{kind=link}
基于社会标签的文本聚类研究*
[何文静 ]
]
]
|
|


以社会标签在网络资源聚类中的作用为研究目标,筛选标注资源的社会标签作为特征项,采用K-means聚类算法对文本资源进行聚类,并在小规模测试集上得到较好效果。详细讨论基于社会标签的文本聚类中标签筛选、聚类方法等关键技术的实现过程。通过实验证明:基于社会标签的文本聚类是一种较传统关键词进行聚类更为有效的一种聚类方法,能够提高文本聚类的效果。
In this paper, the authors select social tags which are used to annotate resources as feature items. Text clustering is implemented by K-means, a kind of clustering algorithm, and successfully conducted on small data set. The implementation of primary technology, such as tag filtering, clustering algorithm, in text clustering based on social tagging is discussed in details. By the experiment, it is concluded that text clustering based on social tags performs better than keywords, which can improve the clustering results.
社会标签(Social Tagging)作为一种新型网络信息组织方式,由网络信息的提供者或者用户自发为某类信息赋予一定数量的标签,选用自由词对感兴趣的网络信息资源进行自上而下的描述和揭示来实现网络信息的分众分类,正在改变着传统的网络信息组织模式,被广泛应用在图书馆、博物馆、企业、商业以及科研教育领域。社会标签在某种程度上具有主题法的特征,较传统的主题词其具有更大的灵活性、易用性,同时资源描述性关键词的增加也便于对资源进行准确查找,尤其是对多媒体资源来说,用户所标注的标签信息就更为重要。
然而实际标注行为中,由于用户的知识背景不同、用户标注行为遵循“最省力原则”等原因导致垃圾标签的产生,使得社会标签的价值受到了很大的质疑。基于社会标签进行文本聚类是否是一种可行的文本组织方法?社会标签在文本聚类中的作用如何?本文探讨了基于社会标签的文本聚类方法,设计特征标签的选择方法并对文本聚类算法进行选择。通过对比实验证明:基于社会标签的文本聚类方法是一种有效的文本组织方法,然而垃圾标签的过滤以及标签中词间关系的建立仍然是影响基于社会标签进行文本聚类的重要因素。
基于标签的文本聚类,旨在通过标签对相关文本进行聚合,近年来国内外学者尝试从不同角度进行研究。Christopher从Tag的定量分析角度,通过对Technorati中排名前350的Tag以及分享同一Tag文章的相似性进行定量研究,分析了Blog标签分类的有效性[ 1]。Al-KhalifaScott等[ 2]通过测量Folksonomy和Yahoo关键词设置的重叠率对基于相同网站的Yahoo API文本语词抽取技术和Folksonomy进行评价。Ramage等[ 3]将社会性标签引入到基于LDA的K-means和启发式聚类方法中,对基于Web文本的聚类算法提出了改进。王波等[ 4]分析传统RSS聚合的不足,提出标签比重概念和基于标签比重积累的文档聚类算法。Kim等[ 5]分析了Inter-Est系统,该系统使用SCOT本体描述用户的标签云结构,帮助用户发现共享同样兴趣的小组,允许用户整合标签云,实现相似标签云的检索。通过计算用户和标签间的相似度以及标签与标签之间的相似度,杨丹等[ 6]从用户-标签-文本中提取相关关系,提出了基于用户喜好的文本聚类方法。张云等[ 7]根据词共现信息对文本集去冗余并排序,从而获得候选聚类标签,基于该标签对文本进行聚类。Heymann等[ 8]提出将大量的标签转化为可导航的层次结构分类目,将标签所标注的资源次数表示成向量形式,计算标签的相似度,最后得到潜在层级分类法。窦永香等[ 9]利用Porter算法对英文标签进行词根提取,依据用户的精确度要求对相关标签进行聚类。
