

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向中文图书的自动标引模型构建及实验分析*
[王昊 , 邹杰利
, 邹杰利
, 邹杰利|
|


针对中文图书关键词自动标引问题,引入条件随机场机器学习算法,通过对大量已有的中文图书手工关键词标引数据进行训练和学习,生成包含序列实体之间语义关系和规则特征的标注模型,并利用该标注模型进行机器预测,自动抽取出图书关键词。主要解决两个问题:鉴于条件随机场模型的参数选择会影响到系统的标注性能,从多个角度进行对比实验,确定针对中文图书关键词标引这一特定问题的条件随机场模型的最佳参数集合;探讨不同的观察特征对关键词标引的影响,通过实验论证4个能够有效提高标引性能的观察特征。最终建立起面向中文图书的最佳关键词标引模型。
For the problem of automatic keywords indexing for Chinese books, this paper introduces the machine learning algorithm of Condition Radom Fields to deal with it. The method generates an annotation model including semantic relations and rule features among sequence entities though training the large number of existing keywords data of Chinese books indexed by manual, then uses the annotation model for machine predicting so that to automatically extract the books’ keywords. The paper mainly solves two problems. First, because the parameters choice of CRFs will affect the indexing performance, the authors make comparative tests from several angles so as to identify the optimal parameter set of CRFs for the specific problem of keywords indexing for Chinese books. Second, the authors discusse the effect of different observed features to the keywords indexing, and demonstrate four observed features which can improve the indexing performance effectively through the experiments analysis. Finally, the optimal model of keywords indexing oriented to Chinese books is constructed.
