{kind=link}
针对中文学术文献的情报方法术语抽取
[化柏林1, 2  ]
]
]
|
|


采用规则的方法,从学术文献中识别方法类句子,然后运用词表与规则相合的方法从句子中抽取方法术语,对抽取出的方法术语进行同义归并,形成情报方法术语库。选取《情报学报》2012年全文作为实验数据进行实验,实验结果表明,利用该方法进行术语抽取是有效的。
This paper identifies sentences on method from academic literature using rules, then extracts method terminology from these sentences using lexicon and rules, among which synonymous terminology is merged. The author makes an experiment to extract method knowledge from full text of papers published on Journal of the China Society for Scientific and Technical Information, then builds a set of information method system by a statistical analysis on experiment result, which testifies the method is effective.
情报学作为一门新兴的跨学科领域,具有多学科属性,这种多学科属性产生了多种研究范式。在情报学科研究中,情报方法是连接情报理论与情报实践的桥梁,关于方法论的研究也就成为决定学科能否健康发展的关键,因此,关于情报方法的内容研究就变成一个比较有意义的问题。针对情报方法的系统研究不仅有利于提高情报工作效率与情报产品质量,而且有利于挖掘情报学科核心竞争力,推动情报学科发展。
哪些方法属于情报方法,哪些方法不属于情报方法,这是一个值得探讨的问题。笔者认为,凡是在情报研究中需要或可能用到的方法都属于情报方法研究范畴,不管这些方法来自于其他学科,还是来自于情报学科本身,都值得去发现、探索、改进与梳理。情报方法按照来源可分为两大类:一类是借鉴其他学科的方法,如趋势外推法、时间序列法、关联规则方法等;另一类是学科特有的方法,如引文分析方法、空白点分析法、非相关文献知识发现方法等[ 1]。这些方法频繁出现在情报学学术文献中,因此从情报学学术文献中抽取方法术语,然后构建情报方法体系,有很强的实际意义。
情报方法从形式上还表现为模型、算法、指标等。模型包括框架类模型与数学模型,SWOT分析方法其实就是一种框架类模型。框架类模型是一种宏观的指导思路与框架,而对于有些具体问题的求解,则需要良好的数学模型与算法[ 1],如隐马尔科夫模型、遗传算法、关联规则挖掘算法。算法是某些方法的具体体现,一旦到了算法阶段,则说明方法具有很强的可实现性。有些方法表现为面向评价或预测设计的指标及指标体系,如H指数、竞争力指标体系、召回率、准确率、F-值、MAP、NDCG等。这些方法具有一定的模式与规律,充分总结与利用这些模式与规律,在技术上实现方法术语的自动抽取具有很强的可行性。
术语抽取包括基于网页的术语抽取、基于百科全书的术语抽取、基于专利的术语抽取、基于论文的术语抽取。程岚岚[ 2]针对Web上存在的大规模术语网页,提出一种采用正则表达式的术语对抽取方法。何燕等[ 3]利用《计算机科学技术百科全书》的分类目录构造计算机科学技术领域本体,并利用自然语言处理技术从《计算机科学技术百科全书》术语条目的解释文本中抽取本体实例。韩红旗等[ 4, 5]针对专利中缺少技术关键词的问题,引入C-value方法,修改了术语构词规则和术语度计算公式,提出用于生成候选术语的中文术语构词规则和测量术语内部结合强度的traithood指标,实现从论文文本中抽取中文科技术语。
