

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于LDA高频词扩展的中文短文本分类*
[胡勇军1  , 江嘉欣
, 江嘉欣2 , 常会友3 ]
, 江嘉欣|
|


针对短文本特征稀疏、噪声大等特点,提出一种基于LDA高频词扩展的方法,通过抽取每个类别的高频词作为向量空间模型的特征空间,用TF-IDF方法将短文本表示成向量,再利用LDA得到每个文本的隐主题特征,将概率大于某一阈值的隐主题对应的高频词扩展到文本中,以降低短文本的噪声和稀疏性影响。实验证明,这种方法的分类性能高于常规分类方法。
Short texts are different from traditional documents in their shortness and sparseness. Feature extension can ease the problem of high sparse in the vector space model, but feature extension inevitably introduces noise. To resolve the problem, this paper proposes a high-frequency words expansion method based on LDA. By extracting high-frequency words from each category as the feature space, using LDA to derive latent topics from the corpus, it extends the topic words into the short-text. Extensive experiments conducted on Chinese short messages and news titles show that the new method proposed for Chinese short-text classification can obtain a higher classification performance comparing with the conventional classification methods.
作为一个开放的信息空间,互联网已经成为人们进行信息交互和处理的有效平台,其中以文本形式表示的信息更是以极高的速度增长,而这些文本数据中,有很大一部分是长度很短的文本数据,如微博、短信、博客评论、即时聊天信息、新闻标题、图片标题、问题检索等,都是典型的短文本数据,如何从这海量的短文本中发现有用的信息已经成为信息处理领域亟待解决的关键难点之一。
短文本最大的特点就是文本篇幅较短,通常在80字以内,包含的有效信息较少而且内容相对单一。虽然之前有很多成功的文本挖掘技术被提出,但是它们都是针对长文本数据集的,如博客、新闻等,这些方法也仅在长文本数据集上进行了实验,直接应用这些方法在短文本上会带来非常不好的结果。相对于长文本,短文本在文本处理和分类技术上存在一些问题:
(1)短而稀疏的数据是短文本分类中一个突出问题,这表现在采用传统的背包模型(Bag of Words)进行文本的特征表示时,特征稀疏性问题显得更为严重和突出,使得其分类性能显著下降。
(2)多词同义和一词多义是短文分类另一个突出问题,这表现在相对于长文本,短而稀疏的文本通常噪声影响更大、主题特征更不明显、非常短,从而不能提供足够的共词信息,使得普通的机器学习理论不能获得令人满意的分类准确度。
由上述分析可见,在中文短文本分类中,需要针对其特点对传统的文本分类方法进行优化或重构,以获取具有降噪、主题化以及包含更丰富信息的短文本特征,实现更高性能的分类算法。
为解决短文本分类的特征稀疏和噪声问题,研究者一般通过引入外部语料库或者借助内部语义关联规则等方式进行短文本特征扩展。
Hotho等[ 1]和Pinto等[ 2]分别引入WordNet、MeSH实现了短文本特征扩展,Banerjee等[ 3]采用搜索引擎引入了维基百科外部语料库。这种特征方式往往受外部语料库限制,尤其一些专业性较强、用语习惯比较特定的短文本很难直接应用一般的外部语料库进行扩展。为解决这一问题,Pinto等[ 4]进行了医学领域科技文献摘要的聚类研究,主要采用TPT(Transition Point Technique)、词本义扩展(Self Term Expansion)[ 2]等理论,不仅考虑了与文本关联度较强的词频特征,还采用WordNet本体库(Ontology)提取语义关联的词(Co-related Terms)进行替代,实现短文本特征扩展。