信息的大规模性、异构性以及无关联性使得用户对信息的获取和利用异常艰难,对信息资源进行有效组织和
描述是解决该问题的典型方法。信息描述是指对资源的主题、类别、形式等特征进行记录的活动[ 1],就图书而言,即为图书标引,是实现图书计算机检索的基础。
文本关键词抽取是图书标引的有效方法,即利用计算机技术自动地从图书标题或其他内容文本中抽取关键词作为图书标引词。前人在文本关键词抽取方面做了很多工作,Frank等[ 2]提出将朴素贝叶斯模型用于自动标引,同年Turney[ 3]提出将遗传算法和决策树算法结合来研究关键词提取,上述方法均采用了分类思想;Ercan等[ 4]提出基于词汇链的自动标引方法,关键词抽取由分类问题转变为序列标注问题,准确率和召回率都有了明显提升。由于汉语句法的复杂性,汉语关键词抽取研究一直滞后于字符语言。李素建等[ 5]利用最大熵模型进行汉语关键词提取,Zhang等[ 6]引入支持向量机模型,邓三鸿等[ 7]则基于条件随机场构建了字序列关键词自动标引模型。
本文在前人工作的基础上,采用机器学习模型条件随机场(Condition Random Fields, CRFs)[ 8],以解决两个问题:针对中文图书关键词标引问题从多个角度进行对比实验,确定最佳参数集合;探讨不同观察特征对关键词标引的影响,通过实验论证了4个能够有效提高标引性能的观察特征。从而建立面向中文图书的最佳关键词标引模型。实验结果表明,本文提出的基于条件随机场的中文图书关键词自动标引模型F值能够达到92.30%,具有良好的可行性和实践利用价值。
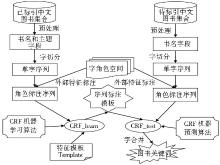
中文图书标引,即给出能够反映中文图书内容的标引词集合,是数字图书馆建设过程中的主要难题之一。对此笔者提出基于条件随机场的中文图书关键词自动标引模型(Automatic Keywords Indexing for Chinese Books, AKICB)作为解决方案,如图1所示。
 | 图1 中文图书关键词自动标引模型 |
AKICB由5部分组成,分别是字角色空间定义、文本预处理和序列标注、特征模板的构建、特征函数参数权重训练和中文图书关键词自动标引。需要指出的是,本文模型仅抽取题名中存在的关键词,不存在于题名中的关键词暂不考虑。
字角色空间定义是指选择一些需要观察的字角色特征,组成字角色空间,然后用一组特定的符号标识每个角色,以便于在序列标注时进行符号化。为此,笔者有针对性地选取9个相关特征建立字角色空间,包括作为标注主角色的关键词特征、图书所属中图法分类号、书名字符长度、单字出现的频率、音译外来字、姓氏字、数字字母序列、所在词语的位置和词性。具体字角色特征及其标注说明如表1所示:
| 表1 字角色空间定义 |
文本预处理和序列标注是指将已经标引的中文图书集合和待标引的图书分别进行提取书名和关键词的预处理,统一清洗后进行字切分,然后对切分后的字序列按照字角色空间进行相应的特征标注产生待用的角色标注序列的过程。AKICB主要有两个处理过程:学习过程,对已标引的图书进行机器学习产生序列标注模型;预测过程,对待标引的图书根据所产生的序列标注模型进行机器预测产生关键词。学习过程中预处理需要操作图书题名和关键词,而预测过程仅操作图书题名。预处理过程对题名和关键词进行数据清洗,其目的是让所有的图书数据有统一的格式。针对关键词,主要是将其拆分为一个或者几个规则的中文词语;而书名清洗主要是去除不统一字符,比如全角和半角的句点符号、长短不一的破折号、中文和英文的引号、多余的空格等。
