




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种基于改进BFS算法的主题搜索技术研究
[乔建忠 ]
]
]
|
|


通过对Web主题爬行器在预测链接优先级时所用到的特征因子的细化和重新分类,引入收割率和媒体类型两个新特征作为相关性判断依据,提出一种改进的最好优先搜索算法。该算法采用“细粒度”策略过滤不相关网页,选取多个角度有代表性的特征因子构造链接优先级计算公式,以达到全面揭示和预测链接主题的目的。通过与其他三类主题搜索算法的小规模实验比较,证明改进算法在收割率和平均提交链接数上效果较好。
This paper introduces two new features——harvest rate and media type as the basis to judge relevance, by refining and reclassifying all kinds of characteristic factors that are used by focused crawlers to predict the priority of Web links, and proposes an improved Best-First Search algorithm. The algorithm uses “fine-grained” policy filtering irrelevant Web pages, selects multiple angles representative characteristic factors and constructs a links priority formula to reveal and predict the subjects of Web links comprehensively. The small-scale experiment comparing with the other three topic search algorithms demonstrates that the improved algorithm has a better performance on harvest rate and the average number of links submitted.
主题搜索(Focused Crawling)技术是用于在互联网中对相关资源或兴趣资源进行自动发现的技术。主题搜索技术的系统实现一般称为主题爬行器(Focused Crawler),是专门用于从互联网上大规模收集特定主题信息的软件系统[ 1]。当前它也是构成垂直搜索引擎或Web信息采集系统的关键组件。主题搜索技术中的关键问题之一就是启发搜索策略,经典的启发策略包括宽度优先(或广宽优先)、深度优先和最好优先等。而搜索算法是启发策略的具体实现,在本文中特指一种针对Web资源的超链接分析技术,即自动识别相关链接并为之排名的算法,如Page-Rank和HITS(Hypertext Induced Topic Search)等。最好优先搜索算法(Best-First Search, BFS)是根据一定的规则总是优先访问最有价值的节点[ 2],其在主题搜索技术中的应用则是根据已经获得的网页,利用一定的启发策略来推断主题资源的分布情况,然后采用最好优先的原则每次优先选择优先级最高的链接进行下一步的抓取。
本文首先对Web主题爬行器在预测链接优先级时所用到的特征因子进行梳理和分类,提出一种改进的最好
优先搜索算法。其中重点论述了用于预测链接相关性的新特征因子和运用这些特征因子采用细粒度策略过滤不相关网页的链接优先级算法。为证明所提算法的优势,选用“radius-1”[ 3]、Topic-Relevant PageRank[ 4]和Topic-Relevant HITS[ 5]三种主题搜索算法与本文原型系统CMSCrawler进行对比实验,并选用多个指标客观评价各算法的表现和新特征对改进算法的影响。