另一方面,采用内部语义关联规则,可以无需借助外部语料库,直接通过建立语料集中词的关联性,从而实现对特征稀疏短文本的特征扩展。Fan等[ 5]从训练语料中提取关联规则,并建立高质量的关联规则库用于特征扩展。但是,采用内部语义关联规则的一个难点是如何选择合适的语义关联,不仅能更好地提高短文本分类性能,还可以降低样本训练和学习的时间开销。
随着相关研究的不断深入,这种丰富短文本语义表达的研究还可以进一步分为以下两类:
(1)基于语义的特征扩展
基于语义的特征扩展一般采取同义词词典或互联网知识。Sahami等[ 6]提出利用Google等搜索引擎为短文本提供更多的上下文信息,然而通过搜索引擎来丰富短文本内容的方法是很难应用到实际场景中的,一方面太耗时,另一方面这种方法太依赖于搜索引擎的质量,其结果往往很不稳定。Hu等[ 7]则提出了利用一个三层架构以同时使用维基百科和WordNet中的知识来丰富短文本特征表达。Phan等[ 8]通过将额外的知识库转换为主题信息以帮助提升短文本的表征效果。另外,也有研究借助文本集内部的语义关联性实现特征扩展。其中,Quan等[ 9]直接利用文本集本身的主题信息,建立不同词在文本间的关联度。然而,这种方法没有直接为每一个短文本建模,只适用于基于距离的分类和聚类算法,如KNN或者K-means等,而对SVM这些对文本分类效率比较高的分类算法是不适用的。
(2)基于主题模型的特征扩展
随着概率主题模型在长文本分类中的成功应用,将概率主题模型应用到短文本分类成为一个新的趋势。由于维数灾难的影响,大部分统计模型在高维数据上都会遇到一定的学习困难,因此对数据进行降维就成为一种很有必要的预处理,其中,主题模型兼具可解释性和高性能降维特点,在文本分类中获得了广泛应用。目前主要的主题模型有LSI[ 10]、PLSI[ 11]以及LDA[ 12]。在主题模型中LDA(Latent Dirichlet Allocation)是一个完全概率生成模型,受到广泛应用。它的基本思想是每个文本都是由多个隐主题混合而成的,而每个隐主题又由多个词混合而成。在文本分类中,研究者大多是直接将LDA应用到文本分类中,其中,Rubin等[ 13]在文档分类中建立了实现一种多标签分类的主题模型,并系统地比较了统计主题模型和判别模型技术的各自优劣。另一方面,研究者也开始采用主题模型对文本特征进行扩展。其中,Phan等[ 8]在基于外部语料库的文本特征扩展中采用了隐主题,Chen等[ 14]在短文本分类中通过多粒度主题模型(Multi-granularity Topics)实现了文本特征拓展和基于不同标签的最优主题选择技术,并在搜索摘要(Search-snippet)中应用了新的特征拓展算法,相较于直接应用LDA特征,取得了更好的分类效果(相对LDA提高了4.14个百分点)。这种概率主题模型的特征扩展方式通过建立词与文档的潜在语义关联,不仅可以用于外部语料库扩展,也可以建立内部语义关联,为短文本分类提供了更多手段。
本文从降低短文本的噪声影响和特征扩展策略入手,提出基于LDA高频词拓展的短文本分类方法。该方法的基本思路是:利用高频词建立短文本的特征空间,利用LDA模型将概率大于某一阈值的隐主题对应的高频词扩展到文本中。最后通过实验验证了该方法的有效性。
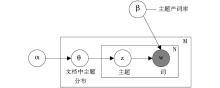
LDA是一种文本集的生成概率模型,其核心思想是文档可以表示为一系列潜主题的随机混合,其中每一个主题都代表了在所对应的文档集中全部词的概率分布,与潜主题相关的词的概率分布较高[ 12]。例如,有三个文档构成的文档集“爸,我一会要上班,现在出门打车”、“上午不在办公室下午再电”、“我在上课,下课给电话你”,采用三个隐主题“工作”、“家庭”、“校园”,文档集中包含的词则为“爸、我、一会、要、上班、现在、出门、打车、上午、不在、办公室、下午、再、电、上课、下课、给、电话、你”。三个文档都可以用“工作”、“家庭”、“校园”三个潜主题的混合比例表示,而每个潜主题又可以用全部词的概率分布表示,其中“工作”主题在“上班、下班、办公室”等词中的概率分布值较高,“校园”主题在“上课、下课”等词中的概率分布值较高。如果有K个潜主题,那么对于一个给定文档的第i个词可以表示为:
其中,zi是潜变量,表示产生第i个词的主题,p(wi|zi=j)表示词wi在第j个主题中的概率,p(zi=j)表示当前文档从主题j中产生一个词的概率,p(zi=j)的值随文档不同而改变。p(w│z)显示一个词在主题中的重要性,而p(z)则显示了那些主题在一个文档中的流行情况。这就正如上文例子中,“工作”主题中 “上班、下班、办公室”等词的概率较高,而文档2中最流行的主题是“工作”。
LDA模型假定文本集D={d1,d2,…,dM}中任意一个文档d={w1,w2,…,wN}的概率生成过程如下[ 12]:.
