
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
在线商品评论效用排序模型研究*
引用本文
李志宇. 在线商品评论效用排序模型研究* . 现代图书情报技术, 2013, 29(4): 62-68
Li Zhiyu. Study on the Reviews Effectiveness Sequencing Model of Online Products. New Technology of Library and Information Service, 2013, 29(4): 62-68
Permissions
Li Zhiyu. Study on the Reviews Effectiveness Sequencing Model of Online Products. New Technology of Library and Information Service, 2013, 29(4): 62-68
在线商品评论效用排序模型研究*
摘要
从研究在线评论效用的影响因素入手, 建立评论效用指标体系。采用模糊层次分析法确定指标的相对权重, 通过语义挖掘对评论内容的各项指标进行量化处理, 最后统计每条评论的效用总分。模型应用部分选取国内淘宝商城某商品的近2 000条商品评论信息进行实证分析。研究对比发现, 经过排序模型处理后, 大量的无用评论被后置, 新排序中靠前的评论内容信息含量非常丰富, 评论效用较高, 能够有效地辅助其他消费者进行购物决策。
关键词:
信息挖掘; 在线评论; 效用排序
Study on the Reviews Effectiveness Sequencing Model of Online Products
Abstract
On the basis of studying the influencing factors of online reviews effectiveness, a review effectiveness index system is established. The fuzzy analytic hierarchy process is adopted to determine the relative weight of indexes, various indexes of reviews content are quantized by semantic mining, and the total effectiveness score is calculated for each review. In terms of the model application of this study, nearly 2 000 reviews on a product of China’s Tmall are selected to make an empirical analysis. The study and comparison indicates that, after being processed by the sequencing model, a large number of useless reviews are postponed, and those reviews at the forefront of the new sequence are very rich in information content and high in effectiveness, and can assist consumers in making purchase decisions effectively.
Keyword:
Information mining; Online reviews; Effectiveness sequencing
1 引 言
在线下市场, 消费者购买商品时的决策在很大程度上依赖于现实生活中相互之间的产品口碑传播。随着互联网商务应用的高速发展, 在线商品评论开始产生, 传统口碑开始逐渐向电子口碑过渡, 在线商品的评论信息已经成为消费者进行网络购物决策时的重要参考依据之一。消费者开始习惯于在线评论自己对商品和服务的看法, 并使其评论内容对其他消费者的购物决策造成影响[ 1]。但是, 网络购物高速发展的同时也伴随着信息过载的现象[ 2], 由于在线评论的数量呈几何级增长, 动辄几千条甚至上万条的商品评论也让用户感到无所适从, 并且从这些商品中获取有用的信息开始变得十分困难[ 3]。因此, 需要建立一定的评论效用评价机制, 对大量的评论内容进行数据挖掘与处理, 提取出对于消费者购物决策较为有用的评论, 在第一时间内展现给消费者, 辅助其进行购物决策。
2 国内外研究现状
从2006年起, 国内外学者开始对在线商品评论效用进行逐步深入的研究, 其研究内容主要集中在4个角度, 即评价目标、评价特征、评价技术以及评价对象[ 4]。
(1) 评价目标.
Miao等[ 5]通过将信息质量的时间维度以及将主题相关性纳入评论排序的考量因素, 建立起一个观点搜索系统, 以此满足消费者的个性化需求。Liu等[ 6]从鉴别垃圾评论与非垃圾评论的测度规范方法的角度出发, 建立支持向量机的评论自动分类机, 对垃圾评论和非垃圾评论进行分类。
(2) 评价特征.
对于评论效用的度量, 需要建立相应的指标进行计算与统计。Zhang[ 7]认为在评论内容中, 评论的表面语法特征在进行评论的效用分析及预测有用性时贡献最显著, 而郝媛媛等[ 8]则认为在线评论的正负情感倾向对于评论的有用性影响最为显著。彭岚等[ 9]从减少消费者决策风险出发, 在感知诊断性概念基础上定义了评论的有用性概念, 构建了一个有用性影响因素模型, 将评论等级、评论长度、好评率和互联网经验作为考察有用性的主要因素, 但研究内容缺乏对评论内容本身的信息挖掘, 忽视了消费者获取评论信息的主要目的。
(3) 评价技术.
