{kind=link}
{kind=link}
{kind=link}
跨领域迁移学习产品评论情感分析
[张志武 ]
]
]
|
|


针对不完备数据的产品评论情感分析问题,提出基于谱聚类的跨领域迁移学习情感分析方法。将领域无关的词语作为桥梁,通过谱聚类算法把不同领域的领域相关词语排列到统一的聚类中,减少源领域和目标领域的领域相关词语间的差异,提高情感分类器在目标领域的分类准确率。实验结果验证该方法在解决跨领域产品评论情感分析问题上的有效性和优越性。
Aiming at the problem of sentiment analysis of incomplete product reviews data, this paper proposes a cross-domain sentiment analysis method based on spectral clustering and transfer learning. With the help of domain-independent words as a bridge, using spectral clustering algorithm to align domain-specific words from different domains into unified clusters, it can reduce the gap between domain-specific words of the two domains, and can improve the accuracy of sentiment classifiers in the target domain. Experiments studies are carried out to show the efficiency and superiority of the proposed approach in solving the problem of cross-domain sentiment analysis of product reviews.
随着Web2.0的盛行,网络上产生了越来越多的用户情感数据,它们以购物网站的用户评论、博客文章和客户反馈等形式存在[ 1]。网络评论已经成为人们日常生活的重要组成部分,如何从这些海量的评论数据中挖掘出用户的情感倾向等有价值的信息已成为研究人员关注的课题。情感分析(Sentiment Analysis)是挖掘这些重要信息的一个基本方法,情感分析又称评论挖掘或意见挖掘,是指通过自动分析某种产品评论的文本内容,发现消费者对该产品的褒贬态度和意见。产品评论信息的挖掘与分析不仅能够为消费者的购买决策提供支持,也便于销售商和生产商直接获取消费者对其自身产品及同类产品的反馈信息,从而改进产品和服务质量,制定更有针对性的营销计划[ 2]。
在产品日新月异的背景下,产品评论情感分类面临越来越多的新产品领域的倾向性分析问题,通常这些产品领域已标注评论稀少甚至没有已标注评论,利用传统的统计学习方法进行情感分析往往效果较差,而网络中存在大量其他相关产品领域已经标注好的评论数据,如何将这部分数据迁移到标注样本稀少的新产品领域,进而对新产品的情感倾向性进行分析即跨领域情感分析,这样的任务被称为迁移式分类任务[ 3],是本文的主要研究内容。