术语抽取对象包括术语抽取、术语关系抽取、术语属性抽取。傅继彬等[ 6]提出一种基于知网和术语相关度的关系抽取方法。王璐等[ 7]使用共现分析的方法从术语定义抽取术语属性,然后使用对应分析的方法对科技术语和术语属性之间的关系进行分析。
术语抽取的技术路线一般包括基于规则的方法、基于统计的方法、基于语言学的方法以及基于混合策略的方法。
(1)基于规则的抽取方法
规则包括正则表达式规则、产生式规则、关联规则等。王昊等[ 8]讨论了非结构化中文文本中表达式命名实体的抽取,建立基于层次模式匹配的ENE识别模型。谷俊等[ 9]提出一种改进的关联规则方法,利用基于上下文的术语相似度获取方法得到术语间的相似度权重,再通过加入谓语动词的关联规则算法计算、抽取文本中的非分类关系。潘虹等[ 10]设计了一种基于最大公共子串算法的术语抽取方法:抽取切分后的语句片断的所有最大公共子串作为候选术语集,通过停用词过滤、对照领域词筛选和术语嵌套子串筛选等规则进行判别。
(2)基于统计的抽取方法
基于统计的抽取方法主要包括频率统计、信息熵、互信息、似然度统计等方法。姜韶华等[ 11]提出一种中英文混合术语的抽取方法,依靠统计信息,抽取出支持度大于等于阈值的中英文混合术语。陈士超等[ 12]提出一种双阈值互信息过滤方法,能够快速精确地给出最优上下限阈值进行候选术语过滤与抽取。刘桃等[ 13]提出一种基于信息熵的领域术语抽取方法,在给定领域分类语料的前提下,该方法既考虑领域术语在不同领域类别间分布的不均匀性,又考虑其在特定领域类别内分布的均匀性。胡文敏等[ 14]提出一种基于卡方检验的汉语术语抽取方法:先从网络上下载语料,然后使用改进的互信息参数抽取结构简单的质串,使用卡方检验结合质子串分解方法抽取具有复杂结构的合串。Pantel等[ 15]使用互信息与最大似然估计的方法从双语或多语语料中进行抽取,并证明术语抽取的方法对语言没有依赖性。Li等[ 16]选择了条件随机场模型的7种特征,采用条件随机场和自适应学习的算法抽取中文术语。
(3)基于语言学的方法
傅继彬等[ 17]提出一种基于语言特性的中文领域术语自动抽取算法,集成领域耦合性、领域相关性和领域一致性三种语言特性建立统计模型进行中文领域术语的自动抽取。张希府等[ 18]提出一种基于句法模式的语义关系抽取方法,通过抽取包含语义关系信息的句法模式,并将其与词典文本进行近似匹配以达到抽取语义关系的目的。Déjean等[ 19]在分析讨论几种从多资源中抽取双语词汇方法的基础上,重点关注多语叙词表及针对叙词表的检索策略,提出一种将多种资源有效结合起来进行双语词汇抽取的优化方法。
(4)基于混合策略的抽取方法
梁健等[ 20]引入种子概念方法,利用统计和规则两种方法抽取与种子概念相关的领域术语。章成志等[ 21, 22]采用条件随机场模型将语言学方法与统计方法进行并行融合,综合考虑候选术语及其所在语句的术语度,进行基于多层术语度的一体化术语抽取。杜波等[ 23]设计了一个将统计方法与规则方法相结合的专业领域内术语抽取算法,先使用阈值分类器抽取出双字候选项,然后对这些候选项向左右进行一定程度的扩充,从中筛选出符合要求的多字候选项。何琳[ 24]提出通过候选术语的分布度、活跃度以及主题度进行计算的多策略术语抽取方法。周浪等[ 25]分别使用子串归并、搭配检验和领域相关度计算技术来解决术语抽取过程中的短语结构完整性、短语内部词汇的搭配合理性、衡量短语中所负载领域信息量三个问题,完善词组型术语的抽取任务。
术语抽取主要用于机器翻译、本体学习、产品评论挖掘、竞争情报监测等。综合以上研究发现有以下特点:
(1)与句子级知识抽取大多使用规则的方法不同,术语的抽取既有统计方法,也有规则方法,而且基于统计的术语抽取比基于规则的术语抽取更多一些。
(2)在术语抽取中,涉及到双语或多语的问题比较多,特别是查阅英文文献时,从双语语料中抽取术语特点的比重很高。笔者认为,从双语语料中抽取术语,构建术语对,为后续的机器翻译、跨语言检索等应用提供资源是术语抽取的重要应用。
