







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用主题自动标引生成技术功效矩阵*
[王丽 , 张冬荣
, 张冬荣
, 张冬荣|
|


构建一种标引功效矩阵自动化工具Patent-TEM,该工具通过词库构建、主题标引、功效矩阵、文本提取等步骤对专利文本进行挖掘和分析,自动生成专利功效矩阵图,能够大幅度提高传统功效矩阵分析的工作效率,实现专利微观分析工作的自动化与工具化。结合CMOS工艺技术专利分析的应用实践对Patent-TEM的设计和实现进行详细描述,并指出下一步研究工作的方向。
This paper studies a method of deep patent analysis and realizes this method through automation tool, namely Patent-TEM. This tool can mark key technology words automatically for every patent, finish the patent technology/effect maps based on subject indexing and extract patent text for need. Patent-TEM saves time cost on patent technology/effect maps analysis. This paper gives the practices in CMOS process with this tool, and points out the research direction for the future.
世界知识产权组织WIPO统计报道,专利说明书中有足够且详尽的技术说明文件,含有90%-95%的研发成果,70%-90%的发明创造从未在其他刊物上发表,如果能够充分利用专利信息,可以缩短60%的研发时间,节省40%的研究经费[ 1]。因而对专利信息进行深度挖掘和分析成为当前信息情报研究的一种重要手段。传统的专利信息分析集中在对专利外部特征项(如申请年/发表年分析、专利权人/机构分析、专利发明人/作者分析等)进行分析,展示技术宏观态势与研究格局等,但是针对专利内容进行深度挖掘,从专利微观技术分析角度揭示技术研发关键要素、把握技术发展脉络等方面,仍稍有欠缺。随着用户服务需求的深入,进一步充分利用技术专利来挖掘技术研发关键要素、缩短研发时间及激发创新思路,实现基于内容层面的微观技术预测,显得越来越重要。
