



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
健康信息资源公益性开发中异构数据整合方案的研究与应用*
引用本文
侯丽, 李姣. 健康信息资源公益性开发中异构数据整合方案的研究与应用* . 现代图书情报技术, 2013, 29(4): 83-89
Hou Li, Li Jiao. Heterogeneous Data Integration in Developing a Non-profit Health Information Resource. New Technology of Library and Information Service, 2013, 29(4): 83-89
Permissions
Hou Li, Li Jiao. Heterogeneous Data Integration in Developing a Non-profit Health Information Resource. New Technology of Library and Information Service, 2013, 29(4): 83-89
健康信息资源公益性开发中异构数据整合方案的研究与应用*
摘要
健康信息资源的公益性开发是当今公立医学图书馆数字化建设的重要组成部分。针对互联网环境下健康信息服务无法满足公众对健康信息需求的现状,提出对不同类型、不同结构的健康信息资源的全面整合方案,设计异构健康信息资源整合框架,并将其应用于公益性网络平台“中国公众健康网”的数据管理与发布。
关键词:
健康信息资源; 异构数据; 公益性资源; 整合框架
Heterogeneous Data Integration in Developing a Non-profit Health Information Resource
Abstract
The development of non-profit health information resources is an important mission of a public medical library. To facilitate the general public to access health information anywhere and anytime, this paper presents a heterogeneous data integration framework,which enables to integrate health information in different formats and from multiple sources, and disseminate the integrated information in a standardized schema via Internet. This integration framework is applied to “CHealth Online”, which is a non-profit health information Web site developed for public in China.
Keyword:
Health information resource; Heterogeneous data; Non-profit resource; Integration framework
1 引 言
健康信息资源的公益性开发是指围绕公众受益和社会效益的原则,以非营利性方式向公众提供与健康相关的科普信息服务[ 1],已成为当今公立医学图书馆数字化建设的重要组成部分,美国国立医学图书馆注重为公众、病患提供医学健康信息,通过其公益性健康信息网络服务平台MedlinePlus[ 2, 3],免费向美国公众提供健康信息。中国公众对健康信息的需求是迫切的,据第8次中国公民科学素养调查结果显示,我国公民最关注的科技信息是医学与健康,关注比例高达82.7%[ 4]。为使公众能够获取更加全面客观的健康信息,我国医药学领域的各个学协会在政府资助下,开展了大量健康信息资源的公益性开发。如:中华预防医学会整理发布了常见多发传染病的防治知识视频;中国药学会建立了安全用药常识知识库;中国医学科学院医学信息研究所开发了公益性健康知识服务平台,并自建了健康信息资源库。
经过研究发现,这些公益性网络服务平台的资源存在独立、分散、异构的特点,资源内容由异构数据组成,以
不同格式、不同存储方式分散在各个学协会和非营利性机构中,公众无法通过简单搜索一次获取全面的健康信息。如何实现不同来源、不同结构的公益性健康资源的整合,并提供一站式公益服务成为医学图书馆亟待解决的新课题。本文针对健康信息资源的异构特性,提出对互联网中公益机构开发建立的健康资源的整合方案,并基于此对部分健康信息资源的整合进行案例实现。
2 健康信息资源类型、结构及整合技术选择
2.1 健康信息资源类型界定
