

{kind=link}
{kind=link}
{kind=link}
基于统计分布的中文专利自动分类方法研究
[胡冰1  , 张建立
, 张建立2 ]
, 张建立|
|


传统的基于向量空间模型的文本自动分类算法没有考虑到特征词的类间分布情况及特征词在文本内部的位置分布情况,导致该算法用于专利分类时效果不佳。提出一种基于统计分布的中文专利自动分类方法。首先,统计出特征词的类间分布信息,引入类间分散度加权因子,突出分布类别少、出现频率高的特征词的权重;其次,结合专利文本的结构特点,引入位置权重因子,突出专利的法律特性和技术特性以及组成专利各元素内容的差异性。最后通过对比实验证明,该方法能够有效提高中文专利自动分类的效果。
Traditional text automatic classification algorithm based on Vector Space Model fails to take the distribution information of terms among classes and the position information of terms in class into consideration, which leads to a poor performance of the algorithm in patent classification. This paper proposes a Chinese patent automatic classification method based on statistical distribution. Firstly, this paper puts forward distribution information weighting factor to manifest the weighting of the terms that appear frequently but in less class. Then, combining with the structural feature of patent text, this paper introduces position information weighting factor to highlight the legal and technical characteristics of patent and differences of patent’s each element in content. Finally, the contrast experiment shows that the classification effect can be improved sufficiently by this proposed method.
专利文献作为一种特殊的文本,包含大量法律、技术与其他类型资料的关系等多方面有价值的信息,已经引起了人们的高度重视,根据世界知识产权组织的统计,专利文献含有世界每年发明创造成果的90%-95%[ 1, 2]。因此对专利文本信息的加工处理显得日益重要。专利分类是专利文本挖掘的关键技术之一,其目的是对专利文本信息进行有效的管理。专利分类不仅可以帮助企业进行各类技术研发趋势与动向的预测[ 3],并且可以对国家和竞争企业的整体技术动态进行分析,为技术部门实现竞争跟踪与分析提供有力依据[ 4]。然而,面对海量的专利数据,传统的手工分类方式不仅效率低下,而且资源耗费量大[ 5]。因此,专利的自动分类显得日益迫切和重要,人们对专利自动分类的关注程度和重视程度也越来越高。与一般的文本相比,专利文本具有结构特殊、专业性强、领域词汇较多等特点,这使得传统的文本分类方法不能很好地满足专利自动分类的需要。