(3)术语抽取涉及主题词或叙词的情况比较多,概念定义术语或属性术语抽取比较多,专门针对方法术语的抽取并不多。
通过以上综述述评,本文研究聚焦在以下几点:
(1)对于术语抽取,利用基础词表作为处理的起点,然后运用规则的方法对词表里不包含的新术语进行抽取。
(2)采取词表与规则相结合的方法从情报领域论文里抽取方法,并构成情报方法术语库,然后分析方法术语之间的关系,构建情报方法体系,这种应用视角与其他术语抽取略有不同。
根据句子特征把文章切分成句子;识别带有方法特征的句子,对识别的句子按照最大向量分词法进行分词等处理[ 26];从这些句子中抽取方法术语。
采用决策树判别方法判定句子中含有方法的相关性。如果含有“方法”,则该句子是与方法强相关的句子,把该句放入命中池中;其余的句子放入剩余池中。从剩余池中判断句子中是否含有“算法”、“模型”、“指标”等,这类句子可能与方法相关,放入相关池;然后判断剩余池中的句子是否含有“词法”、“句法”、“法国”、“法语”、“法则”、“法律”、“法典”、“无法”等与方法不相关的词,再从剩余池中判断句子是否含有“法”,放入相关池。利用方法集词表对相关池中的句子进行二次识别,如果含有,则转入命中池。命中池存放与方法强相关的句子,剩余池存放与方法不相关的句子,相关池中存放与方法可能相关的句子。
方法术语具有一定的特点,尾词经常是“方法”或“法”,如果方法本身的呈现以“模型”、“算法”等尾词为特征,那么术语出现的句子中一般也会有“方法”的标识,如“对于处理大规模的数据集,近邻传播算法是一种快速、有效的聚类方法”,“矢量动态模型是将统计数据形象化,从而更加直观地观察研究热点的发展动态,是由美国专利与商标局专利技术评价和预测办公室提出的一种方法”。
方法术语的噪声干扰可通过建立方法术语噪声表消除。方法术语噪声表,涉及法律的“法”、语言系列的“法”两大系列,对于法律的法,主要包括“~立法”与“~权法”两大类,但不能通过简单的模式匹配消除噪声,这会把“主观赋权法”、“客观赋权法”等权重设置方法类术语误过滤。语言系列的法包括词法、句法、语法等。“法国”的“法”不构成干扰,因为“法国”、“法语”、“法兰西”等词中的“法”位于词首而不是词尾。
分别建立方法术语表以及方法术语噪声表。从关键词表中识别关于方法的术语,构成方法术语表。然后运用方法术语表、方法术语噪声表以及普通词典构成分词词典,对含有方法的句子进行切分,使用正向最大向量分词方法进行切分。切分后的结果如下:
“首先/ , 将 用户/ 标签网络/ 视 为 用户兴趣模型/ 雏 形 , 利用/ 社会网络分析/ 方法/ 计算/ 标签权重/ , 并 以 加权/ 标签/ 集 的 形式/ 表示/ 用户兴趣模型/ , 最 后 将 标签权重/ 转化/ 为 资源/ 与 用户兴趣/ 的 相似度/ , 进 而 实现/ 个性化推荐/ 。”
依据CSSCI选取17种图书情报领域核心期刊论文,分别从中国知网、万方数据以及重庆维普下载相关题录信息,对这些核心期刊论文的关键词进行统计分析,得到图书情报领域关键词表,有63 203条,从这63 203个关键词中识别出方法术语,有1 302个,构建方法术语表。
用方法术语表对命中池中的句子进行识别,如果能够匹配到方法术语,则对方法术语的前后附着信息进行统计,以形成规则。如果未能匹配出方法术语,则采用规则进行识别。识别出方法术语进行人工核对,如果正确,则对识别出该方法术语的规则进行加权;如果错误,则对错误识别方法术语的规则进行降权处理。最终每条规则都有一个权值,然后对规则进行修正。最后查看未能识别的句子,人工标记方法术语,并追加到方法术语库里,其程序流程如图1所示:
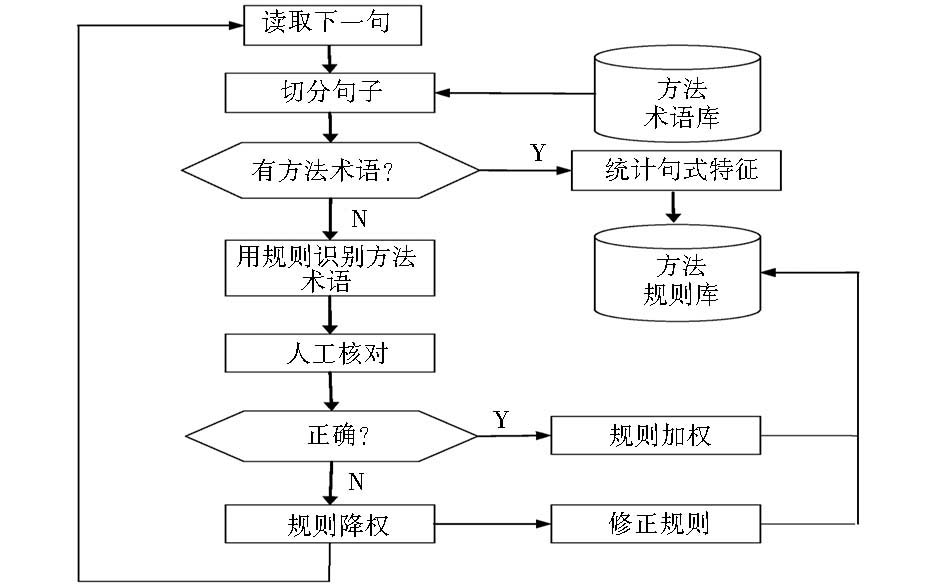 | 图1 方法术语抽取流程 |
抽取方法术语之后,需要对方法术语的同义词进行归并,即建立同义词方法术语库。同义词方法术语库包括以下4种情况:.