(1)文档集D中词的总数N服从泊松分布,即N|ξ~Poisson(ξ);
(2)单篇文档中潜主题分布θ服从狄利克雷(Dirichlet)分布,即θ|α~Dir(α);
(3)对于每一个n,n∈{1,…,N},有潜主题Zn服从多元分布,即Zn|θ~Mult(θ);词Wn也服从多元分布,即Wn|{Zn,β1:K}~Mult(βZn)。
其中,ξ、α、β是超参数,ξ对模型的推断与求解没有影响,只是为了表述上的完整,α是一个与文档中主题分布相关的狄利克雷超参数,β是一个与文档集中主题产词概率相关的狄利克雷超参数,一般依据经验提前设定。上述LDA概率生成过程也可以用一个有向概率图表示,如图1所示:
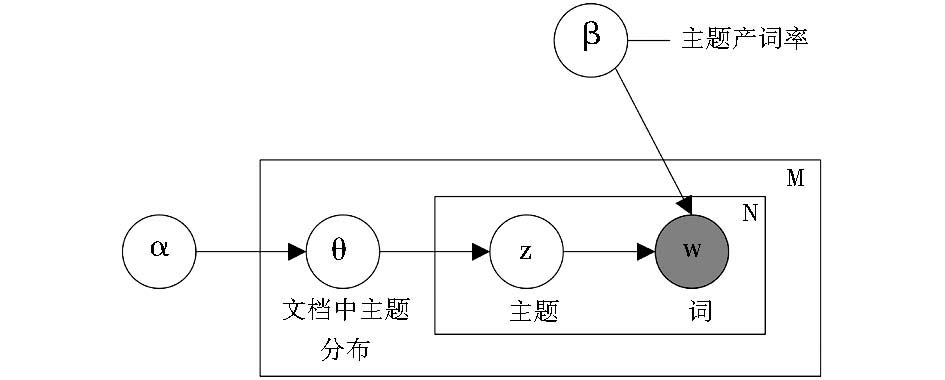 | 图1 LDA有向概率[ 12] |
对一篇短文本进行分词,去除停用词之后,得到一个词向量,每个词都带有词性标记,如名词、形容词、方位词等类型,不同词性对主题表达的贡献程度不同,在中文语料中对主题表达和辨识度作用最大的是动词和名词,所以在词频统计中只考虑这两种词性。
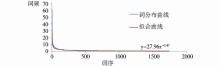
根据Zipf定律,文档的词频分布符合幂律分布。图2是搜狗新闻标题数据集中历史子集的所有词的词频分布图,拟合指数函数y=27.961x-0.479,其中横坐标表示按照词频降序排列的序号,纵坐标表示词频。
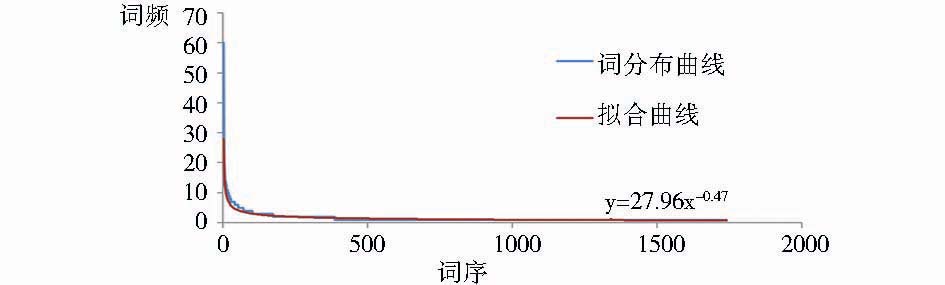 | 图2 搜狗新闻标题中历史子集词频分布 |
通过比较可以发现,高频词对主题的辨识度比较大,低频词对主题的辨识度很低,对类别的辨识度不高的低频词,如果将其加入到词典中,不仅对分类效果帮助不大,反而会增加短文本的噪声,降低分类的效率。因此,本文对短文本进行去停用词等预处理后,抽取分类贡献较大的高频特征,滤掉噪声和冗余的低频特征。特征提取算法步骤如下:
(1)文本预处理,分词、去停用词;
(2)采用Sogou字典进行词性处理,保留名词和动词;
(3)对每个类别,抽取相同比率的高频特征词;
(4)合并抽取的所有类的高频词,假定总数为n;
(5)用新提取的特征对文档进行表征:V(d)=(w1,w2,…,wn),V(d)的每个分量表示对应特征在该篇文档中的权值;