技术功效矩阵是专利微观分析最常用的一种分析方法。技术功效矩阵能通过专利文献反映的主题技术方案和主要技术功能之间的特征研究来揭示技术和功效二者的关系[ 2]。它是将技术领域的技术手段与对应实现的技术功效种类构成矩阵,通过矩阵数据直观揭示出技术密集区、空白区,从而发现和选择技术创新点[ 3]。广义上讲,技术功效矩阵可以是从专利信息中提取多种类型的技术元素(如手段、功效、目的、功能等),通过矩阵的形式来刻画各元素之间的关系,尽可能体现影响技术领域的关键问题[ 4] ,对技术研发布局一目了然,进而帮助科研用户设计专利技术回避方案及创新发展研发路径。因此研究技术功效图可有效加强“专利部署”,在了解技术现状、分析竞争对手和协助制定技术发展战略方面具有重要作用。
传统技术功效矩阵大多通过人工逐篇阅读后抽取专利关键技术手段与功能效果的类型,并将专利归入各分类中,列出专利技术手段与功能的二维矩阵,专利分析的数量规模较小,效率较低。本文所构建的专利标引功效矩阵自动化工具(Patent-TEM),通过主题标引实现技术元素的分类,自动形成技术功效矩阵;同时Patent-TEM不局限于狭义上的技术手段VS技术功效矩阵,通过主题标引功能,将专利自动归入技术元素分类中,生成广义上的技术元素VS技术元素的技术功效矩阵,同时可对技术功效矩阵进行扩展,实现多维度专利功效复合分析的目的。
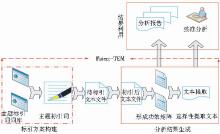
通过对专利功效矩阵分析基础方法进行解析,Patent-TEM采用的自动化标引功效矩阵方法分为4个模块,Patent-TEM基本框架如图1所示:
 | 图1 Patent-TEM基本框架 |
(1)主题自动标引。核心为主题标引方案构建, Patent-TEM会根据构建的标引方案对文本进行自动标引。标引结果是生成功效矩阵的基础,同时可为专利研读提供索引,节省阅读的时间和精力。
(2)功效矩阵生成。配置主题标引维度,自动统计与测算,构造专利技术功效矩阵,制作专利功效矩阵圆点统计图。
(3)功效矩阵扩展。选择不同的分析内容,形成多样化的技术功效矩阵,如常规的技术功效专利分析(默认)、技术功效申请人分析、技术功效发明人分析、技术功效IPC分析等多样化的分析矩阵结果。
(4)文本关联提取。进行专利原始文献文本标示和提取,支持用户利用工具的标示和提取功能对相关专利进行深度内容研读,验证和完善已形成的功效矩阵。
基于Patent-TEM的设计框架通过软件技术实现其应用功能。目前数据库尤其是专利数据库大多支持Excel的导出,Patent-TEM采用业界标准 COM 技术来实现 Excel 互操作,支持Excel格式的导入、分析、导出等。主题自动标引是所有功能的基础模块,实现的技术核心是检索引擎。Patent-TEM采用支持中英文的高性能开源检索系统Firtex2作为基础[ 5],使用C++ 语言实现扩展应用,部署原生Win32应用程序,优化内存检索的标引操作,自主研发矩阵检索算法,最终实现主题自动标引、技术功效矩阵生成、文本提取及可视化。
Patent-TEM基于技术功效矩阵的目的而开发,首先对技术词和功效词进行提取, Patent-TEM通过构建主题词标引方案,实现技术词和功效词自动标引,然后对标引词进行计算分析实现技术功效矩阵。
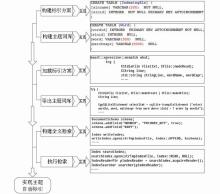
