
{kind=link}
{kind=link}
跨语言术语同义关系推荐方法及其实证*
[宋培彦1  , 李静静
, 李静静1 , 赵星2 ]
, 李静静|
|


同义关系是术语词间关系的基本类型。以英汉对齐词典为知识库、以等值翻译词对为知识表示形式,提出对中文术语和英文翻译进行双向推导的方法,建立树形拓扑结构并进行遍历操作,通过加权优选模型对同义词推荐结果进行优化。实验证明该方法对术语同义关系识别的准确率较高,在知识组织工具构建、百科知识服务、信息检索等领域有一定应用价值。
Synonym of terminology is a basic type of relationships between terms. Based on the English-Chinese alignment dictionary, this paper proposes recommended method of term synonyms, deriving of Chinese and English translation in pairs, and optimizes synonyms results by weighted optimization measure. The experiments indicate that both the accuracy and efficiency of synonym recognition are improved by the method, which is beneficial to the construction of knowledge organization systems, encyclopedias and information retrieval.
知识的有效传播、利用和共享需要以知识的有序化组织为基础,近年来产生了以术语表、叙词表、本体等为代表的多种知识组织系统,形成了“知识组织”(Knowledge Organization)这一重要学科分支。知识组织试图将表示专业领域概念的术语组织成内涵规范、相互关联、定位清晰、层次分明的一个知识系统,通过对专业术语进行有效组织、揭示和管理,为人们精准获取各类知识提供有效工具。而构建丰富的词间关系是构建知识组织工具、开展知识服务的重要工作。
术语同义关系是知识组织工具的基本语义类型之一,它从概念角度对术语的语义进行判定,既包括严格意义上的等义词,也包括语义关系较为紧密的近义词。通过构建同义关系、对术语名称进行概念归并,有利于提高知识组织工具的适用性和用户友好性,实现不同知识组织工具之间的互操作,对于词表映射、语义检索和百科知识服务等具体应用具有重要意义[ 1, 2]。面对学科众多、数量庞大、增长迅速的术语数据资源,单纯依靠专家手工建立同义关系不仅成本高昂,而且周期较长、效率较低,因此术语同义关系的自动发现和推荐已经成为知识组织领域急需加强研究的重要课题[ 3]。以英汉对齐术语词典为知识库,研究术语语义的等值推导方法,进而推荐出可信度较高的候选同义词,是本文的主要研究内容。
目前,同义关系的识别主要有基于语言规则和基于统计模型两种方法。基于语言规则的方法是采用语言学知识、领域知识库、模式规则库等,对词语的语义关系进行判定。WordNet、《同义词词林》、《知网》等已有的知识库对词语的语义关系进行了显性描述,可以用于对词义距离进行推导和计算,在非专业领域的同义词语计算方面取得了较好效果[ 4, 5, 6, 7];图书情报学界编制了叙词表、分类表、本体及术语数据库等知识组织工具,也可以作为机器可读的知识库,用于对术语的语义关系进行计算[ 8, 9, 10, 11, 12],为构造术语的概念关系提供了参考。采用翻译词对作为双语对齐语料,将术语同义词作为等价翻译的过程,提出基于“翻译镜像”(Translation Mirror)的同义词计算方法,有助于提高同义词计算的效率,展现出了较好的研究前景[ 13, 14, 15, 16]。不过,现有的知识组织工具大部分收词数量较小、更新速度较慢,无法适应海量术语的知识计算需求,该方法目前尚处于研究阶段。此外,可以采用模式匹配的方法、通过有限的规则和特征对同义关系进行挖掘,例如陆勇等[ 17, 18]总结术语同义词的句法规则和特征词,从术语释义句中发现和识别同义词,并融入字面相似度、PageRank链接等多种策略,效果较好,部分克服了对知识库资源的依赖性;章成志[ 19]提出基于多层特征的字符创相似度计算模型,融合了字面、语义和统计关联等特征,识别效果有一定提升;徐硕等[ 20]采用双序列比对的方式,研究术语同义关系的计算方法。以上方法大多需要手工预先构建具有相当深度的规则库、知识库或者语料库,知识表示方式较为复杂,适用性受到一定的限制。
近年来,随着文献库的不断积累,基于词汇共现统计的方法迅速兴起。共现分析法认为,如果两个词在同一文献单元中经常同时出现,则认为两个词在意义上是相互关联的。利用词汇的共现统计信息,对词汇之间的相关性进行量化分析,有利于发现词语之间的潜在语义关系。常春等[ 21]采用共现计算的方法,对文献标题中词汇的共现频率进行统计,提出构建术语词间关系的可行方法;刘华梅等[ 22]对检索词的共现关系计算同义词,领域适用性较好。吴云芳等[ 23]从大规模语料中自动获取有并列结构关联的词语对,据此形成图,采用Newman算法对图进行划分,通过自动聚类相似词语实现同义关系的推荐。统计方法具有较好的领域适应性,能够适应不同领域词汇的处理,但是,同义关系本质上是深层的语义计算问题,统计方法通常还需要强有力的知识库的支持,才能对计算结果进行进一步优化和揭示。
以双语对齐术语词典为知识库、对计算结果进行量化操作,是进行同义关系计算的可行方法。术语词典、百科辞书、作者关键词等文献中收录了大量的中英文对照术语,中文术语与英文翻译较为整齐地建立对应关系,这些双语对齐的术语知识具有知识含量高、专业性强、词汇量大、更新速度快等优点,为术语计算提供了可靠的、海量的知识库,有助于克服知识资源稀缺的问题;同时,通过语义传导、排序和优化,形成可量化的推荐结果,提高了术语计算的可靠性。
信息论的观点认为,语言作为人类交际的工具,所负载的信息传递过程是:从信源出发,将信息进行适当的编码和加工,然后经过信道的中间变换和传输,将信息最大可能地传递到信宿的过程;信息经过编码、传递、解码三个基本阶段,完整、足量、准确地传递到接收者;语法、语义和语用是语言符号的三个基本层面,共同保障信息的有效传递。其基本过程是:
信源 ——编码 ——传递 —— 解码 —— 信宿.
