


{kind=link}
{kind=link}
{kind=link}
应用阿里云搜索服务构建图书馆站内搜索引擎
[王爽 ]
]
]
|
|


利用云搜索服务已成为新的站内搜索技术方向。厦门大学图书馆采用阿里云服务重构站内搜索,将云搜索封装为独立的搜索引擎。网站数据经过预处理后提交、生成索引,传递搜索字符串到云搜索引擎即可使用云服务,实现搜索及结果呈现。评测结果表明,阿里云站内搜索与原有站内搜索相比,在检索效率和功能等多方面有显著提升。
The application of cloud search service becomes a new search technical direction. Xiamen University Library chooses Aliyun service to rebuild site search, and packages the cloud search as an independent search engine. After pre-processing, the site data is submitted and index files are generated, then the search strings are passed to the cloud search engine. Base on the cloud search service, searching finished and results displayed. Evaluation results show that Aliyun cloud search, compared with the old search engine, is significantly improved in search efficiency and functionality,etc.
云计算近年来不断发展,已从抽象的概念演变为用户身边实实在在的产品与服务。在云环境下,图书馆借助云服务的支持,基于云计算随时取用、按需支付、平台无关、易部署易扩展的特点[ 1],进一步提升资源建设与服务能力,已经是一种不可回避的选择[ 2]。
2002年,罗良道[ 3]调查了国内10所重点高校图书馆应用站内搜索的情况,当时只有4所高校的图书馆网站提供站内搜索入口。随着图书馆各类服务的开展,网络资源的持续增长,大中型图书馆的网站内容日益丰富,站内搜索已成为提升用户体验的重要应用。目前这10所图书馆中有7所已在其网站提供了站内搜索入口。笔者选取这7所高校图书馆,在站内搜索技术平台方面与厦门大学图书馆列表比较,如表1所示:
| 表1 8所高校图书馆站内搜索技术平台一览 |
由表1可以看出,目前图书馆站内搜索大多基于本地数据库或通用搜索引擎。此外,曹强[ 5]提出基于Lucene的站内搜索实现方式;2012年和2013年两大云服务提供商(Amazon[ 6]和阿里云[ 7])相继发布了全新概念的“云搜索”服务[ 8, 9]之后,利用云搜索服务成为一种新的站内搜索技术方向。以上4种站内搜索技术方案的比较如表2所示:
| 表2 4种站内搜索技术方案的比较 |
厦门大学图书馆新版主页于2012年12月正式发布。新版主页的栏目分类设置、内容组织方式与旧版主页有很大的不同,一些零散的子系统未能有效地组织于搜索引擎中,导致用户无法快速找到所需资源。
站内搜索需要检索的数据种类很多,包括主页栏目、商业数据库、自建数据库、免费资源、下载文档、图书馆通告等各类信息,这些信息分散存储于数据库表中,不同的表结构各异,尚有部分内容是以文件形式存放,如果采用本地数据库的全文搜索针对这些数据进行检索,不仅检索效率不高,易造成漏检,而且检索结果也无法按照相关度进行排序和推荐,无法实现为用户提供快速、正确、全面、有效的检索结果的目的。针对多样性数据内容,开发一个检索效率高,结果全面,并可进行相关度排序的搜索引擎是较为迫切的需求。
目前提供云搜索服务的有Amazon及阿里云两大云服务提供商,这两家厂商实现云搜索的技术思路、实现方式都高度相似,用户的选择主要应考虑服务质量、访问速度、费用等方面,而在这些方面Amazon CloudSearch[ 11]处于劣势,原因如下:
(1)中文分词是中文搜索的一大关键技术,Amazon CloudSearch主要面向欧美市场,经试用其针对中文并未进行相应优化。
(2)鉴于国内网络的国际出口带宽限制,国内访问国外网站速度较慢,而Amazon CloudSearch并未专门针对国内网络提速。
