{kind=link}
云模型和多特征的高校读者借阅偏好不确定性图书推荐研究*
引用本文
李克潮, 蓝冬梅, 凌霄娥. 云模型和多特征的高校读者借阅偏好不确定性图书推荐研究*. 现代图书情报技术, 2013, 29(5): 54-58
Li Kechao, Lan Dongmei, Ling Xiaoe. Research of Books Recommendation of Borrow Preference Uncertainty in University Readers Based on Cloud Model and Multi-feature. New Technology of Library and Information Service, 2013, 29(5): 54-58
Permissions
Li Kechao, Lan Dongmei, Ling Xiaoe. Research of Books Recommendation of Borrow Preference Uncertainty in University Readers Based on Cloud Model and Multi-feature. New Technology of Library and Information Service, 2013, 29(5): 54-58
云模型和多特征的高校读者借阅偏好不确定性图书推荐研究
摘要
利用云模型表示自然界中模糊性、随机性等不确定性优势,提出云模型和读者多特征的借阅偏好不确定性。计算读者专业、性别、年级加权相似度,利用逆向云算法计算以云的期望、熵、超熵来表示的读者借还时间间隔偏好,再计算读者基于云的相似度。结合读者多特征相似度、云相似度,向读者推荐存在复本的图书,并通过实验验证算法的有效性。
关键词:
云模型; 读者多特征; 借阅偏好不确定性; 图书推荐
Research of Books Recommendation of Borrow Preference Uncertainty in University Readers Based on Cloud Model and Multi-feature
Abstract
The paper, taking advantages of cloud model in expressing uncertainty of fuzziness and randomness in nature, proposes that there are uncertainties in cloud model and readers’ multi-featured books preference.The paper computes the weighted similarity of readers’ majors, genders and grades,uses the backward cloud algorithm to compute readers’ preference of borrow- return time interval that is expressed in cloud expectation, entropy and hyper entropy,and then computes the readers’ cloud similarity. Combining multi-featured similarity of readers with cloud similarity,the paper finally recommends books to readers with copied ones and proves the validity of the algorithm by experiments.
Keyword:
Cloud model; Readers multi-feature; Uncertainty of borrow preference; Books recommendation
1 引 言
个性化图书推荐系统能够使广大读者在海量的高校数字图书馆中,快速找到他们所偏好的图书,提高图书馆资料的利用率、服务质量,解决高校信息超载的问题[ 1]。目前的图书推荐方法,如协同过滤[ 2]、类别[ 3]、图书和用户多特征[ 4]、聚类[ 5] 、结合项目分类与概率[ 6] 、图书的目录与写作风格[ 7] 、图书价值[ 8]等,都只是根据读者过去的流通借阅记录决定读者偏好,把读者的借阅偏好看做确定的。
然而,高校读者借阅图书是一个定性定量的认知过程,存在很多客观的不确定性因素:
(1)一些高校的读者,特别是刚刚踏入大学校门的读者,大学生活迷惘,看到图书馆几百册的图书更显得迷失,随便外借了几本图书,这不能说明读者对外借的图书感兴趣;
(2)对放在同一个书架靠得很近的不同索书号的两本图书,图书的主题、出版年份、页数等都差不多的时候,在读者可外借册数、阅读时间受限时,读者随机外借了这两本书中的一本,这种情况下,不能说明读者对外借图书的偏好程度高于未被外借的另一本图书;
(3)文献[2]和文献[4]认为读者借还(外借与归还)图书的时间间隔越长,读者对图书越感兴趣。但有的读者,当他很喜欢某本图书时,把时间全部放在阅读这本书上很快就把书看完,归还图书馆。这种情况下读者借还图书的时间间隔反而变短;
(4)还有一些读者,因比较忙,没时间阅读已经借的图书,或者阅读完了但忘记归还图书馆,以致借还的时间间隔比较长,这种情况也不能说明读者很喜欢外借的图书。
云模型表示定性概念与其定量表示之间的不确定性转换模型,反映客观世界中事物或者人类知识不确定性中的模糊性(边界的亦此亦彼性)、随机性(发生的概率)[ 9],已经应用于电子商务协同过滤算法[ 10, 11]、食品安全质量综合评价[ 12]等领域。本文提出云模型和读者多特征的图书推荐方法,结合影响读者借阅的多特征相似度、基于借还时间间隔的逆向云相似度,在图书馆书库存在复本的前提下,向读者推荐其可能偏好的图书。
