
{kind=link}
{kind=link}
互联网用户偏好本体实例的学习方法研究*
[朱恒民1  , 贾丹华
, 贾丹华2 , 黄震奇3 , 王春晖1 ]
, 贾丹华|
|


互联网用户偏好本体可以全面、准确地描述出互联网用户的兴趣和多维偏好。针对偏好本体中主题类的实例对象数量众多、不断扩展变化、手工搜集工作量大这一问题,重点研究用户偏好本体中主题专业网站、品牌和体育赛事三类具有代表性的实例学习方法,以期实现互联网用户偏好本体的半自动构建,并设计实验验证这三类实例学习方法的有效性。
Internet user preference Ontology can fully and accurately describe the interest and multidimensional preference of Internet users. In order to effectively resolve the problem that a large number of instances which are expanding and varying are hard to collect manually, the learning method of three representative instances including the topic professional website, brand and sporting events is researched. This method can achieve semi-automatic construction of Internet user preference Ontology. The experiments are designed to verify the effectiveness of the method.
互联网正逐渐渗透到人们生活、工作的各个领域,深刻地改变着信息时代的社会生活。互联网用户获取信息资源的浏览行为反映出用户当时的消费倾向与行为偏好。如果能够分析互联网用户的浏览行为,采用科学的分类体系来标记和描述用户兴趣和偏好,对于商家实现精细营销是非常有意义的。
本体可实现对某一领域知识的共同理解,并以形式化模式明确词汇间的相互关系。引入本体来描述和表达
互联网用户的偏好可有效克服偏好主题词的多样性、模糊性等缺陷,并实现偏好主题之间的语义推理。因此,笔者构建互联网用户偏好本体,以期全面、准确地描述出互联网用户的兴趣和多维偏好。
由于互联网用户偏好本体构建的数据来源是广大互联网用户访问过的海量信息资源,而且各个领域中不断有新的概念在扩充、修正与完善,构建工作量非常大。考虑到偏好本体中主题的分类体系是相对稳定的,而具体主题类的实例对象(如汽车的品牌)是在不断扩充和完善的,因此本文重点研究结合人工干预的本体实例半自动学习方法,以期实现互联网用户偏好本体的半自动构建。这对于丰富和完善偏好本体、及时地捕捉用户兴趣的动态变化,都具有非常重要的意义。
本体正在越来越多的应用中发挥作用,如何以自动或者半自动的方式构建和演化本体是目前人工智能、文本挖掘和信息搜索等多个领域的重要研究课题[ 1],特别是面向非结构化数据的本体学习技术,引起了众多学者的关注。一些学者研究了基于语言学的本体概念学习方法,即根据领域概念的特殊词法结构或模板,寻找和抽取结构符合这些特定模板的字符串[ 2, 3, 4];根据领域概念与普通词汇拥有不同的统计特征而设计的基于统计的方法也广泛地用于本体概念的抽取[ 5, 6];刘豹等[ 7]结合语言学和统计学技术,提出了一种科技术语识别的混合方法;谷俊等[ 8]利用TF-IDF方法计算中文专利文本中特征项的权重,通过筛选得出专业术语。