特征因子(Characteristic Factors)是指来源于Web用于预测链接与主题相关性的各种证据。Pandey 等[ 6]将特征因子分为两类:依赖于内容的,如标题、正文关键词;独立于内容的(Content-independent),如链接字符串、锚文本、主机别名、入度(或后向链接数)。并认为对于陌生链接而言,其优先级取决于独立于内容的特征。该分类略显宽泛和模糊,在实际操作中较难把握,例如链接字符串和锚文本均对反映网页的内容起到重要作用,如果将其列为独立于内容的特征不符合实际情况。本文将与判断相关性有关的特征因子分为6类,从不同层面反映了其对启发策略的影响。6类特征因子分别为:
(1)文字内容特征,如标题、正文、粗体字、锚文本、链接本身文字、锚邻近文本等;
(2)Web拓扑特征,如权威度、中心度等;
(3)主题分布特征,如相关网页局部聚集的特征(父网页相关则子网页也可能相关等)、主题稀疏特征、隧道效应等;
(4)文档类型特征,如论文、课件或新闻等各自独特的表现形式等;
(5)统计特征,如TF、IDF、RIDF等;
(6)时效性特征,如更新时间、更新间隔等。
各类特征因子都与计算陌生链接的优先级有关,但各自所起的作用不尽相同,因此一般采用分配相关性权重的方法来决定特征因子的影响程度。因此通用的链接优先级计算公式可归纳为: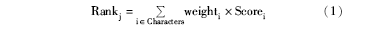
其中,i表示特征因子,j表示被预测的链接,Rank表示链接优先级值,Score表示特征因子的相关度值,weight表示特征权重,如果某项特征的权重为0则表示该项特征未被启用。
众多特征因子不可能同时投入到预测链接的相关性判断策略中,必须兼顾效果和性能。实际上在不同应用领域所使用的特征因子各有侧重。目前存在的问题是对特征因子的应用规则比较模糊,选择上相对片面。多数启发策略主要依赖文字内容特征和Web拓扑特征的组合来实现[ 4, 5, 7],很少考虑主题分布、文档类型等特征。
目前针对最好优先算法的改进重点集中于优先级计算公式的优化,而且启发策略中的组合策略多数是内容特征与Web结构特征的组合应用策略。从Page-Rank[ 8]到HITS[ 9]再到Topic-Sensitive PageRank和HITS+Topic-Sensitive PageRank[ 10]等可看出这种多特征因子的综合应用趋势。
PageRank搜索算法基于整个网络的链接结构来计算各网页的重要性,但该算法适合发现权威网页,不适合发现主题资源[ 11]。HITS算法基于特定查询主题的网络子图,计算速度比PageRank快,但HITS搜索算法容易引起主题漂移。Topic-Sensitive PageRank搜索算法则是Haveliwala[ 4]在其研究中为解决PageRank算法的主题宽泛问题,基于Chakrabarti[ 3]提出的相关网页互相指向的假设,增加了对网页内容相关性的判断。HITS+Topic-Sensitive PageRank是Shchekotykhin[ 10]等提出的搜索策略,在存在大量无关网页的环境下如何迅速定位目标网页,需要充分挖掘首页、菜单、导航条、网站地图或HUB页,其认为HITS与Topic-Sensitive PageRank算法相结合比单纯使用HITS更好。上述搜索算法研究中对特征因子的综合运用多局限于内容特征与Web结构特征的组合,其他如文档类型特征等未考虑在内。
国内与本文所提算法较接近的研究首先是陈竹敏[ 12]在其博士论文中提出的一种基于多粒度优先级计算的自适应主题爬行算法(AFC-PUMG)。AFC-PUMG是指利用站点、网页内容、相关链接块、锚文本、URL地址和链接类型6种特征,从站点级、网页级、块级和链接级等不同粒度来计算待爬行链接的优先级。其提出的“一个站点到目前为止已爬行的相关网页数(相关度总和)的增速可以用来衡量该站点的TCURLs的优先级”与本文提出的收割率在预测链接优先级上的作用有异曲同工之处。该算法重点解决了如何去除网页中的噪音,提高优先级计算的准确性,但参与预测链接优先级的特征仍然以文本特征和Web拓扑特征为主。
其次,傅向华等[ 13]、黄莉等[ 14]和谭骏珊等[ 15]均提出利用基于强化学习改进的爬行算法,该方法的特点是具有在线增量自学习能力。其基本思想是从获取的页面中抽取特征文本,根据特征文本评估页面的主题相关性,预测链接的Q值(相关于优先级),然后基于Q值过滤无关链接。该类算法所依赖的特征比较单一,重点解决的是主题搜索过程中的隧道效应问题,即在目标网页稀疏的情况下,远期奖赏建模的效果显得较为突出。