针对上述不完备数据的情感分析的应用背景,本文引入迁移学习机制,根据基于特征的迁移策略,将领域无关的词语作为桥梁,构建领域相关词语与领域无关词语之间共现关系的双向图,在双向图上使用谱聚类算法构建源领域和目标领域的特征聚类集合,使用Logistic回归模型进行分类识别。选择来自Amazon电子商务网站上的产品评论信息作为研究对象,设计无迁移方法和领域内分类方法以及Blitzer等[ 4]提出的结构对应学习(Structural Correspondence Learning, SCL)算法作为对比实验,以验证本文方法在解决跨领域情感分类问题上的有效性和优越性。
国内外学者对单个领域的产品评论情感分析的研究非常广泛,处理方法也相对成熟,但是对跨领域的产品评论情感分析的研究相对较少。近年来,研究者逐渐开始利用迁移学习的方法对跨领域的产品评论进行情感分析。Blitzer等[ 4]将结构对应学习(SCL)引入跨领域情感分析,SCL是一种应用范围很广的特征迁移算法,其目的是通过枢轴特征将训练集上的特征尽量对应到测试集中,通过特征的映射构建目标领域与源领域之间的桥梁。Tan等[ 5]将基于最大期望算法的朴素贝叶斯半监督学习方法应用到跨领域的情感分析中,通过频繁共现熵构建特征空间,将源领域与目标领域的样本表示在一个共同的样本空间中,使用最大期望算法构造自适应朴素贝叶斯。 Pan等[ 6]提出谱特征重排(Spectral Feature Alignment, SFA)算法,根据源领域与目标领域的词语的共现信息构建共现矩阵,通过对共现矩阵进行矩阵变换,构建两个领域的公共特征空间,实现情感分类的特征迁移。Tan等[ 7]提出利用源领域的标注数据训练分类器,对目标领域的未标注数据标注伪标签,然后根据样本数据与类别质心的距离,挑选最有代表性的样本添加标签,作为训练样本添加到训练集中训练分类器。杨文让等[ 8]在其思想的基础上提出质心迁移的算法:在挑选可信度高的目标领域样本作为训练样本的同时,根据源领域样本到目标领域类别质心的距离动态地删除离目标领域较远的源领域数据,以减少训练样本中的领域差距,从而提高不同领域间的情感分类的精度。张慧等[ 9]提出一种基于评价对象类别的跨领域学习方法,将评价对象分为4大类:整体、硬件、软件和服务,人工标注源领域中属于4类评价对象的句子,并构建评价对象类别分类器,将不同的评价对象类别当作不同的视图,使用协同训练进行跨领域情感分类。张莉[ 10]提出基于词典资源和有监督机器学习的两种跨领域中文评论情感分类方法,探讨了跨领域中文评论在算法上与单一领域的异同。
在情感分析中,源领域与目标领域的学习任务一般都是相同的,即二元或多分类问题,属于归纳式迁移学习及直推式迁移学习。目前采用的主要迁移方式是特征迁移、样本迁移,对参数和关联知识的寻找一般都是通过半监督的方式进行迭代拟合。通过对之前研究成果的学习,笔者最终选择基于特征的迁移策略来对产品评论的情感分析进行研究。
在产品评论中进行情感分析,即在大规模产品评论中,分析带有主观评价的句子,并判断其中所传递的对于产品的褒贬态度。一个跨领域情感分析的实例如表1所示:
| 表1 跨领域情感分析实例:电子产品和视频游戏产品评论 |
对于跨领域迁移学习的情感分类问题描述如下:
给定特定的源领域Dsrc和目标领域Dtar,假设已有源领域的有标记的情感数据集合为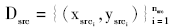 ,目标领域部分无标记情感数据为
,目标领域部分无标记情感数据为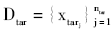 ,其中,x表示情感文本,y表示相应的情感褒贬态度(+1表示褒义,-1表示贬义)。于是,跨领域迁移学习的情感分析问题就是学习一个准确的分类器来预测目标领域中未知情感数据的褒贬态度。假设情感分类器是一个线性函数y*=f(x)=sgn(xwT),当xwT≥0时sgn(xwT)=+1,否则sgn(xwT)=-1,这里的w是分类器权重向量,它能够从训练数据中学到。
,其中,x表示情感文本,y表示相应的情感褒贬态度(+1表示褒义,-1表示贬义)。于是,跨领域迁移学习的情感分析问题就是学习一个准确的分类器来预测目标领域中未知情感数据的褒贬态度。假设情感分类器是一个线性函数y*=f(x)=sgn(xwT),当xwT≥0时sgn(xwT)=+1,否则sgn(xwT)=-1,这里的w是分类器权重向量,它能够从训练数据中学到。
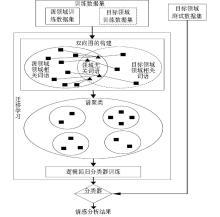
跨领域迁移学习的产品评论情感分析算法框架如图1所示,其中虚线框表示目标领域已标注产品评论稀少或者是没有已标注的评论。
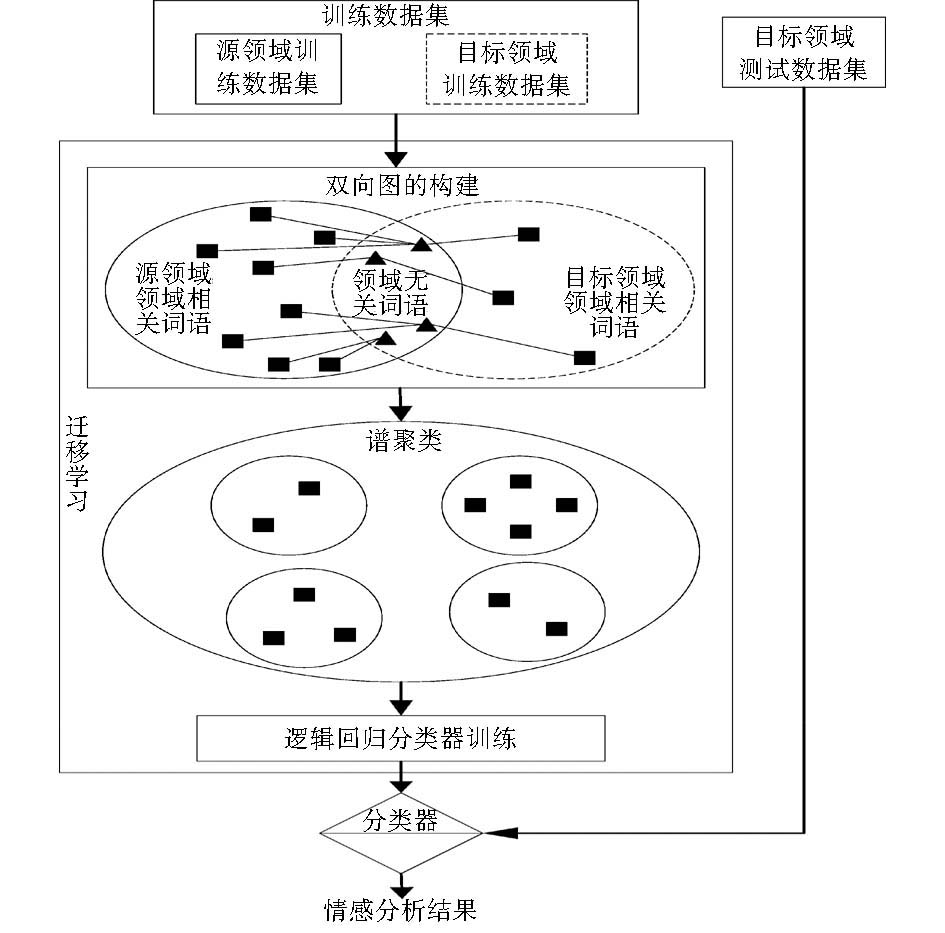 | 图1 基于跨领域迁移学习的情感分析算法框架 |
(1)在训练数据集上运用分词技术进行文本预处理,利用两个领域上词语出现的概率提取领域无关的词语和领域相关词语;
(2)利用领域无关词语与领域相关词语的共现关系,构建双向特征图;
(3)在已构建的双向特征图上利用谱聚类算法进行领域相关词语的聚类划分;
(4)在已形成的聚类上,运用逻辑回归分类器进行训练,得到适合跨领域迁移学习的情感分类器,情感分析的测试阶段就可以使用目标领域的测试数据在情感分类器上直接分类,输出结果就是情感分析结果。
根据图1中跨领域迁移学习的产品评论情感分析算法流程,本文将其分为5个模块:输入数据预处理、领域无关词语提取、双向特征图构建、谱聚类和情感分类器训练。其中,输入数据预处理部分已有很多成熟的文本处理方法,在此不再赘述。
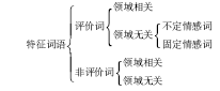
虽然目标领域与源领域的特征词汇空间不一致,但是仍有部分词语是二者共有的,因此可以将领域特征词分为领域相关词语和领域无关词语。领域相关词语即领域独有的词语,领域无关的词语则是每个领域都可能有的词语。对于情感分类领域,特征词语又可分为具有情感指示作用的评价词和没有情感指示作用的非评价词。同时由于评价对象的不同,评价词可能会导致情感倾向不同。情感倾向固定的评价词被称为固定情感词,情感倾向不确定的词被称为不定情感词,对于情感分类问题来说,评价词起着至关重要的作用。具体分类如图2所示:
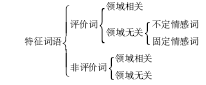 | 图2 情感分类中的特征词语分类 |
领域无关的特征词语对领域的依赖性小,具有全局意义,应该频繁出现在源领域和目标领域且起到相似作用,可以利用领域相关度对其进行度量。计算领域相关度的方法很多,可以通过统计特征词语在各个领域中出现的频率来判断,由于其简洁有效的特点,本文采用该策略来提取领域无关词语。具体做法是:给定l个领域无关的候选词语,选择在源领域和目标领域共同出现超过k次的词语作为要提取的领域无关词语。