2 云模型
云模型能够实现定性概念与其定量数值表示之间的不确定性转换模型,表示自然、社会中的不确定现象,已经应用于智能控制、模糊评测等多个分类中[ 9]。
定义1:设集合T={x}是用精确数值表示的定量论域,C是定量论域T的定性概念,若任意定量值x∈T,并且x是定性概念C的一次随机实现,x对C的确定度μ(x)∈[0,1]是一个具有稳定倾向的随机数,μ:T→[0,1],∀x∈T,x→μ(x),则x在用精确数值表示的定量论域T中的分布C(X)称为云(Cloud),每个x称作一个云滴。用数值特征期望Ex、熵En、超熵He表示云,Ex是云滴的重心位置,反映云滴在空间的分布期望;En是定性概念亦此亦彼的度量,反映定性概念云滴的离散程度、定性概念在数域中被接受的数域范围;超熵He是En的熵,用于度量熵的不确定性,由熵的随机性、模糊性决定[ 9]。
定义2:逆向云,实现从定量数值表示的精确数据到以数字特征期望Ex、熵En、超熵He表示的定性概念的转换。逆向云算法的步骤为[ 9]:
输入: N个云滴x1,…,xN。
输出:N个云滴表示定性概念的数字特征期望Ex、熵En、超熵He。
①计算样本均值X、样本方差S2:
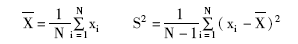
②期望Ex的估计值 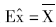 ;
;
③熵En的估计值 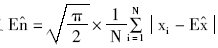 ;
;
④超熵He的估计值 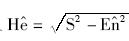 。
。
定义3:云Φ与φ的相似度[ 10]:
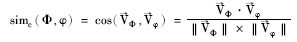 (1)
(1)
其中,云Φ、φ的数字特征向量分别为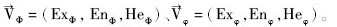 。
。
3 云模型和多特征的高校读者借阅偏好不确定性图书推荐
其中,ufm,t为读者um特征ft的值。
表2中,学科门类代码由两个字符串组成;专业类代码是在所属学科门类代码的基础上后加两个字符;每种专业代码是在所属专业类代码的基础上后加两个字符(若专业代码后含“T”或“K”表示此专业为特设专业和国家控制布点专业)。
由表4的例子统计出三位读者A、B、C借还时间频度向量:
读者偏好什么书会受到其特征的影响。设标识读者唯一性的m位读者的借阅证号U={u1,…,um},影响读者借阅的主要特征F={f1,…,ft}。读者-特征如表1所示:
| 表1 读者-特征 |
高校读者借阅图书,主要受到读者专业、性别、年级的影响。不同读者专业可能不一样,不同专业的读者借的专业书类别就不一样;性别影响读者借阅业余书的类别;在高校期间,同一年级相同专业的读者开设的课程基本一样,借阅的专业书也基本一样,高年级的读者比低年级的读者更倾向于借阅较深入的专业书。
高校读者的专业,本文以教育部关于印发《普通高等学校本科专业目录(2012年)》为准[ 13],分设哲学、经济学等13个学科门类,每个学科门类下分设一个或多个专业类,每个专业类又分设一种或多种专业,所有的学科门类、专业类、专业都可用代码表示。由于篇幅有限,本文只列出部分专业如表2所示:
| 表2 普通高等学校本科专业目录 |
笔者已经在文献[4]建立读者专业分类树,通过搜索的方式比较读者专业相似度,但此方法比较繁琐。本文先把专业目录表专业代码中的“T”或“K”去掉(去掉不影响比较),所得每种专业的代码都为6个字符,然后通过比较任意两种专业代码字符串最左边的相同字符位数来计算读者专业的相似度。此时,任意读者ui与uj的专业相似度:
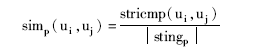 (2)
(2)
stricmp(ui,uj)为专业代码最左边相同字符的位数,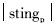 为专业代码字符串长度,取值6。例如处理后的“逻辑学”的代码为“010102”,“宗教学”的代码为“010103”,两者代码最左边的相同代码为“01010”5个字符,那么逻辑学与宗教学的专业相似度为5/6。
为专业代码字符串长度,取值6。例如处理后的“逻辑学”的代码为“010102”,“宗教学”的代码为“010103”,两者代码最左边的相同代码为“01010”5个字符,那么逻辑学与宗教学的专业相似度为5/6。
读者主要特征相似度采用文献[4]的方法:
simf(ui,uj)=α×simp(ui,uj)+β×simg(ui,uj)+χ×sims(ui,uj) (3)
其中,simg(ui,uj)和sims(ui,uj)分别为读者ui与uj年级、性别的相似度,并且α+β+χ=1。
建立m位读者U={u1,…,um}对n本不同索书号图书B={b1,…,bn}的借还时间间隔如表3所示:
| 表3 读者-图书借还时间间隔 |
其中,ubm,n为读者um外借与归还索书号为bn的图书的时间间隔(天)。为防止一些读者借书很久后,忘记还书导致借还时间间隔太长对推荐的负面影响,因此若ubm,n≥35天(实验数据集来自借期为35天的本科生借阅记录),则取ubm,n=35天。 统计读者对每种索书号图书的借还时间间隔,记作读者的借还时间间隔频度向量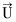 ={u1,…,uy},u1-uy为对应于读者借还时间间隔天数的借阅次数。读者借阅频度向量不关心具体图书的借还时间间隔,而是关心图书集合的借还时间间隔特征。
={u1,…,uy},u1-uy为对应于读者借还时间间隔天数的借阅次数。读者借阅频度向量不关心具体图书的借还时间间隔,而是关心图书集合的借还时间间隔特征。
| 表4 读者借还时间间隔频度 |
A=(0,0,0,0,0,0,0,0,0,2,0,0,0,0,0,1,0,0,0,1,0,2,0,0,0,0,1,1,0,1,0,0,0,0,0).
