



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
数字图书馆中层关联数据的创建与发布*
[王忠义 , 夏立新
, 夏立新
, 夏立新|
|


为实现数字图书馆馆藏资源目录数据(中粒度)的中层关联数据的创建与发布,在对现有关联数据创建与发布方法进行研究的基础上,针对目录数据自身的特点,采用自动标引、主题词映射等技术实现目录数据的结构化,借助目录体系与文本匹配实现关联数据的关联发现,借助D2R最终实现中层关联数据的创建与发布。
In order to create and publish middle linked data of catalog data on the digital library resources, this paper, based on researches on the current creation and publishing methods, firstly structuralizes catalog data using technologies of automatic indexing and subject headings mapping, then mines relationships by analyzing catalog system and using the text mapping technology, at last, achieves the purpose of the creation and publishing of Middle Linked Data of digital libraries’ resources by D2R.
随着网络技术的发展,网络已成为人们快速获取知识的重要媒介,为人们提供了知识获取的多种途径,如维基百科、百度百科、百度知道等。相对这些常用的网络知识资源,数字图书馆作为人类知识的宝库,虽然存储的知识更可靠权威,更能满足人们对专业知识的需求,但却没能得到网络用户的普遍使用[ 1]。通过分析发现其原因主要有:
(1)查询结果的集成度不高,虽然语义数字图书馆以机器可读可理解的 RDF(Resource Description Framework) 语言为介质,提供具有语义功能的浏览和检索服务[2],在一定程度上提高了检准率,但是文献信息资源之间并没有建立关系,文献信息资源还是以孤立的形式存在;
(2)服务粒度过大,数字图书馆提供知识服务时,通常以一篇文章、一本书等为单元,用户若要获取所需的知识,还需对文章、书等进一步阅读才能定位到所需知识的位置,大大增加了用户的认知负担和时间成本。
关联数据(Linked Data)[ 3]作为一种形式化的知识组织和发布方式,它的提出为解决上述问题提供了方向。当前,图书馆关联数据的研究和应用已取得了大量的研究成果[ 4, 5, 6, 7, 8, 9, 10],然而通过对这些研究成果的分析发现,数字图书馆关联数据的研究和应用主要集中在书目数据、规范数据(如主题词、规范人名)、标准(如MARC、DDC)等领域(本文称其为浅层关联数据),而有关更加细粒度的关联数据应用较少,严重限制了关联数据在数字图书馆中的高级应用和发展。因此,本文在当前研究的基础上,探索数字图书馆馆藏资源目录数据的关联数据创建问题,即中层关联数据的创建,使得图书馆关联数据的创建向着更加细粒度的方向深入,以便向用户提供语义关联检索,更好地满足数字图书馆用户的需求,提高数字图书馆的利用率。
