



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
多因素影响的特征选择方法*
[路永和 , 李焰锋
, 李焰锋
, 李焰锋|
|


在特征选择过程中,通过特征选择评估函数得到的词的权值大小决定该词是否作为特征词,然而词的权值受多种因素影响,主要因素有词的重要性、特征性和代表性。从以上几个因素出发,构建新的特征选择函数TW,通过对词的卡方分布CHI、信息增益IG和新的特征选择函数TW做对比实验,验证TW能够提高类别中专有词汇的权值,降低常见但对分类不重要的特征的权值;将TW作为新的特征选择算法,通过在中文分类语料库中分别采用KNN、类中心和支持向量机(SVM)三种分类方法进行实际分类实验,并与其他特征选择算法进行比较,验证该特征选择算法的有效性。
In the process of feature selection, term’s weight determines whether the term can be a feature. But the weight is affected by many factors, the main factors are term’s importance, characteristics and representative. With the consideration of those factors, a new function TW (Term Weight) based on the importance of the feature and the ability of category distinguishing, is brought to be an improved method to select features. After that, experiments on the comparison between term’s CHI, IG and TW validate that TW can increase the weight of special features in a class and can decrease the weight of unimportant features. Finally, the validity of the new algorithm in feature selection is proved by the classification experiments on Chinese classification corpus by three classifiers.
Web信息的快速增长使得寻找所需要信息的难度加大,文本分类作为处理大量文本数据的关键技术,可以在一定程度上解决信息快速增长带来的一些问题。向量空间模型VSM(Vector Space Model)是目前文本分类中最常用的文本表示方法之一。VSM 的基本思想是用词袋法表示文本,将每个特征词作为向量空间坐标系的一维,文本被形式化为多维向量空间中的一个向量,文本之间的相似度用两个向量间的夹角衡量[ 1]。即VSM模型把对文本内容的处理简化为向量空间中的向量运算, 并且它以空间上的相似度来表达语义的相似度。 当文档被表示为文档空间的向量时,就可以通过计算向量之间的相似性来度量文档间的相似性。
而采用VSM模型进行分类的最关键环节是特征选择。好的特征选择算法不但能降低向量空间维数、简化计算,还能去除噪声,从而提高文本分类的准确率和分类速度。
通常原始特征空间维数非常高,且存在大量冗余的特征,为避免特征维数过高影响系统速度和分类效果,通常会对其进行降维处理。降维处理的根本任务是在尽可能保持其信息完整性的同时对无用的信息进行删减过滤,目前降维技术主要有特征选择和特征重构。特征选择常用的算法有文档频率(Document Frequency, DF)、卡方统计(CHI)、信息增益[ 2](Information Gain, IG)和互信息(Mutual Information, MI)等。