(3)阿里云搜索针对数据量少于10万的用户采取免费策略,同时不限制访问次数,而Amazon CloudSearch只提供30天的免费试用,之后将根据搜索实例、上传文档、IndexDocuments 请求、数据传输的实际情况收取相应费用[ 12]。
厦门大学图书馆站内搜索有两个特点:数据量小,目前厦门大学图书馆主页的数据仅有2 223条;用户对于搜索结果的精确度要求较低,主要目的是导向目标栏目及子系统,因此对于搜索引擎的排序、优化无需过多干预。阿里云搜索现有的功能已经能够满足以上需求,其成熟的云服务保证了搜索引擎的稳定、快速;用户无须提供搜索引擎服务器资源,也无需关注搜索的实现细节;开发工作主要集中于整理数据、解析搜索结果即可,开发量小、难度低。经综合比较,采用阿里云搜索服务实现图书馆站内搜索是具创新意义的最佳选择。
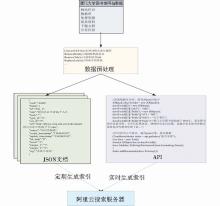
笔者对厦门大学图书馆主页数据进行分析整理,将数据分为网站栏目、数据库、免费资源、馆员资料、下载文档5种类型,前4种类型数据可直接读取数据库内容生成JSON[ 13]文件,下载文档分散在不同类型的内容中,需要把所有包含下载链接的数据选取出来,并剔除文本内容,只保留下载链接的地址及文件题名,再生成相应的JSON文件。阿里云提供资讯模板、小说模板、游戏、APP模板和论坛模板,根据厦门大学图书馆网站数据的特点和检索需要,笔者最终选择资讯类作为生成JSON文档的模板。 该模板支持全文检索、标题检索;支持类型、类别过滤;支持创建时间、更新时间、点击等各种维度的排序;相关性方面除了全文匹配度外,对时效性要求高,同时还会参考点击、关注等因素,并预留Boost(站长自定义加分项)字段方便调节该资讯排序情况[ 14]。最终确定的文档字段如表3所示:
| 表3 阿里云搜索资讯类型字段与厦门大学图书馆站内搜索对应字段 |
需要注意的是,JSON文档需要以UTF-8格式进行编码,根据JSON数据格式要求,在生成文档时需要对数据内容进行预处理,如剔除没有检索意义的HTML标记;去掉内容的制表符Tab,字符 “\” 转换成“/”等。
厦门大学图书馆“站内搜索”的功能定位是整合馆内所有自建系统的数据,因此笔者将“阿里云搜索”封装为一个独立的仅提供搜索服务的小系统,实现搜索及搜索结果的呈现。其他系统只需要传递搜索字符串到该系统即可使用搜索服务,用户得到搜索结果后再引导到各个子系统,如图2所示:
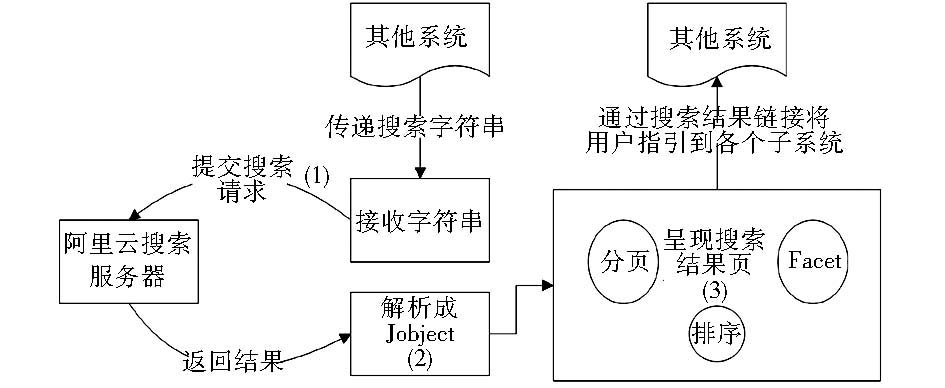 | 图2 “阿里云搜索”封装后嵌入图书馆系统 |
采用这种实现方式的优势在于各个子系统无需分别开发阿里云的调用模块,可以极大节省开发成本。具体实现要点如下:
(1)接收参数,提交请求
如提交的链接为:
http://x.x.x.x/aliyun/s.aspx?q=民国期刊
该链接默认传递的参数“q”是检索关键字,除此之外还可以传递“page”(页码)、“pageSize”(每页大小)。搜索子系统在解析链接参数后调用API进行检索:
var index = api.getIndex(indexName); //打开相应索引
results = index.search(“q=”+query, page.ToString(), pageSize.ToString(), sort, filter, facet, null); //调用搜索API获得搜索结果
(2)解析返回数据
阿里云返回的标准JSON数据在ASP.NET平台使用Newtonsoft.json[ 15]来解析。它将返回的字符串解析成JSON对象,呈现数据时能够直接以访问键值对(Key-Value Pair, KVP)[ 16]的方式快捷地定位信息:
JObject sr = JObject .Parse(results);
在实现要点(1)中调用API时传入facet参数,该参数用于指定执行facet的字段并设置该facet需要返回的数据。根据字段定义,设定cat_id为执行facet的字段,并要求API返回每个cat_id分类的搜索结果统计信息:
NameValueCollection facet = new NameValueCollection ();
// 初始化facet
facet.Add( “facet_key” , “cat_id” );
//定义执行facet的字段为cat_id
facet.Add( “facet_fun” , “sum(hit_num)#count()” );
//要求API返回搜索结果中根据cat_id进行分类统计的个数
通过上述设置,API返回的数据不仅包含基本的搜索结果,还包含facet相关数据。
