



{kind=link}
{kind=link}
{kind=link}
{kind=link}
关键词-分类号关联词表构建*
[杨贺1, 2  , 杨奕虹
, 杨奕虹1, 2 , 李宁2 ]
, 杨奕虹|
|


在多年海量文献人工标引的数据基础上,采用互信息法(MI)、卡方检验法(Chi-Square)、最大似然估计法(MLE)等概率与数理统计方法计量分析关键词与《中国图书资料分类法》分类号的关联关系,构建适用于科技文献自动标引的关键词-分类号关联词表,并通过实际标引文献数据的封闭与开放测试分析其应用效果。
Based on years of massive manual indexing data, this paper constructs a natural language classification thesaurus with Mutual Information (MI), Chi-Square (χ2) and Maximum Likelihood Estimate (MLE) to analyze the corresponding relation between keywords and Chinese Library Classification Codes. The performances of the Keywords-Chinese Library Classification Codes Integrated Thesaurus used for automatic indexing of sci-tech literatures are tested by close and open testing .
科学技术的快速发展带动了信息量的剧增,信息过载现象严重,大量无关冗余的信息严重干扰了检索用户对相关有用信息的快速、准确选择。数据标引是解决这一问题的重要途径之一,它通过对信息载体所包含和传递的内容特征进行预先揭示标记,形成有序化存储,来提高信息检索的查全率与查准率,并有效提升数据检索效率。分类法与主题法是信息组织中揭示内容特征最基本的两种方法,传统的数据标引由人工给出主题词和分类号,其主要工作步骤为:根据标引源数据提炼关键词;将关键词依据受控词表统一为主题词;由主题词描述的概念依据分类法给出分类号。然而面对爆炸式增长的文献数量,人工标引早已难堪重负,且劣势越来越明显,具体体现在标引效率低、成本高、一致性差等方面,无法解决文献数量迅猛增长与文献加工严重滞后的供需矛盾,因此引入计算机对文献论文进行自动标引。同样,自动标引也分为主题标引和分类标引,本文集中解决自动分类标引领域的问题,自动主题标引领域的研究另文撰写,此不赘述。
应用计算机进行自动分类标引,最初的朴素想法是应用计算机模拟人工标引的工作步骤,依据待标引数据源的内容,形成关键词→主题词→分类号的转换,最终得到分类结果。后期考虑到计算机拥有处理能力强、速度快、成本低等优势,且科技快速发展引发新词层出而传统叙词表修订严重滞后的现状,故决定暂时绕过主题词的问题,直接研究建立关键词与分类号映射关系,形成关键词-分类号关联词表。
笔者通过挖掘以往人工标引的海量文献数据,汲取其中蕴含的人工智能,借助数学领域中的概率与数理统计方法,提炼关键词与分类号的映射关系,建立了关键词-分类号关联词表。需要特别说明的是,鉴于当前国内的文献主要依据《中国图书资料分类法》(含《中国图书分类法》)进行分类组织,因此本文提到的分类号专指《中国图书资料分类法》(简称《资料法》)分类号。此外,该词表构建方法也可推广应用于关键词与其他分类法的关联关系建立,解决应用其他分类法的信息数据自动分类标引问题。