上述方法主要是从文本中学习出领域本体概念或者专业术语,文本中的领域概念和专业术语是相对不变的,而互联网资源中本体实例是不断扩充和完善的;且专门针对本体中实例学习的研究工作相对较少。柳佳刚等[ 9]采用改进的TF-IDF方法和复合事件的关联规则算法探索了Web页面信息本体的概念和概念间关系的学习,但该方法学习的准确率不高,且要求学习对象是结构有一定规律的数据导向型页面;连乐新[ 10]研究了一种实例信息的抽取和匹配方法,但需要基于领域词典和领域本体进行;夏亚梅等[ 11]采用描述逻辑来表示汉语语法句式,建立了一个有限汉语语法学习系统LCGAS,以期解决服务组合领域中本体实例生成问题。
互联网用户偏好本体是一种包含众多主题的通用本体,其中实例种类多,形式多样,且不断扩充和完善。如何利用网络信息资源特点,高效、快速地抽取出互联网用户偏好本体实例的方法尚需要进一步的研究。
通过文献调研、领域专家咨询和参考分类网站目录等方式,笔者自顶向下手工构建出互联网用户偏好本体的概念层次结构[ 12],部分结构如图1所示:
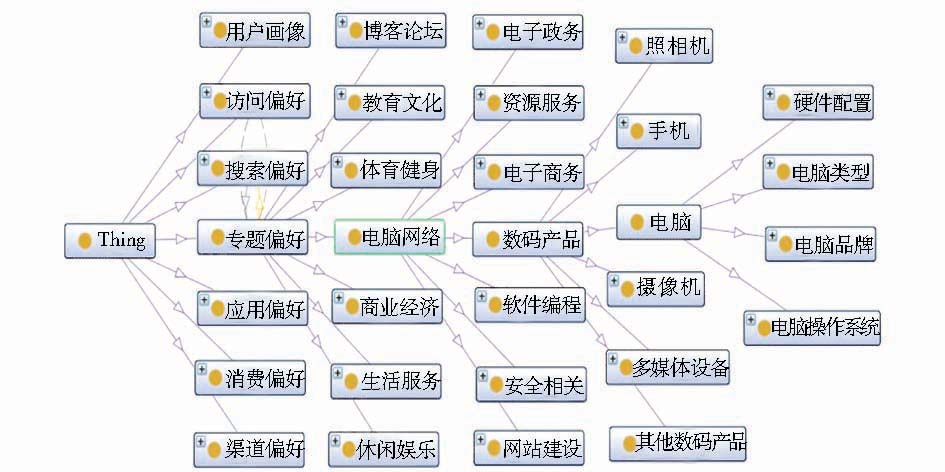 | 图1 互联网用户偏好本体的概念层次结构(部分) |
以Protégé4.2软件默认的“Thing”为最高类,然后下分为“用户画像”、“访问偏好”、“搜索偏好”、“专题偏好”、“应用偏好”、“消费偏好”和“渠道偏好”等二级子类,再逐级向下建立子类的子类。二级子类中,专题偏好描述了用户浏览互联网信息时所感兴趣的主题信息,它对于捕捉客户的兴趣偏好和消费倾向具有重要意义。由于偏好本体是面向整个互联网信息资源,因此专题偏好下包含了电脑、游戏、音乐和读书等众多主题子类,主题子类下又包含了众多实例对象。例如,在“专题偏好”中的“电脑”主题下有“电脑品牌”子类,其下就包含了联想、惠普、华硕等众多品牌实例。偏好本体中主题子类概念及其关系是相对稳定的,而各主题子类的实例对象是在不断扩充和完善的,例如电脑品牌随着时间的发展不断有新的品牌出现。互联网用户偏好本体中实例种类众多,笔者统计出“专题偏好”下共有98种实例,其中40种是各类主题的专业网站,25种是各类主题的品牌,20种是各类体育赛事,其他包括编程语言、即时通讯工具和家政服务项目等主题类实例。尽管偏好本体中实例种类繁多、形式多样,但是每一大类的实例一般是有规律可循的。例如,虽然主题不同,但各类主题的品牌实例往往是一些专有名词或音译人名。因此完全有可能在人工干预下实现偏好本体实例的半自动学习。
考虑到专业网站、品牌和体育赛事三大类实例数量占偏好本体中实例种类总数的87%,且这三类实例的半自动学习方法各不相同,具有代表性,因此本文重点研究这三类实例的半自动学习方法。
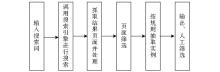
考虑到互联网用户偏好本体中实例数量众多且具有动态变化特点,为了及时地搜集和捕捉偏好本体实例及其动态变化,本文充分利用网络信息资源组织特点和信息搜索工具,提出了互联网用户偏好本体实例的半自动学习方法,该方法的学习过程如图2所示:
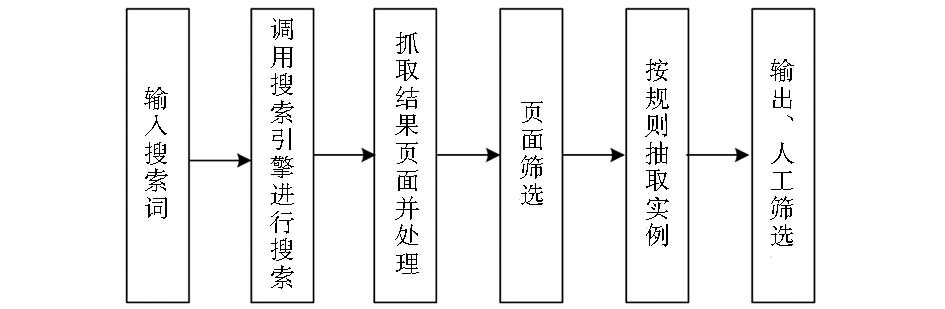 | 图2 实例半自动学习的一般过程 |
用户在实例学习系统里输入实例所属的主题类名称;程序自动调用通用搜索引擎,以该主题类名称为搜索词提交搜索;程序逐条抓取、处理和筛选搜索引擎的反馈结果,并按照为该类实例定义的规则抽取实例;通过可视化窗口输出抽取结果,结合人工和频率统计进行筛选。在偏好本体实例学习的整个过程中,根据主题类与实例的位置、词性等特征定义实例抽取规则,是实例学习的关键步骤。将针对主题专业网站、品牌和体育赛事三大类实例研究其学习规则和实现算法。