公众关心的健康信息资源主要是与公众身心健康密切相关的各种健康信息,诸如求医问药方面的信息、健康保健类的信息、就诊医院方面的信息等。可以根据健康信息资源的载体差异、呈现形式的多样性等从不同角度进行分类:
(1)按照信息的载体类型分为[ 5]:文字信息、图片信息、影像信息、视频短片、交互式展示等。
(2)按照信息的呈现内容分为:疾病、药物、症状、诊断检查、医院、医生、营养保健等信息[ 6]。对于不同内容的健康信息,其描述项目存在很大差异,例如:对于一种疾病,公众关心其病因、症状、诊断、治疗、预防等方面的信息;对于一种药物,公众关心其疗效、服用方法、服用剂量、产生的不良反应等。
(3)按照信息的存储方式分为:纸质存储、光盘存储、本地硬盘存储、网络服务器存储、数据库存储等。
(4)按照信息的发布方式分为:书籍出版、宣传册发放、社区展板、光盘传递、网络发布、电视媒体播放等。
2.2 公益性健康信息资源类型与结构分析
要集成发布公众所需求的全面、权威的健康信息资源,资源的采集与建设是首要环节,而适合公众阅读与理解的资源应该是科普性质的健康资源。这些资源应该涵盖医药学领域各学协会的科普资源、医学图书馆自建、整理的各种健康资源。笔者对医药学领域学协会产出的公益性健康资源进行收集与整理,主要梳理了学协会在十一五国家科技支撑计划课题中的产出成果[ 7],如表1所示。
这些公益性健康信息资源是由医药学领域各学协会持续建设与积累的成果,且经过专家论证,属于权威健康信息资源。通过对表1的梳理,发现这些健康资
| 表1 公益性健康信息资源一览表 |
源在数据库底层存储的结构存在较大差异,采用Oracle、SQL、MySQL等不同数据库技术进行存储管理,有的直接采用文本方式存储,有的资源还是纸质文件,需要进行数字化转化。因此该类健康信息资源具有如下异构特性:资源来源多样性;知识类型多样性;存储格式具有差异性;资源分散;资源自主性,分属不同机构,功能存在差异。这些异构特性体现为“技术异构”、“数据格式异构”和“语义异构”[ 8]。
健康信息资源结构上的特点使得对其进行一站式整合比较困难,需要探索一种能将不同类型、不同格式的健康资源进行统一描述与存储的技术方案,对异构资源统一标示、存储和管理,选取一种能提供异构资源统一描述的规范,且能够实现异构资源描述项目的可扩展及服务的可扩展。
2.3 异构健康信息资源整合技术选择
异构数据的整合技术研究已经比较成熟,如CrossRef的DOI技术,是对不同出版商出版的异构文章资源的整合,通过DOI实现统一查询[ 9, 10];基于OpenURL的SFX技术通过OpenURL语句实现从二次文献到全文,从全文到全文的链接[ 11, 12];还有基于Web Service技术的异构资源整合方案,通过基于XML、Web Service UDDI及SOAP等协议[ 13, 14],实现不同数据库提供商之间异构数据的整合;数字图书馆方面的资源整合也有采用XML技术,借助XML对图书馆的全文文献,实现全文检索系统[ 15],以上研究表明数字图书馆的整合重点在于对不同数据库商提供不同格式的数据库文献的整合,其对象以数据库商的各种全文文献为主。
在公益性健康资源的互联网发布与资源集成方面,美国国立医学图书馆开展了大量探索性研究。从PubMed生物医学文献摘要到PubMed Central的生物医学文献全文到PubMed Health临床信息的发布,真正实现了互联网上任意用户可以在世界上任何角落、任何时间访问图书馆的资源。这得益于美国国立医学图书馆基于XML技术所建立的期刊文章标签集 (Journal Article Tag Suite, JATS)[ 16]。JATS充分集成了XML的所有技术特性,提供一系列XML框架模型,对各类文本、图片设置了特有元素与属性。
面对公众关心健康信息资源的数据异构特点,综合分析互联网环境下的资源整合技术,考虑到XML的可扩展性、互操作性及开放性[ 17]、能对异构资源进行归一化揭示等特性[ 18],具有独立于操作系统和网络系统的、用来描述任意数据及数据显示与内容分开的技术优势,适合充当数据交换的中间语言。将Java 技术与XML相结合,构建异构数据库的集成系统,可使系统具备更强的可移植性及可扩展性[ 19]。此外,通过XML Schema和XML DTD能对文档中的句法限制进行揭示与表达,进而通过受控词表能加强类型不同但主题相同的资源之间的关联性[ 20]。因此XML技术是进行异构健康信息资源整合的最优选择,不仅能实现异构资源的统一揭示,还能加强异构资源中相同主题的关联,提升系统的语义关系,方便公众对知识服务平台中健康知识的全面检索与获取。
3 健康信息资源整合模式及描述规范设计
为了规范面向公众的健康知识的组织模式,并实现资源的整合,需要对健康信息资源的整合模式进行探讨,并制定一套通用于不同知识类型的XML描述规范,便于后续实现基于XML的公众健康知识整合,本文借鉴JATS[ 21]描述期刊论文内容方面的定义模式,对面向公众的健康信息资源整合进行描述规范设计,并以“中国公众健康网”[ 22]为实验平台进行XML规范设计与改造。
3.1 公益性健康信息资源整合模式
.
