

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用转化SKOS和关联规则挖掘创建本体及其检索应用*
[刘巍 , 祝忠明
, 祝忠明
, 祝忠明|
|


提出一种结合转化SKOS和关联规则挖掘创建本体并实现面向知识资源集合的语义化检索应用方法。该方法首先通过转化SKOS构建本体,再对知识资源集合进行关联规则挖掘,并将挖掘结果作为概念间的关联属性补充进本体。最后,通过基于本体的应用技术实现语义化检索推荐功能。
This paper proposes an Ontology construction and application solution. Firstly, the authors create Ontology through the conversion of SKOS.Then, association rules are mined to supply association property between classes. Finally, semantic retrieval is achieved by using retrieval and reasoning techniques based on Ontology.
近年来,数字文献资源始终保持高速增长的状态。同时,用户对信息获取的需求也在不断提高。功能单一的检索方式,或者无法体现信息相关性的检索结果无法满足当今用户对于检索的需求。因此,需要建立一种灵活、高效的语义化检索推荐模式,为用户提供准确、全面的资源检索功能。
尽管传统的关键字匹配检索方式还在大量使用,但是简单的关键字匹配因无法揭示资源之间的深层语义关系而损失了查全率;同时也会因为关键字歧义而损失查准率。通过叙词表标引的方式,可以在很大程度上解决资源查全和查准的问题。但是,与本体相比,叙词表的属性相对固定,在概念间的属性扩展和多本体的互用方面叙词表是无法达到本体所具有的灵活性的[ 1]。因此,通过创建并使用本体进行语义化检索,将是实现灵活、高效检索推荐功能的一个主要发展趋势。
目前,国内外很多科研机构和学术团体都相继开展了利用叙词表转化本体以及利用本体创建语义化检索系
统的研究。其中主要包括:联合国粮农组织(FAO)利用RDF(S)将Agrovoc叙词表转换为农业本体[ 2];阿姆斯特丹大学的Wielinga等[ 3]将艺术和建筑叙词表(AAT)转换为本体;此外,还有Van Assem等[ 4]对MeSH、IPSV、GATT等词表进行了转化以及美国Syrause大学研究的教育资源网关(GEM)中的受控词表转化本体项目[ 5]等。国内在该领域的研究主要集中在将《中国分类主题词表》[ 6]、《汉语主题词表》[ 7]等转换为领域本体。
在研究和借鉴该领域现有成果的基础上,本文提出一种针对知识资源集合构建本体并实现检索应用的方法。该方法面向知识资源集合的语义化检索应用,不局限于研究针对某个叙词表进行转换,而是借用叙词表保证本体中概念以及概念间关系的权威性,并通过对知识资源集合中资源的主题词进行关联规则挖掘,将挖掘结果作为概念间的关联属性对本体进行补充,以保证概念间关联关系的可靠性。最终,实现了基于本体的语义化检索应用,并给出通过机器和人工方式实现的本体维护策略,以保证本体的可扩展性和长期有效性。