互联网之父Berners-Lee[ 3]于2006年7月首次提出关联数据的概念,从技术框架上来说,关联数据可以被看作是一组最佳实践的集合,其目的是将网络中的众多资源与关系联系起来。Berners-Lee在提出关联数据的设想时,同时指出人们在创建和发布关联数据时需要遵循的4个基本原则:
(1)使用URI(Uniform Resource Identifier)作为事物的名称;
(2)所有事物的URI都应是HTTP URI,以便人们访问这些事物;
(3)通过查询URI可以获得有用的信息;
(4)尽可能提供其他URI的链接,以便发现更多的事物。
在具体实现过程中,原则(3)可以被具体化为提供资源的RDF描述,原则(4)中的关联URI则通过RDF Link来体现[ 11]。由此可见,关联数据实际是以RDF为数据模型,以URI为实体标识,借助HTTP协议访问获取的一种数据网络,该网络不仅人可以阅读,而且机器也可以理解,是语义网的一种实现方式。
数字图书馆存储的数字资源包括多个粒度层次,如有关数字资源的书目数据,多是以一本书或一篇文章为单位来描述信息资源的相关信息,粒度较大;目录数据通常是对一本书或一篇文章中的章节信息资源的描述,粒度相对书目数据来说比较小;而一本书或一篇文章的章节内部所包含的各个知识点则是最细粒度的信息资源。即数字图书馆的数字资源大体上可以划分为三个粒度层次:粗粒度、中粒度和细粒度。针对数字图书馆存储的信息资源具有不同粒度层次的特点,本文将有关粗粒度的书目数据的关联数据称为浅层关联数据,有关中粒度的目录数据的关联数据称为中层关联数据,而有关细粒度的文献内容数据的关联数据称为深层关联数据。
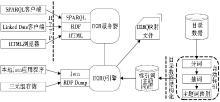
根据中粒度的目录信息资源的特点,遵循关联数据4个基本原则的要求,本文设计了中层关联数据创建与发布方法的流程,如图1所示:
 | 图1 中层关联数据创建与发布流程 |
该方法是基于D2R这一关联数据创建和发布工具实现的。从图1可以看出,数字图书馆中层关联数据创建与发布方法流程大致可分为4个步骤:目录数据的结构化、结构化数据的RDF化、RDF数据的关联化和关联数据的发布与查询。
目录数据结构化的作用主要是将非结构化的目录数据转化为结构化的数据。具体来说,主要是提取用于标识目录所包含内容的主题词,在提取这些主题词的过程中本文采用自动标引的方式,通过使用自动分词、自动抽词和主题词映射等方法达到目录数据结构化的目的。其中,需要指出的是主题词映射的目的是为了确保相同的数据对象都具有唯一的标识符,从而使得数据集都使用相同的资源描述规范进行描述,即都采用相同的模式(Schema),这将有利于自动建立数据对象之间的关联关系。
它的主要作用是实现目录数据描述的计算机可理解,即创建目录数据的RDF三元组,该环节是实现目录数据的关联数据创建的基础,具体包括两个步骤:为每个标识目录数据对象的主题词分配HTTP URI;为每个标识目录数据对象的主题词添加属性与属性值。