与以上研究相比本文提出的最好优先搜索算法具有两个特点:采用“细粒度”策略过滤不相关网页;选取内容特征、Web拓扑特征、主题分布特征、文档类型特征以及统计特征等多种类型的特征因子用于优先级算法,并且加入两个新特征因子:收割率和媒体类型(MIME Type)。
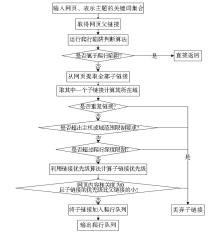
由于被网络爬行器预测的链接有可能来自相关或不相关的网页,算法在总体设计时就需要综合考虑对不相关网页的处置原则,因此本文设计了两种针对不相关网页的处理策略:一种是传统的最好优先启发策略即对不相关网页直接丢弃,本文称之为“粗粒度”策略;另一种是对不相关网页中的链接进一步鉴别相关性的“细粒度”策略。粗粒度策略过滤了大量无关链接,在一定程度上可能会提高抓取的准确率,但同时也会因为网页相关性判断的误差导致大量有用链接流失,因此该策略比较适合用户对检准率要求高的情况或在训练分类器的阶段使用。细粒度策略则是对相关或不相关网页的子链接均进行优先级预测,但只将优先级大于父链接且父网页也相关的子链接排入优先级队列。细粒度策略的BFS算法流程如图1所示。
 | 图1 采用细粒度策略的BFS算法流程 |
该算法的前提是对相关或不相关的网页均预测其子链接的相关性,但重点是对于不相关网页子链接的处理,即以其与父链接的优先级为参考,如果子链接的优先级小于父链接的优先级则这样的子链接将被丢弃。父链接的优先级与父页面的相关度是两个不同的值,虽然两个值都是主题相关性的体现但前者表达的是页面在未下载前的预测值,而后者是经网页分类算法验证后的结果。对于那些已经判断为不相关的网页如果它的子链接的预测优先级小于父链接当初的优先级,那么子页面验证为相关的可能性较小或称为信心值较低,则该子链接被丢弃;相反则送入队列中。由于增加了对无关页面中子链接的预测工作,因此细粒度策略要比粗粒度策略耗费较多的系统资源。
链接优先级的计算重点是特征因子的选取,因此本文为合理选取特征因子制定了三项规则:
(1)针对不同类型的主题侧重使用不同的特征,有所侧重的特征其权重应较大。例如:针对面向内容主题的抓取任务,目前文字内容特征是主要判断依据,如锚文本等,同时媒体类型特征也作为一项判断依据但重要性不如锚文本高,因此权重较低。
(2)为适应不同的爬行环境侧重使用不同的特征。例如:遇到隧道效应问题时,由于文字内容特征严重缺乏甚至它的相关度为0,如果放弃则可能损失召回率,这种情况下对Web拓扑特征和主题分布特征的依赖性加大。
(3)选择易于获取且尽可能不通过第三方工具得到的特征因子。这主要是出于对性能的考虑和减少对外界和不确定因素的依赖。
本文采用的特征因子有5类共7个,其中包括:文字内容特征(取锚文本和链接文本)、Web拓扑特征(取后向链接数)、主题分布特征(取父页面相关度和收割率)、媒体类型特征(取网页的MIME Type)和统计特征(取相对词频)。
其中后向链接数(入度)并没有在全局范围内计算而采用一个替代方案,取爬行器已经访问过的并被判断为相关的后向链接的个数,即在相关结果集中求得共同指向当前网页的相关网页数。
收割率反映了主题爬行器快速找到目标网页的能力。Chakrabarti等[ 1]提出的收割率等于时间t内已下载的目标网页数与时间t内已访问的网页数(包括丢弃的)的比值。该计算方法适用于通用网络爬行器,针对主题爬行器应关注目标网页的主题相关性。因此笔者修改了计算方法如下所示: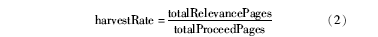
本文提出的收割率等于全部相关的网页数除以全部处理过的网页数。处理过的网页数并不等于已下载的网页数,下载的网页中需经过语种识别等手段过滤掉不合格网页后才能真正用于处理,因此处理过的网页数是全部下载网页的一个子集,它比使用已下载的网页数参与收割率的计算更精确。收割率在一定程度上反映了主题的分布情况,例如当爬行器处于一个主题相对稀疏的区域中时,处理的网页数增长较快但相关的网页却相对很少,因此这种情况下收割率较低。收割率较高则相应赋予链接较高的优先级可指导爬行器向着高相关度区域爬行。
相对词频用来计算锚文本或链接文本中相对于查询关键词的相关度值,它等于绝对词频除以锚文本或链接文本中的总词数。
陌生链接的优先级就是爬行器在下载其页面内容之前对新遇到的链接经过算法计算得到的相关性预测值,它是衡量链接是否符合主题相关性的概率值。在笔者归纳的通用优先级计算公式(见公式(1))的基础上,按实际特征选取方法对其进一步具体化,如下所示:.