主题标引是根据文献的特征赋予文献标识的过程,主要包括两个环节:主题分析,即确定文献内容特征;转换标识,即用主题标引词表达主题概念[ 6]。根据标引词的来源,自动标引分为自动抽词标引和自动赋词标引两种类型[ 7],本文涉及的主题自动标引属于自动赋词标引,就是从某种形式的词表中选取词语来表达文献主题内容。主题自动标引分三个层次实现:基于词库的整体层次,即构建标引方案,提供各种词库的相关描述;跨词库的基于主题标引词的揭示与检索,包括主题词库检索与关联,由Patent-TEM自动完成;在前两层的基础上以主题标引词的规范化表达进行标引,由Patent- TEM自动完成[ 8],技术实现流程如图2所示:
 | 图2 Patent-TEM主题自动标引技术实现流程 |
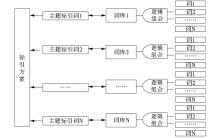
Patent-TEM是文本内容挖掘分析工具,在进行主题词标引之前,需要构建合理的标引方案,建立主题关联词库,以期在主题标引时尽可能挖掘出相关的文本内容。根据最终的分析目的确定Patent-TEM的标引主题词,可以是技术特点的分类、技术流程的分类,也可以是用户提出的研发技术点的分类,可根据具体的分析内容动态扩展,灵活构建标引方案,而不受技术领域的限制,因此Patent-TEM可以应用于任何技术领域。Patent-TEM采用布尔逻辑检索式构建词库,不受检索词数量限制,支持中文或英文。在构建词库之前,需要确立最终的主题标引词;对该标引词所代表的内容进行剖析,列出具有相同主题内涵的各种表达词、表达式(如同义词、俗名、学名、简称、全称等);进行逻辑组合,形成主题标引词的关联词库,如图3所示:
 | 图3 标引方案构建 |
本文通过CMOS工艺技术专利分析实践说明Patent-TEM的技术实现。截至2011年6月,经检索、合并、筛选得到CMOS工艺最终分析专利簇3 947项。 CMOS工艺技术专利分析是根据科研用户提出的研发技术点构建CMOS工艺标引方案,同时根据集成电路的性能和用户需求确定CMOS效果标引方案,如图4所示:
 | 图4 “CMOS工艺”标引方案 |
“CMOS工艺”标引方案确定“隔离”、“压力”、“沟道”、“器件”、“栅门”、“连接孔”等6个标引主题词。通过科研用户提供、技术背景研究、文献阅读等确定每个技术点和技术效果的常用表达。然后,通过匹配表达式分别对标引主题词构建相应的关联词库,例如,标引主题词“压力”的匹配表达式在本方案中为“stress OR strain OR tension OR piezoresistance”,Patent-TEM将按照该匹配表达式对文本专利进行“压力”标引。Patent-TEM工具具有英文的词根还原功能,可实现词形扩展检索。
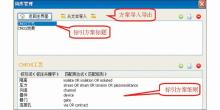
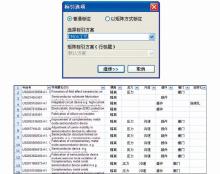