总体来说,目前主要集中于对社会标签之间聚类算法的研究以及基于社会标签进行相似用户的发现和资源推荐,而在基于社会标签改善文本聚类效果方面的研究相对较少。本文旨在探讨在Web2.0环境下,基于高质量用户的社会标签对所标注资源进行文本聚类来改善网络信息资源组织的效果,从而更好地揭示社会标签在网络资源聚类中的作用。
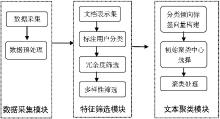
以研究社会标签在文本聚类中的作用为主要目的,设计基于社会标签的特征选择方法,筛选出具有聚类特性的特征标签,继而采用K-means方法,利用筛选后的标签对文本进行聚类,通过测评来评价该方法的有效性。本研究分为数据清洗、标签的特征选择、基于标签的聚类算法设计以及依据聚类效果分析标签作为揭示文本内容的工具时对文本内容的组织能力等几个步骤。总体研究设计如图1所示:
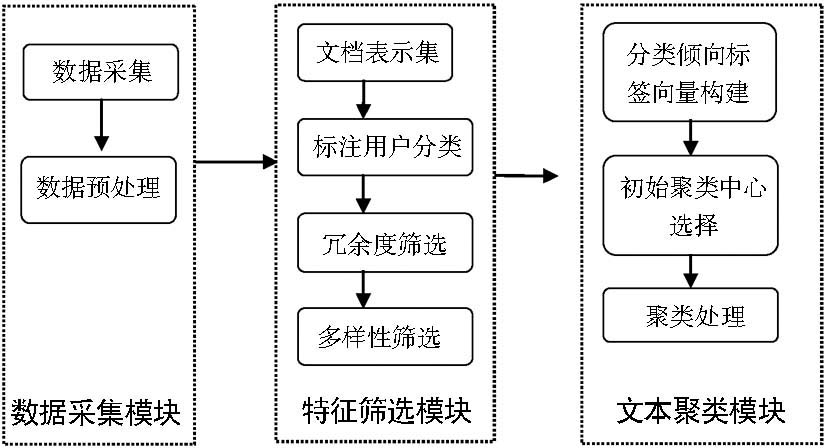 | 图1 总体研究设计 |
(1)数据采集模块:主要功能是采集大量数据,形成文本数据集,并对文本数据进行预处理,如去除噪音数据,规范化处理等,确保文本集中数据的有效性,以减少无关数据对实验结果造成的干扰。
(2)特征筛选模块:主要功能是选取揭示文本内容的社会标签作为特征词项。通过一定的筛选方法对标签进行选择,过滤垃圾标签,使标签在表达文本主题的基础上具有一定的区分性,而且概念明确客观。
(3)文本聚类模块:主要是采用向量空间模型,将文本均用特征向量表示,以文本相似度为衡量指标,采用一定的聚类方法对文本集进行聚类,使数据集中的数据形成若干个类别体系。
(4)实验分析模块:按照一定的方法和指标对聚类结果优劣进行评价,将聚类结果进行对比,分析标签作为揭示文本内容的工具时对文本内容的组织能力。指出实验的不足,并提出可能改进的方法。
为了保证本实验中搜集的所有数据集中的标签具有一定的语义标识能力,对数据进行如下清洗:
(1)单词小写化:英文标签被转化为小写字体,更容易对其进行字符串比较;
(2)符号、乱码过滤:将含有乱码的标签删除,若标签中含有标点符号,且该符号在标签中具有意义(如Web2.0中“.”是标签组成部分)则保留,其余含有符号的标签均被剔除;
(3)数字过滤:若标签中含有数字,且该数字在标签中具有意义(如H2O中“2”是标签的组成部分,去掉后意义改变)则保留,其余含有数字的标签均被剔除;
(4)停用词过滤:若标签为停用词,则剔除该标签。
社会标签作为一种新型网络资源分类方式,为广大Web用户提供了更多自由分类共享的机会,但同时由于其非专业性使得基于标签的分类系统通常难以保证分类的一致性。为了保证标签聚类的一致和完备,本文首先采用Strohmaier提出的用户动机理论将数据集中的用户划分为分类倾向用户和描述倾向用户[ 10],继而利用TF-IDF方法对分类倾向用户的标签进行权重计算,并依此对标签进行筛选。
分类倾向用户为了便于浏览和管理资源会选择没有相同含义并且概念明确、客观、区分度强的标签,长期使用标签系统之后就会形成一个没有冗余的简单而又稳定的词表。而描述倾向用户会从不同角度选择概念作为标签,长期使用会形成规模大、易变化、开放性强的词表[ 11],从标签冗余度和多样性两个方面提出了三个衡量用户动机的指标:

其中,|Tu|表示用户u使用的标签数,|Ru|表示用户u标记的资源数。TRR的值越小,则用户标注动机越倾向于分类。
(2)ORPHAN[ 10](低频标签使用率)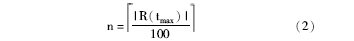
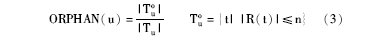
其中,n表示阈值,大于n则为描述倾向用户;|R(tmax)|表示被使用次数最多的标签所标注的资源数;|Tou|表示用户u使用的低频标签个数。ORPHAN的值越小,则用户标注动机越倾向于分类。
(3)TPP[ 10](Tags Per Post)
其中,|Ru|表示用户u标记的资源数;|Tui|表示用户u标记资源i所用标签数;r表示数据集中资源总数。TPP的值越小,则用户标注动机越倾向于分类。