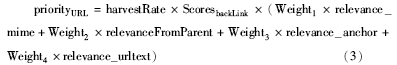
其中,使用收割率harvestRate反映主题分布特征,当收割率变大时,优先级也相应增大,此时链接被优先下载;使用后向链接数ScoresbackLink反映Web拓扑特征,后向链接数相当于当前链接的权威度,或称之为“入度”,权威度变大时,优先级也相应增大,此时链接被优先下载。harvestRate和ScoresbackLink实际上作为权重的一部分参与到计算公式中。
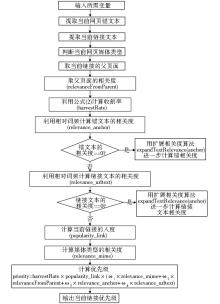
relevance_mime表示媒体类型相关度。媒体类型是反映类型主题的重要特征之一,例如论文的媒体类型以application/pdf等比较常见,如果当前链接对应的媒体类型也是application/pdf,那么它是论文的可能性也较大,新闻、讲义等类似。根据相关网页相互链接、聚集的特征[ 16],父页面相关性对子页面相关性有正面影响。父页面相关度较高relevanceFromParent,其子链接相关度也较高。内容特征选用了relevance_anchor和relevance_urltext两项特征,锚和链接文本都是预测链接相关性的重要内容特征,尽管其包含的词语较少但起着十分关键的作用。例如锚和链接文本中的关键词通常反映了某网站或网页的性质和目录结构,因此锚和链接文本的权重相对较高。具体算法流程如图2所示:
 | 图2 链接优先级算法流程 |
其中,expandTextRelevance()方法用来实施扩展相关度算法;权重ω1-ω4目前采用的是经验值,例如对于媒体类型相关度、父页面相关度、锚文本相关度和链接文本相关度4项特征的权重分别取值为0.2、0.2、0.3和0.3,锚与链接文本的权重相对较高是因为它们是预测优先级的主要特征,而且本文利用它们实施隧道策略即扩展相关度算法[ 17];收割率的计算采用全部相关网页数与全部已处理网页数的比值,而链接优先级采用公式(3)计算得到。
在实验方法上,笔者借鉴了前人的比较实验方法,例如Krishnakumar等[ 18]采用了将其“STAIR”爬行技术与Google、Yahoo等检索结果比较的评估方法。另外为考察本文提出的新特征因子在预测链接优先级中的作用,专门设计了媒体类型MIME预测贡献率并对其进行了相关统计分析。而收割率在预测链接优先级中的作用,本文将它作为一项总体指标放在搜索算法的总体性能中进行比较。性能是主题爬行器必须考虑的因素,因此笔者专门比较了各算法的平均提交链接数和平均用时两个性能指标。
与本文算法进行对比实验的主题搜索算法有三个,分别是“radius-1”[ 3]、Topic-Relevant PageRank[ 4]和Topic-Relevant HITS[ 5],并将“radius-1”作为基准比较对象(Baseline)。这三种算法具有一定的代表性,是目前主题爬行器系统中经常使用的三种经典的主题搜索算法。Baseline基于“radius-1”假设,也是“软聚集爬行”的基本策略。该技术假设父链接相关那么其子链接相关的可能性大于其他随机链接。在计算子链接的优先级时直接将父链接的相关度作为其子链接的优先级排入待爬行队列。Chakrabarti[ 3]同时也提出“radius-2”假设,是在“radius-1”的基础上增加了对待预测链接的后向链接数的计算。其与HITS类似实际上是基于一种权威度或共引假设,为避免重复因而未启用“radius-2”作为Baseline。在判断链接主题相关性方面,Baseline只采用了文字内容特征,而Topic-Relevant PageRank和Topic-Relevant HITS均采用了文字内容特征和Web拓扑特征。而依据本文算法实现的原型系统CMSCrawler不仅运用了文字内容特征和Web拓扑特征,而且还加入了主题分布特征(收割率)和媒体类型特征(MIME Type)。
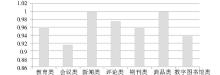
由于一方面较难获取其他三种算法的运行系统,另一方面部分对比技术如Topic-Relevant PageRank被应用在大型搜索引擎系统中,较难模拟真实的场景,因此在本文原型系统CMSCrawler中按照不同主题搜索原理分别搭建各算法的实验环境,用于模拟三种对比技术。为客观比较,其他环境设置均采用相同参数,例如采用相同的主题查询关键词、种子地址、网页解析手段、预处理方法、分类算法和可识别的语种范围等。为观察搜索不同主题上4种算法的表现,本文选用多类主题进行对比实验,这些主题包括教育类、会议类、新闻类、评论类、期刊类、商品类和数字图书馆类。有关实验环境配置、关键词和种子地址选用等具体实现细节可参考文献[19]。
(1)收割率比较.