人工标引文献时,分类标引可用到的工具除《资料法》外,还有《中国分类主题词表》(简称《中分表》)。《中分表》出版于20世纪80年代末90年代初,实现了《中国图书馆分类法》(含《中国图书资料分类法》)和《汉语主题词表》两大检索语言的一体化,以对照索引的方式建立主题词与分类号之间的对应转换关系[ 1, 2]。2006年8月,北京图书馆出版社编辑再版了《中分表》电子版,该词表共收录分类法类目52 992条,主题词110 837条,主题词串59 738条,入口词35 690条,包括哲学、社会科学和自然科学、工程技术等所有领域的学科和主题概念[ 2]。然而在海量文献标引的实际工作中,《中分表》(第二版,电子版)尚不能满足一线工作需要,仅以北京万方数据股份有限公司(简称万方公司)的《中国学位论文文摘数据库》(简称万方学位论文库)为例,截至2013年4月底共收录252万条记录。万方公司规定每篇论文根据实际需要标引3-8个关键词,1-2个《资料法》分类号。经统计该库主题标引涉及到的关键词数量达百万以上,远远超过《中分表》(第二版)词汇量,即论文标引出的大量词汇均不在《中分表》中,因此无法得到分类号。换句话说,《中分表》的词汇量限制了自动分类标引系统的应用,难以发挥其效力,因此构建一部相当规模的关键词-分类号关联词表是当前亟需解决的问题。
通常文本自动分类可分为自动聚类和自动归类[ 3],包括向量模型表示、特征选择和分类器训练三个步骤[ 4]。本文的研究基础包含大量具备人工标引关键词和分类号的论文,实际上已经完成了对文本的降维处理和特征抽取,因此本文的具体问题就归结为在一个相当规模的样本特征集中建立两个特征变量——关键词和分类号关系的问题,即特征选择的问题。
通过查阅文献发现,特征选择有多种数理统计分析方法,不少学者如Yang等[ 5, 6, 7]、Mladenic等[ 8]、Kolcz等[ 9]、Lassi[ 10]、侯汉清等[ 11]、Liu等[ 12]、Yan等[ 13]都进行过研究与实验,其应用到的具体算法包括文档频率阈值法(Document Frequency Thresholding)[ 5, 14, 15]、信息增益法(Information Gain)[ 5, 6, 14, 15]、互信息法(Mutual Information, MI)[ 5, 6, 14, 15]、卡方检验法(Chi-Square,χ2)[ 5, 6, 14, 15]、期望交叉熵(Expected Cross Entropy)[ 8, 15]、文本证据权(the Weight of Evidence for Text)[ 8, 15]、几率比(Odds Ratio)[ 8, 15]、共现分析法(Co-occurrence Analysis)[ 10]、概念空间法(the Concept Space Approach)[ 10]、贝叶斯网络法(Bayesian Networks)[ 7, 10]、最大似然估计法(Maximum Likelihood Estimate,MLE)[ 11, 16, 17]等。以上算法各有优劣,本文结合前人的研究结论以及中文语言的特点,选用互信息法(MI)、卡方检验法(χ2)、最大似然估计法(MLE)三种算法进行关键词与分类号的相关度计算。
依据概率统计法的基本原理,样本集数量越大、质量越高,特征变量对应关系的可信度就越高,因此样本特征集的两个基本要求即数量足够大、质量相对高。本文选用93万篇万方学位论文库的论文作为样本特征集的基础数据来源,论文所属学科以理、工、农、医、生物为主,涵盖人文社会科学。全部论文的主题和分类标引均由人工审核完成,保证了标引质量。基础数据库的元数据结构选用馆藏号(唯一、不重复)、关键词、分类号。
鉴于基础数据库中关键词与分类号的对应关系是多对多关系,需要将数据进行拆分整理,形成以馆藏号为识别ID、关键词与分类号一一对应的样本特征集,称其为DATA1,如图1所示:
 | 图1 DATA1结构节略图 |
该特征集共有6 626 281条记录,其中关键词共计1 094 881个,分类号共计48 555个(Q95和Q951视为2个分类号)。《资料法》共有51 715个分类号(通用复分号未计算在内),DATA1中分类号的覆盖率达90%以上。
分析DATA1中分类数据呈现的特点,关键词对应分类号个数的分组统计如表1所示:
| 表1 按对应分类号个数分组统计关键词个数 |
