
{kind=link}
{kind=link}
{kind=link}
通过防火墙日志挖掘构建电子期刊数据库统计分析系统
引用本文
王孝亮, 王威. 通过防火墙日志挖掘构建电子期刊数据库统计分析系统. 现代图书情报技术, 2013, 29(7): 122-126
Wang Xiaoliang, Wang Wei. Constructing Statistical Analysis System of Electronic Periodical Databases Based on the Firewall Log Mining. New Technology of Library and Information Service, 2013, 29(7): 122-126
Permissions
Wang Xiaoliang, Wang Wei. Constructing Statistical Analysis System of Electronic Periodical Databases Based on the Firewall Log Mining. New Technology of Library and Information Service, 2013, 29(7): 122-126
通过防火墙日志挖掘构建电子期刊数据库统计分析系统
摘要
针对电子期刊数据库访问量统计的需求,构建一种基于防火墙日志的电子期刊数据库使用情况的统计分析系统,从防火墙日志文件中识别和提取所需要的字段信息,并将提取的信息存储到关系数据库中,以供检索和相关分析。以中国药科大学图书馆为例,对部分中外文电子期刊数据库进行实验,结果表明基于防火墙日志的提取方法能够很好地统计出目标数据库的访问情况,有助于图书馆决策层从宏观层面了解所订购数据库的使用情况。
关键词:
电子期刊数据库; 统计分析系统; 防火墙日志
Constructing Statistical Analysis System of Electronic Periodical Databases Based on the Firewall Log Mining
Abstract
In order to have a clear vision of usage of electronic periodical databases, a statistics & analysis system based on firewall logs is proposed. Useful field information is identified and extracted from firewall logs and stored in relational database for future analysis and research. In case of China Pharmaceutical University Library, tests are carried out on some databases of Chinese and Foreign electronic periodicals. The results show that the methods based on extraction of firewall logs can be very effective on access statistics of target databases, and it is very helpful for policy makers to have a general idea of ordered databases’usage from macro perspective.
