基于条件随机场的网民评论对象识别研究*
[林琛1, 2  , 王兰成
, 王兰成1 ]
, 王兰成|
|


在分析网民评论对象特点基础上,提出一种基于条件随机场的网民评论对象识别方法。该方法无需引入任何领域知识,通过引入字级特征、特征词(字)特征、线索词(字)特征,利用条件随机场模型将网民评论对象识别问题转化为最大概率序列求解。实验结果表明,该方法具有较高的识别性能,能够完整、有效地提取网民评论中的评论对象。
Combined with the characteristic of comment object, this paper gives an identification method based on conditional random fields. Without domain knowledge, the new method introduces characteristics word and clues word, then transforms comment object recognition problem into solving maximum probability sequence. The experimental results show that this method can completely, effectively extract comment objects from network comments.
随着网民对社会和民生问题的不断关注,互联网已经成为人们发布意见的聚集地,网络词语表达的意义已经远远超出了词语本身的含义,成为网民对社会问题、社会事件态度的代名词。近年来,盛行的各类网络热词无不表达了网民参与社会活动的自我态度。
网民评论是网民意见表达最直接的载体。网民评论对象包含在网民评论中,是网民参与社会热点问题、热点事件讨论时其态度的指向对象,有效识别其中的评论对象能够帮助人们迅速获取网民意见指向,对有效引导舆情具有重要作用。
目前,网民评论对象识别的针对性研究并不多见。与之直接相关的技术方法主要来自产品评价对象识别领域。产品评价对象识别任务是找出产品评论中作者所评价的产品特征,包括产品名称、产品组成元件以及其他相关属性。例如,汽车产品评论中,评论对象包括汽车品牌、汽车型号以及汽车外观、颜色、性能、油耗等属性,还包括发动机、空调、音响等元件。产品评价对象识别方法主要有两类,即无监督识别方法和有监督识别方法。
(1)无监督识别方法主要结合种子特征集合、启发式规则或上下文语义线索等对产品评论进行分析,从中抽取评价对象。Hu等[ 1]根据候选对象的同现率识别评价对象,还通过词语之间位置距离来发现非常见对象,其结构简单且具有较好的移植性。Popescu等[ 2]通过计算名词短语与特定鉴别短语之间的PMI值对名词短语进行评估。刘鸿宇等[ 3]使用句法分析结果获得候选评价对象,然后结合PMI 算法和名词剪枝算法对候选评价对象进行筛选获取最终结果。徐叶强等[ 4]在制定一组词性规则的基础上,对评价对象非完整性、非稳定性等情况进行过滤,利用置信度及扩充规则来确定评价对象。Yi等[ 5]根据名词短语的组成和位置特点设定的启发式模式,利用设定模式对产品评论中的对象进行抽取,并利用两种相似度测试方法确定最终评价对象。无监督识别方法存在一定的局限性,适合处理语法规范且评价词与评价对象距离较近的句子。
(2)有监督识别方法是在人工标注训练语料条件下,基于统计学习方法训练构建识别模型,进而利用该模型自动识别产品特征。刘非凡等[ 6]结合知识库、启发式规则,利用层级隐马尔可夫模型,综合运用内部和外部的词汇、语法、语义等各个层次的上下文特征进行统计消歧,从而确定产品特征。Zhang等[ 7]采用条件随机场模型, 在模型训练中选择词级特征,并引入领域词典的知识对产品属性进行抽取。徐冰等[ 8]在条件随机场模型训练过程中通过浅层句法分析引入浅层句法信息,通过情感词表引入启发式位置信息,有效地提高了识别的准确率。与无监督方法相比,虽然有监督识别方法需要人工标注语料,但具有更高的性能和实用性。