分析DATA1中关键词数据呈现的特点,列出对应分类号最多的前20个关键词,如表2所示:
| 表2 对应分类号最多的关键词前20位 |
| 表3 “数值模拟”对应的前10个分类号 |
分析关键词词对与分类号关联关系的想法源于潜在语义索引(Latent Semantic Indexing, LSI)[ 17, 18]理论,该理论假设出现在文档中的词语并不是完全随机的,而是存在某种潜在语义结构。笔者将文档的定义范围缩小在一个关键词串中,关注各关键词彼此之间在一个数据集中的共现频度,该值越高,则词间关系越紧密。而基于这个理论设想,当一个词本身兼类时,如果辅以另外一个词,就缩小了专业领域,这好比两点成线、三点成面的道理,有助于缩小分类范围。基于此,笔者在一篇论文中,将关键词串拆分成两两组合的词对(下文称之为关键词词对),再与该论文的多个分类号进行匹配,建立关键词词对与分类号一一对应的数据集,称其为DATA2。例如馆藏号为Y343411的论文,其关键词串为:入侵检测系统;模糊专家系统;不确定性推理;模糊综合评价;网络安全,分类号串为:O159;TP11,将其拆分整理后的结构如图2所示:
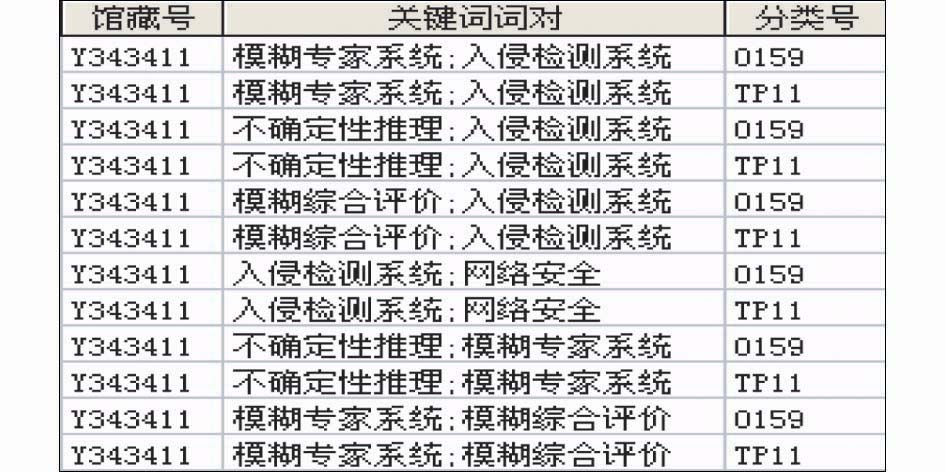 | 图2 DATA2结构节略图 |
该特征集记录数为14 173 056条,词对7 710 059对,对应分类号情况如表4所示:
| 表4 词对频次及对应分类号个数统计表 |
综上所述,通过对基础数据的整理,形成了样本特征集DATA1和DATA2,两者均可作为文本特征集进行下一步的统计分析,本文将其特征具象为关键词(或词对)与分类号,以下将通过统计学算法对两者的相关关系进行分析。
采用MI、χ2、MLE三种算法作为关键词与分类号的关联度量方法。在DATA1和DATA2特征数据集中,关键词与分类号作为两个相关变量,其关系可通过表5说明。
| 表5 关键词与分类号的相关关系 |
三种算法的计算公式分别为:
其中,a表示关键词与分类号共现的频次;b表示关键词出现而分类号不出现的频次;c表示关键词不出现而分类号出现的频次;d表示关键词与分类号均不出现的频次;X表示关键词在整个集合出现的频次,已知X=a+b;Y表示分类号在整个集合中出现的频次,已知Y=a+c;N表示特征数据集的总数量,已知N=a+b+c+d。
本文设定的特征数据集中,DATA1的N=6 626 281,DATA2的N=14 173 056。由公式(1)-公式(3)可分别计算出关键词与分类号、关键词词对与分类号的相关度理论MI、χ2、MLE值,计算结果如图3和图4所示:
 | 图3 关键词与分类号相关度理论值计算结果(节略) |
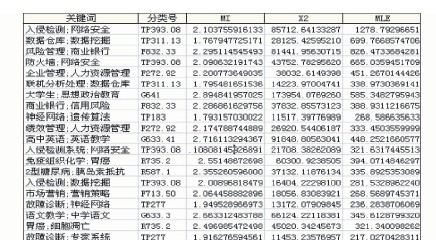 | 图4 关键词词对与分类号相关度理论值计算结果(节略) |
需要特别说明的是,在关键词词对与分类号的计算中涉及到词对中两个词先后顺序问题,例如“入侵检测;网络安全”和“网络安全;入侵检测”两个词对在本文计算中视为等同。尽管从语义的角度理解,关键词的序列对表达主题是有影响的,但是笔者采访了万方公司工作在一线的文献标引人员,他们提到实际标引中会考虑关键词是否恰当、缺失或冗余,但并没有将关键词按照揭示文献内容的相关度降序排列,因此在形成特征数据集DATA2时区别关键词的先后顺序缺乏实际意义。
在MI、χ2、MLE三个值中,需要判定最理想的理论值。本文以《中分表》为衡量标准,取每个关键词对应多个分类号中理论值最高的那组对应关系(一个关键词对应一个分类号称为一组)与之比较,词与分类号的对应关系完全一致视为重复,重复组数越多效果越好。比较结果如表6所示:
| 表6 理论计算值与《中分表》查重统计表 |
为检验表MAP1的实际应用效果,选取样本集范围内的学位论文9 514条与样本集之外的学位论文5 385条分别进行封闭测试和开放测试。全部论文均有人工审核过的关键词和分类号作为比较的标准答案。