目前,关于专利自动分类的问题已经引起了学者们的关注,国内外有学者对组合分类器开展了研究,如Mathiassen等[ 6]基于WIPO-alpha文本集对组合分类器的分类效果进行研究,认为分类器组合后的专利分类效果优于任何一个单独分类器的分类效果。李程雄等[ 7]将SVM与KNN算法进行组合改进,弥补了单独应用SVM算法时对不同的应用问题核函数参数选择较难的不足。除分类器以外,影响专利自动分类效果的另一个重要因素是专利文本的特征表示,近年来我国有学者在专利自动分类中的特征词权重评估方面开展了一些研究,如邓擘等[ 8]提出一种基于统计分布和集合论的分类方法,其思想是特征词出现的类越多,则该特征词的权重越小,反之特征词出现的类越少则权重越大,但该方法没有对特征词的分布信息进行定量处理。蒋健安等[ 9]提出在计算特征词的权重时引入位置权重,但仅仅是用经验法设置各个位置的权重。笔者认为,在特征词权重评估方面,还可以详细统计特征词的类间分布信息及特征词在文本内部的位置分布信息,通过对这些信息进行量化处理,进一步改进特征词权重评估算法,从而提高专利自动分类的效果。
因此,本文给出一种基于统计分布的中文专利自动分类方法。该方法在分析传统的TF-IDF算法用于专利文本自动分类时不足之处的基础上,一方面统计特征词的类间分布信息,引入类间分散度加权因子,将加权因子量化,同时给出具体的计算公式;另一方面结合专利文本的结构特点,引入位置加权因子,并利用实验法,设置各个位置的权重。从而在评估特征词权重时引入了特征词的统计分布信息这一重要因子,改进了特征词权重评估公式,使其更适用于专利文本自动分类,提高了中文专利自动分类的效果。
在对专利文本进行分类时,一般采用基于向量空间模型(Vector Space Model, VSM)[ 10]的文本表示方法,在向量空间模型中, 文本集被看作是由一组向量组成的向量空间。若空间的维数是n, 则每篇文本d可表示为由二元组组成的实例特征向量V(d) =((t1,w1),(t2,w2),…,(tn,wn)),其中tn表示专利文本d的特征词,wn表示特征词tn的权重。在计算特征词的权重时考虑的基本要素是词频和文本频,应用最普遍的是TF-IDF算法[ 11],传统的TF-IDF 算法主要考虑特征词的词频、逆文本频、归一化等因素,算法如下所示:

TF(tij)表示特征词ti在文本dj中出现的次数,即词频;IDF(ti)表示逆文本频,其中被广泛使用的经典计算公式为[ 12]:
N(C)表示文本集C中的总文本数,N(ti,C)表示文本集C中特征词ti出现的文本数。
在TF-IDF算法中,体现了以下思想[ 13]:一个词在文本中出现的频率越高,说明它区分该文本内容属性的能力越强;一个词在文本中出现的范围越大,说明它区分文本内容属性的能力越弱。
然而,在专利自动分类中,该算法在处理专利数据时有两个明显的不足之处:
(1)专利文献中经常为了规避专利侵权或建立专利壁垒而反复强调某些概念,这使得专利文本中一些词在少数类中频繁出现。而传统的TF-IDF算法在计算分布类别少、出现频率高的这类特征词的权重方面存在不足,算法中逆文本频(IDF)只是简单认为文本频率低的特征词比较重要,而没有考虑到特征词ti在各类之间的分布情况。如果特征词ti在某一类的各个文本中出现频率很高,而在其他类的文本中出现频率很低,那么特征词ti在表示该类文本时更具代表性,应该赋予更高的权重。举例说明,特征词t1和t2在各类中出现的文本频数如表1所示:
| 表1 特征词的文本频数 |