Keyword:
Electronic periodical databases; Statistical analysis system; Firewall logs
1 引 言
随着数字图书馆的迅速发展,电子文献资源的建设与利用越来越受到人们的重视,如何运用快速有效的方法对电子期刊数据库利用率进行统计分析倍受关注。笔者以中国药科大学图书馆为例,通过对防火墙日志的收割、解压、过滤、清洗等步骤的分析和设计,实现了对图书馆订购的电子期刊数据库总体使用情况的有效统计,为图书馆对电子期刊数据库使用绩效评估起到了指导作用。
2 研究背景
为加强图书馆资源建设和更好地以用户为中心开展服务,图书馆管理层希望从宏观层面了解所订购电子期刊数据库的使用情况,及时掌握各个数据库的访问量、访问读者地域分布等信息。目前图书馆对所购数据库使用
情况的统计分析主要有三种方式:
(1)问卷调查:向读者发放问卷,根据读者反馈信息了解使用情况[ 1, 2, 3]。
(2)数据库服务商提供:向相应的数据库服务商索取数据库登录次数、下载篇数等数据[ 4, 5]。
(3)Web日志分析:对图书馆服务器的Web日志统计访问量、点击量、时间偏好等信息[ 6]。
以上三种方式各有优缺点,方式(1)可了解不同年龄段、不同学科、不同学历读者的使用情况,但样本点少,覆盖面不全,对全局范围内的统计缺少数据支撑;方式(2)可较全面掌握使用情况,但索要数据较困难且有些数据库服务商响应时间较长,时效性不强,特别是当购置的数据库很多时,须和每个数据库商沟通交流,费时费力;方式(3)能较好地反映出本地镜像数据库的访问情况,但对于大量非本地镜像数据库,读者可以直接输入网址进入而无需通过图书馆网站来访问,其数据来源不够全面。可见,上述方式均存在一定的局限性,针对电子期刊数据库访问量的统计,需要向更精细和全面的方向发展。
笔者结合实际工作需求,提出了区别于上述方式的统计分析方法:以网络中心防火墙日志为数据源,数据库IP地址为目标字符,从日志中提取含有目标字符的记录,并对匹配记录进行相关处理后进行统计分析。此方法具有如下特点:数据源能更全面、真实、客观地反映使用情况、准确性高;数据来源均在本地,可根据需要即时分析,时效性高;分析速度快,极大提升了统计效率。通过此方法可以从另外一个层面总体了解图书馆所购置的电子期刊数据库使用情况,为图书馆决策层进行成本分析和购置规划等提供真实可靠的数据支撑。
3 设计思路和方案
防火墙日志中完整地记录了每一次网络会话中的信息,通常包含产生时间、协议类型、源地址、目的地址、源端口、目的端口等信息。已有很多科研工作者对基于防火墙的日志分析进行了许多卓有成效的研究,但大多都是基于入侵检测或安全审计的[ 7, 8],没有用于统计图书馆电子期刊数据库使用的报道。中国药科大学网络中心采用的是Amaranten防火墙,syslog日志格式,日志记录每达到1GB则产生一个TXT文件并压缩存放,单个日志文件记录数约为240万条,正常情况下每天的日志记录约7 000万条。参考用于其他领域防火墙日志分析的研究成果并结合本校防火墙的现状,系统设计的核心思路是从海量日志中提取与指定数据库IP地址一致的记录,并按照指定的格式存入数据库中进行统计分析。因此系统需具备如下功能:自动获取日志文件,以便从中提取匹配记录,并按照指定的格式存入数据库中,进行统计分析;高效可行,需在新日志产生前处理完历史日志;统计功能方面,可实现对某一时间范围内各个数据库总体访问量统计、平均每天的访问量统计、读者地域类型统计等。