在线商品评论效用的评价技术主要可以分为基于机器学习和基于相似度得分的两类方法[ 4]。Liu 等[ 6]利用支持向量机的评价技术方法来检测低质量的垃圾评论。Lau 等[ 10]认为过度泛滥是垃圾评论的重要特点之一, 即内容雷同的评论针对不同产品重复出现, 由此对照每条评论的相似度评分, 来区分出垃圾评论和有用的评论。
(4) 评价对象.
在线商品评论对象的类型主要可以分为“实用型”和“享用型”两类商品[ 11]。郝媛媛等[ 8]基于影评数据的在线评论有用性研究, 以评论阅读者及时提供有用性评论为目标, 结合文本挖掘技术与实证研究方法, 建立了在线评论的评论有用性影响因素模型, 并用于有用性分类预测, 但由于研究对象局限在享用型商品——电影数据上, 使得模型的可扩展性不强, 无法直接应用于实用型商品的模型建立, 因为不同类型的商品, 其评论内容的差异性较大, 评论的效用及其影响因素也会不同。
本文从实际应用角度出发, 综合考虑评价特征的选取要素, 建立评论有用性指标模型, 通过对模型评论数据的信息挖掘与处理, 采取语义挖掘以及元数据特征度量, 将评价指标量化, 然后运用模糊层次分析法对已量化指标进行评分处理, 得出每条商品评论的有用性得分, 从而确定评论内容对消费者购物决策的有用性程度, 排定评论内容展现的相对位置, 辅助消费者在大量的商品评论中获取最有用的信息。 .
3 模型设计
3.1 概念模型
.
Clemons等[ 12]指出, 消费者阅读在线商品评论的主要目的是为了获取和产品的相关信息以减少购买决策中的不确定风险。基于此, 本文构建关于评论有用性的指标体系。
现有在线购物网站对消费者的评论内容排序方式主要有按时间排序、按消费者信用排序和按评论内容得票数排序三种方式。但由于单一指标排序存在相对偏差性, 无论采用哪种排序方式都无法将对消费者购买决策起较大参考作用的评论在第一时间内展现给消费者。因此需要综合考虑影响消费者在实施购买决策时的决定性因素, 对大量的评论内容进行效用排序, 将对于消费者效用较高的评论内容前置, 而将无用评论后置, 辅助消费者做出有效的购买决策。
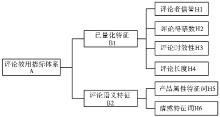
根据指标信息来源以及数字化特征, 将评论指标体系分为两个二级指标和6个三级指标, 如图1所示:
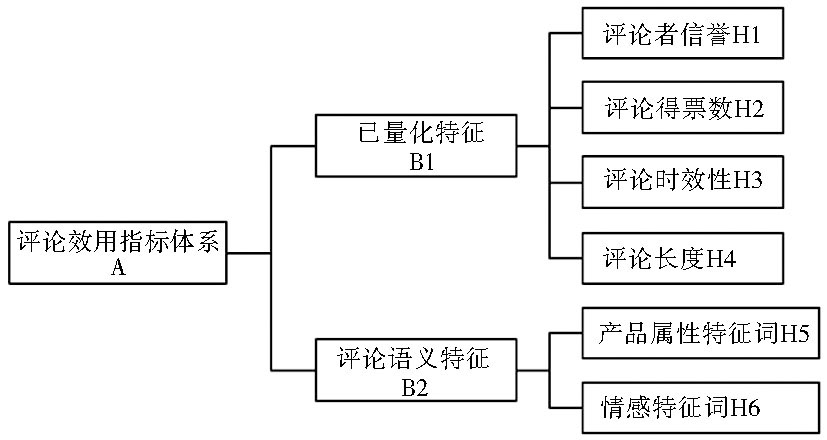 | 图1 评论效用概念模型 |
其中已量化特征指直接通过对网站数据进行抓取即可获得的指标数据, 分别为评论者信誉、评论得票数、评论时效性、评论长度;评论语义特征指需要对评论内容进行语义挖掘后方可获得的指标数据, 分别为产品属性特征词数量和情感特征词数量。
3.2 研究假设
(1) 已量化特征B1.
①评论者信誉对评论效用的影响.
评论者信誉是消费者网络购物经验丰富程度的一个重要体现, 高信誉的消费者在进行购物评论时, 其评论的“引导作用”往往比低信誉的评论者要强。对于缺乏购物经验的其他网络购物者而言, 高信誉评论者的“意见领袖”作用较为明显, 因此高信誉者的评论对其他消费者的效用相对低信誉者的评论要高。因此提出假设H1:评论者信誉对评论效用的影响是积极的, 占指标总权重为W1。
②评论得票数对评论效用的影响.