它的主要作用是建立目录数据的RDF三元组之间的关联,该环节是实现目录数据的关联数据创建的关键,通过该步骤可以最终实现目录数据的语义描述,达到跨数据集知识发现的目的。RDF数据的关联化主要是借助目录数据本身的属分关系以及各主题之间的sameAs关系来实现。
它的主要作用是使得目录数据达到网上可访问和可检索查询的目的。该环节是实现基于关联数据的服务的关键。本文采用基于关系型数据库的方法来实现有关目录数据的关联数据的发布与开放查询的功能,具体来说,主要是利用D2R这一关联数据发布与查询工具将存储在关系型数据库中的关系型数据直接发布为关联数据,并提供一个SPARQL查询接口,实现对有关目录数据的关联数据的检索。
从中层关联数据创建与发布方法的基本流程可以看出,其大体上遵循了一般关联数据创建与发布的基本思路,然而,由于常用的一般关联数据创建与发布方法大都是针对结构化数据的,而目录数据属于非结构化数据,因此如果要借助这些常用的一般关联数据创建方法对目录数据进行中层关联数据的创建与发布,关键在于解决目录数据的自动标引和关联关系的挖掘,前者是实现目录数据结构化的基础,后者是实现目录数据的RDF三元组关联化的前提。
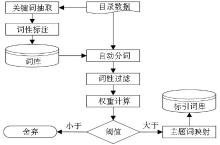
目录数据自动标引主要包括关键词抽取、词性标注、自动分词、词性过滤、权重计算、主题词映射几个功能模块,如图2所示:
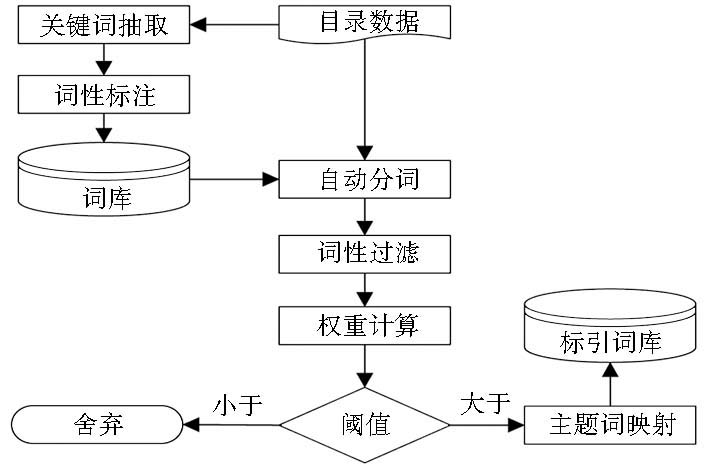 | 图2 目录数据自动标引 |
(1)关键词抽取:为依据词性选择标引词,本文在对目录数据进行分词时,选用了中国科学院计算技术研究所中文分词系统ICTCLAS,该分词系统采用的是基于词库的分词,因此词库在分词的准确率上起着至关重要的作用。由于数字图书馆中的数字资源涉及到许多专业词汇,尚未被词库收录,严重影响了ICTCLAS分词的准确性。然而,通过分析发现大部分专有词汇都在文献的关键词中出现,因此本文抽取了文献中的所有关键词,经过去重后,构建了一个专业词汇库作为分词词库的补充。
(2)词性标注:ICTCLAS分词系统的词库包括单词和词性两个部分。构建专业词汇库后,还需对专业词汇的词性进行标注。在本系统使用的ICTCLAS版本中,词库的格式为“单词 词性”,即单词和词性是用空格分隔,例如“华中师范大学 nt ”。ICTCLAS 官方网站(http://www.ictclas.org)提供了《计算所汉语词性标记集》,本文按照该词性标记规范,对专业词汇库的词性进行了标注。
(3)自动分词:采用正向最大匹配算法对目录数据的标题进行分词,这是因为对于中文来说长的词往往反映比较具体、下位的概念, 而短的词通常表示相对抽象、上位的概念,例如“计算机”、 “电子计算机”、 “数字电子计算机”三个词专指性依次增强,而概括性依次减弱。因此在对目录数据的主题词进行抽取时,选择词长较长的词更为科学[ 12]。
(4)词性过滤:根据对标题的分词结果,抽取其中的动词和名词。从语言学来看,动词、名词可以对主题起到更好的表达作用[ 13]。
(5)权重计算:在抽取主题词过程中,词频、词长都是决定是否适合作为主题词的关键因素之一,本文借助TFIDF的取词思想,融合词长在选词中的意义,提出主题词权重计算方法如下所示:
W(wi)=f(wi)1/2×log(c/ti)×(ni/mj) (1)
其中,W(wi)表示第i个词的权重,f(wi)表示主题词wi在其所在小节出现的频次,c表示文档中所有与关键词wi所在小节的等级相同的小节的个数,ti表示出现wi的同级小节数,mj表示第j个小节的标题分词后,所有词包含字的个数总和,ni表示第i个词包含的字的个数。
(6)主题词映射:主要是将抽取的标引用词与主题词表进行映射,使得相同的实体都使用统一的主题词进行标引。该主题词表由《中国分类主题词表》和自建主题词表构成,其中自建主题词表主要是从文档题名、目录、摘要和关键词中抽取的新词,作为《中国分类主题词表》的补充。
本文在实现目录数据的RDF三元组的关联化时,关联信息的获取主要有两个来源:目录体系的层级关系和实体之间的等同关系。根据关联信息上述两个来源,主要采用以下两种关联关系挖掘策略。
(1)基于目录体系的RDF三元组之间的关联挖掘
目录数据的层级体系结构是作者依据知识之间的内在联系对各知识点进行的有机组织。即目录数据的层级体系结构本身揭示了知识内容的某种逻辑关系,如各数据对象之间的各种属分关系、并列关系等。因此,从目录数据的层级体系结构中可以挖掘出有关目录数据的RDF三元组之间的多种关联关系。
(2)基于文本匹配的RDF三元组之间的关联挖掘
这种关联挖掘主要是用来获取三元组之间的等同关系(即sameAs关系),基本思路是:在种子数据集合S1中取某一实体的名称,以该实体的名称为键值在数据集S2中匹配查找是否具有相同名称的实体对象,如果有,则说明两个实体对象之间存在sameAs关系。例如三元组<关联数据,创建方法,“×××”>与三元组<关联数据,发布方法,“***”>通过实体名称匹配发现具有相同的名称,便可以建立两个三元组之间的sameAs关系映射。由于本文在目录数据结构化的过程中进行了主题词映射,在一定程度上保证了相同的实体都使用统一的实体名称加以描述,从而大大提高了基于文本匹配的RDF三元组之间的关联挖掘的准确性和效率。
本文选择数字图书馆数字期刊论文作为实验的数据源,主要是基于以下两个方面的考虑:数字图书馆的数字馆藏资源包含电子图书、期刊、硕博论文等,其中期刊论文是数字馆藏资源的一个重要组成部分;期刊论文作为知识承载的单位,具有明显的篇、章、节、段、句的层级结构,换言之,这类数字资源的知识组织具有多粒度多层次的特点,因此具有一定的代表性。此外,为使得创建的中层关联数据具有更多的关联关系,在具体实验过程中只选择某一主题领域的期刊论文,具体来说,主要是以有关“关联数据”的期刊论文作为实验对象。本文在中国期刊网中,采用“关联数据”作为检索词进行检索,根据相关度选择了100篇文献,并下载PDF格式的全文。
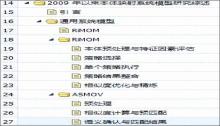
在文献目录体系结构抽取中,借助PDFBox的开源Jar包,采用抽取算法充分分析了文献在PDF中的存储结构、文献中信息出现的顺序、文字的大小、文字的位置和间距等特点,并以树作为数据结构表示文献目录体系的层次结构,最终将它们存储到关系数据库中,自动抽取的文献目录体系结构如图3所示:
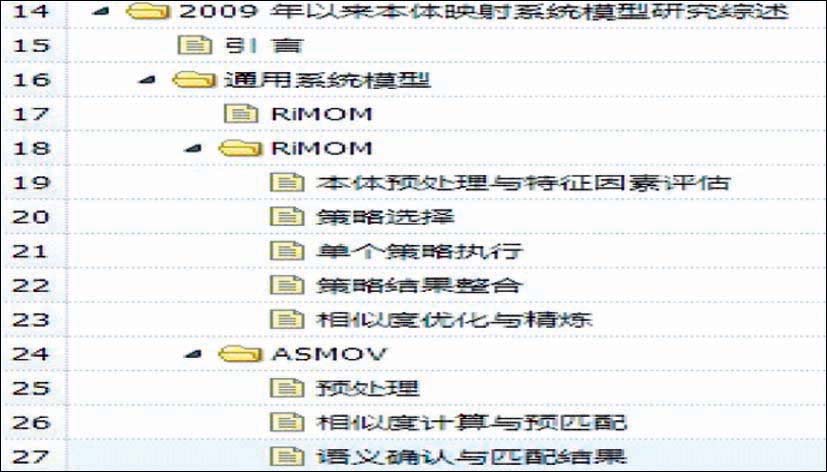 | 图3 文献目录体系结构 |
采用自动标引和主题词映射方法与技术,自动从目录数据中提取标识某一目录下所包含的知识内容的主题词,抽取主题词过程中反馈的主题词列表如图4所示,左侧为目录体系,右侧为抽取的用来标识目录所包含内容的主题词。
 | 图4 抽取的主题词列表 |
根据D2R-server的启动命令参数,设置端口号和映射文件,即可启动D2R-server服务,发布关联数据,提供用户访问。
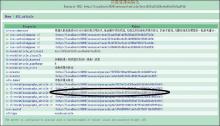
基于D2R-server发布关联数据是以其映射文件为基础的。映射文件用于描述关系数据库中表与表之间的关系,通过该映射关系,D2RQ引擎可以自动生成SQL查询数据。本文采用D2R提供的映射文件自动生成工具Generate-mapping连接创建的MySQL数据库,生成映射文件。由于Generate-mapping工具生成的映射文件,其表与表之间的关系是基于外键生成的,外键并不能完全满足所有关系需求,于是为了保证发布的关联数据更准确,本文根据D2R-server映射语言的语法规则,对映射文件进行了相应调整,如图5所示:
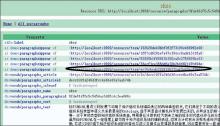
 | 图6 文献集列表 |
 | 图7 浅层(文献)关联数据 |
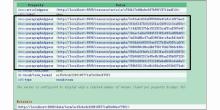
 | 图8 中层(目录)关联数据 |
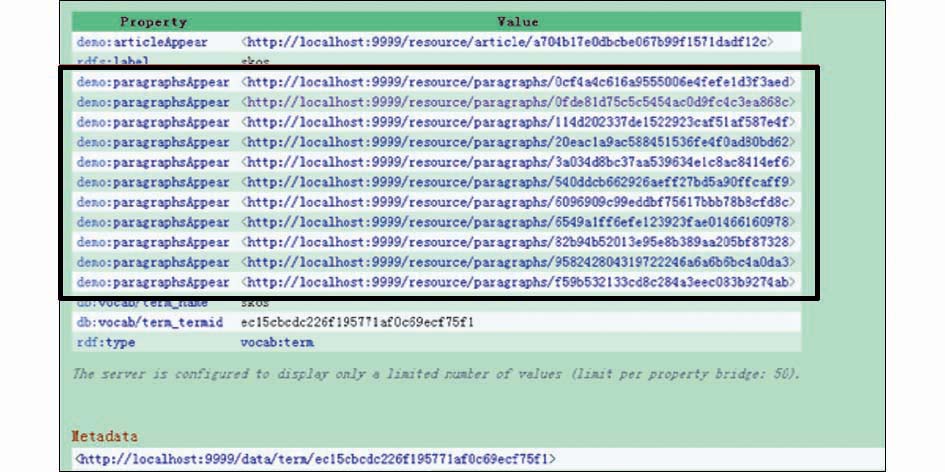 | 图9 基于主题词的中层关联数据聚合 |
在启动D2R-server服务后,用户便可以访问文献集合的列表,如图6所示。任意点击一篇文献题名(如点击图6中用椭圆标识的题名)后,可以浏览文献浅层关联数据,如图7所示。点击详细信息中的小节(如点击图7中用椭圆标识的小节),即可浏览有关该小节的中层关联数据信息,如图8所示。此外,点击标识该小节的主题词链接(如图8中用椭圆标识处),便可以获得所有以该词为主题词的小节,如图9中矩形部分所示,向人们展示了与主题词SKOS相关联的所有中层关联数据。
为了使数字图书馆关联数据的创建和发布向着更加细粒度的方向发展,满足用户对数字馆藏资源不同粒度层次的需求,本文在数字图书馆关联数据现有研究成果的基础上,对中粒度目录数据的关联数据的创建和发布问题进行了探索和研究。具体来说,针对目录数据的特点,采用自动标引、主题词映射等技术实现目录数据的结构化;借助目录体系与文本匹配实现关联数据的关联发现;借助D2R最终实现中层关联数据创建与发布。此外,为检验方法的可行性,以期刊论文作为数据源,对中层关联数据的创建与发布进行了实证研究,在一定程度上印证了方法的科学性。本文仅对中粒度的目录数据的关联数据的创建和发布进行了探索,尚未深入到更加细粒度的文献内容本身的深层关联数据的创建与发布问题,未来将在此基础上,进一步对细粒度的文献内容本身的关联数据的创建与发布问题进行研究,以满足人们对更加细粒度的知识的需求。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|