基于上述思路,笔者提出如下解决方案:系统由数据收割、自动解压、IP过滤、数据清洗、数据入库、统计分析6部分组成。整个方案采用C#和Perl语言混合开发,其特点是充分利用两种语言各自的优势,处理不同任务,C#处理日志解压、入库、统计分析,Perl采用正则表达式进行过滤和清洗工作。笔者采用Perl编程对关键的日志过滤环节进行了改进,处理速度相对于已有的相关研究提升了25-35倍[ 7, 8],同时针对压缩类型日志实现了自动解压功能。根据实际测算,系统每分钟处理记录数约为120万条,证明该方案处理速度快,高效可行。系统结构如图1所示:
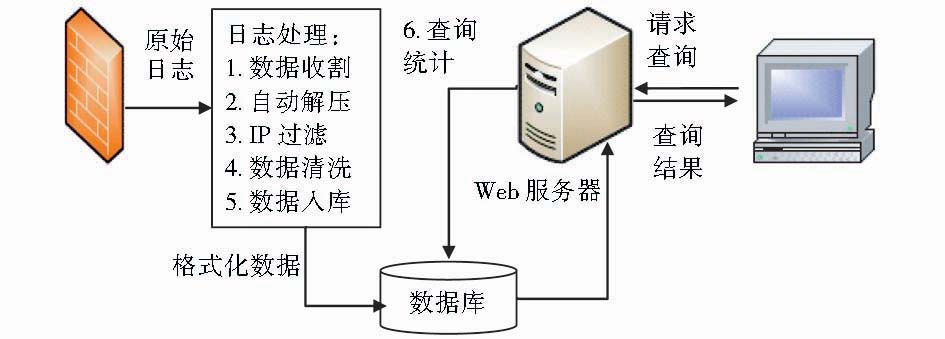 | 图1 系统结构示意图 |
4 系统设计与实现
4.1 数据收割
数据收割即数据源获取,由于网络中心防火墙服务器基于不同底层框架,没有特定的数据收割协议,因此笔者采用FTP方式进行数据源的获取。解决方法是在网络中心防火墙服务器上建立一个任务计划,定时执行批处理文件,将前一天的日志文件通过FTP命令传输到图书馆指定服务器目录上。
4.2 自动解压
防火墙日志数据量大,为节约磁盘空间,日志文件生成时进行了压缩,因此数据过滤前需要进行自动解压处理。日志文件解压的关键问题是如何实现自动执行且高效解压。实现方法是:采用C#语言开发,获取指定目录下的所有压缩日志文件,每获得一个文件即通过线程调用的方式执行WinRAR软件,同时将文件路径、解压后保存的目录、是否删除压缩文件等参数传递给WinRAR软件,解压完成后循环执行下一个文件。
4.3 IP过滤
防火墙日志记录信息具有如下特点:产生速度快、数据量大;查询难;记录内容复杂。IP过滤需要遍历所有记录,较为复杂,是本系统的重点和难点。过滤的核心思想是遍历日志文件中的所有记录,查询与指定数据库IP地址匹配的记录,从匹配记录中抽取和简化相关字段组合成新记录,写入新文件,以待下一步处理。如何实现高效的匹配是整个系统性能的关键,笔者通过文献调研[ 7, 8]和实际多种编程语言测试,采用Perl语言编程,Perl是介于低级语言和高级语言之间的一种语言,其特点是跨平台和执行速度快[ 9]。由于日志文件格式固定,因此采用正则表达式实现数据的匹配和抽取。根据需求,过滤后的记录包含访问时间、源IP、目的IP三个字段信息,其他信息被过滤掉。IP过滤的核心代码如下:
while(glob(′*.log′)){ #glob取得当前目录下后缀为log的文件名
open FI,"﹩_" or die ﹩!; #打开文件
print"打开原始日志﹩_\n"; #打印当前文件名
s/\.log/\.txt/; #文件名后缀由.log替换为.txt
﹩newfile="out_".﹩_;
open OUT,">﹩newfile";
print "写入过滤后文件﹩newfile\n"; #打印过滤后的文件名
while (
#下面为按指定格式输出代码#
@ziduan=split/\s+/;#将记录分割,以空格为分割符
if (/conndestip\=145\.36\.156\.10/) #正则表达式匹配