互联网用户偏好本体中,专题偏好下每个主题子类的专业网站实例主要用来描述和刻画用户访问感兴趣主题的网站偏好。尽管在通用搜索引擎中以“某主题网站”为关键词搜索也能得到一系列结果,但是搜索引擎返回的结果往往是一些包含关键词的页面,而非该主题的专业网站。而且众所周知,一些搜索引擎返回结果是依据竞价来排名的,并不能真正反映网站的专业化程度。分析多个主题的专业网站,一般具备两个特点,即页面上有大量的超链接且网页中主题词出现的频率较高。本文基于通用搜索引擎抓取出读书、音乐、相机和书法等主题的422个网站,经人工判别,其中有328个属于专业网站,94个属于非专业网站,这也说明对通用搜索引擎的反馈结果进行筛选的必要性。该实验中网站主题词频率和超链接数量统计情况如表1所示。
| 表1 网站主题词频率和超链接数量统计 |
从表1可知,专业网站超链接数量和主题词频率在平均值和中位数上都大幅度高于非专业网站,这也说明较高的超链接数量和主题词频率是专业网站的重要特征。为了评价网站的专业化程度,本文定义了网站专业度prof的计算方法,如下所示: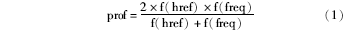
其中,href为网页中出现的超链接数量,freq为搜索词经分词产生的所有主题词在网页中的出现频率,这里要考虑标题的重要性,为title中出现的主题词频率乘以权重系数w,表1中取w=20。公式(1)中函数f(x)取值要满足“x越大,f(x)趋向于1;x越小,f(x)趋向于0”这一变化趋势的约束,因此笔者定义f(x)=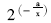 ,a为统计指标的中位数,在上述422个网站的统计中,超链接数量指标的中位数为238.5,主题词频率指标的中位数为98。专业网站实例的半自动学习方法步骤如算法1所示:
,a为统计指标的中位数,在上述422个网站的统计中,超链接数量指标的中位数为238.5,主题词频率指标的中位数为98。专业网站实例的半自动学习方法步骤如算法1所示:
算法1 ProfWebLearning( )
Input:实例所属的主题子类,处理的搜索结果数量n;
Output:该主题的专业网站实例列表;
①以主题子类作为搜索词,自动调用通用搜索引擎进行信息搜索;
②对输入的搜索词进行分词,得到主题词列表s;
③For each pi do{//pi前n个搜索结果中的第i个页面
④统计s在pi中的加权频率,得到freq;
⑤统计pi中的链接数量,得到href;
⑥依据公式(1)计算pi的专业度;
⑦}按照专业度大小从高到低排序,输出该主题的专业网站列表。
互联网用户偏好本体中具有实例的主题子类名称往往由多个主题词组成,例如主题子类“汽车专业网站”包含“汽车”、“专业”和“网站”等主题词,算法1中步骤②是将主题子类名称经分词产生出所有主题词,以便统计出主题词在网页中的出现频率。
品牌实例描述了客户浏览互联网信息时对所感兴趣商品的品牌偏好,它有助于商家更好地实现精细营销。分析各类商品的品牌实例,笔者发现品牌往往集中出现在该主题的专业网站,例如在爱卡网等汽车专业网站中汇聚了各种汽车品牌。而且在专业网站的页面信息组织中,品牌名称往往作为一个单个的词或图片的锚文本出现,而非出现在一个句子中,因此,基于上下文语法分析或基于统计的方法就不能有效地用来学习品牌实例。通过对页面内容进行分词和词性标注后,笔者发现绝大部分品牌实例的词性为专有名词或音译人名,且在某类主题专业网站的页面中,绝大部分专有名词和音译人名往往也是该主题的品牌。因此,本文定义品牌实例的学习规则为:首先找到该品牌所属主题的专业网站,对页面进行分词和词性标注,结合词性筛选和词频统计抽取出品牌实例。品牌实例半自动学习方法的步骤如算法2所示:.