将经过标签特征选择后的数据组记作C(a,t,v),其中a为网站地址,t为分类动机的标签,v为该标签在资源中所占的权重。由于数据集中的文本均为英文,故只需去除停用词后识别分隔符即可达到分词效果。本文采用TF-IDF方法对文本中实词进行降序排列,TF-IDF方法根据词项在文档和文档集中的频次计算词项的权重,在一定程度上能代表该文本的内容,因此实词的TF-IDF值越大,其解释文本主题内容的能力就越强,即认为其为关键词。
对数据集进行聚类之前,需要先建立信息特征。本文采用基于向量余弦值的方法进行文本聚类,用特征向量表示文档,所有的文档均可用向量(T1,V1,T2,V2,…,Tm,Vm)表示,其中Ti表示特征词项,Vi表示Ti在该文档中的权重,m表示向量维度。对具有m个特征属性的n篇文档计算余弦值,第i篇文档与第j篇文档间的余弦值可表示为: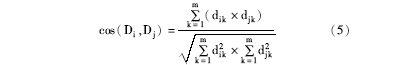
其中,dik表示第i篇文档中第k个特征项的权重,djk表示第j篇文档中第k个特征项的权重。当两向量余弦值越大时,两文本的相似度越高,被归为同一类别的可能性越大。
基于向量余弦值的聚类方法有多种,考虑到处理数据集的大规模性、结果簇内紧凑性以及簇和簇之间的相互分离,通过多种聚类结果的比较,笔者最终采用K-means聚类方法。
K-means聚类的具体过程如下:.
(1)确定聚类结果簇的个数k,形成簇集合S={S1,S2,…,Sk},从数据集T={T1,T2,…,Tn}中随机选取k个数据元素,分别作为k个簇的中心;
(2)分别计算剩下的数据元素与k个簇中心的余弦相似度,将这些数据元素分别划归到相似度最高的簇中;
(3)依据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数;
(4)将数据集T中全部数据元素按照新的中心重新聚类;
(5)重复步骤(4),直到簇集合S中每个簇内数据元素不再变化。
Filckr、豆瓣、Delicious、各大博客网站等均为社会标签网站,在本实验中,笔者选取用户共享性较高、涉及领域较广的Delicious作为数据采集的来源。抽取了约10万条用户u使用标签t标引网页a的数据作为训练数据,该数据组合记作D(u,a,t)。抽取出的网页a及其文本内容c构成的数据组合记作H(a,c)。从数据集中人工挑选出300个网页作为测试数据,记作网页集合H{h1,h2,…,h300},涉及体育、计算机网络、商业经济、教育等10个类别,每个类别包含约30个网页。
将已采集的原始数据集中的每个网页都用向量P(T1,W1,T2,W2,…,Tn,Wn)表示,其中Ti为标签,Wi为该标签的权重。将经过标签筛选后的数据集中的每个网页都表示为向量C(T1,W1,T2,W2,…,Tm,Wm),其中Ti为筛选后的标签,Wi为该标签的权重。将网页集合H中所有网页的P向量表示的集合记作HP(p1,p2,…,p300),将网页集合H中所有网页的C向量表示的集合记作HC(c1,c2,…,c300)。
(1)评价方法
为验证标签作为一种自组织的分类方式比传统的关键词标引方法更具有组织和管理网络资源的能力,将基于标签的文本聚类结果与基于关键词的文本聚类结果进行比较,依据经典的TF-IDF方法从待分类网页的题名及内容中抽取关键词。
(2)评价指标
本文采用纯度和熵值来衡量聚类结果。纯度定义如下[ 12]:
其中,ni表示簇Si的大小,nji表示簇Si与第j类的交集大小,k为最终聚类形成的簇的数目,一般纯度越高聚类效果越好。
熵值刻画了同一类数据在结果簇中的分散度,熵值越高,聚类结果越差,熵值定义如下[ 12]:
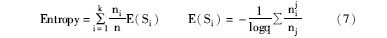
其中,ni表示簇Si的大小,nji表示簇Si与第j类的交集大小。
(1)基于筛选标签—基于关键词的聚类结果比较
将关键词作为特征项的聚类结果与将筛选后标签作为特征项的聚类结果进行对比,试图区分标签和关键词在文本聚类中的能力大小。关键词聚类和标签聚类的效果如表1所示:
| 表1 基于动态聚类的关键词和标签聚类结果 |
笔者认为产生关键词聚类效果与标签聚类效果差异的主要原因如下:.