得到统一格式的书名和关键词后可进行序列标注。首先将预处理后形成的词语或文本片段进行单字切分,字母和数字也进行单字切分;然后根据CRFs++[ 9]要求的格式,参照字角色空间对单字进行序列标注。本文采用CRFs++工具对序列标注的语料格式要求如下:训练和测试文件必须包含多行或多个标记(Tokens);每个标记包含相同数量的列;每个标记的各项标记值用空格或制表符分隔;一个语言片段被分成一个标记序列,各语言片段用空行分隔。
CRFs模型可以将观察序列和上下文约束在一起,这个约束通过特征模板(Feature Template)实现。特征模板的作用是提供一种约束规则,使得CRFs能够确定特征函数的生成模式,因此可以通过编辑特征模板来选择和调整CRFs系统所需要考察的特征函数集合。CRFs++采用的特征模板格式如下所示:
#Unigram U04:%x[2,0]
U00:%x[-2,0] U05:%x[-2,0]/%x[-1,0]
U01:%x[-1,0] U06:%x[-1,0]/%x[0,0]
U02:%x[0,0] U07:%x[0,0]/%x[1,0]
U03:%x[1,0] U08:%x[1,0]/%x[2,0]
其中,%x[row,col]用于确定序列的一个确切节点位置。row表示当前节点的相对行号,col表示当前节点的绝对列号。
特征函数参数权重训练是CRFs模型通过机器学习确定各特征函数参数权重的过程,该过程通过CRFs++提供的crf_learn程序进行,学习的结果被保存为特征模型(model)文件。crf_learn程序执行如下:
crf_learn -f 2 -c 3 template_file train_file model_file
其中,template_file是特征模板文件的路径,train_file是待训练的序列标注文件路径,model_file是学习结果生成的model文件的保存路径。需要说明的是,CRFs++有两个重要参数[ 5]:
①f为特征函数频次阈值,它控制参加计算的特征函数个数,即在训练数据中出现f次以上的特征才被认为是需要考察的。f值越大,生成的特征函数越少;f值越小,生成的特征函数越多,同时模型的计算量相应也越大。上例中f=2。
②c即软边界参数,它用来调节数据欠拟合与过拟合之间的平衡[ 10]。欠拟合是指机器学习时生成的模型所包含的特征或规则不能最大限度地覆盖学习语料,即学习不充分;过拟合则是指在训练时一味追求对训练数据的预测能力,选择的参数和产生的规则过多,导致模型虽然能对已知数据有很好的覆盖却具有较差的预测能力。上例中c=3。
参数f和c的选择对标引结果有很大影响,需要进行多次实验对比,根据实际情况设置参数。
根据2.4节产生model文件和已经准备好的待标引角色序列标注文件,利用crf_test程序进行关键词的字预测标引,然后对自动标注结果进行简单的字合并产生最终的图书关键词。类似的,crf_test程序运行命令如下所示:
crf_test -m model_file test_files -o output_file