鉴于网民评论对象识别与产品评价对象识别都是面向网络评论文本,且二者识别目标一致,即获得被评论的对象。因此,可考虑借鉴产品评价对象识别的思路方法。但网民评论对象有其自身的特点,对其识别需要结合其特点进行。
条件随机场(Conditional Random Fields, CRFs)模型的基本思想是通过依赖于少数变量的局部函数的乘积来表示一个依赖于大量随机变量的概率分布。CRFs是Lafferty等[ 9]在最大熵模型和隐马尔可夫模型(Hidden Markov Model, HMM)的基础上,提出一种判别式无向图学习模型。
HMM为产生性预测模型,该类模型中为保证推导的正确性,做出了严格的独立性假设。而事实上大多数序列元素不能被表示成一系列无关联的元素。CRFs在保留HMM的一些特性下,考虑了序列元素之间的相关性,它可以容纳任意上下文信息,同时由于CRFs计算全局最优输出节点的条件概率,它还克服了最大熵马尔可夫模型标记偏置的缺点。
线性链CRFs是一种最常用的图结构,其输出变量被连接成一条线性链且存在马尔可夫独立性假设。假设o={o1,o2,…,on},s={s1,s2,…,sn}分别为观察序列和有限状态集合,则线性链CRFs条件概率可以表示为[ 10]: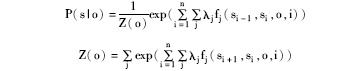
fj(si-1,si,o,i)为特征函数,通常为二值函数,取值非0即1;λj为特征函数的权值,Z(o)为归一化因子。
网民评论对象不同于产品评价对象,产品评价对象具有领域局限性,对象的表述相对稳定。网民评论对象来源于网民对社会不同领域产生的热点问题和热点事件的评论,加之网民丰富的联想能力,使得网民评论对象很大一部分是网络新造词语。这些评论对象在中文分词处理时很容易被错误切分成碎片,如“逃跑老师范美忠”事件中评论对象“范跑跑”被切分为“范/nrl跑/v跑/v”。另外,一些非实体评论对象,尤其是名词短语或动词短语,如“央视停播NBA”事件中评论对象“停播NBA”,由于分词并不以评论对象为单元进行识别切分,所以虽然分词正确但仍造成评论对象被碎片化。上述情况极大影响了评论对象识别结果的准确性和完整性。
笔者引入CRFs对网民评论对象进行识别,即将网民评论对象识别问题转化为最大概率序列求解问题。采用CRFs的优点在于它可以对互相关联的多变量进行建模,即可以引入多维特征,而无需考虑这些特征之间是否保持独立。基于CRFs的网民评论对象识别算法输入为利用分词、词性标注和常规命名实体识别输出的分词串,输出为识别出来的网民评论对象。本文采用中国科学院计算技术研究所分词系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)[ 11],它集分词、词性标注、命名实体识别与一体(以下统称为分词)。算法主要组成部分如下:
(1)特征函数选取是模型构建的关键环节,直接影响所构建模型的识别性能。在分析网民评论对象特点的基础上,引入词(字)的自身特征和上下文特征来完成对特征函数fj(si-1,si,o,i)的选取。
(2)特征函数权重估计是计算各特征函数fj(si-1,si,o,i)的权重λj,该过程为CRFs模型的训练过程。CRFs训练过程通常利用最大似然法则,以迭代的方式获取特征函数的权重。
(3)评论对象识别过程是已知分词串组成的观察序列o={o1,o2,…,on},求解该条件下最大概率的状态序列s={s1,s2,…,sn},该过程为CRFs模型的识别过程。
网民评论对象的构成非常复杂,在类型上既可能包含实体对象,又可能包含非实体对象。无论实体对象还是非实体对象,识别是否为网民评论对象来自两部分信息:词(字)自身对评论对象的表征能力和上下文语言环境对评论对象的表征能力。本文在将产品评价对象识别中常用的词、词性、上下文信息作为特征函数的基础上,考虑到网民评论对象特点,引入字级特征、特征词(字)、线索词(字)作为特征函数。本文考虑选取的所有特征函数如表1所示:
| 表1 特征选取 |
(2)词(字)的词性:网民评论对象的类型多种多样,除了名词、名词短语,还可能是动词、动词短语,因此词(字)的词性对表征评论对象具有重要贡献。
(3)词(字)是否为特征词(字):特征词(字)是指词(字)在网民评论的分词结果里是否被标注为人名、地名和机构名这三类命名实体的词或字。通过对大量语料的观察,上述三类实体在评论中出现时通常被作为评论对象,所以特征词(字)本身携带了大量的评论对象信息。
