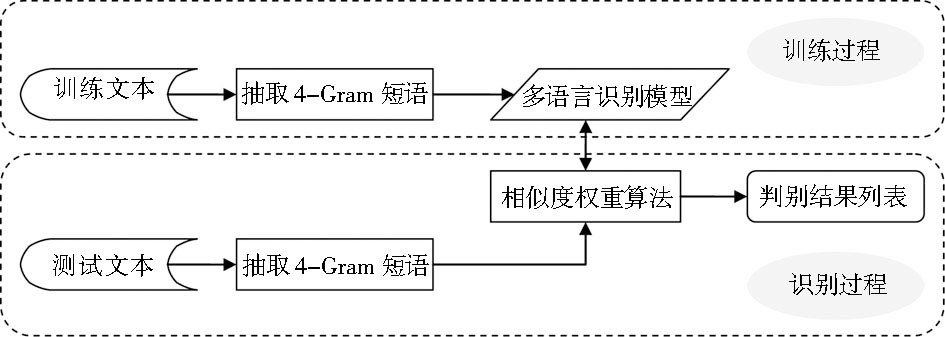 | 图1 识别系统模型概要设计 |
将训练文本和测试文本进行相同的4-Gram语词单元的抽取和词频统计。其中训练文本经过处理后的结果以文本语种模型的形式呈现。测试文本经过处理后, 将采用相似度权重算法来计算和各个文本语种模型的相似度, 以此作为最终判别结果的依据。
3.2 N的选取
.
基于N-Gram算法的基本思想是将文本内容按照字节流进行大小为 N的滑动窗口操作, 形成长度为1~N的语词片段序列, 分别统计各个语词出现的频率[ 14]。因此, 对文本中N-Gram进行统计的计算量随着N取值的增大而增大。
使用N-Gram抽取训练及测试文本中的词语单元时, 基本要求是所抽取的 N-Gram 单元能够覆盖文档中有语义的词。统计分析表明, 在中文文本中, 主要词条为 1~4-Gram词条[ 15]。因此, 抽取1~4-Gram的词语单元可较完整地表达整个中文文档语义。由于汉字等东方字符集多为双字符编码, 而英文等西文字符对此无特殊要求。因此, 选择4阶作为实验参数, 并期望在后续实验中进行调整。即对于字符串“南京大学”, 识别程序按照长度为1~4的窗口进行切分, 示例如表1所示:
| 表1 N-Gram算法中参数N取4时的文本切分示例 |
3.3 文本语种模型
通过对训练文本的N-Gram (N=1, 2, 3, 4) 计算, 可以建立文本语种模型。各语种的语言模型均包含两列。首列列举N-Gram (N=1, 2, 3, 4) 词汇单元, 第二列是其相应词频, 按降序排列。各语种语料库中词频各异, 在语种识别流程中, 词频只是作为排序依据而非相似度权重计算依据。
因训练数据量不大, 故语料库规模偏小, 识别模型中的各语言模型适用于训练文本所属的垂直领域。
3.4 相似度权重算法
文本语种识别模型关键步骤在于参照各语种语料库中的4-Gram, 计算各测试文本4-Gram的权重。相似度权重计算过程伪码如下:.
if someHashMap.containsKey (testNgram[i]) .
weight += Absolute (someHashMap.get (testNgram[i] - i) ;
else.
weight += PUNISHMENT;
即如果测试文本中抽取出来的语词单元存在于某多语种模型中, 则根据该语词单元在语言模型中的索引位置, 给出一个权重值;否则, 给出一个惩罚值PUNISHMENT。这里的PUNISHMENT是一个全局参数, 可以依据具体运行结果进行微调。
| 表2 文本语种识别重要参数 |
上述算法设计与训练和测试N-Gram语料库结构结合紧密, 设计思想基于简单概率统计, 实践关键在于相关参数的调整。程序中较重要的全局参数及其作用如表2所示。
4 文本语种识别实验设计
4.1 实验概述
基于N-Gram的文本语种识别实验, 分为N-Gram语料库训练和文本测试两部分。选择中文简体、中文繁体、英语、法语、德语、俄语、韩语共7个语种作为训练和识别对象, 构造7语种语料库, 以及相应测试文本, 查看识别情况。
7个语种各自选择20个测试文本, 包括短文本、长文本和混合语言文本三种构成形式。其中长短文本皆是纯语种文本, 包含少量数字和特殊符号等, 短文本的字符数在500-1 000, 长文本为1 000-3 000字符;混合语言文本指两种以上语种混合的文本。采用中文、英文和其他语种文本进行两两混合, 比如中英混合、中韩混合等, 混合比例分1∶1和不均衡两种;短、长、混合文本的比例分别为50%、40%和10%。
将本文多语种识别程序与同领域内知名的TextCat语种识别工具进行4组对比测试, 包括:TextCat调用自身与本文研究对象相关的7种多语种语料库、TextCat调用自身全部74种多语种语料库、TextCat调用本文7种语料库、以及本文程序调用TextCat 7种语料库, 在对比中进一步探讨多语言识别的细节问题。
4.2 数据来源
.