(6)采用TF-IDF计算新特征的权值,词条ti在文档d中权值定义为: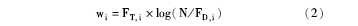
其中,FT,i是词条ti在文档d中出现的频数;N表示全部训练文档的总数;FD,i表示包含词条ti的文档频数。
在提取高频特征后,本文提出了一种新的基于LDA的高频词扩展算法,以解决短文本的特征稀疏问题,具体算法如下:
输入:主题高频词集S,文档-主题分布概率矩阵M。主题概率抽取阈值C,主题词数抽取阈值K,待测短文本文档;
输出:特征扩展后的短文本特征向量空间。
①对于待测短文本d,查找对应的主题分布θd,如果短文本d在主题i中的概率θdi大于阈值C,则提取主题高频词集Si中概率在前K的主题词,执行步骤②,否则执行步骤③;
②对Si中已经提取的K个主题词进行遍历,如果主题词wij在文档d中出现,则wij不加入特征空间列表,否则计算wij的权重weightj,将其加入到特征空间列表;
③如果短文本在所有主题中分布的概率均小于阈值C,执行步骤④;
④该短文本特征不进行扩展,继续查询下一个短文本的主题概率分布。
采用上述算法可以得到扩展的LDA主题词,其中新扩展的主题词权重的计算采用了Griffths等[ 15]的塌陷吉布斯方法,公式如下: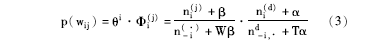
其中,p(wij)是wij的权重weightj,α、β是LDA超参数,分别是变量θ、Φ的先验参数,n(·)-i是不包括当前分配的其余所有将主题j分配给词wi的次数,公式(3)第一部分的比率代表了在主题j中词wi的概率,第二部分比率代表了在文档di中主题j的概率。
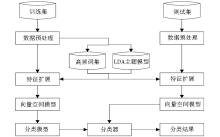
得到短文本的LDA高频特征向量后,可以采用支持向量机(Support Vector Machine, SVM)对短文本数据集进行训练和测试。本文的中文短文本分类算法框架如图3所示:
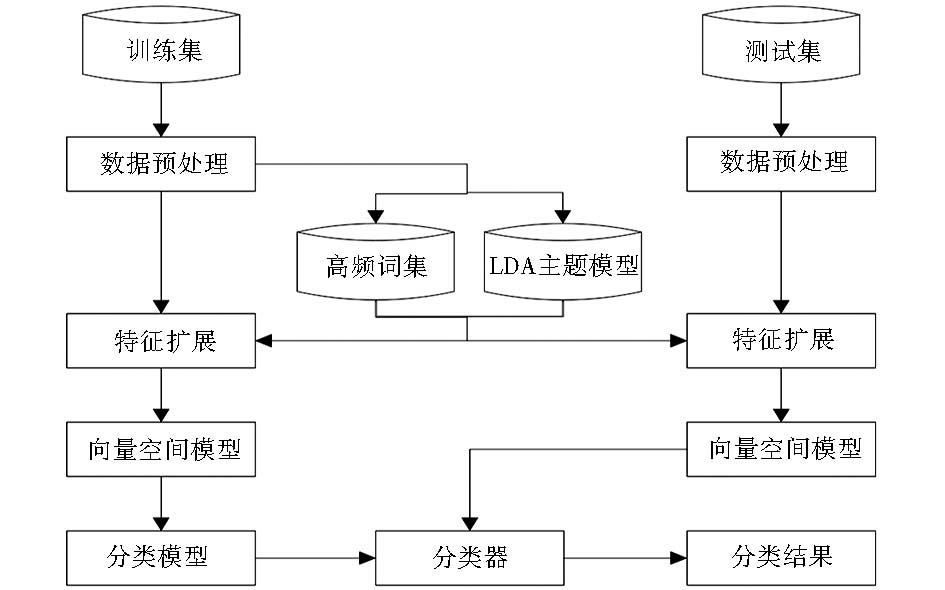 | 图3 短文本分类算法框架 |
整个算法由4部分组成:采用3.2节的特征提取方式提取训练集短文本的高频特征;采用3.3节的LDA特征扩展算法实现训练集短文本的LDA主题特征扩展;采用上述算法实现对测试数据集的高频特征提取以及主题特征扩展;应用 SVM 训练分类器,并用于测试集的预测。