多数电子商务网站的评论栏目都设置有投票项, 即评论的阅读者可以对其他消费者的评论内容进行投票。得票数越多, 表示该评论内容的赞同者越多, 通过对不同评论得票数进行排序, 从而达到对评论效用排序的目的。但这种单一因素排序法存在“时间差异性”的问题, 即得票数高的更高, 最新的评论排序反而被置后。因此, 只能作为影响效用的一个参考因素, 提出假设H2:评论得票数对评论效用的影响是积极的, 占指标权重为W2。
③评论时效性对评论效用的影响.
评论的时效性是指评论者做出评论的时间和当前阅读评论时间的差值, 差值越小, 表示评论越新, 时效性越高;差值越大, 表示当前时间距离评论时间越久远, 时效性也就越低。对于同一个商品而言, 距离当前时间越近的评论, 其参考价值越高, 即对于消费者的效用越高。因此, 提出假设H3:评论的时效性对评论效用的影响是积极的, 占指标权重为W3。
④评论长度对评论效用的影响.
Mudambi等[ 13]的研究发现, 评论的字数对于评论的有用性影响是正相关的。评论字数越多, 评论长度越长, 其中对商品及其服务的描述可能就越详细, 这种详细的描述对于其他消费者而言, 能够在很大程度上减少购买决策时的不确定性, 从而增加评论的效用。因此, 提出假设H4:评论长度对评论效用的影响是积极的, 占指标权重为W4。
(2) 评论语义特征B2.
①产品属性特征词对评论效用的影响.
产品属性特征词多表现为名词和名词性短语, 是对产品本身及其服务的客观性描述。评论内容中所包含的产品特征词越多, 则评论内容与评论产品的相关度越高, 所包含的信息也就越丰富, 对其他消费者的辅助决策作用也就越好。因此提出假设H5:产品属性特征词对评论的有用性影响是积极的, 占指标权重为W5。
②情感特征词对评论效用的影响.
在进行商品评论时, 评论者会根据自身使用产品或服务的体验和主观感受进行情感评价, 评论内容会体现出评论者的态度倾向, 即“喜欢”、“厌恶”或者“一般”, 并且呈现出强度的变化。当评论内容中多次出现“很”、“不好”、“好”等带有感情色彩的词汇时, 表明该评论者在使用产品或者服务的过程中感受较为深刻或者体验较为丰富, 从而能够在评论内容中提供丰富的参考信息。较多的正面情感词汇将促使其他消费者做出成功购买的决策, 而负面的情感词汇将使得消费者做出放弃购买的决策。因此, 情感特征词能够增强评论的效用, 更好地辅助消费者进行购买决策, 从而提出假设H6:情感特征词对评论效用的影响是积极的, 占指标权重为W6。
4 关键技术方法及系统实现
4.1 关键技术路线
.
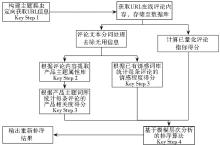
首先通过构建主题爬虫获取在线商品的评论信息, 然后对评论内容进行分词处理, 提取产品属性, 构建属性词库。接着对评论内容进行量化评分, 利用模糊层次分析法处理评分数据, 得出最后评论效用得分, 从而能够区分不同评论的效用高低, 将效用较高的评论在第一时间展现给消费者。研究的核心技术步骤包括获取评论内容、构建产品属性词库、相似度和情感强度对比评分、模糊层次分析法排序4个主要内容, 其关键技术路线如图2所示:
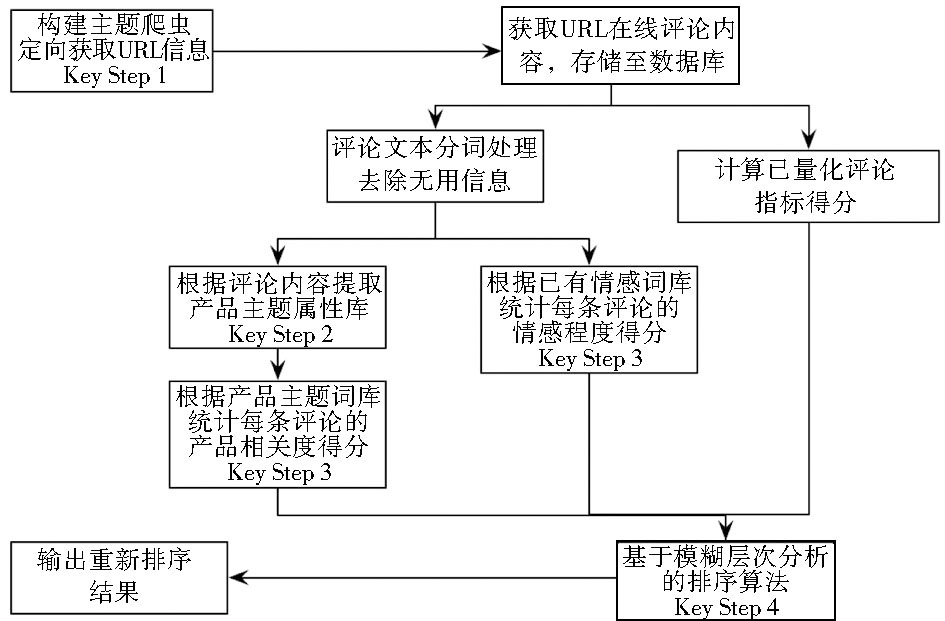 | 图2 关键技术路线 |
4.2 关键技术步骤的实现
.