在建立合理的标引方案之后,Patent-TEM可以根据构建的主题标引方案对文本进行自动标引。首先选择专利文本的关键内容(如题名、摘要、IPC等),然后选择普通标引方案,Patent-TEM根据标引主题词的关联词库对所选内容进行检索,自动完成对每篇专利的主题标引,如图5所示:
 | 图5 “CMOS工艺”标引及结果显示 |
因为专利技术存在主题交叉现象,同一篇专利(或论文)可能被复分在不同的标引主题词下。通过主题标引,可以清楚快速地了解待分析的专利集每条专利所属的技术分类,同时为选择性读取专利提供参考,节省科研用户面对大量数据进行阅读的时间和精力。
技术矩阵可以通过多维度组合深入分析专利技术网络[ 9]。Patent-TEM基于双标引方案形成技术矩阵,即根据要形成的技术矩阵的横纵坐标选择横标引方案和纵标引方案(技术标引方案或功效标引方案),Patent-TEM根据所选方案自动形成技术矩阵。每个标引方案包含若干标引主题词(技术词或功效词),Patent-TEM根据标引方案,进行自动标引,每篇文献均被赋予一个或多个主题词标签,Patent-TEM通过统计分析形成技术矩阵并进行可视化显示,技术实现流程如图6所示:
 | 图6 Patent-TEM矩阵生成技术实现流程 |
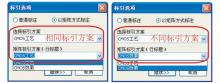
Patent-TEM基于功效矩阵的目的开发,提供常规的技术手段VS技术功效矩阵,但并不局限于此,它可根据科研用户的实际需求设计标引方案,通过双维标引方案形成多种类型的技术元素VS技术元素功效矩阵[ 4]。图7示例中,可以选择相同(CMOS工艺-CMOS工艺)或者不同(CMOS工艺-CMOS效果)的标引方案,生成不同的专利技术矩阵。
 | 图7 矩阵标引方案选择 |
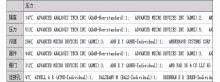
Patent-TEM自动生成的专利技术矩阵,通过技术交叉分类监控技术现况,以对比气泡图方式呈现,直观显示专利技术的疏密分布状态唐與菁.专利地图制作与实例解析(培训).北京:中国科学院国家科学图书馆,2008。。选择相同标引方案(CMOS工艺-CMOS工艺)生成的技术矩阵如图8所示,其中,横轴和纵轴均为技术手段,交叉点数量表示相应技术手段的专利数量,该技术点的专利数越多,相应的气泡越大。
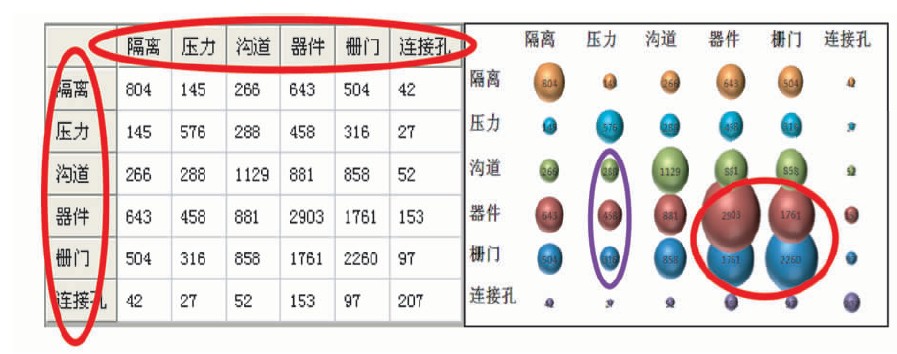 | 图8 技术手段VS技术手段矩阵分析结果示例 |
可以直观看出本专利集的技术手段主要集中在“器件”、“栅门”及“器件-栅门”方向,这些专利密集的技术点是当前的热点技术,需要重点关注,更需要在自主开发时注意技术规避设计。同时,也可以通过该矩阵直观地发现目前在CMOS“压力”方面的交叉研究集中在“器件”、“栅门”、“沟道”方向,为科研创新方向提供参考。因此,这种相同标引方案的专利功效矩阵,不仅有利于科研用户发现技术研发的“雷区”和“处女地”,也有利于进行技术交叉演化方面的深入分析,为后续结合时间进程的基于交叉技术的演化树研究提供基础[ 10]。