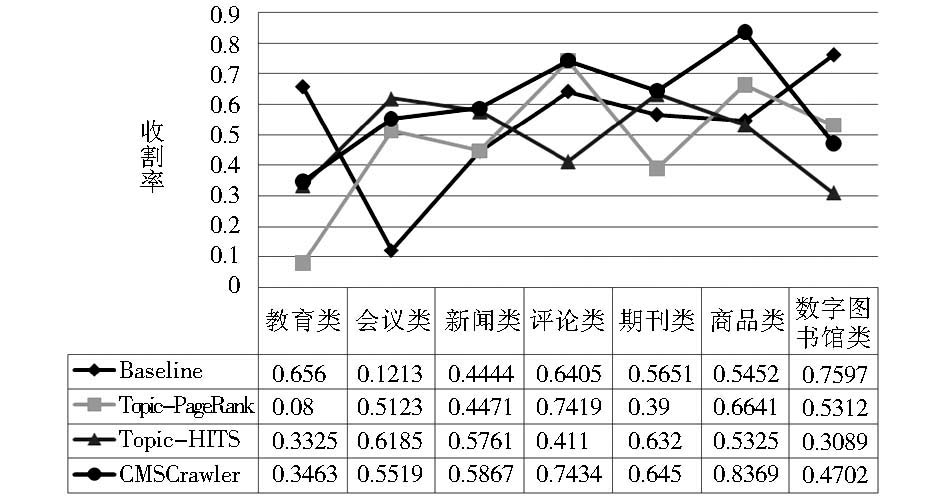
实验时设置每种算法在各类主题抓取500个左右的相关文档后自动停止。统计各算法的收割率,结果如图3所示:
 | 图3 4种算法的收割率比较 |
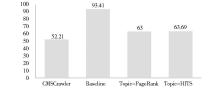
各算法平均收割率对比如图4所示:
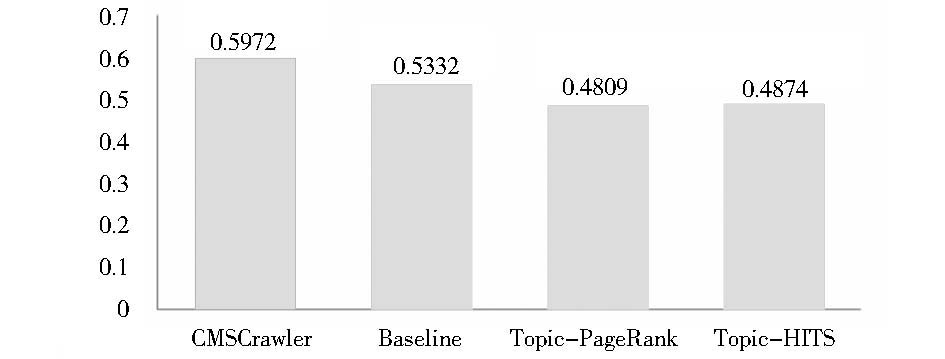 | 图4 平均收割率对比图 |
从实验结果可知,4种主题搜索算法在各主题上的表现互有高低,从平均水平看出4种主题搜索算法差距并不明显。CMSCrawler在各主题搜索技术中略占优势。
(2)平均提交链接数比较.