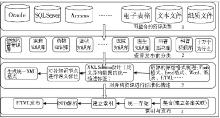
结合公众所需健康知识的类型、XML的技术优势以及采集到的资源,设计面向公众的健康信息资源整合模式,健康信息资源整合分为4步:
(1)对采集到的健康信息资源的存储结构进行梳理;
(2)根据不同资源内容设计待发布知识库分类;
(3)将所有资源进行数字化 (包括对纸质资源先进行数字化及OCR识别),对不同格式的资源进行特征分析,抽取其描述特征,设计能涵盖所有资源特征的XML Schema,手工对各个知识节点的主题进行语义标注,生成不同资源的XML文档;
(4)对资源进行发布,底层进行统一存储、建立索引,借助DTD、CSS进行HTML格式的发布。
其流程如图1所示:
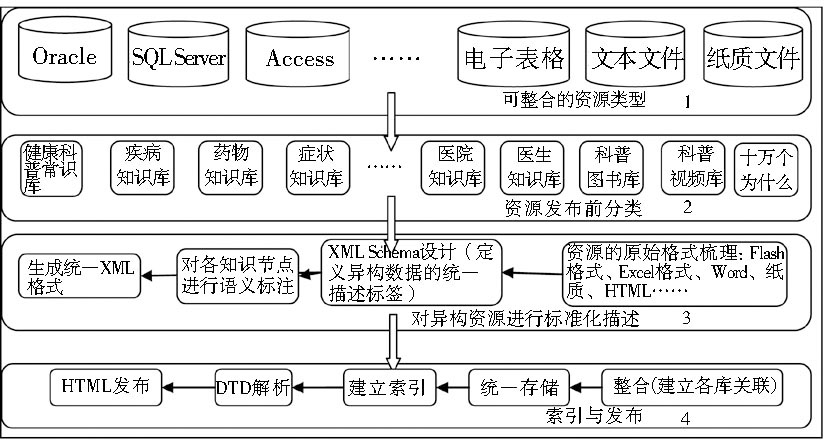 | 图1 面向公众的健康资源整合模型设计 |
3.2 公益性健康信息资源描述规范的元素定义
.
结合健康信息资源类型多样、各知识类型的描述属性差异大的特点,在设计XML描述规范时,将健康知识服务平台可能涉及到的元素分类如下:
(1)标识类元素:描述知识服务平台中知识内容的整体标签、每篇的知识名称、及各个知识库的各种标示。本文将整合的知识服务平台命名为:monograph。
①每一条疾病/药物/症状/……记录为:chapter,并为每一条疾病/药物/症状/……赋予唯一的ID号,同时还需包含别名属性,用<alt-title>标记。
②标记方式为:<book-part book-part-type="chapter" id="A00000*">。
③知识库的缩写形式定义为:cht。
④知识库的ID形式定义为:chtcid。
⑤知识库的完整标记方式为:<book-id chealth-id-type="chtcid">cht</book-id>。
(2)定义类元素:用于描述疾病、药物、检查各类知识库等特有的语义层面的属性,例如疾病病因、疾病预防、药物的副作用、检查的概述等信息。其标签表达形式为:<sec id="知识库缩写_知识条目编码.所属子知识库.各知识的元数据描述项">,如在描述疾病库中某一条疾病的症状时,规则是:<sec id="cht_000008.disease. symptom">,包含的元素为元素名称及其文本内容,表示为:<title>症状</title>及<p>文本内容</p>。
(3)关系类元素:描述不同知识库中可能涉及到的各种关系,如疾病-药物之间的被治疗与治疗的关系、疾病-疾病之间的并发关系、疾病-症状之间的表现关系等。文本中出现的关系类属性需要标记超链接,定义标签为:<related-object>,包含的属性为:相关概念的规范名称ID,相关概念ID,原概念ID及其链接号[ 23], 即:related-concept id,related-object id (相关疾病/药物/症状),document-id (该链接在此篇Document中的链接ID,标识方式为:id=chapter_link1/2/3/……根据相关概念在文中出现的先后顺序分别标示1、2、3……)三项。
(4)管理类元素:描述每篇记录的创建者信息、版权信息、编辑者信息等。
(5)附加类元素:以上未能包括的项目,如外部链接地址标记、图片信息标记,对于图片信息标记需要标记该图片反映的人体部位及编码、图片的名称、图片的标注信息、图片的外部链接地址、图片更新日期、图片编辑者等元素。
(6)分隔符标签:各部分的分隔符为<sec>……</sec >,段落间标签为<p>……</p>。