选取不同标引方案(CMOS工艺-CMOS效果)形成的专利功效矩阵如图9所示,横轴为技术所实现的效果、纵轴为技术手段。
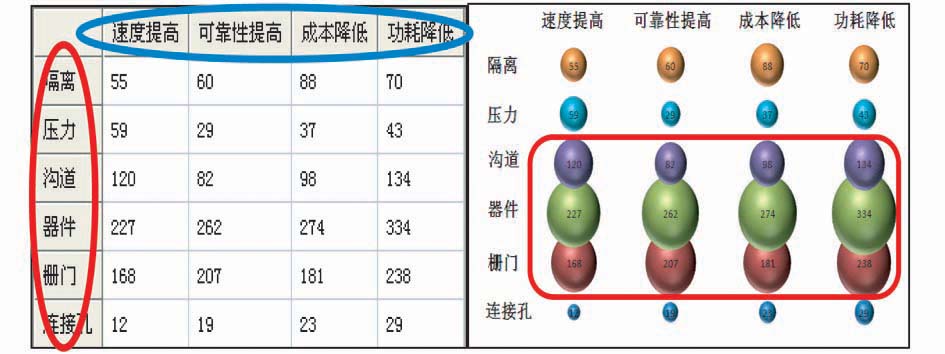 | 图9 技术手段VS技术功效矩阵分析结果示例 |
通过功效矩阵图发现CMOS的每项技术手段所对应的功能效果的气泡大小较为均匀,说明科研用户所关心的单个技术手段的改进均可以提高整体的性能,其中“器件”、“栅门”和“沟道”是目前的主流研究方向,而“连接孔”和“压力”方向的专利较少,原因可能是在“连接孔”和“压力”方向的研究对提升整体性能贡献不大,也很有可能以上方向是目前的专利申请空白点,或者正处于技术研发的起步阶段。通过专利技术功效矩阵获悉当前技术空白点具有重大意义,不仅可以指导企业研发方向,还可以在这些技术点布局自己的专利,形成自主知识产权。
本文构建的Patent-TEM工具除了可以生成常规的“技术-功效-专利数”矩阵,还可以生成“技术-功效-专利申请人”、“技术-功效-专利发明人”、“技术-功效-专利IPC”、“技术-功效-专利申请年”等“技术-功效-专利相关”的矩阵,不同矩阵代表不同意义,大大扩展了专利功效矩阵的类型和分析角度。例如通过“技术手段-技术手段/技术功效-专利申请人”矩阵,可进行申请人技术聚焦点和技术空白点分析,帮助科研用户规避专利壁垒,优化自主专利布局,发掘新的活跃技术方向。Patent-TEM首先实现功效矩阵(如,技术手段VS技术功效矩阵),经过矩阵检索后,命中的记录将减少,再选择扩展统计项(如,专利申请人),遍历每一个命中记录,对命中的记录分别分析其扩展统计项,汇总统计,最终得到扩展矩阵(如,技术手段VS技术手段VS申请人矩阵)。技术实现流程如图10所示:
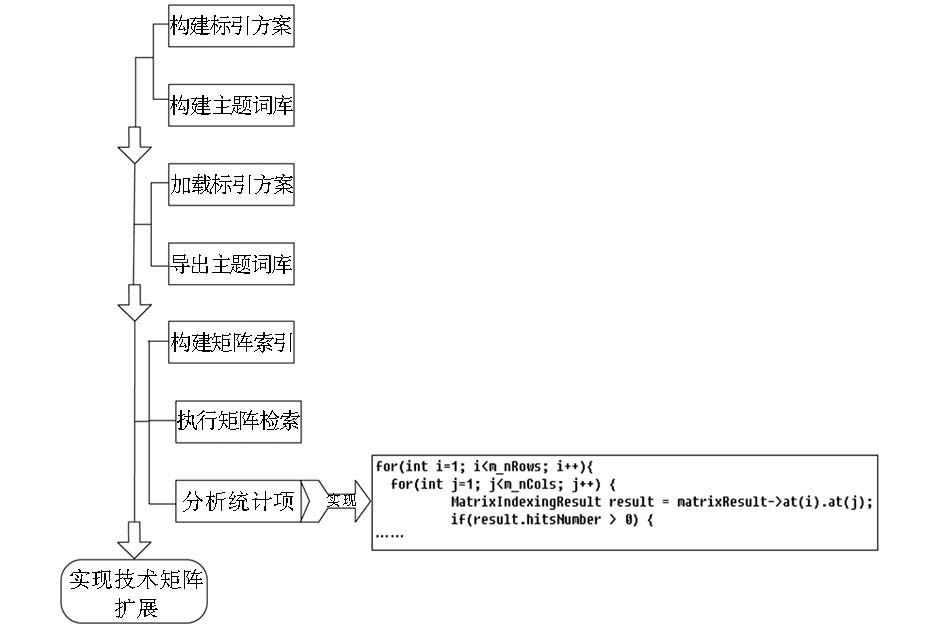 |
图10 Patent-TEM矩阵扩展技术实现流程 |
图11中交叉点数量表示“CMOS工艺-CMOS工艺”涉及的专利申请人数量,可直观看出“器件”、“栅门”、“器件-栅门”技术方向的研究机构较多。而对比图8,可以发现在“器件”、“栅门”、“器件-栅门”方向的申请人相对于专利数量较少,表示在这些方向研究相对集中,普遍存在一个机构拥有多项专利的情况,易于发现核心机构和相关专利簇。
 |
图11 技术手段VS技术手段VS申请人矩阵分析结果示例 |
图12中交叉点数量表示“CMOS工艺-CMOS效果”涉及的专利申请人数量,交叉点的专利申请人越多,相应的气泡越大,在进行相关技术研究时需要关注的机构也越多。结合图9,可发现图12中申请人与专利数在技术功效上的趋势基本保持一致,但是申请人数相对于专利数量要多,说明在技术功效方面合作申请的情况较多,由于技术效果性能的改进与市场紧密联系,及时发现和关注专利技术合作开发的机构,将为研发导向提供重要参考。
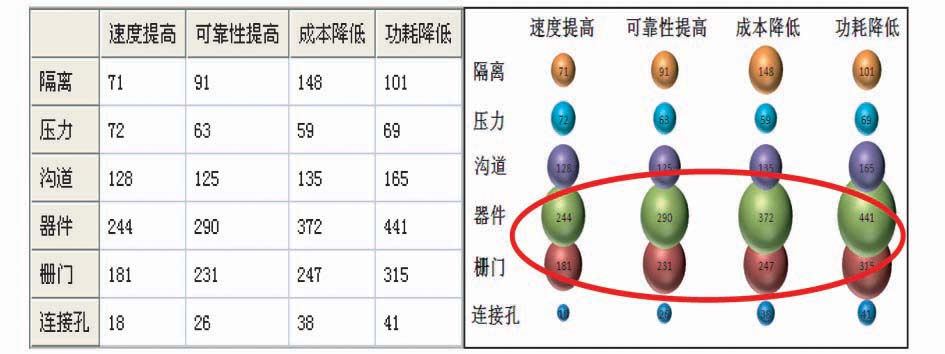 |
图12 技术手段VS技术功效VS申请人分析结果示例 |