(1)中文全称与英文全称或英文缩略语,以括号为标记特征。括号里的内容分为单一表达和双表达两种方式,单一表达方式以英文全称居多,也有英文缩略语。双表达方式一般英文全称在前,英文缩略语在后,中间用逗号隔开,逗号后面有时会有“简称”、“称为”等指示词,如“数据包络分析(Data Envelopment Analysis, DEA)”。带括号的方法术语表达类型如表1所示:
| 表1 带括号的方法术语表达类型 |
(2)不同称谓的词,以“又称”、“或称”为标记特征。如“本文主要讨论术语的共现分析,又称共词分析”、“大众分类也叫社会分类、自由分类、分众分类等,它就是由网络信息用户自发为某类信息定义一组标签(Tag)进行描述,并最终根据标签被使用的频次选用高频标签作为该类信息类名的一种为网络信息分类的方法”。
(3)同一方法术语有多种表达形式,常见的表达形式有以下三种:M+“的方法”、M+“方法”、M,如共现分析的方法、共现分析方法、共现分析;KNN分类算法、KNN方法、KNN算法、KNN;MDS分析方法、MDS方法、MDS等。
(4)前后中心词互置的情况,通过前后部分中心词互置识别同义词,如基于语义相似度的Web文本分类方法、Web文本语义特征相似度的算法。
提取带括号的方法术语,建立方法术语同义词表。对于相近概念,以出现频率最高的为规范词并进行人工校对。分别通过上述4种情况计算方法术语之间的相似度,把相似度比较高的聚类到一起,形成同义词方法术语库。
利用以上方法,对《情报学报》2012年全文进行方法术语的抽取。首先利用既有的方法术语进行抽取,然后对抽取的方法术语进行统计,初次统计结果如表2左列所示。通过模式规则识别方法术语同义词表,构造同义词表库,对方法术语进行归一合并,然后重新统计,得到结果如表2右列所示:
| 表2 高频方法术语表 |
可以看出,合并以后,聚类分析、社会网络分析、调查问卷、相似度计算方法、内容分析法、作者共被引分析方法等方法术语的频率都有较大增长。说明这些方法是情报学常用的方法。需要说明的是,本研究并没有对方法的上下位类进行归一后统计,如“聚类分析”是指单纯的“聚类分析”、不包括“层次聚类”、“KNN聚类”等。 如果方法术语表里没有方法术语,则采用规则的方式进行识别并抽取。例如“基于……的法”、“采用……(方)法”,符合这种结构体的句式中往往包含有新的方法(严格讲,应该是未登录方法),但需要排除“基于”后面紧接着是对象术语的情况,例如“基于简单树匹配的结构相似性度量方法”、“基于本体的语义特征抽取转换方法”等。
共得到同义词词条183组,其中有10、9、8个同义词元素的词条分别有1组,6个同义词元素的词条有3组,5个同义词元素的词条有7组,4个同义词元素的词条有14组,3个同义词元素的词条有29组,2个同义词元素的词表有127组,得到同义词表如表3所示:
| 表3 同义词表示例 |
为了测试效果,本文选取《情报学报》2013年第1-4期论文共46篇的全文数据进行测试。46篇论文共切分出句子5 916个。方法术语的抽准率为92%,召回率为94%。
查看错误结果发现主要为以下两种情况:Adj+[的]方法:主流方法、同样方法;Pron+方法:此方法、该方法、这种方法、这些方法、此类方法。影响召回率结果主要包括以偏概全型及新方法遗漏型等。以偏概全型:论文里出现了“作者文献耦合方法”,由于术语库中没有此方法,但是有“耦合方法”,因此抽取出“耦合方法”,由于已从此句中抽取了方法术语,因此没有进行识别。新方法遗漏型:方法术语表里不含有此方法,而且运用规则也未能识别出该方法术语,造成方法术语抽取的遗漏。