(2)对专利进行分类,不仅要考虑专利在技术上的相似性,还要考虑组成专利的各元素在信息内容上的差异性。专利分类是从专利文本信息的角度衡量待分类文本的所属类别,而专利文本信息与一般文本信息有所不同,主要表现为专利文本信息具有法律特性和技术特性,这些特性对于专利分类有重要影响。专利文本信息的不同特性表现在不同的字段上,因此在对专利分类时,应结合专利的具体结构特点,选择最能表现专利法律特性和技术特性的结构单元,调整出现在不同位置特征词的权重,才能获得良好的分类效果。然而传统的TF-IDF算法将每篇文本作为一个整体看待,并没有考虑到特征词ti分布在文本dj中的不同位置时对于分类的影响。例如,特征词ti出现在摘要中,主要表征的是专利的技术特性,而ti出现主权项中,更多的是表征专利的法律特性,但TF-IDF算法并没有进行区分处理。
考虑到以上两种情况,传统的TF-IDF算法已经不能很好地满足专利自动分类中计算特征词权重的需求。
(1)基于以上分析,在进行专利自动分类时,在统计特征词在各类之间分布情况的基础上,引入类间分散度加权因子DI(Distribution Information),以应对特征词ti在某一类文本中集中出现的可能性,本文设计的DI计算公式如下: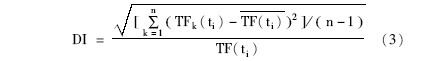
其中,TFk (ti)表示在第k类中特征词ti出现的频数,n为类别总数,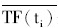 表示特征词ti在各类中出现频数的平均值。
表示特征词ti在各类中出现频数的平均值。
公式(3)中,若特征词ti在所有类中出现次数相同,则计算得到DI的值为0,这说明该特征词不具有类别区分能力;若ti仅在极少数类里出现,则DI的值会相对比较大,这说明该词的类别区分能力较强。
(2)引入位置加权因子,以突出专利的法律特性和技术特性。专利文本是由名称、摘要、申请号、分类号、主分类号、发明人、申请人、主权项等元素构成的。但并不是组成专利文件的每个元素都适用于专利分类。例如,发明人和申请人等涉及的是专利主体的具体信息,并不具备表示专利具体知识信息的能力[ 14]。通常,出现在标题和摘要中的词对专利主题的表达能力比出现在正文中的词强,出现在主权项中的词表达专利法律特性的能力比出现在其他位置的词强。因此,本文选取最能代表专利知识信息的元素,将专利文本分割成三个独立的部分,用一个三元组P=(p1,p2,p3)表示,其中,p1表示标题,p2表示摘要,p3表示主权项,将出现在不同位置的词赋予不同的权重并通过加权来处理。设位置权重为zp,其值通过大量的实验获得,设TFp(ti)是特征词ti在专利文本的位置p中出现的次数,则本文设计的该特征词的位置加权因子PI(Position Information)计算公式如下: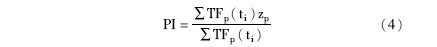
其中,位置权重:
综合上述各个加权因子,改进的适用于专利文本自动分类的特征词权重评估函数公式如下: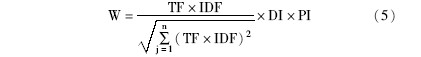
将改进的特征词权重算法应用于专利文本自动分类的过程中,具体分类算法描述如下:
输入:带类别标记的训练文本集,测试文本
输出:测试文本所属类别
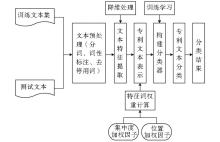
①对训练文本集和测试文本进行预处理。对文本进行分词和词性标注,并去除停用词。
②统计出词条的位置分布信息、类间分布信息以及频次信息,将每篇专利表示成由词构成的向量,并运用特征选择算法对向量进行降维处理。
③结合运用本文改进的特征词权重算法,计算出每个特征词的权重,将每一篇专利文本都表示成由特征词及其权重组成的特征向量。
④采用KNN分类算法,计算测试文本和训练文本集中每一篇文本的相似度,相似度通过计算向量间的夹角余弦得到。设sim(di,dj)表示专利文本di与dj的相似度,则采用余弦系数表征的文本di与dj的相似度计算公式为[ 15]: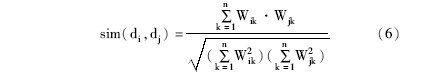