本文所述本体构建采用目前应用较为广泛的OWL描述语言,OWL通过类以及类之间属性的定义来形式化地描述领域知识[ 8]。其中类表示一组对象的集合,是对一组词条概念的抽象描述。类可设计为父类和子类,在本文所述本体构建方法中,父类和子类体现叙词表中概念间的上、下位关系。属性是类或实例之间存在的逻辑关系,可以将不同的类或个体关联起来。在本例中通过关联规则挖掘的方法补充创建本体中类之间的关联属性,并可以通过推理机进行计算。此外,还可以为类补充实例。实例是类的具体对象,即类的个体,实例之间也继承了类之间的关系。在本例中实例表示类对应概念的入口词。这种构成方式与SKOS叙词表的构成方式比较接近,可以直接将SKOS叙词表的概念、入口词、上下位关系转化为OWL本体的相关组成部分。
本文所述方法是结合目标知识资源集合的具体应用需求,将选定SKOS的部分或整体转化为本体,并通过对资源集合中的资源进行主题词标引和关联规则挖掘的方式来补充本体中类之间的关联属性。最后,通过机器和人工相结合方式建立本体补充和维护策略。
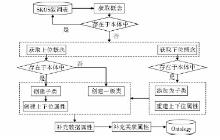
如果是针对某个知识资源集合,通过转化部分叙词表的方式创建本体,可以先用选定的SKOS叙词表中的相关概念对资源集中的关键字进行规范概念的标引,然后以这些规范概念作为类来创建本体。如果要创建一个相对完整的领域本体,也可以直接将某个选定的SKOS叙词表整体转化为领域本体,两种转化创建思路的流程相同。具体转化流程如图1所示:
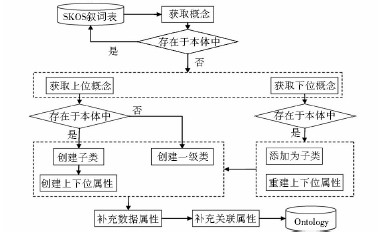 | 图1 SKOS叙词表转化为本体流程 |
(1)构建本体类Class
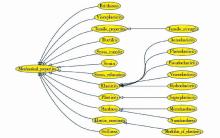
类是一组对象(子类,实例)的抽象表述,是本体构建的基础。SKOS中的概念词条是一组入口词的规范化描述,与本体中类的定义近似。因此本文方法将SKOS中的概念词条取出,并转化为本体中的类。在转化过程中同时也将SKOS中概念的结构层次关系转化为本体的类层次关系。转化后本体中(部分)类的层次关系如图2所示:
 | 图2 本体类目片段树形目录 |
(2)构建对象属性ObjectProperty
本体的属性可以分为对象属性和数据属性等,在本例中需要建立上位属性、下位属性和关联属性。在检索时可以通过这些属性来实现对检索词的上位概念、下位概念、关联概念的检索和推理。这里所说的上位、下位、关联属性都是对象属性。在本体中通过对象属性可以将不同的类关联起来,由于本体中的属性具有传递等特性,因此在实际检索时可以通过属性的设置扩展检索的范围。
在SKOS中有定义概念间的上位、下位关系。在本文方法中,在转化本体的时候,首先判断当前要转化的概念是否存在于本体中,如果存在则返回继续选择其他概念,如果不存在则转化为本体中的一级类,并判断该概念在SKOS中是否有上位概念和下位概念。如果有上位概念,则查看上位概念是否已经存在于本体中,如果不存在,则将当前概念转化为一级类;如果上位概念已转化为本体中的类,则创建当前概念的上位概念对应类的子类,并创建上位、下位属性,上位属性的domain是上位概念对应的类,range则是当前概念对应的类。将上位属性的domain和range指向的类反过来就创建了下位属性。如果当前概念有下位概念,则判断下位概念对应的类是否存在于本体中,如果存在则修改下位概念对应类的上位、下位属性。转化后本体类目层次体系结构如图3所示:
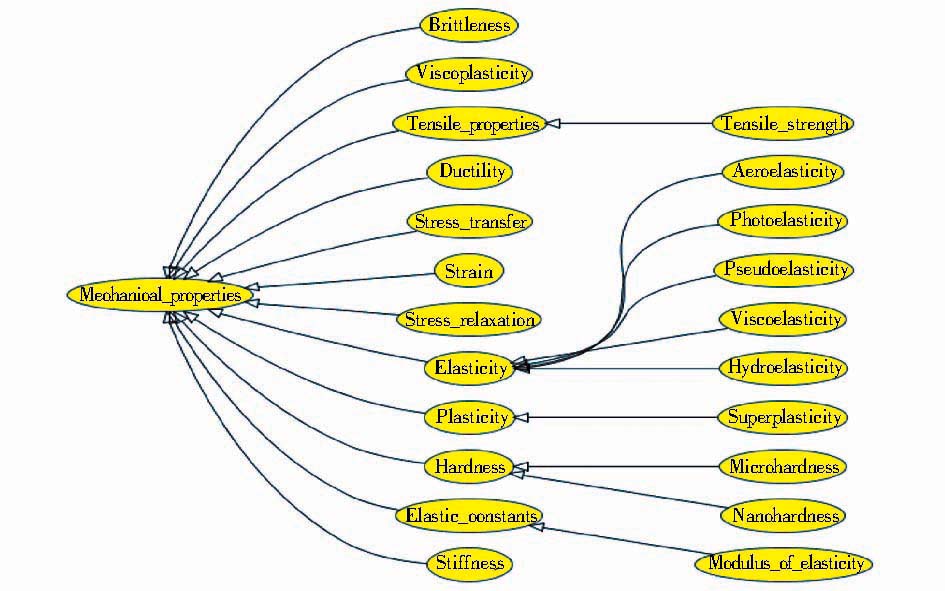 | 图3 本体类目层次体系片段 |
(3)补充数据类型属性DatatypeProperty