本文数据均来自ODP, ODP是目前互联网上最大、最广泛的人工目录[ 16]。截止2012年4月, ODP下的类目数超过101万个, 共收录500多万个站点[ 17]。尤其在一些冷门学科或边缘学科上, 其类目数量比雅虎提供更全面。在遵守“ODP 许可”和“归属说明条例”的条件下, 任何机构和个人均可免费下载和使用ODP的数据[ 18]。
本实验采用ODP World目录下的文本语种分类目录。从参与测试的语言的分类链接中人工选取优质内容的站点链接, 摘取或长或短的纯语言文本作为实验数据。由于各种语言下的分类目录种类和数量不完全相同, 因此领域分类选择各语种共有的新闻、社会科学、互联网或计算机、艺术等类别。具体种子链接选取及其对应于ODP的目录层次如表3所示:
| 表3 文本语种识别实验文本来源链接 |
4.3 测评指标
(1) 正确识别比例 (针对长、短文本的识别) .
正确识别比例用于衡量识别结果正确的样本数目占参与测试的样本总数目的比重。比值越大说明程序识别正确率越高。这个指标是长、短文本识别结果的重要参考。本实验中未采用直接列举比值的方式来呈现识别结果。例如“19/20”指共20个实验样本, 其中有19个样本的语言形式能够被正确识别。
(2) 正确识别结果 (针对混合文本的识别) .
正确识别结果直接展示参与混合文本的识别情况。例如“en→ch”指在该语种中混合了近一半比例的英语, 最终被识别为汉语。
(3) 误识别用例.
在实验结果表中列举长、短文本中误识别用例, 便于实验后直接分析。
5 文本语种识别实验结果及分析
5.1 多语种识别程序调用7种语料库的实验及分析
基于本文开发的多语种识别程序调用训练获得的7种语料库, 使用长、短及混合测试文本进行文本语种识别测试, 结果如表4所示:
| 表4 多语种识别程序调用自身7种语料库识别结果 |
表4中对7语种采取缩写形式, 其余语种采用全称。例如误识别用例“fr 2”表示该语种误识别用例中有2例被判断为法语;误识别用例中“persian 1”表示该语种被误识别为波斯语;Chinese_gb2312中混合文本“en→en”表示中文简体和英文各占半数组合而成的混合文本, 被识别为英文;“none”则表示TextCat程序中无法判断语种类型的提示“I don’t know; Perhaps this is a language I haven’t seen before?”;“except Chinese”指去除误识别为中文这个影响因素, 是一个宽容的度量。
从表4可以看出, 在现有的语料库和测试文本环境下, 多语种识别程序对中文简体、中文繁体以及德语的识别较成功。对中文简体和中文繁体的短文本的识别都达到100%。长文本识别中, 中文简体有2例误识别, 分别被识别为法语和俄语;中文繁体的长文本有1例误识别, 识别结果为中文简体。在混合文本的识别中, 中文简体中混合入约50%的英文和中文繁体, 被识别为各自混合的语种;中文繁体混合入英文和中文简体的文本, 识别结果分别为英语和中文简体。德文的识别很清晰。长短文本识别率都达到100%, 而混合了中文简体和英文的德文文本也一律被识别为德语。
俄语和法语的识别正确率也较高, 俄语短文本中只有1例被识别为德语, 法语短文本中误识别的2例分别是德语和英语, 均为西欧语言。长文本中, 俄语的2例误识别均被判断为中文简体, 法语的2例则均被误判为德语。
英文的识别结果不尽如人意, 长文本的识别正确率明显比短文本的识别率高, 前者比例为5/8, 后者为6/10, 均是刚过半数。长短文本均容易被误识别为法语和德语。中英混合文本识别均被识别为英语。结果显示, 直接识别, 英语文本可能被识别为与其血缘关系相近的法语、德语。但如果是与血缘关系较远的藏汉语系语言混合, 英语被正确识别的比率会提高。
韩语的直接识别结果多被中文简体、中文繁体或少量德语取代。若排除误识别为中文等因素的影响, 18例长短韩语文本被正确识别的比例是11例。笔者曾尝试加大韩语语料库训练文本的数量和质量, 结果有所提升, 但识别不准, 尤其受汉语影响比较大。
5.2 与TextCat多语种识别工具的比较分析
(1) TextCat调用自身语料库.