(4)词(字)前后三个词(字)中是否包含线索词:线索词(字)是指与网民评论对象距离较近的形容词或者副词。根据统计,语料中副词或者形容词周围存在评论对象的比例为30%,因此形容词或者副词对表征评论对象起到指示作用。如“大部分老师认为范美忠言论不当”的分词结果为“大部分/m老师/n认为/v范/nrl美/b忠言/n论/v不当/a”。
(5)上下文信息:上下文信息对表征评论对象具有重要作用,本文考虑当前词(字)前后两个词(字)及它们的词性和是否为特征词(字)。
由于领域研究起步较晚,目前还没有统一的网民评论语料库,需要人工进行语料标注。本文实验数据来源于2012年1月到12月强国论坛、网易新闻评论网站,共选取了“王立军事件”、“钓鱼岛事件”、“莫言获得诺贝尔奖”、“方舟子与韩寒骂战”以及“中国首艘航母”5个话题的网民评论。实验利用网络爬虫从网站中爬取上述主题的网页并自动抽取网民评论4 822条,去除无文字和文字数小于2的评论后剩余3 155条。
为了对算法性能进行封闭和开放两种测试,将5个话题数据分为封闭实验语料和开放实验语料两份。实验数据具体如表2所示:
| 表2 实验数据 |
其中,封闭实验样本采用ICTCLAS进行分词,在此基础上对样本进行BIO标注,B为评论对象的开始,I为评论对象的内部,O为其他无关项。此外,为了测试算法在真实语言环境中的性能,开放实验样本中既包括含有评论对象的网民评论,同时也包括部分不含有评论对象的网民评论。
在算法性能评估上,实验使用准确率(Precision)、召回率(Recall)和F-Measure作为评价指标,公式如下:
其中,“人工标注数目”是人工标注的结果,“模型标注数目”是本文实验的结果,“匹配标注数目”是模型标注数目在人工标注中匹配的样本个数。
(1)实验1:鉴于封闭实验语料库大小,把每个话题的封闭实验语料随机均分为5份,其中4份作为训练集,1份作为测试集,完成5次交叉验证最终得到封闭测试结果。进而利用封闭实验训练获得模型,在开放实验语料上进行算法性能的开放性测试。两部分实验结果如表3所示:
| 表3 实验结果1 |
此外,开放实验结果要明显低于封闭实验结果,笔者分析错误识别结果,发现其中主要原因在于:之前为了方便实验语料的标注,在标注过程中忽略了分词结果中部分错误信息,当模型处理开放实验语料时,性能受到了分词错误带来的影响。因此,如何避免或者减少分词对识别结果的影响是下一步工作的主要方向。
目前,网民评论对象识别未发现有直接的针对性研究,为了验证算法的有效性,选取相关研究论文中引用频次最高的频繁特征识别方法[ 1]作为Baseline系统。在封闭实验语料上进行测试,Baseline系统平均召回率为68.42%,平均准确率为60.20%。可见,本文算法性能要远高于Baseline系统的性能。
(2)实验2:为了验证不同特征的引入对算法识别性能的影响,话题1和话题5封闭实验语料上不同特征选取下识别算法的性能如表4所示:
| 表4 实验结果2 |
(3)实验3:为了验证算法在实际使用中的有效性,实验循环将4个话题的封闭实验语料作为训练数据,对剩余一个话题语料中评论对象进行识别。实验结果如表5所示:
| 表5 实验结果3 |
网民评论对象是网民意见的具体指向,有效识别网民评论对象对针对性引导网络舆情具有重要意义。目前,网民评论对象识别研究并不多见,本文借鉴产品评价对象识别思路,对网民评论对象识别进行有效尝试,在分析网民评论对象特点基础上提出了一种基于条件随机场的网民评论对象识别方法。该方法在CRFs模型的训练过程中,在词级特征基础上,引入了字级特征、特征词(字)特征和线索词(字)特征。在真实网络数据上进行实验,结果表明新特征的引入能有效地提高网民评论对象识别的性能,同时通过不同话题语料之间的交叉实验,验证了该方法在实际应用中的有效性。此外,相比产品评价对象识别方法,本文方法无需引入任何外部领域知识,因此可以有效地扩展应用到对其他领域评论对象的识别上。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|