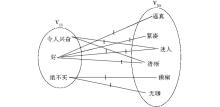
提取领域无关词语后,就可以得到相应的领域相关的词语。给定领域无关和领域相关的词语,可以在它们之间构造一个双向图G=(VDS∪VDI,E)。在图G中,VDS中的每一个顶点对应一个领域相关的词语,VDI中的每一个顶点对应一个领域无关的词语,E中的边分别连接VDS和VDI中的一个顶点,E中的每一条边eij对应一个非负权重mij,它的值度量了对应顶点上词语的关系(如共同出现的次数)[ 6]。利用已构建的双向图可以建立领域相关和领域无关词语间的内在关系模型,在表1实例上构建的双向图如图3所示:
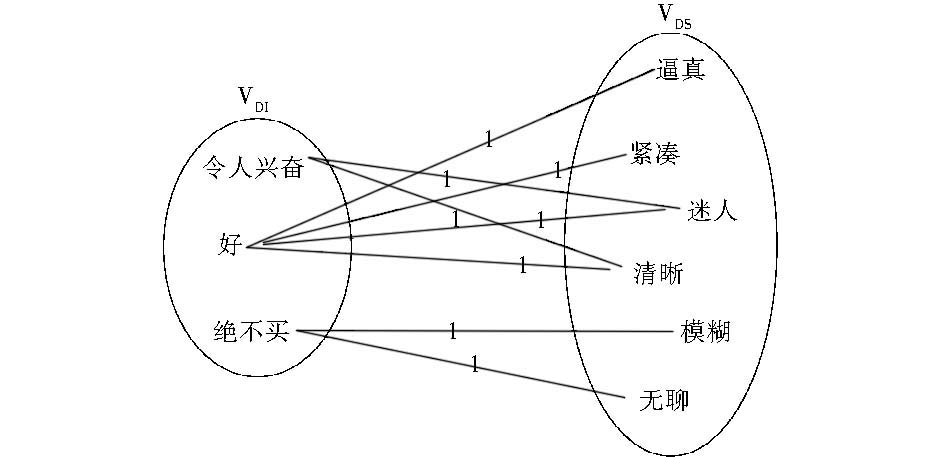 | 图3 对应于表1的领域相关和领域无关词语的双向图 |
在图谱理论中,有两个假设:如果图中两个点都与很多共同的点相连,那么它们应该是相似的(或者非常相关);在复杂图中存在一个低维潜在空间,如果两个点在原始空间中相似,那么它们在这个低维空间中也相似。基于这两个假设,谱图理论被广泛地应用到维度约减和聚类中[ 11]。在本文中,假设:
(1)如果两个领域相关的词语都共同连接到很多领域无关的词语上,它们往往是很相关的,将很可能被分配到同一个聚类中;
(2)如果两个领域无关的词语都共同连接到很多领域相关的词语上,它们往往是很相关的,将很可能被分配到同一个聚类中;
(3)可以找到一个更紧凑而有意义的领域相关的词语的表示,它能够减少领域间的差异。
因此,基于以上假设,通过在特征双向图上使用图谱技术发现一个新的领域相关的词语的表示,能够缓解领域相关的词语间的不匹配问题。
本文采用的谱聚类算法描述如下(假设要分为k个类):
①对于给定的n个顶点的双向图G=(VDS∪VDI,E),计算图的带权邻接矩阵W∈Rn×n,这里如果i≠j,Wij=mij,否则Wij=0;
②计算对角矩阵D,其中Dii=∑jWij,构建图的拉普拉斯矩阵L=D-1/2WD-1/2;
③计算L的前k个最大特征值对应的特征向量u1,u2,…,uk,构建矩阵U=[u1u2…uk]∈Rn×k;
④标准化U,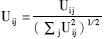
⑤在U上使用K-means算法,把n个点聚类到k个聚类中。
在聚类上得到领域相关词语的新表示后,迁移学习就可以在源领域和目标领域潜在的子空间上进行,即训练跨领域情感分类器。在情感分类阶段,本文采用逻辑回归作为情感分类器。逻辑回归是利用概率估计来进行分类的。考虑具有p个独立变量的向量x′=(x1,x2…,xp),设条件概率P(yx)为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为: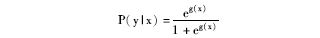
其中,g(x)=β0+β1x1+β2x2+…+βpxp,在分类的情形下,经过学习之后的逻辑回归分类器就是一组权值β0,β1…,βp。由于模型函数的值域为(0,1),因此最基本的逻辑回归分类器适合于对情感分析这样的两类目标进行分类[ 12]。