使用TextCat并选择它自身的7种语料库, 进行文本语种识别实验, 结果如表5所示:
| 表5 TextCat调用自身7种语料库识别结果 |
中文简体、中文繁体和德语的识别非常出色。其中中文简体和德语均能够被完全识别;只是在德语混合文本识别时, 中文简体被识别为德语。中文繁体的短文本中有1例被误识别为中文简体, 长文本中有1例被识别为日语。
英语识别的效果其次。短文本中有2例被识别为法语, 长文本中1例被识别为德语, 混合文本中2例中英文也均被识别为德语。
法语的识别效果也较好, 不过暴露出一个用户体验的问题, 即出现“未能识别”的提示。返回效果上来看, 长短文本的正确识别率均略过半数。未被识别的用例一律返回“I don’t know; Perhaps this is a language I haven’t seen before?”, 出现这种提示的原因可能是TextCat计算出来的位于结果列表前几位的返回值权重值接近, 根据区分策略无法区分。
俄语识别返回的结果很差。长短文本有返回识别结果的各自只有2例, 短文本返回中文繁体和德语, 而长文本除1例正确返回外, 另1例错误识别为中文简体。其余返回结果均为“I don’t know; Perhaps this is a language I haven’t seen before?”因为它为西欧语言, 识别效果可能受其他西欧语言的影响, 但统一返回这样的结果无法呈现出很好的区分。
韩语识别受中文等同源的东亚语言影响也是明显的。除了短文本中有2例分别被识别为俄语和德语, 其余测试用例的结果列表基本都是中文简体或繁体在先, 韩语紧随其后。混合文本识别中, 中文简体被识别为中文繁体, 英语仍被识别为英语。
(2) TextCat程序调用本文语料库.
使用TextCat程序, 调用笔者训练的7种语料库。识别结果呈现的规律与笔者的程序调用自己语料库的结果相似, 如表6所示:
| 表6 TextCat调用7种语料库识别结果 |
表6中数据特点是:中文简体、中文繁体和德语的识别正确率仍然高于其他语种的识别结果。中文简体和德语识别结果中, 全部测试文本的语种类型可以被正确识别。对于中文繁体, 短文本中1例被误识别为德语, 长文本中1例被误识别为中文简体。
法语识别中, 与TextCat调用自己语料库相比, 没有无法识别的结果, 但准确率略显不足。短文本有2例被误识别为德语;长文本2例分别被误识别为德语和英语;混合文本均被识别为法语。
俄语识别中, 短文本2例仍然被识别为德语;长文本3例分别被误识别为中文简体、韩语和德语, 其中值得关注的是1例西欧语言被误识别为东亚语言;混合文本识别比较混乱, 中俄混合被识别为俄语, 英俄混合被识别为德语。
韩语识别仍未能排除中文的影响。不过排除中文影响之后的识别率, 短文本9/10, 长文本7/8, 比TextCat原程序有所提升。
英语识别中大量被误识别为德语。包括两个混合文本中, 其中一个中英混合文本, 也被误识别为德语。
(3) 多语种识别程序调用TextCat语料库.