.
.
(1) 评论内容获取.
产品评论内容的获取是研究分析的准备阶段, 由于获取的数据量较大, 必须采用网络爬虫批量获取。本文采用GooSeeker公司的集成网络信息抓取工具包MetaSeeker。MetaSeeker是一个Web网页页面信息提取的工具包, 包含MetaStudio和DataScraper两个基本组件, 能够按照用户的指导, 从Web页面上筛选出需要的信息, 并输出含有语义结构的提取结果文件 (XML文件)[ 14]。
MetaStudio组件将目标网页内容的语义结构用信息结构表述, 信息属性是信息结构的组成成分, 在抓取网页内容时, 信息结构就像一个容器 (称为整理箱)[ 15], 将目标网页上的内容进行结构化“整理”, 并且对应一个个信息属性字段存储。MetaStudio自动生成的抓取页面内容的规则能够有效地将不需要的网页内容过滤掉, 只保留与信息属性字段对应的内容, 从而达到信息抓取的目的。
(2) 评论内容的情感强度评分.
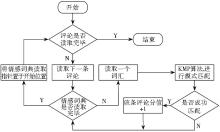
评论内容的情感强度是通过评论者在评论内容中书写的与情感相关的词汇表现出来, 如在评论内容“这本书是一本值得一看的好书”中, “值得”、“好”等就属于情感词汇。在模型中, 主要通过计算每条评论中情感词汇出现频率, 来判定该条评论的情感强度。模型首先对每条评论进行分词处理, 然后对照情感词汇词典, 判断哪些词汇属于情感词汇, 同时统计词汇出现的次数。情感词汇词典主要来源于台湾大学的简体中文情感极性词典[ 16], 其中包含2 810个正极性词语和8 276个负极性词语, 相对知网的情感词汇集来说, 台湾大学的词典更加丰富和准确。情感强度统计评分的主要算法流程如图3所示:
 | 图3 评论内容情感强度评分算法 |
(3) 评论内容产品相关性评分.