①仅依据网络资源文本中权重大小所挑选的关键词所表达的语义是隐含的,不能清晰、准确地表达信息的概念和含义。标签则不同,它是用户对网络资源进行阅读和理解后的产物,在一定程度上是对信息内容的精炼。例如,资源S是足球购物网站,资源内容以足球产品介绍为主,文本抽取的关键词中含有Football,用户赋予的标签为Shop,资源F是足球新闻网站,文本抽取的关键词含有Football,用户赋予的标签为Sport。基于关键词的聚类会把资源S和资源F归为一类,而基于标签的聚类则不会将资源S和资源F归为一类。以关键词为特征项时,关键词复用率较低,同一关键词标记的资源数较少,造成通过该特征项对网络资源的聚类效果远不如使用标签聚类的效果。
②用户倾向于对多个类似的网页标记相同的标签,例如,资源A是篮球新闻网站,资源B是足球新闻网站,资源A基于文本抽取的关键词为Basketball,资源B抽取的关键词为Football,基于关键词的聚类将可能把资源A和资源B分到不同类别中,而用户则认为这两个资源具有相似性,都赋予了标签Sport。
(2)未处理标签—筛选标签聚类结果对比.
以用户为自变量,对每个用户的三个指标按升序排列,可获得用户-指标排名数据组合记作B(u,r(TRR),r(ORPHAN),r(TPP)),其中按每个用户的三个指标的排名之和进行升序排列可对用户的动机进行综合评价,分类倾向的强度随着所占名次的增加而降低。取前1/100名用户,认为其为分类动机最强的用户,他们通过高度概念化将标签视为一种资源分类的方式,因此这些分类动机较强的用户所使用的标签也是相对最具分类倾向的,对网络资源聚类的一致和完备具有积极效果。通过筛选,只保留具有分类倾向标签所标注的资源。
将未处理标签的聚类结果与筛选后的标签聚类结果进行对比,试图从标签选择的角度来优化文本聚类效果。聚类结果见表1,该表显示了标签筛选前后的文本聚类熵值和纯度。从表1可以看出,标签经过筛选后对文本聚类效果起到了一定的优化作用。
(3)不同聚类方法的结果对比.
为了探讨不同聚类算法对聚类结果的影响,本文同时使用了层次聚类算法进行测试。层次聚类算法是一种会聚式聚类算法,为了达到对比的效果,设定层次聚类的终止条件是类目数量达到了动态聚类的类目数。采用层次聚类的结果如表2所示,同表1动态聚类结果的各项指标相比,动态聚类效果均优于层次聚类效果。
| 表2 基于层次聚类的关键词和标签聚类结果 |
①许多标签网站都具有推荐功能,依据“最省力法则”,用户可能不加思考直接使用别人标注过的标签,从而导致一些垃圾标签的广泛使用,对内容揭示起到误导作用,因此探索大规模的深层次的垃圾标签筛选方法与机制,仍然是基于社会标签进行资源组织的重要内容之一。
②标签并不是独立的,标签之间也存在着一定的语义联系,例如标记资源A的标签为Basketball,标记资源B的标签为Football,A与B应该同属一类,然而在机器聚类处理不考虑标签关系的情况下,A与B可能被分到不同类别。因此,在基于社会标签的文本聚类中,如何有效地进行同义词、等级词的识别是提高基于社会标签的文本组织的另一项重要内容。
本文以标注资源的社会标签为聚类样本,设计基于社会标签的特征选择方法,利用K-means聚类算法对文本资源进行聚类,并与基于文本内抽取的关键词的文本聚类效果进行对比,通过实验验证基于社会标签的文本聚类效果优于关键词聚类(TF-IDF方法筛选)效果,在一定程度上可以优化社会网络资源的组织与管理。由于网络资源的更新速度快,文本中机器抽取的关键词并不能准确表达资源含义,标签作为大众知识汇聚的对资源内容提炼的结果,在一定程度上更能连接同类资源,因此笔者认为基于社会标签对文本进行聚类是一种有效的文本组织方法。然而本文的研究仍然存在不足,虽然筛选标签可以改善聚类效果,但聚类精度仍需要进一步提高,如本实验中尚未考虑标签的同义、层次等关系,在后续实验中会考虑将标签之间的相关程度以量化的形式参与到文本聚类中。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|