数据类型属性可以理解为描述一个类实例的不同数据类型的信息。本例中主要用于注释实例的一些背景信息。数据类型属性的设置比较灵活,可根据需要或根据不同SKOS所提供的信息进行补充。
(4)补充实例Individual
实例是类抽象描述的一组个体。在本文的语义化检索中,通过实例和对象的映射关系可以将一个概念的多种表述方式通过匹配实例的方式映射到规范的概念(类)上。在实际检索中,可以实现检索词的规范概念转换和名称消歧的功能。此外,在检索时还可以结合类之间的各种对象属性获取所需的其他类实例。
在本文方法中实例转化自SKOS的入口词,SKOS的入口词也可称为非正式主题词,是在词表构建中规范化处理时落选的同义词和近义词,是被合并、组代的专指词。入口词的定义可以很好地诠释实例与所属类之间的关系,因此在本方法中将SKOS中概念的入口词提取出来并转化为本体中对应类的实例。
语义化检索中要实现关联概念检索功能,还需要在不同的类之间构建一个对象属性,即关联属性。但是,不是所有SKOS叙词表都能够提供概念间的关联关系信息。因此,在无法直接从SKOS转化的情况下,需要通过其他途径获取不同的类之间的关联属性。在本文中是通过关联规则挖掘的方式获取不同概念之间的关联关系,并将关联关系作为关联属性补充到本体中。关联属性的创建在SKOS转化为本体之后进行,是对转化后本体的补充。
本文中构建的本体是为一个已存在的知识资源集合(如机构知识仓储系统)服务的,通过对资源集合中的资源进行主题词标引,并对标引后的主题词进行关联规则的挖掘,就可以获得主题词之间实际存在的关联关系。此外,本体中的属性具有传递性,即当A与B之间具有关联属性,B与C之间具有关联属性,则可以得到A与C之间存在关联属性。因此,只需挖掘出二维关联规则即可,更多维的关联规则可通过基于本体的推理获得。
在进行关联规则挖掘之前,先使用SKOS中的概念将数据集中的关键词规范化为主题词,再对主题词进行关联规则的挖掘。具体算法改自关联规则挖掘的经典算法——Apriori算法[ 9],但是因为这里只需要挖掘出二维关联规则,所以对Apriori算法进行简化。首先,确定样本空间,如果资源集合中的资源涉及多个领域,需要先将知识资源集合中的资源按照其主题涉及的领域进行划分,每一个领域所包含的资源集合即为关联规则挖掘的样本空间。确定样本空间后,利用Apriori算法挖掘关联规则依靠两个指标,即支持度和置信度。当一个频繁项集的频繁度大于支持度阈值,则由这个频繁项集产生的关联规则成为候选集,当候选集中的规则置信度大于置信度阈值时就产生一条强关联规则。
在本例中,使用某个主题词A在某领域事务数据集中出现的次数除以该领域事务数据集中的总资源数作为支持度;将A与同时出现在一个资源中的其他主题词(如B)分别组成二维关系(如AB)作为候选集,首先查看AB是否已经作为关联属性在本体中建立,如果还没有建立就在事务数据集中查看AB同时出现在一个事务中的次数并除以A在整个事务数据集中出现的次数作为置信度,支持度和置信度都大于等于某阈值(阈值可根据资源库的实际情况设定)时,则认为AB是一个强关联规则,并在本体中构建关联属性,其中domain指向A所对应的类,range指向B所对应的类。可以循环从资源集合中逐条取出资源,按上述方法挖掘关联规则并构建为本体中对应类的关联属性。