同时,本文构建的Patent-TEM工具还可以提取并同步显示专利相关的详细信息,比如专利涉及的具体申请人及其专利数量、具体发明人及其专利数量、专利涉及的具体IPC分类及各类专利所占份额等信息。例如图13所示对“技术手段-技术手段”矩阵进行扩展分析得到申请人详细信息,分析结果显示了每一个技术点上都有哪些申请人,每个申请人在每个技术点上有多少专利,通过该分析可知每个技术点上的申请人构成情况,为下一步进行技术监控提供指导。
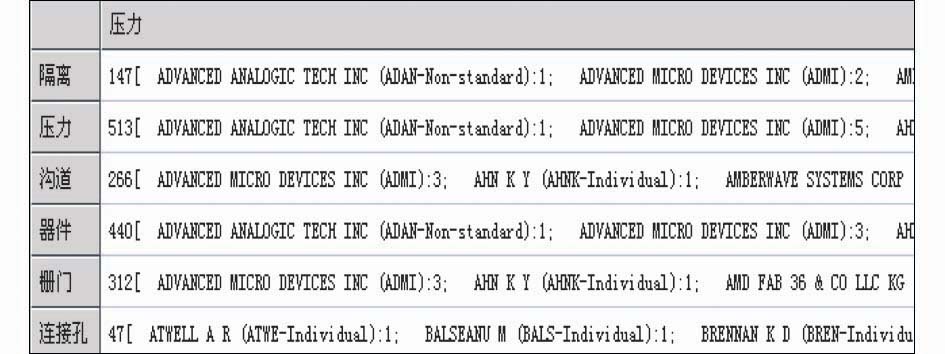 | 图13 技术手段VS技术手段VS专利申请人详细信息分析结果示例 |
文本关联提取在本文中主要指根据功效矩阵结果提取出具体的技术专利。专利分析过程中,可能需要查看某个技术方向的具体专利内容,进行分析效果的验证评估从而及时调整分析方案;或者在将专利分析报告提交科研用户之后,用户格外关注并需要提取某个技术点的专利,这都要求Patent-TEM支持专利文本提取功能,方便情报分析人员和科研用户从过程或结果中提取和关联专利文本。
Patent-TEM文本关联,从功能上,生成功效矩阵后,点击功效矩阵交叉点,可以实现对专利文本的提取和标识;从技术上,通过编程统计命中项,然后赋予不同的操作符将命中项提取出来或进行标识,如图14所示:
 | 图14 Patent-TEM文本关联提取技术实现流程 |
例如需要具体了解可以产生提高芯片速度效果的隔离技术,通过图9功效矩阵结果分析可知,共有55条相关专利,通过点击功效矩阵中的“55”,便可将该55篇专利单独提取出来(鼠标左键双击)或者进行颜色标示(鼠标右键点击),方便验证判读和深度研读。Patent-TEM对专利文本的单独提取和颜色标示的结果如图15所示:
专利技术功效矩阵作为一种专利微观分析的重要方法,支持对专利内容的深度挖掘与分析,支持科研用户掌握技术重点、发现技术空白点、规避技术雷区。实践案例显示,Patent-TEM降低了专利分析的时间与精力成本,是有效实现专利技术功效矩阵自动分析工具。
Patent-TEM在主题标引方案构建方面,是基于技术词汇的逻辑组合,这样的设计结构不受技术领域的限制,但是需要人工操作去构建准确的主题配置词库。因此本文的下一步工作便是对专利主题的自动分类的研究。笔者拟将对专利标准分类如国际专利分类IPC、美国专利分类UPC、日本专利分类FI、F-Term、欧洲专利分类EPO等分类体系进行深入研究,并对国内外当前研究的专利分类方法如贝氏理论[ 11]、本体论[ 12]、层级分类[ 13]、语义分析[ 14]等进行调研,遴选、构建合理的分类实现方法。
此外,专利中较隐晦信息内容和潜在特征的挖掘还存在很多需要深入探讨的问题。相对便捷的了解专利的技术、功效信息,专利的技术词、功效词的界定、区分、抽取,专利词自动聚类、分类等均是下一步研究的方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|