英-汉翻译是信息等值转换的传递过程,本质上是对同一概念的语言符号转换,即同义等值转换过程,也适用于计算机自动发现同义关系。思路是:用户作为信源,希望找到某个概念,并将这个概念以语言符号的形式(术语)进行表达,完成编码过程,提交给计算机;计算机通过对该术语按照规则进行适当的符号变换、语义搜索和传导,在术语数据集中发现潜在的同义概念;然后,对这些潜在同义概念进行优化处理,确定最优的候选结果,并给出规范的术语符号形式,即完成解码过程,提交给用户进行使用;最终由用户对推荐结果进行接收和确认。在这个过程中,计算机完成信息的等值转换,并对计算结果进行优化排序;用户则是信息的发出者和信息的接收评判者,通过人机之间的交互和反馈,直至获得满意的结果。
术语词典中的英汉对齐是一种简单直观的知识表示方式,为进行同义关系的传递提供了可靠和足量的知识资源。在英汉对齐术语词典中,中文术语A对应英文翻译集合E,集合E中包含一个或多个英文词汇(元素);同时,以英文翻译集合E的元素作为中介符号,可以得到具有对应关系的中文术语翻译集合X,(A-E)或(E-X)中的元素构成一个有效词对(Word Pairs),表示对相同或相关概念的指称。这种具有翻译关系的词对是对同义关系的真实刻画,构成同义关系计算的知识表示基础。
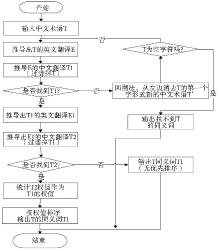
推导是同义关系计算的核心,具体操作为:为了获得术语的同义词,首先将中文术语作为入口,在英汉术语词典中获得其对应的英文翻译,再根据英文翻译词汇检索其对应的中文词,完成第一次扩展,获得该术语的基本候选同义词;对候选同义关系的中文词汇进行再次扩展,检索出其对应的英文翻译,再根据英文翻译检索其对应的中文词,完成第二次扩展,这样可以获得数量更多的同义词(简称“扩展候选同义词集”);最后,根据候选同义词出现的频率确定候选同义词的权重,按照权重从高到低排序,作为最终的推荐结果。同时,为了解决由于部分术语词典收词不全导致术语推导受限的问题,可以采用回溯机制,即如果在英汉双语词典中无法找到对应的词语,则把汉语术语按照从左到右的顺序,依次减少一个汉字,将剩余部分作为一个相关术语进行循环匹配操作,这样可以部分消除由于数据稀疏造成的精度误差,将较为相关的术语推荐出来。具体流程如图1所示:
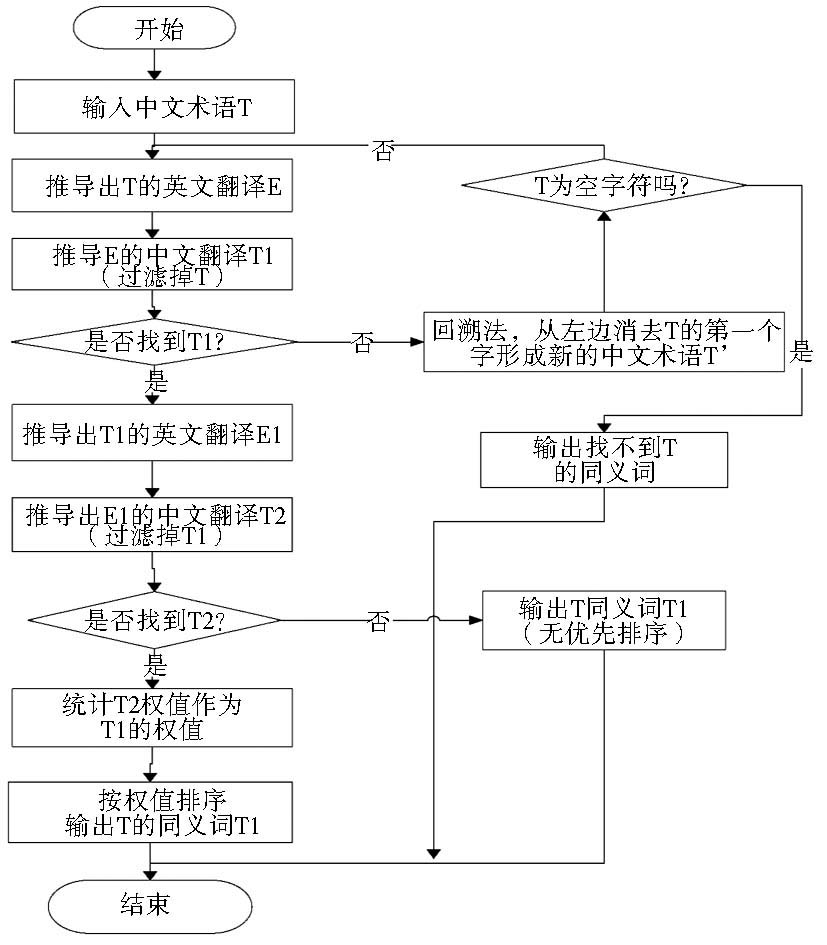 | 图1 算法流程图 |
以当前待检索的中文术语出发,经过两次扩展推荐变换,形成以中文术语为树根、以候选同义词为叶子节点的树形拓扑结构。该树的层次最深为5级,采用广度优先遍历法,从上到下逐层推导,最终将推导结果进行合并,选择权值较高的术语作为候选同义词。
 | 图2 识别同义词示意图 |