取每篇论文的前2个关键词通过MAP1表关联得出2个分类号,然后与人工标引分类号进行比较,区分完全一致和部分一致两种情况进行统计。完全一致,即关联结果与人工标引的分类号完全相同;部分一致则包括两种情况:人工标引的分类号包含关联结果,例如人工标引分类号为“R285.5”或“R285.5;R692.5”,关联结果为“R285”,这种情况记为Y1;情况相反,关联结果包含人工分类号,记为Y2。测试结果如表7所示。同样取上述两部分数据进行了MAP2表的效果测试,结果同见表7:
| 表7 MAP系统效果统计表 |
由表7可知,整体上封闭测试效果远好于开放测试。对于开放测试的正确率仅有41.37%的原因分析如下:
(1)取词是从人工标引的关键词串中取第一和第二个词,这两个词是否能够作为文献分类的核心依据词有待商榷。如前文所述,加工标引人员未将关键词依据表达主题核心程度降序排列,由此可能导致部分数据结果偏颇。如果采用自动标引方式调节控制参数,或者在人工标引中加上一条管理措施,将可避免此类问题的发生。
(2)取词个数。是取更多词保证分类号的“全”,还是减少取词个数以保证分类号的“精”,可在实际运行中根据不同类型文献的标引需求设定阈值进行控制。
(3)制作MAP表的基础数据数量。在MAP1表的开放测试中,共有309条论文没有对应出至少1个分类号。究其原因是标引关键词的“正确答案”中共有2 242个词不在MAP1里,这一问题可通过继续扩大制作MAP1的DATA1数量加以改善。当然也不能无限制地扩大词量,需要在前期的词表建设环节中控制词汇质量。
(4)制作MAP表的基础数据质量。根据MLE值的统计方法设定关联关系仅仅是一种理论算法,它确定了大规模数据集中一对多和多对多的关系取舍问题,但对于一对一且共现频次很低甚至为1的情况还需要进一步的分析。这种问题是统计分析法的共同弊病,笔者认为可以组织专家对这部分数据进行人工处理,或者在人工实际文献标引审核的工作中不断纠错实现积累,而后一种方法更具操作性。
在开放测试数据中,有2 848条数据至少对出1个分类号,且与人工分类号无相互包含关系。对这部分数据人工检验后发现,除真正错误外,还有一部分数据分类是可以接受的,比如在中图分类号小数点后的几位有差异,这在分类标引要求不是很高的情况下,适当对关联分类号进行模糊化后处理即可进一步提高正确率。
对于封闭测试,MAP2的准确率远高于MAP1的准确率,开放测试情况则相反。这说明尽管MAP2正确率更高,但是在实际应用中匹配命中率却很低,适用性较差。加大DATA2的数据集是一个改进办法,但运行效率的问题也会随之而来。
无论是封闭测试还是开放测试,Y2的指标都高于Y1,即计算机关联结果比人工分类号更加细致或者个数更多。在正确的前提下,分类号细致加深了标引深度,分类号个数多说明揭示文献内容更全面,两种结果都是文献加工者乐于接受的。反之,在错误的情况下,则需具体问题具体分析,对于标引深度可通过调节阈值加以控制;对于增加分类号个数造成“半对半错”的情况则需要根据实际情况取舍。
关键词-分类号关联词表的应用可大大提高文献标引加工的效率和一致性,同时降低人工标引的工作量及主观差异性,优势是显而易见的。在构建关键词-分类号关联词表的方法上,统计分析法操作性强、一致性好,而且对于本文的研究成果MAP,也可通过分类法的上下级关系反向关联出关键词的词间关系,有助于构建专业词表,是对应用于计算机辅助文献加工系统的词表建设的有益补充[ 19]。
统计分析法的局限性也是明显的,它是基于大量已经人工标引的数据形成的,只能重复已经存在的情况,并不能突破这个范围,即如果出现了新研究主题,超越了统计集的范围,那么准确率和标出率都会大大降低。这在我国目前倡导创新、科研论文不断出新的情况下是非常不利的。另外,本次统计过程中也仅仅是机械拆分对应,即视关键词串中每个词对分类的作用都是等同的,并未考虑权重差异。
对此笔者将在未来的研究中继续探求更适合的相关度算法,并在计算机辅助文献标引加工系统的实际应用中加强人工校对的审核机制和反馈机制,不断修正MAP,使其成为一个持续修订的自我完善系统。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|