需要说明的是,目前没有专门针对方法术语抽取的测试集。方法抽取的测试比较困难。规范的测试,应由第三方人工标记出一个测试集,运用本文的方法进行术语抽取并识别方法的知识属性,然后对抽取的结果与人工标记结果进行对比,以测试本文所提方法的抽准率与召回率。
在情报学科研究中,情报方法是连接情报理论与情报实践的桥梁,关于方法论的研究也就成为决定学科能否健康发展的关键,因此,如何识别与构建一个情报方法体系就变成一个比较有意义的问题。已有的情报学论文中包含有大量的方法,抽取这些方法及内容并按照一定的逻辑体系组织起来,有利于推动情报学学科发展。
有了基础词表可以提高术语识别的效率,对使用基础词表抽取出来的句子进行规则总结,然后利用规则对新的术语进行识别,是一种有效的方法。
从情报论文里抽取的方法包括信息收集与获取方法、多源数据融合方法、数据清洗方法、计量分析方法、聚类分析方法、路径分析方法、关联分析方法、共现分析方法、相似性度量方法、奇异值分析方法、社会网络分析方法、结果解读方法、情报预测方法、科技评价方法、决策支持方法等[ 27]。这些方法按照属性分为定性方法与定量方法、统计方法与规则方法、线性与非线性方法、结构化与非结构化方法、有监督与无监督方法等。按照方法的适用对象分为面向数据的方法、面向文献的方法、面向知识的方法、面向人的方法与面向组织的方法等[ 28]。按照方法的内容分为方法的定义描述、方法的类属描述、方法的特点描述、方法的过程描述、方法的功能描述等。详细内容将择文另述。
虽然本文做了一些有益的尝试,但也存在一些不足,通过研究发现,方法术语的抽取涉及以下难点:方法的指代消解、方法的缺省表示、嵌套方法的识别与抽取。
方法的指代消解是通过上下文信息及相关规则还原方法的指代消解,把“此方法、这种方法”等指代,从上文中找出最近的方法术语,进行还原消解。例如,“这类方法忽略了用户使用查询关键词的多样性这一事实,当关键词在知识源之外时,查询扩展将无法进行”的上一句为“基于语义结构/语义关系的方法,该方法以已有的词典、本体或知识库作为知识源,从中选择查询相关词汇对原始查询进行扩展”,这个句子里含有“基于语义结构/语义关系的方法”,则可以把“这类方法”还原为“基于语义结构/语义关系的方法”。
方法的嵌套可以参照方法的类属描述,利用特征词进行判别与抽取,上位类方法的划分往往使用“包括、分为”等特征词,在这些动词特征词前有时会出现“总体上”等强度副词,在动词特征词后面有时会出现“~大类”等上层表示特征词。而在并列体里往往使用“如、例如、有、诸如”等下位列举型特征词。当然,有时并列体里也会使用“包括、分为”等特征词,还可能出现“又……”、“细分为……”、“再”、“进一步”等副词特征。
方法名称的缺省:只描述了方法的过程,未能给出一个方法术语名称。这种情况无法抽取方法术语。例如,“在UMI@Web2.0系统中我们采用了如下方法:对于原始数据源,通过采集工具发现以后,采集该数据源的统一资源定位符URI,将其作为对该资源描述的一个重要属性值,形成资源描述文档的一个内容”,只描述了一个方法,但没有给出方法术语的名称,因此,就无从抽取。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|