使用本文的多语种识别程序调用TextCat的语料库, 结果如表7所示:
| 表7 多语种识别程序调用TextCat 7种语料库识别结果 |
中文简体识别第一次出现较多杂质。整体看来, 短文本识别效果要比长文本好。短文本中有两例被误识别为俄语和捷克语;长文本误识别多达6个用例, 识别结果也多种多样, 误识别为瑞典语、挪威语、马恩岛语 (Manx) 、希伯来语 (Hebrew) 、梵语 (Sanskrit) 和土耳其语 (Turkish) 各1例。中英混合文本识别正常。
中文繁体识别比中文简体好许多。短文本被完全识别;长文本有50%的误识别率, 分别被误识别为中文简体1例、希伯来语2例和西班牙加泰罗尼亚语 (Catalan) 1例。中英混合文本被识别为英文, 和中文简体的混合文本被识别为中文简体, 识别功能正常。
德语识别效果不好。仅有4例短文本和2例长文本被正确识别。误识别中很大比例是被识别为中文繁体。混合文本识别略有偏差。中文简体和德语混合文本被识别为中文繁体, 英德混合则被识别为加泰罗尼亚语。
英语长短文本18个用例中能够被正确识别的只占4例。误识别14例中有半数被识别为中文繁体。两个中英混合文本一致被识别为英语。
法语短文本只有1例被正确识别, 包括混合文本在内, 被误识别为中文繁体的用例共为7例, 被误识别为越南语 (Vietnamese) 的合计也有4例。
俄语短文本无一例外被识别为中文繁体, 长文本和混合文本中各有一半被误识别为中文繁体。
韩语在这次测试中受中文的影响仍然严重, 短、长文本 (包括混合文本) 被误识别为中文的用例各有8例和3例, 其余被识别为弗里斯兰语 (Frisian) 、波斯语 (Persian) 、俄语、阿拉伯语、加泰罗尼亚语等。
6 结 语
(1) 汉语对韩语识别具有一定影响。这个现象在上述4组实验中均有明显反映。其直接原因是互联网固有的语言编码之间的冲突。由于互联网上语言编码分布各异, 东方大字符集中文字编码的分布尤为错综复杂, 中、韩、日编码之间的冲突一直是语言文字处理的障碍之一。这三种语言均为双字节编码, 编码间有大片重合区域。目前语言学界将世界语言划分为九大语系, 汉语被公认划分为藏汉语系, 韩语则属于阿尔泰语系, 它们长期以来被公认为是两个各自独立形成的语言群体[ 19]。但蒙古族的语言学家芒·牧林[ 20]在《古突厥文来源新探》中, 提出汉藏语系和阿尔泰语系之间极有可能存在亲缘关系。因此汉语对韩语识别的影响有其语系根本的原因, 如果原因成立, 那么多语种识别程序的设计思路或许要改变。
(2) 英、俄、法、德语识别存在互相影响。在英语识别结果中, 长短文本中误识别用例的返回结果均为法语或德语, 而德语对俄语识别也存在1例的干涉;在英语识别表现较好的TextCat识别工具的测试中, 3例误识别用例中, 法语占据2例, 德语1例。从语言学角度分析, 英语和德语属于日耳曼语族, 法语属于拉丁语族, 俄语则属于斯拉夫语族, 它们均属于印欧语系。笔者再增加5万英语语料训练文本后, 实验结果显示正确识别率提升较明显, 可见, 语料库对识别结果有影响。
(3) 长文本比短文本更有优势。究其原因, N-Gram是一个简单概率模型, 输入的测试文本词语数量越庞大, 得到的测试语言模型越趋近于其所属的语言模型, 判别为同类语言的概率也越大。
(4) 人名、地名等名词识别对小型N-Gram语料库建设的影响。在本文自建语料库运行程序过程中, 有一则英语用例被误识别为德语, 通过查看测试文本发现, 文中每段都会出现2-3个人名或地名。这些字符串在N-Gram看来, 与英语不同族。如果剔除全部人名或地名, 识别结果的后台判别权重会略有提升, 由此可见名词识别对多语种整体识别结果也存在微妙影响, 因此在文本语种识别前添加名词识别功能模块, 有助于提升识别率。
值得说明的是, 上述研究结论均基于本文的实验论证获得, 而鉴于样本筛选的复杂度和时间限制, 本文针对每一语种仅选择了20个测试文本, 每个文本在500-3 000字符之间。虽然在现有实验数据量下得出一些能够说明问题的结论, 但是测试样本量需要进一步增加以提高实验测试和分析结论的正确性和说服力, 这一问题将在未来的语种识别工具的具体开发研究中予以改进和完善。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|