对文本原始特征进行特征选择的通用方法是卡方统计(CHI)和信息增益(IG)。在一定程度上,这两个方法能较有效地筛选出对分类比较有效的特征词[ 3],但方法本身存在不足[ 3, 4, 5],而且在中文文本分类实验中的表现不突出,需要对其进行修正才能适合中文文本分类[ 6]。因此,有部分学者对传统的特征选择方法进行改进,在实验中也得到较好的效果。如熊忠阳等[ 7]分析了卡方统计的不足并提出将频度、集中度、分散度应用到卡方统计方法中,以此来改进卡方统计;在互信息基础上,王卫玲等[ 8]提出一种既考虑特征与类别之间的关联性,也考虑特征之间关联性的特征选择算法,以此来选出区分能力强、弱相关的特征。除此之外,有学者还提出基于其他领域知识的一些改进算法,如Shankar等[ 9]引入经济学中的基尼指数,并研究了基尼指数进行加权特征选择问题;Lu等[ 10]通过对词的语义进行统计来筛选特征;Khan等[ 11]则引入本体论来提取概念术语,从而实现特征选择,通过实验验证比TF-IDF效果更好。
国内也有学者将向量权重算法TF-IDF(Term Frequency-Inverse Document Frequency)应用到特征选择中,但直接应用的效果不是很明显,多半会进行改进以使TF-IDF适应特征选择。直接将TF-IDF应用到特征选择效果不好的原因是如果一个词在某个类频繁出现,而在其他类中却极少出现,这样的词应该具有更高权重,然而根据IDF定义的描述,这样的词却极有可能被赋予较低的权重。此后,不断有学者对如何将TF-IDF运用到特征选择过程中进行了研究。不少学者将TF-IDF与传统的特征选择算法结合起来作为新的特征选择算法,并且也取得了不错的效果,如刘海峰等[ 12]将互信息与改进的TF-IDF结合起来作为一种新的特征选择算法,提高特征项利用效率。
以上方法普遍存在以下一个或几个问题:
(1)构造或改进的函数中需要更多的统计量;
(2)计算方式复杂,如方差计算等;
(3)仅考虑词的类内类间分布,未考虑词在文本集和文本中的重要性;
(4)未考虑词与类别间的关联性。
因此,本文从词在文本集和文本中的重要性、类内的代表性和类间的特征性出发,在不增加更多统计量的基础上,使用较精简的函数来描述词的特征重要性,从而使其更容易在实际中得到应用。
改进的核心思想是:每个词对每个类的区分能力是不同的,其重要性用传统的特征选择评估函数与向量权重计算方法TF-IDF共同反映,同时该词集中分布的类就是其所属的类,即这个特征词要具有这个类的特征性。事实上,某词所属的类存在两种情况:该词集中出现在所属类的少数几篇文档中;该词均匀出现在所属类的所有文档中。在特征选择的实际过程中,本文的处理方法是:同等条件下,第二种情况下词的权重比第一种情况下词的权重更大一些。
对于特定词t,它具有的区分类别的能力不同,并且这种能力最终会影响分类效果,将这种能力的大小定义为特征权重(Term Weight, TW)。TW的大小受多种因素影响,主要包括以下几个方面[ 1]:
(1)词的重要性[ 13]。尽管传统的特征选择评估函数不能完全描述词的重要性,但总体上还是可以体现词的重要性,同时将向量权重计算方法也作为衡量词重要性的一个因素。若存在一个词,该词的特征选择评估函数值和通过向量权重算法计算得出的权值越大,说明在一定程度上该词越具有重要性,对分类的影响越大。
(2)词的特征性。若存在一个词,该词越集中出现在某个类别文档集中,而在其他类别的文档集中越少出现,那么该词越能区分其所在类别集与文本集合中的其他类别集,即该词具有其集中出现的类别集的特征越明显,对分类贡献越大。
(3)词的代表性。若存在一个词,该词越均匀地出现在某个特定类别文档集中,即该词能覆盖该类别集中的文档数越多,那么该词越能代表其所在的类别集,即该词越能代表其均匀出现的类别集,对分类贡献也越大。