B=(0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,1,1,1,0,2,0,0,1,0,0,0,0,0,1,0,0,0,0,0).
C=(0,0,0,0,1,0,0,0,1,0,0,0,0,1,0,0,0,0,1,1,0,1,0,0,0,0,0,1,0,1,0,0,0,0,0).
根据逆向云算法,通过读者对索书号图书的借还时间间隔频度向量,计算由期望、熵、超熵组成的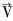 A=(ExA,EnA,HeA)、B=(ExB,EnB,HeB)、C=(ExC,EnC,HeC)。ExA、ExB、ExC反映读者对所有图书的平均借还时间间隔,代表偏好程度;EnA、EnB、EnC反映读者借还时间间隔的集中程度,或称偏好的离散度;HeA、HeB、HeC为熵的稳定程度。
A=(ExA,EnA,HeA)、B=(ExB,EnB,HeB)、C=(ExC,EnC,HeC)。ExA、ExB、ExC反映读者对所有图书的平均借还时间间隔,代表偏好程度;EnA、EnB、EnC反映读者借还时间间隔的集中程度,或称偏好的离散度;HeA、HeB、HeC为熵的稳定程度。
由公式(1)计算读者借还时间间隔频度云相似度simc(ui,uj),结合公式(3)读者特征相似度simf(ui,uj),得到读者相似度:
sim(ui,uj)=μ×simf(ui,uj)+(1-μ)×simc(ui,uj) (4)
其中,μ∈[0,1]为权重因子。
4 图书推荐步骤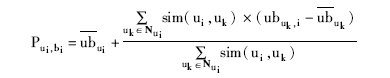
算法执行步骤如下:.
输入:读者的借阅证号U={u1,…,um}、读者特征F={f1,…,ft}、图书在架复本数C={cb1,…,cbn}、读者-图书借还时间间隔表3。
输出:目标读者ui的l本图书推荐列表。
步骤:
①由公式(3)计算读者之间主要特征的相似度;
②根据表3,由公式(1)计算读者之间借阅时间间隔频度云的相似度;
③由公式(4)计算读者之间的相似度;
④根据步骤③,将sim(ui,uj)降序排序,获得目标读者ui的最近邻居读者集合Nui=(N1,…,Nk);
⑤根据最近邻居读者集合Nui中各位读者对图书的偏好,计算目标读者ui对图书bi的偏好:
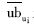 为目标读者ui外借与归还图书的平均时间间隔,Nui为目标读者ui的最近邻居,sim(ui,uk)为目标读者ui与读者uk的相似度。
为目标读者ui外借与归还图书的平均时间间隔,Nui为目标读者ui的最近邻居,sim(ui,uk)为目标读者ui与读者uk的相似度。
⑥把Pui,bi最高、在架复本数不为零的l本图书推荐给目标读者ui。
5 实验结果比较分析