传统的检索方式一般都是通过简单的关键词匹配方式获取检索结果。但是简单的关键词匹配或模糊匹配只能检索到与关键词相同或字符构成相似的主题词所属的资源。在现实的语言环境中,一个概念可以用多个词进行表达,因此用一个单一的关键词是无法映射到用户希望获取的所有资源的。此外,字符构成相似的词并不能完全保证词义也是相似的,因此可能会检索到很多用户并不需要的垃圾信息。同时,简单的关键词匹配无法反映现实语义环境中主题词之间的逻辑关系,也就不能提供一个完整、系统的检索结果。
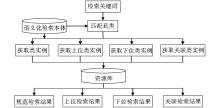
语义化检索由于有符合现实语义逻辑关系的本体介入,可以丰富和扩展关键词的语义内涵。因此,引入本体,可以很好地修正和优化传统检索方式带来的不足。在创建的语义化检索本体中,定义了关键词之间的规范、上位、下位、关联等逻辑关系,通过对这些逻辑关系的匹配和推理,可以实现从用户输入的检索关键词到规范概念、上位概念、下位概念、关联概念的检索。语义化检索功能和流程如图4所示。
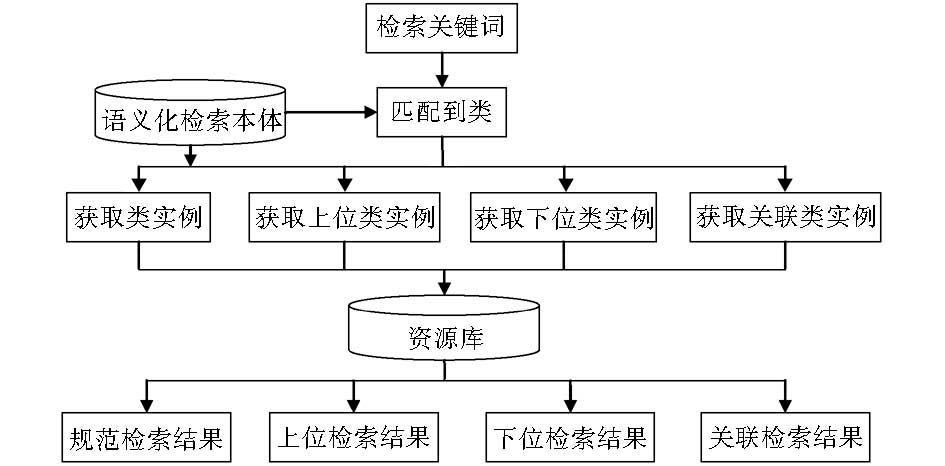 | 图4 语义化检索流程 |
(1)规范概念检索
规范概念检索是将用户提供的关键词映射为本体中的类,本体中的类表示一组同义词的规范概念,用这个规范概念进行检索,可以避免传统关键词匹配检索方法中因关键词多义、不规范、无法匹配同义词而损失的查准率和查全率,是对传统检索方式的优化和补充。
具体做法是:通过将用户提供的关键词与本体中类的实例进行匹配,获取实例所属的类,然后用这个类包含的所有实例作为关键词与资源库中的主题词进行匹配,并获得匹配的主题词所属的资源集合。
(2)上位概念检索
上位概念检索相对于规范概念检索是一个扩展检索,有推荐的作用,用户在检索过程中可能也需要了解一些当前概念的上位概念的相关知识。在这种应用背景下,上位概念检索可以简化用户的检索操作流程,为用户提供更丰富的检索结果。同时,上位概念检索也是一个规范概念的检索,可以提供多个上位关键词的匹配结果。
具体做法是:将用户提供的关键词与本体中的实例进行匹配并获得实例所属的类;获取当前类的上位类所包含的实例;采用这些实例作为检索关键词与资源库中资源的主题词进行匹配,并获得与上位概念相关的资源集合。
(3)下位概念检索
下位概念检索也是一种规范概念的扩展检索,从检索结果的角度强化了用户通过检索获取知识的系统性,可以为用户提供所需知识概念更细化的知识资源。
下位检索功能的实现与上位检索功能的实现方法类似,即通过获取当前规范概念的下位概念实例来匹配资源库中的相关资源。
(4)关联概念检索.
关联概念检索可以为用户提供与检索概念有关联关系的检索结果,丰富了检索结果的范围,使用户可以了解在实际应用中与目标概念有交互的其他概念的知识信息。
由于关联概念之间可以体现传递的特性,即A关联B,B关联C,说明A和C之间也存在一定程度的关联,因此关联概念检索实现过程中,在需要的情况下可以对关联概念进行推理,定义推理规则如下:
[rule1:(?a base:related ?b)(?b base:related ?c)->(?a related ?c)]
基于以上推理规则,可以扩展关联的范围,发现一些规范概念之间隐藏的关联关系,为用户提供一些概念之间可能存在的交互应用的启示。
语义化检索的实现界面如图5所示:
 | 图5 语义化检索界面 |
随着领域内科研的向前发展,会不断涌现出新的概念,而且概念间的关系也会随之不断发生变化。如果本体建设不能随之更新前进,将会降低甚至失去其在检索应用中的价值。因此,还需要设计一些对本体进行维护和更新的功能,以保证本体在实际应用中的时效性。
本研究为本体的维护设计了三种更新策略:.