{.
foreach (@ziduan)
{.
if(/connsrcip/){﹩src=﹩_; }
if(/conndestip/){﹩dest=﹩_; }
}
print OUT @ziduan[4]," ",@ziduan[5]," ",﹩src," ",﹩dest,"\n";} #ziduan[4]为日期 ziduan[5]为时间
}
……
close FI;
unlink ﹩_; #删除原日志文件
close OUT;
}
4.4 数据清洗
经过IP过滤后的数据,即格式化的数据,具有字段简洁、无混杂数据的特点。但由于部分读者采用小路由接入校园网,因此会产生重复记录。在导入数据库之前,必须进行数据清洗。清洗主要目的是去重,其核心思想是建立一个Hash,将过滤后的整条记录作为索引Key值,由于在Hash中Key值是唯一的,在循环读取过滤后日志的过程中,完全相同的记录被认为是同一个Key,重复的次数则通过Value值累计保存。最终,将形成的Hash表写入新文件,以待入库。
4.5 数据入库
经过前面步骤产生的记录文件已经符合系统需求,需要将这些记录一一导入到关系数据库中,作为查询统计分析阶段的数据源。数据入库模块采用C#语言开发,将清洗后的数据文件以流的形式载入内存,逐行读取,调用编写的数据库存储过程写入数据库。根据系统需求,笔者采用SQL Server数据库,并构建了入库日志表,由时间、日期、源IP、目标IP 4个字段构成。
4.6 查询统计分析
统计分析采用B/S架构,利用ASP.NET开发。实现思路为:客户端通过浏览器请求查询相关信息,查询请求发送至Web服务器,Web服务器执行相应的ASP.NET代码,将结果以表格形式返回客户端浏览器。经过前面5个步骤的处理,如果统计的数据库IP地址较多,匹配的数据量依然很大,如何快速高效地执行查询并将结果反馈回客户端是关键。解决方法是针对不同的查询类型,在数据库中建立相应的存储过程,当有查询请求时ASP.NET通过调用相应的存储过程执行统计。
5 系统测试及效果
5.1 数据来源
笔者利用本校2013年3月21日至2013年4月12日之间的防火墙日志文件对系统进行测试。选用中国药科大学图书馆订购的部分中外电子期刊数据库进行统计,选取7个外文数据库和三大常用中文数据库,共计96个IP地址。外文数据库IP地址主要来源于中国教育和科研计算机网提供的IP地址[ 10],中文数据库IP地址主要由笔者手工收集整理。
5.2 分析指标
本文中的访问量是指客户端浏览器与目标数据库的一次“会话”,对于同一时间点同一源IP访问目标IP的不同链接计为一次“会话”,这样更能体现访问量的准确性。
5.3 测试效果
笔者对三种情况进行统计分析,结果如下:
(1)各数据库总访问量统计
各数据库总访问情况如表1所示:
| 表1 各数据库总访问量 |
从表1中可以看出,各个数据库使用率差别较大,以中文库为例,CNKI的访问量远远超过其他两个中文库。虽然三个数据库收录的期刊有一定的重复,但从收录量、检索体验等方面来说CNKI还是有一定优势的,因此访问量较大。外文数据库方面,ScienceDirect由于其综合性特点,访问量是最大的,其性价比也是最高的。其他外文数据库由于专业性较强,因此访问量相对较低。总体来看,中文数据库的访问量为79%,外文数据库访问量为21%。需要说明的是由于本馆有万方数据库本地镜像站点,实验中统计的是访问外网的万方数据总库,镜像站点访问量未计入统计。