(3)呈现数据
在搜索结果页面,数据呈现包含4个部分,具体布局如图3所示:
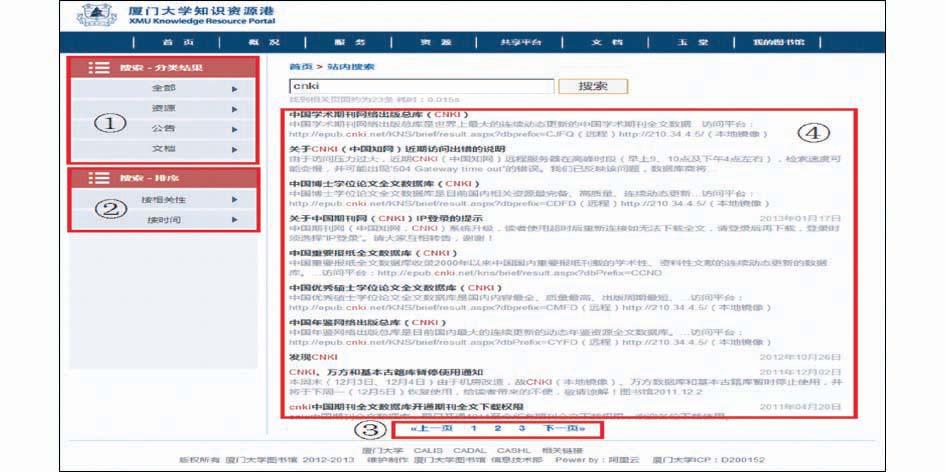 | 图3 厦门大学图书馆站内搜索结果页面布局 |
①分 类
用户的二次搜索实质是进一步限定搜索范围。根据实现要点(2)解析得到的facet数据可将搜索结果的分类统计信息呈现出来,用户点击相应链接会触发程序在一次搜索的基础上传递一个附加的分类号作为过滤器,链接如下:
http://x.x.x.x/aliyun/s.aspx?q=民国期刊&page=1&pageSize=10&c=5
程序接收参数c作为过滤器:
string filter = null ;
if (Request.QueryString["c" ]!= null){
cat = Request.QueryString[ "c" ].ToString();
filter = "cat_id=" + cat;
}
JObject rs = sh.Search(q, page, pageSize, orderbyTime, filter); // 在搜索中加入过滤器filter
②排 序
搜索结果的排序采用两种方式,相关度及记录创建时间。阿里云默认的排序方式是相关度,采用相关度排序无需多余设置,而采用创建时间逆序则需要设置:
string [] sort = new string[] { “-create_timestamp” }; //设置排序的字段为创建时间
results = index.search(cq, page.ToString(), pageSize.ToString(), sort, filter, facet, null ); // 在搜索中加入sort排序
③分 页
根据页面布局设计,分页部分只显示当前页的前后各三页及上一页、下一页的导航链接。API返回结果中包含该检索字符串在整个库中的搜索结果数。通过提取这个数量,并配合页面的pageSize参数即可计算出总页数,最后提取其前后各三页的链接呈现在页面中。
{"result":{"total":28,}} //包含搜索结果数量的json
如分页链接:
http://x.x.x.x/aliyun/s.aspx?q=民国期刊&page=2&pageSize=10
从这里可以看出,翻页的操作只是修改页码(page)部分的参数,实质是重新发送一次搜索请求。
④搜索结果
这部分是页面主体,用于将搜索结果的明细呈现给用户。笔者采用ASP.NET的Repeater控件实现数据呈现,将实现要点(2)中解析得到的JObject传递给相应的Repeater控件,布局则由页面端通过DIV+CSS来实现。
JArray resultItems = rs["result"]["items"] as JArray;
if (resultItems!= null){
resultRp.DataSource = resultItems;
resultRp.DataBind();
}
(4)其他高级功能的实现
除了上述功能外,阿里云还支持高级字段筛选、多索引合并检索等高级功能。
①高级字段筛选
字段定义中的INT或者UINT类型字段都能够用于筛选。实现方式是在调用搜索API时传入相应的filter,如“filter=user_id=5 AND price>20”表示仅返回user_id=5并且price>20的文档。
②多索引合并检索
如果针对每个站点都建立了索引,则需要跨站搜索时即可利用多索引合并搜索的特性。如果是多个相同模板索引,引擎处理多个索引的方式与单个索引没有区别。如果是不同模板的索引,则引擎会根据相关性交替返回不同模板的结果。
厦门大学图书馆于2013年2月25日启动基于阿里云搜索服务的站内搜索升级项目,3月7日提交数据测试,3月18日项目正式上线,快捷简便地构建了图书馆主页的站内搜索引擎,很好地弥补了原站内搜索的不足,满足了读者快速准确获取网站内容的需求。阿里云站内搜索与原有站内搜索在检索效率和功能方面的比较如表4所示:
| 表4 厦门大学图书馆原站内搜索与阿里云站内搜索的比较 |
阿里云搜索服务高质量、易扩展、可高度定制化的特点是厦门大学图书馆采用其构建站内搜索引擎的主要因素。随着阿里云搜索服务自身技术与功能的不断完善,图书馆可借此实现更多功能,满足更为个性化的需求。阿里云搜索服务目前处于内测阶段,提供全免费服务,未来阿里云服务的收费标准、服务的稳定性及安全性将是笔者关注的重点。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|