TF-IDF方法因为考虑到了特征词词频等因素,在一定程度上能有效地表示出一个词在文档中和语料库文档集合中的重要程度。另外卡方值CHI和信息增益IG是常用的特征选择评估函数,故词的重要性采用其中的卡方值CHI和TF-IDF来共同衡量。由于CHI不能完全反映词的重要性,为避免权重失衡,需对其值进行对数化处理。
理论上,不包含词t但属于某个类别的文档越少,即包含词t同时属于该类别的文档越多,并且词t能在该类别中均匀分布,则说明词t在该类的代表性越强。本文用C来反映词的代表性,其含义为不包含该词但属于该类的文档数。同样,包含词t但不属于该类的文档越少,即词跟该类的关系较大,说明词t在类别间的分布基本集中在该类或该类文档都不包含该词。本文用B来反映词的特征性,其含义为包含该词但不属于该类的文档数。
词的卡方值CHI和TF-IDF越大,同时C和B越小,说明类内分布越均匀,类间分布越集中,那么该词的特征权重就越大,越有机会被选为分类特征。因此,本文定义特征权重公式为: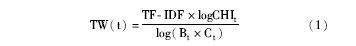
其中,t为词,CHIt为该词的CHI值,Bt为包含t但不属于该类的文本数,Ct为不包含t但属于该类的文本数,TF-IDF为词t的经过对数处理TF后的TF-IDF值。
对于某些词,其Bt×Ct值可能为0或Bt×Ct值可能为1,该值为0或1的意义是该词只出现在某个类中,很少出现在其他类中,它可能是这个类的专有词汇,理论上,这种词的类区分能力是相对较强的,但在实际分类中,Bt×Ct为0,也可能是由于分词效果差和语料库不规范导致的。考虑到分词效果和语料库规范问题较难预测和避免,同时也为了解决特殊点的问题,加入λ使函数在整数的定义域内取值都有意义。而且通过训练λ的取值,还可以减少语料库和分词效果带来的影响。因此,将公式调整为:
其中,λ为相对于Bt×Ct很小的常数(在实验中发现取λ=e-7时分类效果比较好)。
综上所述,改进的特征选择算法为:

其中,tfik表示文档i中第k个词的词频,N表示文本集的文档数,nk表示文本集中出现该词的文本数。
为验证TW对表达词权重大小的有效性,实验将TW与CHI、IG进行对比分析;同时为证明采用TW算法进行特征选择的优越性,实验将其分类效果与现有的三种比较典型算法进行比较,包括DF、CHI和IG。
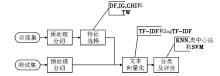
实验数据集采用复旦大学李荣陆博士提供的中文文本分类语料库[ 14],选取其中的9个类别,分别是体育、艺术、历史、航空、计算机、环境、农业、经济、政治,每个类别200篇,按1:1比例选择训练文本集和测试文本集,即训练文本集和测试文本集各900篇。实验采用的编程语言是Java,IDE环境是Eclipse,采用中国科学院计算技术研究所的中文分词进行预处理,实验流程如图1所示:
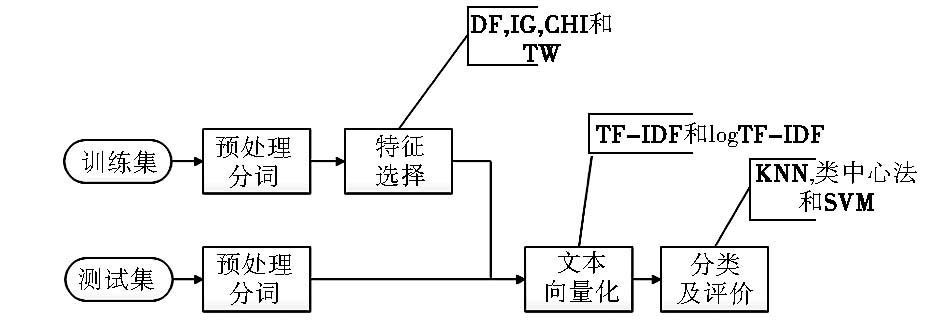 | 图1 文本分类实验流程 |
选取的特征数量有300、600、900、…、3 000。在进行特征选择时分别采用DF、IG、CHI和TW方法来对比。向量权重计算方法采用TF-IDF和对数处理TF的TF-IDF算法。分类算法采用KNN分类法、类中心分类法[ 15]和支持向量机(SVM)分类法,其中KNN中k统一取10。
分类结果评价标准[ 16]采用宏平均查全率(Macro-averaging Recall, MR)、宏平均查准率(Macro-averaging Precision, MP)和宏平均F测度值(Macro-averaging F-measure, MF)等常用标准。
(1)特征权重修正的有效性分析
通过实验发现,TW能提高专有词的权重,同时也能降低常见词的权重。例如“裁判”集中出现在体育类中,其分布不会很分散,即“裁判”这个词可以区分体育这个类别;而“学生”并不会集中出现在某个类,其分布要比“裁判”的分布分散得多,因此,“裁判”的类区分能力比“学生”高,即“裁判”的权重会比“学生”高。实际TW也反映了这一情况,如表1所示:
| 表1 “裁判”与“学生”的对比 |
当选取特征词数量为30时,TW、IG和CHI对应的选择结果如表2所示:
| 表2 特征数量为30时各选择函数的特征词对比 |
表2中只有27个特征词是因为选取时为避免特征词在每个类的分布不均衡,采取每个类都选取相同数量的词作为特征的做法,即此处的做法是从9个类中各选取特征评价函数最高的三个词作为特征词,因此最后只有27个特征而非30个(由于数量差别不大,本文中仍称其有30个特征)。
从表2可以看到TW选择的词都是较为专业且具有代表性的,而CHI、IG对专业词的选择较差,如IG中的“5月”、“新华社”等词,CHI中的“第18”、“5月”等词,这些词对分类的贡献都较小,而且可能会成为分类的噪声,对分类结果造成影响。TW中的词则跟类别具有较强的联系,许多词都能直接判断出其所属类别,如“运动员”、“计算机科学”等。
(2)分类效果的有效性分析
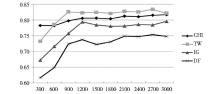
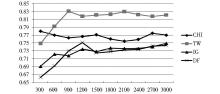
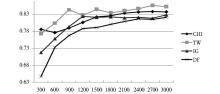
采用各种向量权重计算方法和三种不同分类方法最后得到的分类结果的宏平均F1值的结果如图2至图7所示:
 | 图2 宏平均F1值对比——TF-IDF+KNN分类法 |
 | 图3 宏平均F1值对比——logTF-IDF+KNN分类法 |
 | 图4 宏平均F1值对比——TF-IDF+类中心分类法 |
 | 图5 宏平均F1值对比——logTF-IDF+类中心分类 |
 | 图6 宏平均F1值对比——TF-IDF+SVM分类法 |
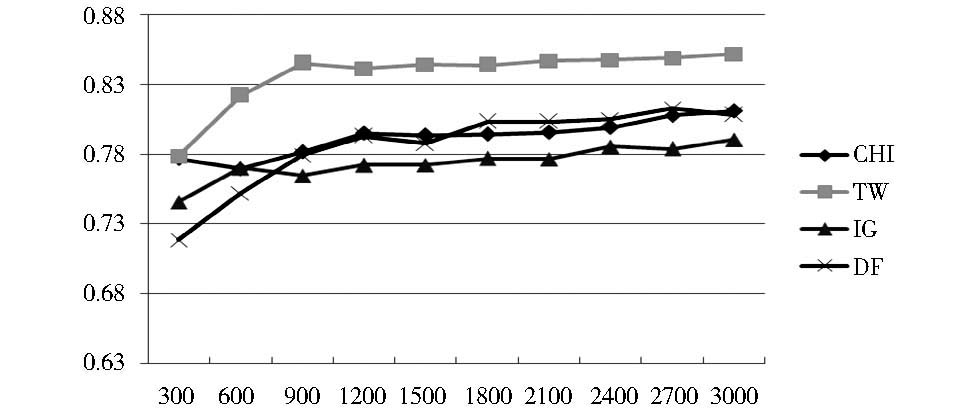 | 图7 宏平均F1值对比——logTF-IDF+SVM分类法 |
①本文提出的TW特征选择是所有特征选择方法在实际分类中效果比较好的,相比传统的CHI、IG和DF特征选择方法,其宏平均F1值得到了普遍提高,特别是采用logTF-IDF作为向量权重计算方法时。
②本文提出的TW特征选择方法虽然与其他三种方法相比取得了较好的分类效果,但从图中可以发现在选取特征数量较少时(如特征数量为300),TW的表现不如CHI,但当特征数量较多时,TW明显优于其他三种方法。这是因为TW在选取特征过少时,如果给专有名词过高的权重,那么特征集合中存在过多的专有词,特征就有可能在测试集中基本不出现,导致向量模型中存在过多权重为零的特征,从而出现特征不明显影响分类效果的情况。
本文重点研究了影响特征选择的几个因素,即词的重要性、特征性和代表性,并在这三个影响因素的基础上提出TW特征选择方法,而且用实验验证了该方法的有效性。该方法的前提是认为每个不同的词对分类有不同的贡献权重,这种权重可以反映词的重要性和类别区分能力,通过赋予词这种权重来进行特征选择,从而使分类效果得到提升,但也存在以下不足:
(1)TW特征选择方法的提出是建立在词的重要性、特征性、代表性三个因素的基础上。从这三个因素的量化角度来说,虽然本文的量化过程能取得较好的分类效果,但未必是最佳的一种量化方式,还可对其进行更深入研究并应用于文本分类。另外,在量化过程中还遇到专有词权重的计算问题,对于基本只在某一个类中才出现的词的权重计算问题也需要进一步研究。
(2)TW特征选择方法整合了CHI和TF-IDF对词的重要性描述,但还存在其他方法可代替CHI来描述词的重要性,如信息增益IG等。因此,在对词重要性的描述上还可用其他方法进行优化。
(3)本文用于实验的语料库仅局限于中文,难以验证改进的特征选择算法的普遍适用性。因此,在接下来的研究中可以选取更广泛的语料库进行实验,以完善模型从而增强其适用性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|