其中,di和dj分别表示训练文本和测试文本,Wik和Wjk表示文本向量中对应特征词的权重,n表示向量的维数。
⑤将计算得到的相似度结果按降序排列,选择排在最靠前的K篇文本。将同属于一个类的文本与待分类文本的相似度相加求和,并对每个类求得的和排序,将待分类文本归到和最大的类中。
具体流程如图1所示:
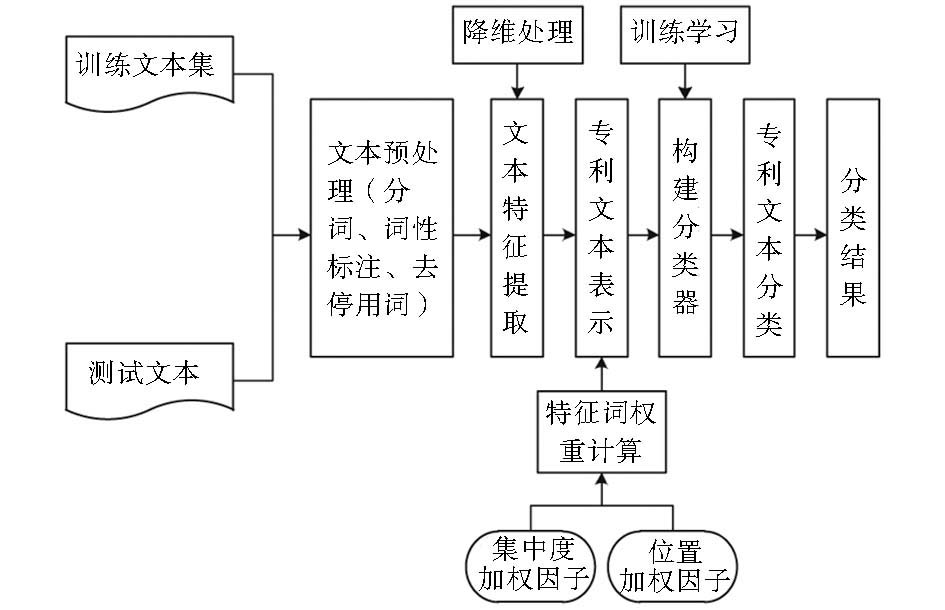 | 图1 基于统计分布的中文专利自动分类流程 |
采用精确率(Precision, P)、召回率(Recall, R)和F1值(F-measure, F1)三个指标对实验分类结果进行评估: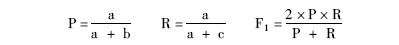
其中,a表示被正确分到某类的文本数,b表示被错误分到该类的文本数,c表示属于该类但未被分到该类的文本数。
为了验证本文提出的基于统计分布的中文专利自动分类方法,选取结构加固技术领域的1 700篇专利文献作为语料库,语料库中的所有专利文献均来自中国专利数据库,通过专利下载分析系统PatentEX下载这些专利并解析出每件专利的标题、摘要、专利号、分类号、申请人、主权项等。该语料库已由工业和信息化部电子知识产权中心的专业人员进行手工分类,涉及整机设计、散热技术、三防技术、抗震冲击设计以及电磁兼容技术5类。从每个类中抽取75%的文献组成训练语料库,共1 275篇,剩下的425篇专利文献组成测试语料库。
实验分两组进行,第一组采用传统的专利文本自动分类方法,即在计算特征词权重时,不引入任何加权因子;第二组采用本文提出的专利文本自动分类方法,引入类间分散度加权因子和位置加权因子。
实验采用中国科学院计算技术研究所ICTCLAS系统进行分词,并编写程序提取专利的标题、摘要、主权项中的内容,以申请号为CN200920246283.2的名为“一种防雷击连接器及具有该连接器的计算机”为例,分词结果如图2所示:
 | 图2 专利文件分词结果 |
采用信息增益(Information Gain, IG)特征选择算法,分两组分别计算特征词的权重,经过多次反复的尝试,KNN分类算法中的K值定为15。实验分类结果如表2所示:
| 表2 实验结果比较 |
 | 图3 F1值对比 |
通过表2和图3的对比实验证明,本文提出的基于统计分布的中文专利自动分类方法与传统的分类方法相比,分类结果的精确率、召回率、F1值都有所提高。这说明,使用本文提出的中文专利自动分类方法,在计算特征词权重时引入类间分散度加权因子和位置加权因子,可以有效弥补应用于专利自动分类时TF-IDF算法的不足,提高计算特征词权重的准确性,从而提高中文专利自动分类的效果。
由于传统的文本分类方法没有考虑到特证词的类间分布情况以及特征词在文本内部的位置分布情况,因此用于专利文本自动分类时无法获得良好的效果。本文提出了基于统计分布的中文专利自动分类方法,引入类间分散度加权因子以及位置加权因子,调整了经典的TF-IDF算法,并给出新的特征词权重评估公式。该方法突出了分布类别少但出现频率高的这类特征词的权重,突出了专利的法律特性和技术特性以及组成专利各元素内容的差异性。实验证明,本文提出的方法有效提高了中文专利自动分类的效果。
研究中的一个关键点是特征词在各类间的分布信息,但本文并没有对特征词在类内部的分布情况进行讨论。因此,未来将针对专利文本中特征词的类内分布偏差开展研究,进一步改进特征词权重评估算法。总之,该方法还需要通过理论和实践研究不断改进和完善。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|