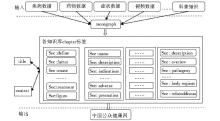
用树形结构来表示本文设计的XML结构,如图2所示:
 | 图2 面向公众健康知识整合的XML树形结构 |
本文制定的XML Schema规范没有单独对不同的知识描述内容设立不同的描述项,整个框架的顶层标签为“monograph”,二级标签则是知识库类型,用“chapter”标记,通过“chapter id”判断其归属于哪个知识库,三级标签是具体知识条目的分内容,皆用“sec”标签进行定义,通过 “sec id”定义该部分所属元数据项属性,即无论是来自于疾病库的知识内容、药物库的知识内容、健康养生库的知识内容还是其他知识库的内容,都可以在“sec”下自行扩展其标签。四级标签则是对sec下具体内容进行描述,通过“title”标签和“context”标签对各属性内容值进行揭示。通过这样的XML Schema设计,能实现异构健康知识资源、不同健康知识类型元数据项的统一揭示与管理。
4 基于XML的健康信息资源整合案例实现
根据本文的设计思路,笔者以“中国公众健康网 (CHealth)”作为实验技术平台,将中国公众健康网中自建的1 100条疾病数据、560条药物数据、中华预防医学会官网的300条疾病预防科普知识、中华医学会官网的200条慢病防治知识、中华预防医学会编著的《全民健康十万个为什么》,全部进行XML格式的统一转化与存储。以疾病知识为例,笔者设计了48个元素,18个属性,通过这些XML的元素与属性可以对中国公众健康网已有健康资源及新整合的健康信息进行统一揭示与整合,且方便与其他外部平台进行数据交互与共享。
以疾病“高血压”为例,结合上述的XML描述规范对“高血压”的描述内容进行资源整合,将各类属性数据归并为:每篇文章的版权信息、知识库宏观层面的元数据信息、正文数据的元数据信息和外部链接信息。并以“高血压”为例,将其XML文档的数据结构进行展示。最后借助CSS对知识内容进行XML转化后的疾病实现了HTML的页面展示。
4.1 疾病知识的版权信息XML实现
该部分文档揭示知识服务平台中每一条记录的版权信息及创建者信息等管理类元素的基本信息,标签为:<book-meta>,其中版权信息包含如下元素:属于哪个知识库的标签,标签为<book-meta>、整个专著的相关ID,采用标签<book-meta>、出版机构、出版时间、版权机构信息及创建者信息。审核者信息的元素包括:疾病的编撰者、编辑时间、审核时间、审核者等相关信息,分别采用:<author-notes>、<date date-type>等标签。
4.2 知识库宏观层面的元数据XML实现
.
主要揭示疾病元数据开始的标签、疾病名称等标示类元素信息。
(1)疾病元数据开始的标签.
该部分文档主要描述该篇文章揭示的知识内容所属类型及分组,包括:所属知识库名称 (疾病/药物/症状/其他),采用<subject>…</subject>标签,疾病/药物/症状/其他所属系统,采用<sub-group>…</sub-group>标签,如高血压可标示其所属的多个系统:心内科、心外科等)。疾病头信息的XML文档结构示例如图3所示:
 | 图3 疾病头信息的XML文档结构示例 |
(2)疾病名称的标签.
标记该条数据的基本信息,包括疾病所属类型、疾病名、疾病别名信息。且疾病别名需要单独一一标示出来,标签分别为:<subtitle content type>、<name content >、<alt-title>等。
(3)此篇文章的链接标签.