(1)整体维护:整体维护是通过结合更新后的SKOS叙词表或更权威的SKOS叙词表对本体进行整体化的更新。更新的内容主要包括补充新的概念和调整已有概念之间的层次关系。
(2)关联属性维护:随着资源库中资源的增加,可能会有一些新的关联规则产生,因此需要对本体中的关联属性进行补充。这里的做法是,在每次资源库中增加新资源的时候,即时对新资源的关键词进行规范概念的标引和关联规则的挖掘,将新发现的关联规则补充到本体中。
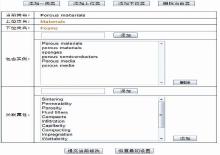
(3)人工维护:随着研究的发展,领域内出现了一些比较活跃的新概念、新关系,并且SKOS还未能及时将这些概念和关系囊括其中的时候,系统为管理员提供一个修正接口。管理员可以人工设置相应的类或补充相应的属性,同时也可以对一些过时的概念或属性关系进行人工清理和修正,以此保证本体的长期有效性。人工维护本体界面如图6所示:
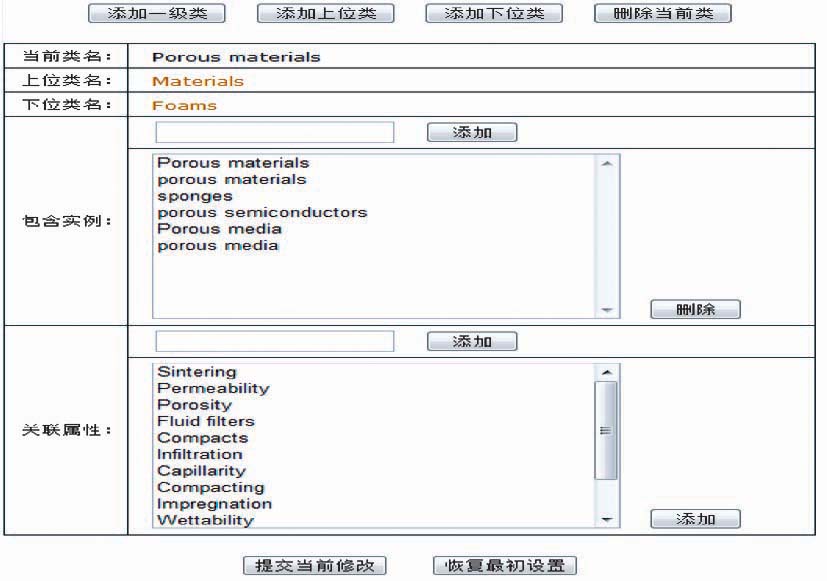 | 图6 人工维护本体界面 |
本文主要描述了一种结合领域SKOS叙词表转化和关联规则挖掘创建本体,并结合知识资源集合实现语义化检索的方法和实践。对SKOS叙词表的转化实现了从SKOS的概念到本体中类以及类结构和类之间相关属性的构建,同时应用SKOS叙词表可以保证收录概念及逻辑关系的权威性。关联规则挖掘的介入补充了本体中类之间的关联属性,同时建立在实际存在的资源集合上的关联规则,更能反映资源间的实际关联情况。通过创建后的本体,可以实现对本体中规范概念、上位概念、下位概念和关联概念的检索和推理,结合对资源库中的资源进行规范概念的主题词标引可以在资源库上建立语义化检索以及扩展推荐的应用系统。系统能够为用户提供规范概念、上位概念、下位概念和关联概念的检索。最后通过一套本体的维护策略来保证本体在实际检索应用中的长期有效性。
本文所述的本体构建、维护方法以及基于构建的本体实现的语义化检索功能,可以丰富检索的内涵和外延。在有效提高检索的查准率和查全率的同时,还能为用户提供更多符合语义逻辑的相关资源。但是,这种方法也存在一定的局限性。首先,本体只是根据SKOS叙词表的结构进行了简单转化,整个本体只包含上位、下位和关联三个属性,从本体中类之间的逻辑关系、属性到最终的推理、应用都比较初级,检索的结果也仅是基于对词表的逻辑推理实现的。这种本体和应用对于个性化的检索、推荐支撑是不足的。本体本身还可以通过补充更多的属性、约束来实现一些更复杂并有意义的推理。此外,还可以结合一些针对用户建立的本体以及建立在本体上的数据挖掘技术来更好地实现基于语义的个性化检索、推荐功能。这些不足将会在后续的工作中不断改进和完善。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|