评论内容的产品相关性评分需要构建产品属性词库, 然后通过统计每条评论中产品属性词出现的次数, 来计算评论内容的产品相关性得分, 其中构建产品属性词库是该步骤的核心算法之一。
产品属性可以分为显式属性和隐式属性[ 17]。显式属性是对产品或者服务本身进行描述的名词或者名词性短语;隐式属性并没有对产品或服务进行直接性的描述, 而是需要根据描述的上文和下文的语义进行理解才能够获得。目前, 由于隐式属性的获取需要依靠人们对自然语言的逻辑处理和语义理解, 处理技术难度较大, 从而对于产品属性的提取主要集中在显式属性的提取研究上。
产品属性的提取方式主要有人工提取和计算机自动提取两种方式[ 18]。人工提取需要专业领域内的专家以及产品使用者参与, 工作难度和工作量较大, 属性的可移植性较差;计算机自动提取相对人工提取而言, 提取所得属性的精准度又需要进一步提高。在计算机自动提取的研究中, 精准率较高的是Popescu等[ 19]的研究项目, 他们首先通过提取商品评论中频率较高的词汇作为候选词, 然后分别计算Konwitall系统自动生成的鉴别短语和提取词的PMI值, 最后以贝叶斯分类作为依据来筛选产品属性词, 从而获得较为准确的产品属性词库。在本模型的研究过程中, 采取人机相结合的方式, 首先利用计算机提取确定由高频词汇组成的属性词典, 然后再通过人工筛选降噪, 进一步提高产品属性词汇的精度, 主要算法流程如图4所示:
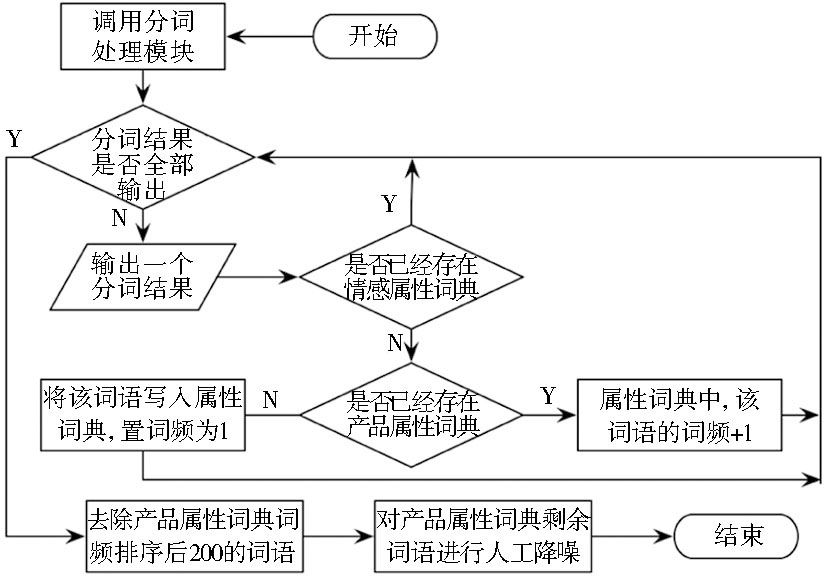 | 图4 产品属性词典生成算法 |
算法中分词处理模块调用中国科学院计算技术研究所的ICTCIAS分词系统进行分词处理, 其余模块采用Java编程技术辅助实现。
(4) 基于模糊层次分析的评论效用排序算法.
模糊层次分析法 (FAHP)[ 20]是一种将层次分析法 (AHP) 与模糊综合评价相结合的定量分析方法。其主要算法步骤如下:.
①建立排序问题的层次结构模型.
本算法采用的评价指标层次模型见图1。
②建立优先关系矩阵并模糊一致化.
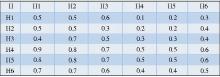
模型中判断矩阵的构建主要来源于专家打分以及对网络消费者进行的问卷调查, 通过问卷调查得到消费者对于不同影响因素的侧重点, 找出影响消费者购物决策的主要因素, 提高效用排序的可靠性。在问卷调查过程中, 笔者将指标矩阵通过网络发放给用户填写, 采用0.1-0.9标度法, 要求用户通过比较不同指标因素的重要性关系, 填写出优先矩阵。比较要求如表1所示:
| 表1 优先矩阵比较标度 |
对获得的优先矩阵数据进行统计并均值化处理后得到优先关系矩阵 (精度0.1) , 如图5所示:
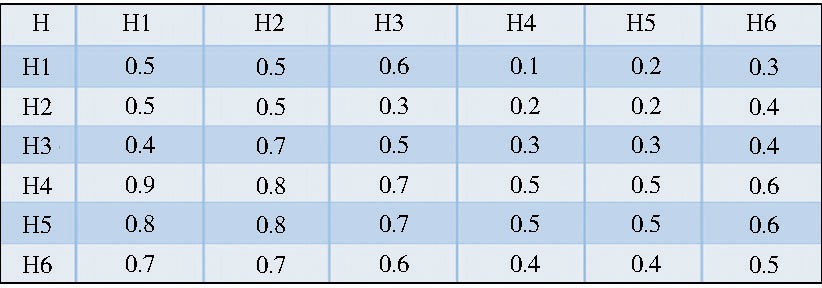 | 图5 优先关系矩阵 |
③层次单排序.
使用得到的模糊一致矩阵计算层次中各个指标因素的相对权重W=[W1, W2, W3, W4, W5, W6], 本算法中采用方根法进行计算, 调用Matlab进行编程, 如下所示:.
clear;
clc;
F=input (′请输入优先关系矩阵 F:′) ;
%计算模糊一致矩阵.