(2)平均每天分时段访问量统计
平均每天各时段访问情况如图2所示。图2反映的是在一天的不同时间段内读者对电子期刊数据库的访问量,可以看出在峰值时间段内数据库的访问量是极大的。
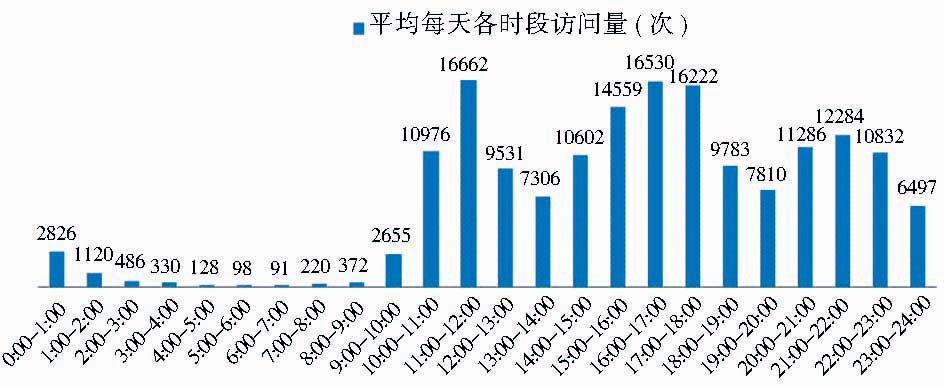 | 图2 平均每天各时段访问量 |
(3)读者地域分类访问量统计
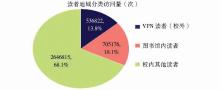
传统的文献调研和数据库服务商提供的使用报告,难以准确统计访问者来自于哪些地域通过防火墙日志中的来源IP并结合网络中心的地址规划可以准确地统计出不同地域读者访问量,如图3所示:
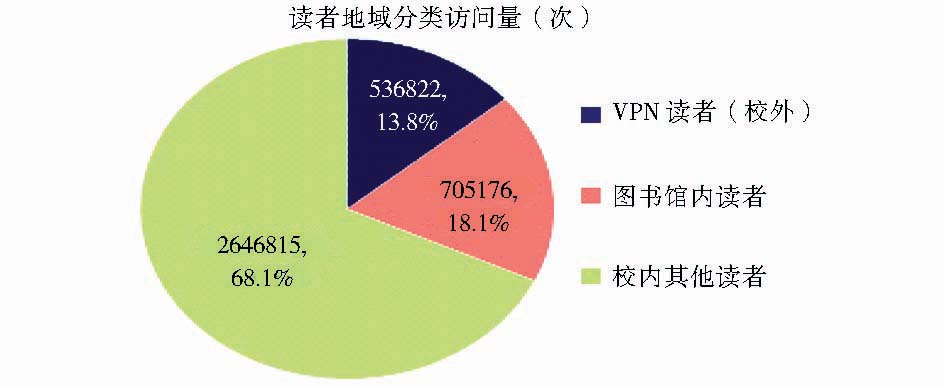 | 图3 读者地域分类分布图 |
从图3可以看出,本校读者在校园网以外通过VPN访问电子期刊数据库的比例达到13.8%,图书馆内读者访问电子期刊数据库比例达18.1%。以上数据显示本校科研工作者在校园网外也充分利用了图书馆电子期刊数据库资源进行教学科研工作,同时图书馆良好的阅读环境和学习氛围也使得馆内读者充分利用了图书馆网络访问电子期刊数据库。
5.4 误差分析
基于防火墙日志对电子期刊数据库使用情况的统计,由于一些客观原因会有一定误差,主要原因如下:
(1)目标IP地址的准确性和完整性
各个数据库地址都是基于IP地址池的,并且会不定期更改或增加新的IP地址,以降低服务器的访问压力和提高用户体验。本次测试的外文数据库IP来源于中国教育和科研计算机网,误差率较小。而中文数据库IP地址主要是由笔者收集整理,误差相对较大。
(2)IP地址被禁用
由于读者恶意下载,数据库服务商暂停某数据库的使用权限,以致访问量明显下降,这时对停用的数据库统计是不准确的。
6 结 语
本文构建了一种基于防火墙日志的电子期刊数据库访问统计分析系统,通过数据收割、自动解压、IP过滤、数据清洗、数据入库、查询统计分析6个步骤,可从全局了解电子期刊数据库相关使用数据。经过测试,该系统简单、实用、高效。运用该系统对防火墙日志进行分析,同时结合各数据库服务商提供的单库分析报告,可以从宏观和微观两个维度对所购置的数据库利用率进行全面了解。
本文的研究与实现目前还处于基础研究阶段,从测试过程和结果来看,系统在某些方面还存在不足,未来还需要从以下几个方面改进:.
(1)数据实时处理。目前数据处理有24小时的滞后,改进思路是在网络中心服务器上运行一个文件动态监测程序,一旦有新日志文件的生成,则实时数据收割并进行后续处理。
(2)优化数据库表结构,提高统计分析响应速度。目前系统数据库中建立了数据库IP地址表和日志表,入库数据均写入日志表,随着时间的推移会造成胀库的危险且查询响应慢。改进思路是以月为单位建立单独的日志表,定期删除过期记录;以年为单位建立年度访问总表,将相关数据统计汇总定期写入年度访问总表。
(3)细化统计分析功能。如根据源IP地址对读者地域分布进行更为详细的统计:不同校区图书馆访问量、图书馆各楼层和阅览室访问量、图书馆无线网用户访问量等。通过细化统计功能,使图书馆管理层能更深入、更全面地了解相关信息。
(4)增加其他辅助信息的分析统计。如提取端口、协议、网络出口类型等信息,以便网络中心有针对性地做好网络优化、提高数据库访问速度等方面的工作。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|