标记该条数据的链接信息。链接地址需要标示出该文章的上级目录 (所属的专著类型)disease、祖父节点目录monograph,采用的标签为<link-group>。
4.3 正文数据的XML案例实现
.
文章正文包括疾病各项具体的元数据描述内容,如病因、治疗、诊断、预后等定义类元素项目,还包括可能产生关联的各种关系类元素信息。
通常以body标签开始,以body结束。多段之间标示出分隔符,并标记出项目符号标签,不同部分元数据用sec标示区分开来。
(1)定义类元素数据.
描述疾病概况的文本内容,包括定义类元素的名称 (标签为<title>)、定义类元素的具体内容 (标签为<p>),若有多段则用项目符号进行分段处理,采用<list-item>标签。
(2)关联类元素数据.
疾病可能在治疗药物、并发症、呈现的症状、可就诊的医院等方面发生关联关系,通过<related-object>标签揭示疾病与其关联项目的链接,其属性值包括“source-id”、“concept-id”、“document-id”等。疾病与其症状之间关联关系的XML文档示例如图4所示:
 | 图4 关联项目之“疾病与症状”的 |
XML文档结构示例.
通过图4所示的标签定义及文档结构形式,在网页呈现的疾病症状文本中,能动态对各个标记出来的related-object id对应的症状库中的症状进行超链接。同理,凡是在疾病文本中和其他知识库的资源存在关联关系的项目,都可以这种方式进行一站式的呈现,方便公众在浏览某一个具体健康知识时,获取其他相关知识的详尽内容。
4.4 相关链接数据的案例实现
.
该部分主要揭示与该疾病相关的外部资源的各种链接,如来自于其他网站与该疾病相关的内容,可以是外部的网页资源,也可以是讲述同一主题的期刊文献资源等,采用<ext-link>标签进行描述。来自于其他健康网站的相关信息如图5所示:
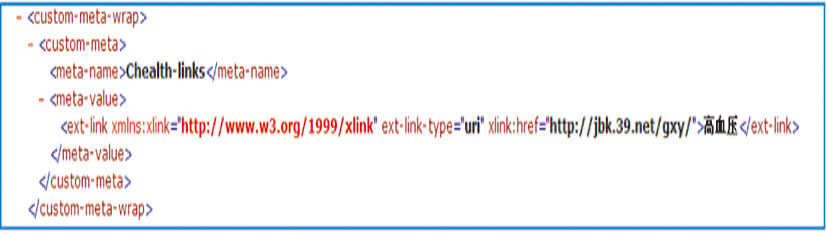 | 图5 外部链接的XML文档结构示例 |
5 结 语
本文针对公众对健康信息资源需求迫切、公益性健康信息资源分散、公众获取健康知识不便捷、医学图书馆提供公益性健康资源整合服务薄弱等问题,对公益性健康信息资源的开发与异构资源整合进行技术探讨。重点梳理了健康信息资源的类型划分、拟整合的健康信息资源来源特征、异构资源的整合技术,并对健康信息资源的整合方案进行设计与实现,使得异构资源能够通过一个统一的文档形式进行存储、呈现与交互,而且提升了健康信息资源在不同平台间进行移植的通用性。
借助XML技术不仅能更好地对异构数据库存储的知识资源进行统一描述,更能对异构数据进行集中揭示。与此同时,由于其XLink的超链接技术,使得超文本中的导航设施更加完善,导航工具更加丰富,便于同一知识点的各类相关知识能够在一个页面进行多项超链接的导航,增加健康信息的可获取性与便捷性,能更加方便公众对健康信息的快捷定位,减少公众在浏览健康信息时的迷航现象。此外,通过笔者的整合设计及案例实现,为公立医学图书馆在拓展公益性知识服务方面进行新的尝试,使医学图书馆在公益性健康信息服务上,能更加便利地整合不同类型、不同来源的健康资源,并实现数据交互与共享,使得不同类型的健康知识不再是孤立的信息孤岛,而是一个联动的健康知识海洋,进而发挥医学图书馆在普及公众健康教育、提升健康素养方面的重要作用。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|