其中,model_file是2.4节产生的 model文件的路径,test_files表示已经准备好的待标引角色序列标注文件路径,output_file表示输出结果文件的路径。参数-o表示输出位置,-m表示其后跟随model文件。
针对提出的基于条件随机场的中文图书关键词自动标引模型进行实验,以验证AKICB模型的正确性和合理性。同时对模型中涉及的几个重要参数进行实验调整,以获得具有实用价值的自动标引模型及其参数集合。
实验采用的工具为CRFs++0.53,其实现了CRFs模型的L-BFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)学习算法和Viterbi预测算法[ 11];采用的数据是某高校图书馆的馆藏书目数据,学科种类齐全,且有很强的代表性,并且高校图书馆数据相对有较严格的人工标引过程,适合作为关键词抽取的训练语料。笔者选取的某高校图书馆书目数据中,共有49 419个关键词来源于题名,该样本数据包含中图法分类体系的各个学科。首先将各类数据随机排列,然后按照8∶2的比例将其分为训练数据和测试数据,共得到39 537条训练书目数据,9 882条测试数据。
获得书目数据后,分别对训练数据和测试数据按照字角色空间集进行预处理和序列标注。在具体操作过程中,首先仅选取关键词特征进行多个实验,分别考察训练集大小、特征函数频次阈值、软边界参数、特征模板的字长窗口数、特征模板的特征元数等对标引结果的影响,并根据对比实验得出相应的最佳参数值集合;然后扩展观察的角色特征序列,探索最佳标引模型的观察角色集合。
采取准确率P值、召回率R值和平衡值FN值进行评测,对于F值,笔者认为准确率和召回率同样重要,即N=1。其计算公式为: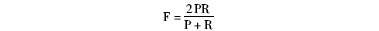
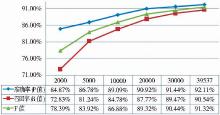
为验证模型的可行性,笔者首先考察了训练集规模的不同对标引结果的影响。为此进行6组实验,逐渐增加训练集大小,其余参数保持不变,参数设置如表2所示,实验结果如图2所示。
| 表2 实验参数表: 训练集规模 |
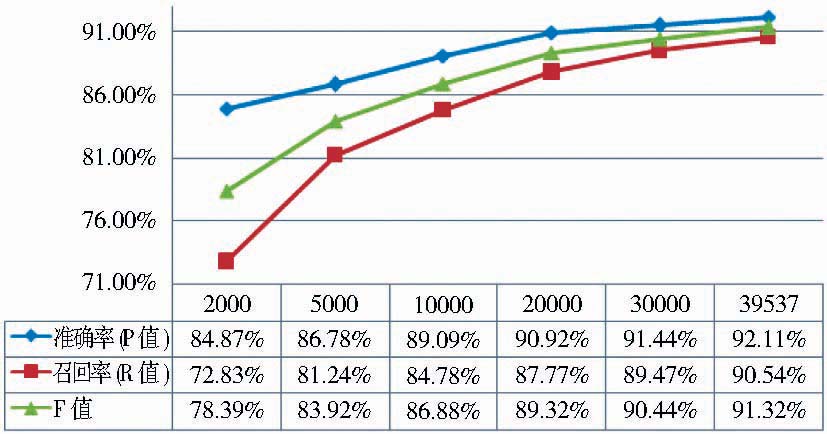 | 图2 训练集大小实验结果 |
由图2可以很明显地看到,训练集的大小直接影响了系统的标引性能。训练集越大,标引性能越好;尤其是训练集规模总体处于较小范围时,比如实验1至实验3,性能的提升相当明显。这是因为训练数据越多,学习越充分,学习模型包含的知识和规则就越多,也就越贴近真实的特征空间,标引性能也越好。同时也应该看到,训练集规模增大到一定范围时,其对标引结果的影响越来越小。原因是对于任何一个领域而言,不管是信息抽取还是文本分类,所研究的对象包含的模型和规则总量是有限的,当训练集的规模增大到一定范围时,就已经能够较为完整地描述对象领域的特征和知识,因而继续增大训练集并不会太明显地影响标引性能。由实验可知,要达到较好的标引性能,应尽量选择较大的训练集,因此后续实验都选择39 537条中文图书书目数据作为训练集。
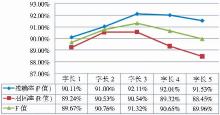