实验数据采用Blitzer等[ 4]收集的来自Amazon电子商务网站上的产品评论数据,这些评论来自4个领域:书籍(B)、DVD光盘(D)、电子产品(E)和厨房用具(K)。根据评论者的评分,给每一个评论分配一个情感标记:-1(表示贬义评论)或+1(表示褒义评论)。每一个领域有1 000个褒义评论和1 000个贬义评论。
为了验证方法的有效性,在以上数据基础上构造12个跨领域情感分析任务方案:D→B,E→B,K→B,K→E,D→E,B→E,B→D,K→D,E→D,B→K,D→K,E→K,这里箭头前的字母表示源领域,箭头后的字母表示目标领域。并与无迁移方法、领域内分类方法和SCL方法进行对比分析,这里无迁移方法是指直接用源领域作为训练数据进行分类器训练,然后直接应用在目标领域进行情感分类;领域内分类方法是指用目标领域数据作为训练数据在领域内进行分类器训练学习。例如:对于任务D→B,无迁移方法是指利用领域D中的有标记数据进行分类器训练,然后在领域B上进行分类;领域内分类器是指从领域B的有标记数据进行分类器训练,然后在领域B上进行分类。在实验过程中,本文随机地把每一领域数据划分成两部分,一部分是从数据集中随机抽取1 600个实例作为训练集,剩余的400个实例作为测试集。为保证对比实验的一致性,采用准确率评价情感分析结果。
4种分类方法在12个情感分析任务上的对比结果如表2所示,其中SCL方法的实验数据来自于文献[4]。
| 表2 情感分析比较结果 |
(1)对于迁移任务“E→K”和“K→E”,4种比较方法的准确率都很高,其中本文的方法优于SCL方法,这是因为源领域和目标领域相近,情感词的使用差异较小,迁移学习效果明显。因此,在迁移学习时,源领域的选择应尽可能地接近目标领域。
(2)对于迁移任务“B→E”,本文方法相对于无迁移方法的分类准确率提高不明显,并且比SCL方法效果差,这是由于领域不同,情感词的用法和使用频率的差异使迁移的源领域样本妨碍了目标领域的分类任务,也就是负迁移问题。
(3)从表2中可以看出,4个领域大致可分成两组:领域B和D彼此相似,领域K和E彼此相似,但这两组又彼此不同。从领域K迁移到领域E比从领域B迁移到领域E容易。对于跨领域情感分析问题,使用谱聚类技术可以为领域相关的词语找到有意义的聚类。
(4)迁移学习情感分析主要针对不完备数据的应用背景,解决目标领域无评论数据或评论数据稀少的问题。从实验结果看,迁移学习的方法整体比不使用迁移学习直接进行情感分析的效果好,但相对于领域内的情感分析方法,跨领域的迁移学习情感分析方法的分类效果较差,这说明迁移学习可以缩小不同领域间差异,但不能完全消除这种差异。
本文提出一种跨领域迁移学习的情感分类方法,用于对网络产品评论进行情感分析。通过建立领域无关的词语和领域相关的词语之间的双向图,在领域无关的词语的桥梁作用下,在双向图上使用谱聚类算法,生成新的更有意义的聚类,新的聚类能缩小两个领域相关词语间的差距,从而使得跨领域的迁移学习能在目标领域上训练出一个准确的分类器。在真实数据上的实验表明基于跨领域迁移学习的情感分析是可行的,且在评价指标上更具优势。未来的研究工作将在通过互信息选择领域无关的词语方面和采用半监督学习方法从双向图上学习领域相关的词语的更合理的聚类以及如何根据分类任务选择源领域方面展开。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|