实验数据来源于搜狗实验室提供的新闻语料集,从中抽取这些新闻的标题作为实验数据。一共抽取了10 953个标题,分为文化、社会、娱乐、历史、军事和阅读共6个类别,每个标题的长度大概在10-20个字之间,属于短文本数据。按9:1分为训练集和测试集,数据集分布情况如表1所示:
| 表1 新闻标题数据集各类别分布 |
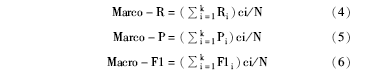
其中,N表示文本的总数,ci表示类别i的文本数量,由于各个类别的文本数量不同,所以本文采用的是加权平均的方法。
(1)提取高频词
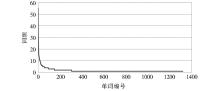
新闻标题数据集经过中国科学院计算技术研究所汉语词法分词系统ICTCLAS进行分词,由于名词和动词对主题的辨识作用比较大,所以只提取其中的名词和动词,并去除停用词。对每一类别的文本进行词频统计,得到每一类的词语列表,将列表按词频排序,取历史类新闻标题为例,如图4所示,可以看到,该列表具有长尾特征,即绝大多数的词只出现了很少的次数,只有少数词语出现频率较高。
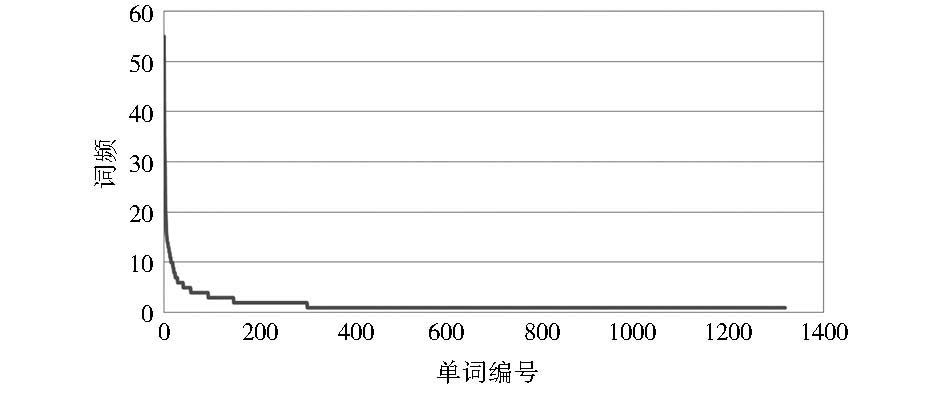 | 图4 历史类新闻标题词语列表 |
比较词频排在前10位的词语和词频排在最后10位的词语,如表2所示:
| 表2 出现频率排在前10和后10的词汇 |
从表2可以发现,高频词对主题的辨识度比较高;低频词对主题的辨识度很低,并且低频词在所有词汇中占据了很大的比例,如果将其加入到词典中,不仅对分类效果帮助不大,反而会增加短文本的噪声,降低分类的效率。
(2)不同特征词抽取方法分类性能的比较
①高频词特征提取。本文按比例分别抽取词频在前10%、20%、30%、40%、50%和全部的词语作为特征词空间,用TF-IDF方法将短文本表示成向量,以SVM作为分类器,文档未经过特征扩展,进行5轮6类短文本分类实验。
②CHI特征提取。同样的,本文采用CHI方法对短文本进行特征选择,选择的特征数与高频词方法5轮实验的特征数一致。
两种特征提取方法的对比如图5所示:
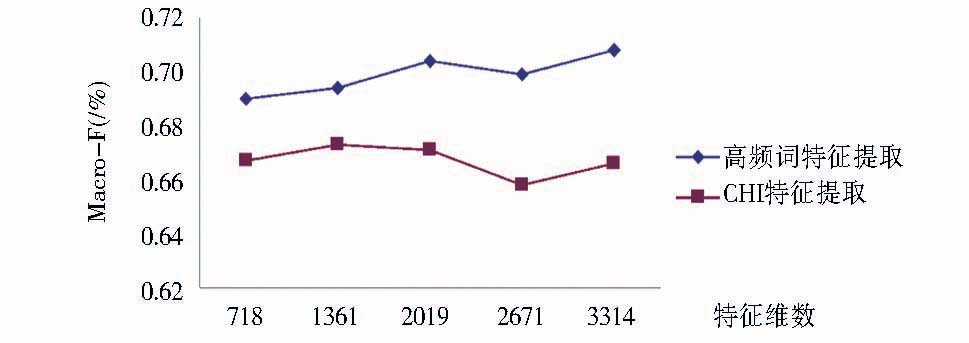 | 图5 基于Sogou新闻数据的短文本特征提取性能对比 (注:作为对比实验,只使用了本文搜狗标题中3 327个标题进行分析。) |
观察图5中的曲线,可以得出如下结论:
①高频词方法抽取特征与常规CHI方法抽取同样数目的特征在短文本分类性能比较上,高频词方法各项性能指标均比常规方法高,说明高频词方法抽取的特征比CHI方法的类别辨识度更强,有助于分类性能的提高。
②观察图5中高频词的曲线可以看出,随着特征数的增加,分类性能虽然有所提高,但是提升的幅度很小,有时甚至有所下降,以特征数为2 019和2 671为例,随着特征数增加,分类性能反而下降。这说明,引入的特征可能带有很多噪声,对分类性能造成了影响。
通过上述高频词实验,采用表1的10 953个搜狗标题数据集,对比分析本文提出的两种分类算法——未扩展的高频词算法和LDA扩展后的高频词算法,用于分析本研究LDA特征扩展算法的有效性。详细数据如表3所示:
| 表3 基于LDA高频词扩展对分类性能的影响分析(特征维度:1 113,%) |
为综合评价本文提出的分类算法的性能,本文在搜狗标题和短信数据集中对比分析了LDA高频特征扩展算法与其他经典算法的分类性能。另外,还对比分析了本文算法在英文数据集Yahoo问答上的分类性能,如表4所示:
| 表4 几种不同分类方法在三个数据集中的分类性能(Macro-F1) |
(1)在中文短文本分类中,本文的分类算法相对经典的LDA[ 12]有显著提升,相对改进的用于文本分类的sLDA[ 17]算法也有显著改善,与经典的文本分类算法MaxEnt(Maximum Entropy)[ 18]相比有明显优势,相对未提取高频特征、直接使用全部特征的基于TF-IDF的SVM分类算法也有明显改善。这表明,本文算法有效地解决了中文短文本的去噪和特征稀疏两个问题。
(2)本文算法在英文短文本分类中,相对其他算法性能也有改善,但幅度不大,尤其是去噪方面性能没有中文短文本分类中显著。
本文研究了如何利用LDA和高频词为短文本特征进行扩展,基于短文本存在特征少、噪声大等问题,提出了利用LDA高频词扩展进行短文本分类的整体框架,并通过实验验证了这种方法对短文本分类的有效性,得到如下结论:
(1)各个类别的高频词对短文本类别的辨识度比较高,提取高频词作为类别特征有利于降低噪声;
(2)利用LDA将高频词引入短文本可以提高分类性能;
(3)本文的LDA特征扩展算法也可以应用到英文短文本分类中。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|