本文从广西某高校图书馆的流通借阅记录中,取汉语言、英语、新闻学、数学与应用数学、计算机科学与技术、网络工程这6个专业317位本科生的1 056条借阅记录作为数据集。从《普通高等学校本科专业目录(2012年)》查到这6个专业的专业代码分别为050102、050201、050301、070101、080901、080903。每条借阅记录包含读者借阅证号、性别、专业代码号、年级、图书索书号、外借日期、归还日期字段。从图书管理系统获取每一索书号图书的在架复本数。按照借阅日期先后对借阅记录进行排序,取前面80%的借阅记录为实验训练集,后20%的借阅记录为测试集。
设Hits为正确的图书推荐数,N为总的图书推荐数,使用准确率Precision作为图书推荐验证标准[ 1]:
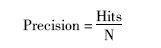
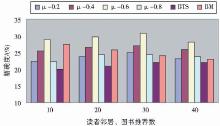
公式(3)中读者专业、年级、性别相似度权重α、β、χ都取1/3,公式(4)中读者特征相似度权重μ分别取0.2、0.4、0.6、0.8,读者的最近邻居数、图书推荐数都取10、20、30、40时,本文提出的图书推荐方法与文献[2]的BTS、文献[4]的BM推荐方法的图书推荐准确率对比如图1所示:
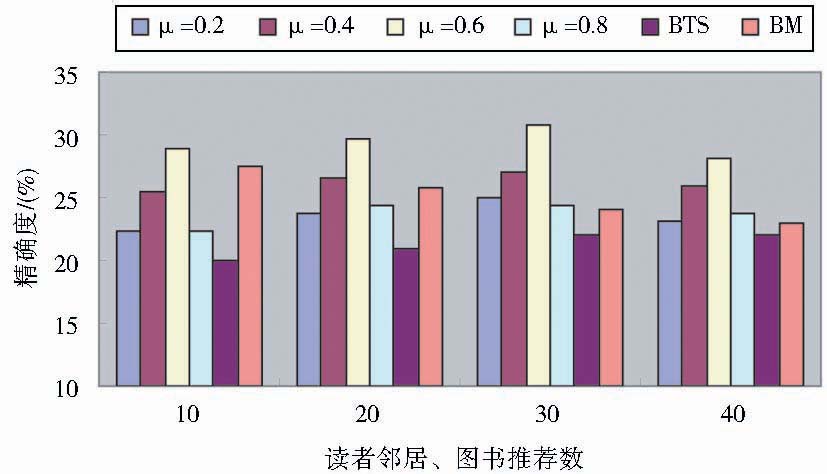 | 图1 图书推荐准确率对比 |
选择文献[2]作为比较,是因为本文与文献[2]都认为读者对图书的偏好与图书借还时间间隔有关;选择与文献[4]作比较,是因为本文与文献[4]都认为读者对图书的偏好与图书借还时间间隔、读者多特征相似度有关。
从图1可以看出,本文提出的结合云模型和读者多特征的图书推荐方法,当权重因子μ取太大值(如取0.8,此时读者邻居主要由读者特征相似度决定)或太小值(如取0.2,此时读者邻居主要由读者借还时间间隔频度云相似度决定)时,推荐效果都不是最佳。这说明读者对图书的借阅偏好受读者特征的影响,同时也具有不确定性因素。当μ取0.6时推荐效果最佳,并且在读者邻居数、图书推荐数的取值内,推荐质量均优于常见类似方法。经分析原因如下:
(1)在认同读者对图书的偏好与图书借还时间间隔有关的前提下,针对读者存在学习规划不明确、对图书的偏好存在模糊性及借还图书存在随机性等不确定性现象,把云模型能够表示自然界中模糊性、随机性等不确定性的优势应用于图书推荐中。
(2)在认同读者对图书的偏好受读者多特征影响的前提下,根据新版的读者专业目录,改进了读者特征相似度的计算方法。
(3)充分结合云模型的优势和改进的读者特征相似度,对两种读者相似度进行加权,再进行综合推荐。最终验证了读者对图书的偏好与读者特征有关,同时验证了文章提出的观点:读者对图书的借阅偏好有些是明确的,也有些是不明确的,即图书借阅具有模糊性、随机性、盲目性等不确定性现象。
6 结 语
个性化图书推荐是使读者充分利用图书馆资源、提高图书馆服务质量的有效手段之一。对读者借阅偏好进行研究,有助于向读者推荐其可能感兴趣的图书。本文除了研究影响读者借阅的历史借阅记录、读者特征,还研究以云模型为理论的读者借阅模糊性、随机性,建立读者偏好相似度模型,较好地表示了读者的偏好。下一步工作包括:通过实验将改进的云模型应用到图书推荐,考虑向读者推荐新书、向新读者推荐图书,即推荐的稀疏性、冷启动,同时考虑推荐的多样性。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|