“平均提交链接数”指标,用于评价主题搜索算法的工作效率,其实际意义在于以较少的工作量换取较多的相关网页。平均提交链接数等于预测为相关并提交给优先级队列的链接数与验证为相关的网页数的比值。各算法在不同主题类别上的工作效率比较如图5所示:
 | 图5 4种算法的平均提交链接数比较 |
各算法平均提交链接数在所有主题类别上的平均值对比如图6所示:
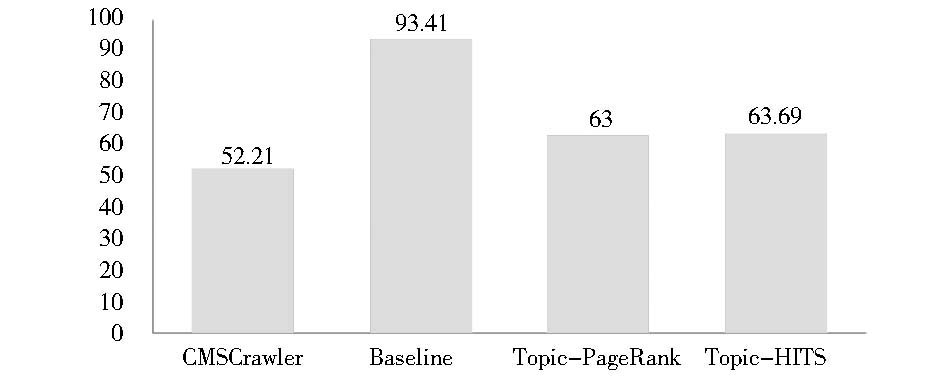 | 图6 平均提交链接数平均值对比图 |
从实验结果可以看出,由于根据“radius-1”假设,Baseline将相关网页的所有子链接都当作相关子链接送入优先级队列而不进一步加以筛选,因此它是以较多的链接提交数量换取了较高的收割率。而Topic-Relevant PageRank、Topic-Relevant HITS与CMSCrawler的平均水平相差不大,是因为它们都采取了进一步的过滤措施,如拒绝优先级为0的链接进入队列等。尽管各主题搜索算法对收割率的影响并不大但对系统工作效率却有较大影响,如果提交的链接当中含有一定数量的无关链接,则会浪费系统较多资源。相反将无关链接无原则地全部丢弃也会遗漏一部分实际相关的目标,因此应在保证收割率的前提下对提交的链接数量进行必要的控制。
(3)平均用时比较.
平均用时是指采用主题搜索算法预测链接相关性的平均时间效率。如果主题爬行器在主题搜索过程中提交给优先级队列中的相关链接数为TotalPredictedLinks,总用时为TotalDuration,则主题爬行器每发现一个相关链接的平均用时为TotalDuration/TotalPredictedLinks。各算法在各主题类别上的平均用时统计结果如图7所示:
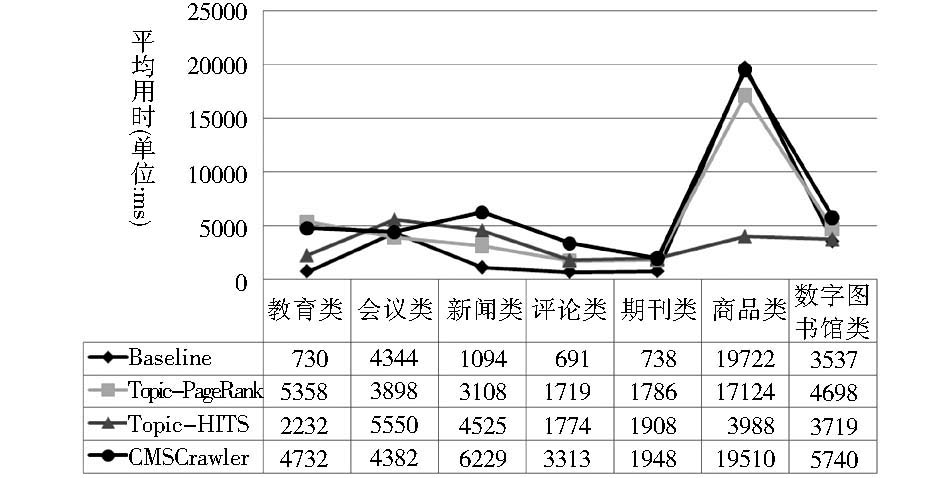 | 图7 平均用时对比图 |
各算法在各主题类别上的时间效率平均值比较如图8所示:
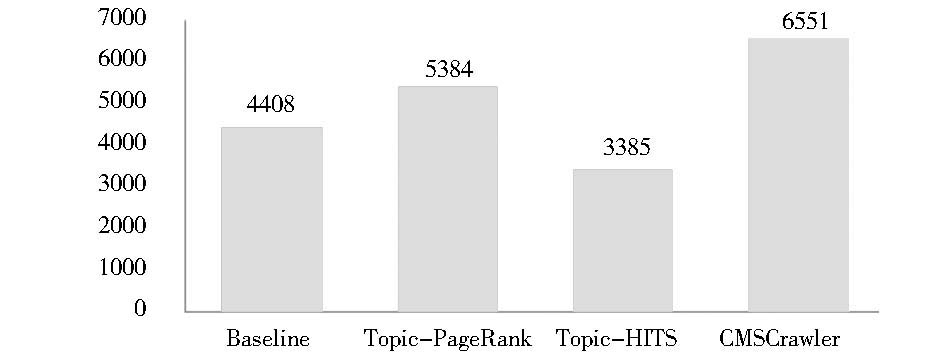 | 图8 平均用时的平均值对比图 |
实验结果表明,Topic-Relevant HITS的平均用时最少,在各主题上的表现比较均匀,证明其确实比PageRank运算速度要快;Baseline由于采取比较简单的算法策略在教育类、评论类、期刊类和新闻类等主题抓取上用时最少,但平均水平不如Topic-Relevant HITS;CMSCrawler由于将较多种类的特征因子加入到链接相关性预测中,而且增加了KBES隧道策略[ 17](该策略需要扩展搜索知识库),因此其综合表现稍微落后于其他三种算法。