特征模板提供了一种约束规则,使得CRFs能够决定需要考察的特征函数集合。显然特征模板的选择会直接影响整个AKICB系统的标引性能。特征模板的构建由两个参数决定:字长窗口和特征元数。笔者选择不同的字长窗口值进行4次实验,结合实验6,考察该参数值对整体标引性能的影响。实验参数设置如表3所示,实验结果如图3所示,其中字长3实验结果来自于实验6。
| 表3 实验参数表:特征模板字长窗口 |
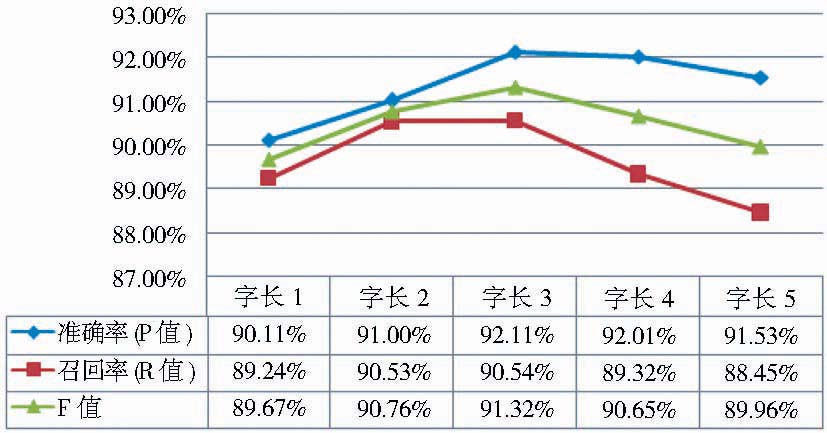 | 图3 特征模板字长窗口实验结果 |
从图3可以发现,F值先升后降,在字长窗口为3的时候达到最大值91.32%。字长窗口为n表示特征函数要考察以当前字为中心,向前和向后各n-1个字,共2n-1个特征。比如当字长窗口为3时,CRFs模型需要考察前2个和后2个以及本身共5个字的特征,特征模板应编辑有类似%x[-2,0]、%x[-1,0]、%x[0,0]、%x[1,0]、%x[2,0]这样的特征。字长窗口太小,CRFs模型不能很好地发现文本上下文之间的依赖性,而太大,的确能发现更多的特征,但计算量明显增多。事实上图书题名往往比较短,前后字之间的关联长度并不会太长,因此反而降低了系统的标引能力。本节实验清晰地验证了这一特点。由图3可知,字长窗口为3时,系统拥有最好的标引性能,故而后续实验的特征模板字长窗口均设置为3。
特征元数n表示CRFs模型需要考虑1-n个字的共现特征。例如特征元数为3,则特征模板中应含有1个、2个和3个字的特征,类似%x[0,0]、%x[-1,0]/%x[0,0]、%x[-2,0]/%x[-1,0]/%x[0,0]这样的形式。为探讨特征元数的不同对标引性能的影响,笔者进行了3个实验,结合实验6进行对比,实验参数如表4所示,实验结果如图4所示,其中特征元数为2的结果来自实验6。
| 表4 实验参数表:特征模板特征元数 |
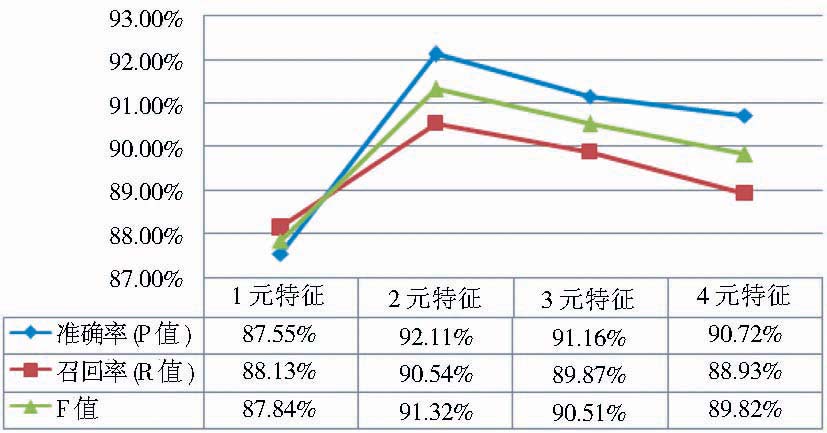 | 图4 特征模板特征元数实验结果 |
由图4可知,与字长窗口实验相似,测试结果F值先升后降,采用2元特征模板标引结果F值最高。笔者认为,这是与汉语的本质特点相关的。汉语文本中,相比单字词如“水”、“书”等,三字词如“经济学”、“表达式”等,以及多字词“信息检索”、“编程思想”、“马克思主义”等,二字词如“原理”、“应用”、“程序”等出现最多。故而二元字共现的频次较高,CRFs模型测试结果可以验证这一点。为达到较好的标引性能,后续实验中特征模板的特征元数均设置为2。
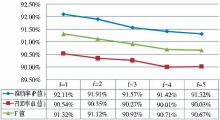
特征函数频次阈值即为CRFs++工具提供的参数f,该参数控制参加计算的特征函数个数,即在训练数据中出现f次以上的特征函数才被CRFs模型纳入考量。笔者设置了不同的f值进行了4个实验,并结合实验6进行对比。实验中只需在crf_learn命令中添加“-f+空格+对应的数字”即可。实验参数设置如表5所示,实验结果如图5所示,其中f为1的结果来自实验6。
| 表5 实验参数表:特征函数频次 |
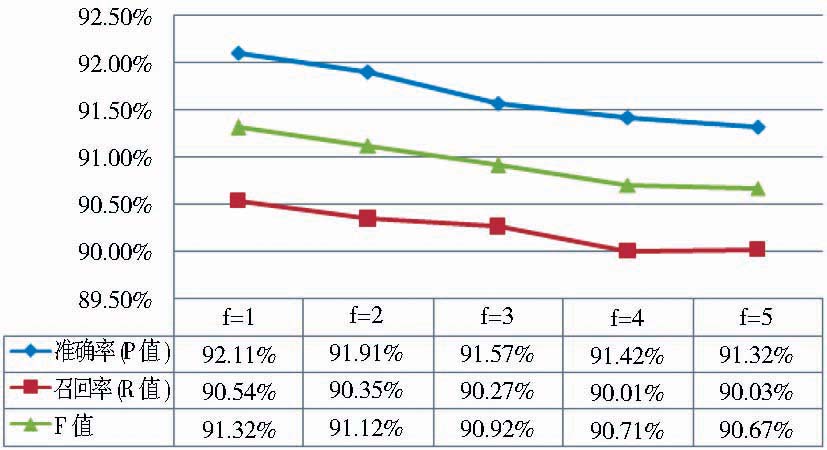 | 图5 特征函数频次阈值实验结果 |
图5结果的规律很明显,随着特征函数频次阈值f值的逐渐增加,准确率P、召回率R和F值都逐渐下降,标引性能逐渐降低。需要指出的是,CRFs++工具默认的f值就是1,通过实验可以看到研发者如此设置是有道理的。事实上,只要出现1次以上的特征,CRFs模型都会进行考察和归一化计算,这样虽然增加了特征函数的规模从而加大了训练难度,也更加耗时,但结果是令人欣慰的。为此,笔者选取特征函数频次阈值f为1进行后续实验。