算法2 BrandLearning( )
Input: 实例所属的主题子类,处理的搜索结果数量n,专业度阈值p_min;
Output:该主题的品牌实例列表;
①以主题子类作为搜索词,自动调用通用搜索引擎进行信息搜索;
②For each pi do{//pi前n个搜索结果中的第i个页面
③自动调用ProfWebLearning( ) 计算pi的专业度prof(pi);
④If prof(pi)≥p_min then {
⑤对页面pi进行分词和词性标注;
⑥筛选出词性为专有名词和音译人名的词,添加至品牌实例列表,并累计出词频;}
⑦}按照词频从高到低输出该主题的品牌实例列表。
体育赛事实例可以描述互联网用户对具体赛事的关注兴趣和偏好。由于体育赛事名称表达形式多样,名称组成元素往往是时间、地点等一些通用词汇,因此其实例的学习具有一定挑战性。通过分析体育赛事名称的语法结构和单词词性,本文归纳出赛事名称表达的一般模板:(m)(+x)(+ns)(+n)…(+n)+赛,其中m是数词,往往表示年份;x为字符串,往往是一串英文字符,例如网球赛事中的“WTA”;ns为地名;n为除地名以外的各类名词;*为通配符,*赛表示以“赛”结尾的单词,但是要过滤掉“马赛”、“禁赛”、“加赛”、“比赛”、“观赛”、“开赛”和“参赛”等与赛事名称无关的词汇;括号表示该元素在体育赛事名称中是可选的,不是必须出现的。上述模板表示体育赛事名称往往由一个表示时间的数词、一个字符串、一个地名、若干个其他类名词和以“赛”结尾的词构成。例如,“2012北京国际网球公开赛”经过分词和词性标注后为“2012/m 北京/ns 国际/n 网球/n 公开赛/n”。通过分析通用搜索引擎反馈的关于体育赛事搜索结果,笔者发现体育赛事实例并不一定集中出现在体育专业网站,“百度知道”和“百度百科”也有某项体育的赛事名称,因此体育赛事实例的学习不需要对搜索结果依据专业度进行筛选。体育赛事实例半自动学习方法的步骤如算法3所示:
算法3 GameLearning( )
Input: 实例所属的赛事子类,处理的搜索结果数量n;
Output:该赛事的实例列表;
①以赛事子类作为搜索词,自动调用通用搜索引擎进行信息搜索;
②For each pi do{//pi前n个搜索结果中的第i个页面
③对pi页面进行分词和词性标注;
④调用GameTempMatch( )依据赛事模板进行前向匹配,结果添加至赛事实例列表,并累计出词频;
⑤}按照词频大小输出赛事实例学习结果。
函数TempMatch的前向匹配过程如下:针对页面经过分词和词性标注后的字符串,首先通过查找和筛选,提取出包含“赛”的单词;然后从该词位置前向查找和提取出所有连续的名词,直至地名为止;再从该词开始通过前向查找先后提取出字符串和数词,构成赛事名称。上述前向匹配过程是针对字符串中所有包含“赛”的单词进行。
笔者采用开发工具Microsoft Visual C++ 6.0实现了互联网用户偏好本体实例的半自动学习系统,系统采用NLPIR汉语分词工具(http://ictclas.nlpir.org/)和中国科学院计算技术研究所汉语词性标记集对网页文本内容进行分词和词性标注处理。
实验分别针对专业网站、品牌和体育赛事实例的半自动学习效果进行分析,采用准确率P和召回率R来评价偏好本体实例的学习效果。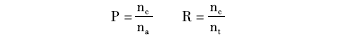
其中,na表示系统输出的实例数目,nc为na中正确实例的数目,nt表示实验文集中所有的正确实例数目,nc和nt是由人工来判断。
依据算法1分别选取读书、音乐、相机和书法4个主题子类进行实验,通过自动调用搜索引擎共采集了422条实验数据,其中读书专题119条搜索结果,书法专题118条,相机专题87条,音乐专题98条。基于人工判断识别出实验数据中包含328条专业网站,取专业度阈值p_min=0.4时,专业网站实例学习的实验结果如表2所示:
| 表2 专业网站实例学习的实验结果 |
依据算法2分别选取电脑和手机两个主题子类进行实验,取网站专业度阈值 p_min=0.3,处理的搜索结果数量n=30,实验结果如表3所示,其中f为实例学习系统输出词汇的频率。
| 表3 品牌实例学习的实验结果 |
依据算法3分别选取排球和乒乓球两个主题子类的赛事实例进行实验,取通用搜索引擎返回的前20个结果为实验文集。由于实验数据中存在相当数量关于同一赛事的不同表述,例如“世界锦标赛”与“世锦赛”,因此,笔者在分析实验结果时都将其作为一个赛事进行处理,实验结果如表4所示:
| 表4 赛事实例学习的实验效果 |
本文研究了偏好本体中具有代表性的主题专业网站、品牌和体育赛事三大类实例的半自动学习方法,该方法充分利用互联网信息资源组织特点和搜索工具,高效、快速地抽取出偏好本体实例,有效地解决了本体构建过程中主题类实例数量众多、动态变化、手工收集工作量大这一难题。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|