N=size (F) ;
r=sum (F′) ;
for i=1:N (1) .
for j=1:N (2) .
R (i, j) = (r (i) -r (j) ) / (2*N (1) ) +0.5;
end.
end.
for i=1:N (1) .
S (i) =R (i, 1) ;
for j=2:N (2) .
S (i) =S (i) *R (i, j) ;
end.
end.
S=S.^ (1/N (1) ) ;
W=S./sum (S) ; %采用方根法计算.
W %输出计算结果W.
运行Matlab程序后得到结果:W=[0.1436, 0.1408, 0.1549, 0.1944, 0.1916, 0.1747]。
④层次总排序.
由于获取数据指标时所依据的打分原则和数据计算方式不同, 导致每类指标的数值区间不同, 无法进行直接的加权排序, 所以需要对各个指标评分进行无量纲化处理。算法中采用均值化方法对指标进行无量纲化处理, 得到每条评论最终的各项指标相对评分结果Si。在此基础上, 得出各条评论效用大小的最终得分Ti=6i=1WiSi。
5 模型应用
5.1 数据收集
模型应用的研究数据来源于淘宝商城的某款相机的评论数据, 通过信息抓取获得大约2 000条有关该商品的评论信息, 主要包含5个字段的内容:评论原始排序、评论者信誉、评论内容、评论时间、评论得票数。
5.2 系统运行
按照模型研究设计的算法, 对获取的评论内容进行重新排序, 得到模型算法评分推荐排序。限于篇幅, 笔者选取淘宝商城原始推荐排序的前三条评论数据和模型算法评分推荐排序的前三条评论数据进行对比, 分别如表2和表3所示:
| 表2 淘宝商城原始推荐排序 |
| 表3 模型算法评分推荐排序 |
在结果中, 分别展示了淘宝推荐排序、模型评论排序、评论内容、评论时间和买家信誉5个字段。
5.3 结果分析
.
对经过模型排序后的评论与排序前的评论从两个方面进行对比分析。
(1) 评论的相关性评价.
评论的相关性评价主要考虑评论者的评论内容是否涉及到产品或服务的多个维度, 主要包括产品功能、质量、性价比、外观以及卖家服务态度和物流。
(2) 评论的体验性评价.
评论的体验性评价主要考虑评论者是否使用过产品或者服务后才进行的评价以及评论内容整体的可信度。
设计调查问卷将表2、表3以及表4通过互联网发送给网络购物用户, 回收有效问卷233份。
统计调研结果后, 对赞同度超过60%的对比项赋予“★”, 少于60%认可度对比项赋予“×”, 统计结果如表4所示:
| 表4 排序认可度对比 |
调查问卷的统计结果显示, 排序算法的认可度高达96.9%, 即有96.9%的用户认为, 经过排序算法排序后的评论内容对他们进行网络购物决策的参考价值更大。
6 结 语
本文基于模糊层次分析法设计了一个在线商品评论效用排序算法模型系统。通过建立评论效用指标体系, 对每条评论的各项指标进行量化评分, 得出同一在线商品的大量评论数据的效用得分, 将对消费者购物决策起到更大辅助作用的评论信息在靠前位置展现出来。
选取淘宝商城的某款商品的近2 000条评论信息进行模型应用研究。研究结果表明, 和原始评论排序相比, 经过模型排序后的评论内容在相同位置上所展现的信息更加丰富, 对消费者的辅助决策效用更高。为验证模型结果的有效性, 笔者通过网络调查的形式发放300份电子问卷, 有效回收233份问卷, 96.9%的消费者认为, 经过排序后的评论内容所展现的商品信息价值更高。
在研究过程中也发现, 优先关系矩阵、产品特征属性库和情感词汇库构建的好坏是影响模型稳定性的主要因素。其中, 优先关系矩阵的获取需要大量的统计数据, 并且随着统计数据的增加, 模型的稳定性也会相应增加, 这是模型存在的不足之处。对影响评论效用的指标组成研究也需要进一步的讨论, 而且可能存在对于不同类型的商品, 需要构建不同类型的指标体系的问题。同时, 评论的数量也可能影响模型的稳定性, 因为在模型中, 产品属性提取的丰富程度和评论的数量成正相关, 较少的评论内容是否会影响到模型的稳定性仍需要探讨。在后续的研究中, 笔者将对这些问题展开深入的研究, 以期望获得进一步的研究成果, 提升消费者的网络购物体验。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|