在图2中,T代表用户输入的中文术语,E1、E2、E3为中文术语T所对应的三个英文翻译。T1.1、T1.2、T1.3为E1所对应的三个中文翻译词汇,T2.1、T2.2为E2对应的两个中文翻译词汇,是一对多的关系;T3.1为E3对应的一个中文解释词汇,是一对一的关系。图2中树的每一个节点的子节点均为直接父节点对应的翻译。
“第一次推导”后得到中文词汇T的同义词{T1.1,T1.2,T1.3,T2.1,T2.2,T3.1},作为基本同义词集;“第二次推导”则是在多部英汉翻译词典中进行扩展查询,得到每个翻译词在所有词典中的翻译情况,并按照词对的翻译频率从高到低排序,将翻译词对的出现频率作为“打分评价”的过程,即:对树中除根节点以外的各个分支的中文术语按照频率排序和加权,权值较高的术语优先作为术语T的推荐同义词。
例如,对于术语“定义”,在英汉词典中的英文翻译为“define”和“definition”,通过第一次推导可以将“define”和“definition”所对应的中文——“规定”、“确定”、“分辨”、“分辨力”、“清晰度”、“清晰度(分辨力)”,作为“定义”的基本候选同义词,完成“第一次推导”操作。为了在候选同义词中确定和“定义”的相似度关系,需要对“第一次推导”后找到的中文候选术语进行“第二次推导”,即进一步在所有术语库中查找各个中文基本候选同义词的英文词,再对其英文词检索得到其对应的中文词,并统计中文词的出现频率,按照频率高低进行排序,将高频的术语优先作为同义词推荐。
为了测试该方法的有效性,从《英汉电信词典》等4本正式出版的英汉对照术语词典中选取通信、计算机、自动化领域的206 104个英汉对照术语为语料,形成英汉对齐的语料库;然后,选取240个电信专业中文术语,通过本文的同义词推导模型从对齐语料库中获取候选同义词,并对候选同义词进行加权处理,按权值从高到底排序,选择权值最高的前三个术语作为推荐同义词,共获得563个候选同义词,平均每个术语可以获得2.34个候选同义词,如表1所示:
| 表1 同义术语推荐实例 |
| 表2 术语同义关系识别准确率 |
在网络信息环境下,以权威性和准确性较强的英汉对齐术语词典为知识库,对翻译词对采用等值推导的方法进行同义关系的识别,能够适用于不同语种的术语同义词计算,弥补传统上字面相似度、共现统计等方法的不足,在处理专业性较强的术语同义关系方面有较好的应用价值,初步证实了该方法的有效性。除了以中英文对照术语词典为基础语料外,以文献中的中英文关键词作为基础资源,进一步扩大术语的学科覆盖面,将有利于提高对同义关系的召回率,为本方法的实用化提供良好的数据基础,进而应用到知识组织工具编制、百科知识服务、检索系统开发等领域。术语具有明显的学科特征,进一步加强术语数据库的建设和知识描述的深度[ 25],并通过术语的学科类别进行词义消歧、减少词义歧义造成的干扰,以提高多义术语计算的准确性,是今后需要继续研究的课题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|