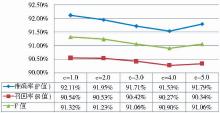
笔者设置4个不同的软边界参数值进行对比实验,结合实验6的结果进行分析。实验中只需在crf_learn命令中添加“-c+空格+对应的数字”即可。实验参数如表6所示,实验结果如图6所示,其中c为1.0的结果来自实验6。
| 表6 实验参数表:软边界参数 |
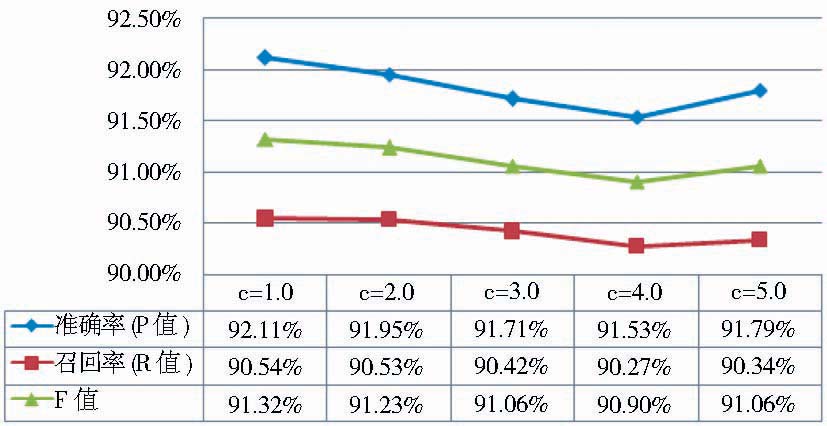 | 图6 软边界参数实验结果 |
可以看到,软边界参数为1.0时,CRFs模型能良好地达到欠拟合和过拟合之间的平衡,即经过学习产生的model能够最大可能地接近真实数据空间,又不完全重合。虽然在c值为5.0时性能有所回升,但是三个评测指标值都小于c值为1.0的结果。需要注意的是,不同类型的学习对象对应的最佳c值不同,具体操作中应该通过实验具体分析和设置。后续实验中,笔者都选择1.0为最佳c值。
为了尽可能精确地预测图书的中文关键词,CRFs模型需要捕捉文本的所有特征,并将其应用于规则的建立过程中。因此,除了上述实验中应用的主特征K外,笔者根据事先建立好的字角色空间,扩展了书名序列的特征标注。各特征符号所代表的含义见表1。之后建立相应的特征模板,连同实验6共进行了9次实验。相应的特征模板如表7所示,其余实验参数如表8所示,部分实验结果如图7所示。
需要说明的是,上述实验是按照逐一添加特征角色进行组织的,但实验24、25和26的结果并未反映在图7中,因为这三个实验特征角色数量与实验27相同但类型不同,其中一特征从D→X→W→P,这三个实验的实验结果如表9所示。
对比实验24与实验23,不难发现增加了书名长度特征D后,P值不变,R值降低且F值也降低,说明增加书名长度特征并不能提高系统的标引性能。因此后续实验中笔者并未继续保留该特征,而是换用其他特
| 表7 不同观察特征角色实验特征模板表 |
| 表8 不同观察特征角色实验参数表 |
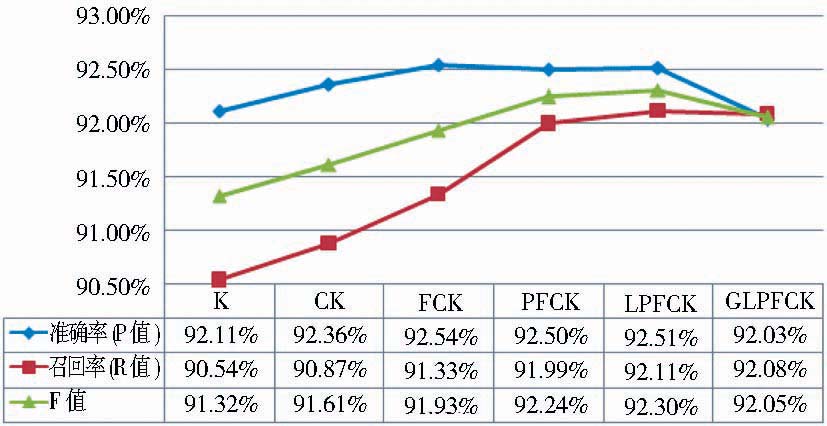 | 图7 不同观察特征角色的实验结果 |
| 表9 实验24至实验26标引结果表 |
笔者尝试分析特征D、X和W都未能有效提高标引性能的原因如下:书名长度特征D代表图书书名的字符串长度,一般而言,中文图书书名普遍较为短小精悍,长度区分度并不大,且长度特征与关键词关联不大,所以标引性能不升反降;姓氏字特征X表示书名单字是否为中文姓氏字,如赵钱孙李等,中文图书较少出现中文姓氏字,即使出现大多并非作为姓名的一部分,它可以提供人名实体抽取的有效特征,但缺乏与关键词标引相关的特征;音译外来字特征W是指书名单字是否为音译外来字,即中文翻译的外文人名或者地名所采用的字,例如“汤姆斯”、“伊丽莎白”、“凡尔赛宫”等。不难发现,汤、丽、白、凡、宫等均为常见的中文汉字,使用时大多只是作为普通汉字而并非表达的外文翻译过来的概念,所以这个特征具有区分是否为外来实体的能力,但却给中文书目关键词的抽取带来了混淆和困扰,造成标引结果不够理想。