此外,将MIME预测贡献率(MIMETypePrioRatio)用于评价媒体类型在链接优先级预测中的效果,笔者提出以下公式:
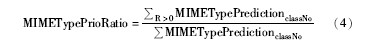
媒体类型在预测链接优先级中的贡献率与具体的主题相关,等于某类主题下的媒体类型判断相关度大于0时的次数与该主题下全部媒体类型预测次数的比值。其中classNo表示参与实验的某主题的所属类,R表示相关度。本文算法在各主题类别上的MIMETypePrioRatio比较如图9所示:
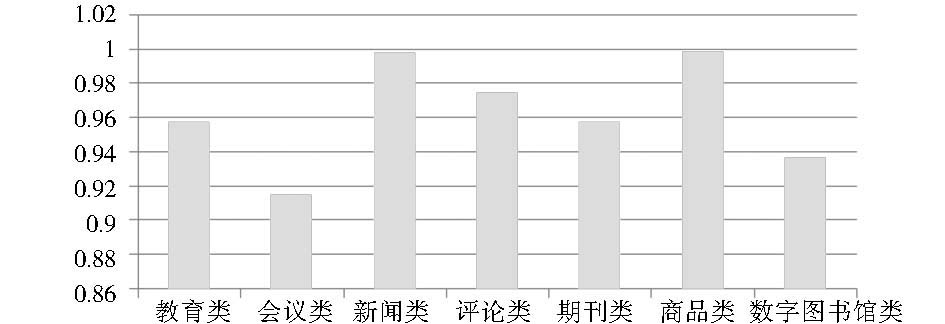 | 图9 MIME在预测不同主题链接优先级中的贡献率 |
MIME类型是本文在计算陌生链接优先级时引入的一个新特征,结果表明MIME类型用于预测链接相关性时起到了一定的作用。但各类主题的预测贡献率均较高也说明“text/html”或“application/xhmtl+xml”仍是各类资源的主要形态,相反“application/pdf”、“application/msword”、“application/vnd.ms-powerpoint”、“application/vnd.ms-excel”或“text/plain”等特殊媒体类型只占各类资源的较小部分。因此MIME类型在预测链接优先级时在各类主题之间表现出的差别性不大。
本文分析了当前主流主题搜索技术的原理和不足之处,对特征因子进行了重新梳理和分类,构造了一般意义上的特征选取规则和链接优先级计算公式,重点提出了预测链接相关性的新特征因子、综合运用多类特征因子的链接优先级计算公式以及最终形成的细粒度过滤策略等。通过较小规模的实验证明本文方法综合效果较好,与其他搜索算法相比在收割率和平均提交链接数上均表现出不同程度的优势。但本文算法仍存在效率偏低的不足。在性能对比实验中,CMSCrawler在识别相关链接的时间效率上落后于Topic-Relevant HITS、Baseline和Topic-Relevant PageRank搜索算法。为准确评估爬行器各算法运行的细节特征,程序被注入了大量日志记录探针,这势必会加重运行负担从而降低性能。如果要投入实际应用需要重点改进系统性能,具体包括合理分配线上与线下的工作、改进数据库存取方法、减弱日志记录详细程度和减少调试信息的输出等。此外,尚需大规模的实验进一步证明本文方法的优势。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|