观察图7,可以发现实验29所添加的单字所在词的词性特征G的实验结果也比实验28的预测结果稍差,可见词性特征对中文图书的关键词抽取意义不大。可能原因是词性是词语的上下文特征,对词语在语言环境中的地位和作用具有重要揭示作用,但是对于字而言,词性不是它的内在特征,而且存在大量相同的字在不同词性且毫无关联的词中出现的现象,因此词性特征并不能有效揭示单字与上下文之间的关系,反而可能给CRFs模型的识别带来干扰,造成标引性能下降。
因此,笔者认为除了K特征外,C、F、P、L在中文图书关键词标引中是合适、具有区分度的特征指标,能良好地提升标引模型的性能。
(1)首先是图书分类号特征C。分类号标志着图书的类别,而图书的类别又决定了图书书名及关键词的设置。如计算机类的图书往往带有“程序”、“计算机”等词,而艺术类图书带有“技法”、“欣赏”等词,都是与各自的领域相关的,因此该特征具有较强的汉字类别区分度,能够带来标引性能的有效提升。
(2)单字字频特征F所带来的积极影响比较好理解,单字字频是由书名中的单字出现次数除以书名总字数得来,该指标能够很好地反映单字的重要性,例如书名“金融市场与金融调控”,“金”“融”这两个字的字频最高,而该书的关键词就是金融,所以CRFs模型能够利用这个特征提升系统的标引能力。
(3)所在词位置特征P是指单字在所属词语中的位置。例如“表达式”一词,“表”位于词首,“达”位于词中,“式”位于词尾。该特征的标注依赖于分词结果,笔者采用的是中国科学院计算技术研究所的分词系统。显然该特征的标注受到分词系统分词性能的影响。但从实验结果看到,虽然分词结果可能不够准确,但是位置特征P依然较大幅度地提高了系统的标引性能。究其原因,单字在词语中的位置直接显示了其与上下文之间的关系,而上下文关系的揭示是关键词自动标引的本质和精髓所在。这也是实验6中仅仅选取一个主标引特征却得到较高的标引结果的原因之一。
(4)字母或数字特征L是指所切分的单字是否为字母或数字,需要注意的是,本文将字母和数字切分为单个字符进行处理,如2013abc会被切分为“2|0|1|3|a|b|c”而不是“2013|abc”。一般而言,关键词含有字母或者数字的可能性较小,因而该观察特征能够给系统提供非关键字信息,从而给标引结果带来积极影响。
针对中文图书关键词自动标引问题,笔者引入信息抽取领域的机器学习方法,通过对已有的大量图书手工标引数据进行训练学习,建立了基于字切分序列的角色特征集合,生成了图书题名与图书关键词之间的语义联系和规则模型,然后利用该模型进行机器预测,最终自动产生了图书关键词。在此基础上,笔者提出中文图书关键词自动标引模型,进行多个实验修正了模型的参数设置,明确了需要考察的字角色特征集合,具有良好的参考价值。
然而本文的研究建立在关键词源自图书题名这一假设的基础上,而鉴于题名的长度,包含图书关键词的可能性较大,但完整包含的却少之又少,即图书关键词并非仅仅源自题名。内容提要可能包含更多可以描述图书内容的词汇。因此,从图书内容提要中抽取关键词将会具有更好的召回率,但是内容提要的篇幅远远高于题名,采用字标注的方式可能会极大地增加计算量;再者期刊论文与图书具有相似的应用要求,也需要能够从论文中抽取关键词,本文提出的方法能否应用于期刊论文,或者是否还存在更好的观察特征可应用于期刊论文关键词的抽取。上述的问题都将是今后进一步研究的主要内容。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|