{kind=link}
先秦古汉语典籍中的人名自动识别研究
[汤亚芬 ]
]
]
|
|


以数字人文的文本挖掘和分析这一研究内容为切入点,通过条件随机场这一机器学习模型,在先秦语料库的基础上自动识别古汉语人名。在规模为187 901个词汇的先秦语料上,把调和平均值为91.52%的交叉验证语料所训练的模型确定为古汉语人名自动识别的最优模型,并进行实验验证。本研究不仅有助于先秦古文献命名实体的抽取,而且也有益于其他人文学科对先秦人物关系和背景的探究。
The ancient Chinese name is automatically recognized by the machine learning model of Conditional Random Field based on Pre-Qin corpus from a point on the research of text mining and analysis of digital humanities. The training model, the F-score of which is 91.52% in cross-validation corpus, is identified as the optimal performance of ancient Chinese name recognition and experimentally verified based on Pre-Qin corpus containing 187 901 words. The research is not only helpful to extract the named entity from Pre-Qin ancient literature but also beneficial to explore the relationship and background among people in other humanities and social sciences.
自Busa[ 1]提出数字人文概念,到Unsworth[ 2]对数字人文的内涵和外延进行多角度的论述,数字人文使古籍的深度知识挖掘具备了创造性的理论和实践性的方法。本文从文本分析与文本挖掘这一数字人文的重点研究方向入手,基于先秦语料库中的《左传》语料,对先秦典籍中的古汉语人名进行自动识别的探究。本文基于条件随机场自动识别人名的方法不仅可以应用到先秦其他文献人名命名实体的抽取上,而且抽取的人名可以对先秦文献中的人物进行社会网络关系挖掘,使得历史学、社会学、语言文学及心理学的研究者可以从大规模的文本中对人物关系和背景有一个系统而全面的认识,同时该识别古汉语人名过程中选取特征的方法可以应用到其他古汉语命名实体的识别上。
关于汉语人名命名实体的识别研究,主要集中在现当代文本语料上。Li[ 3]面向条件随机场,构建了基于边界特征与统计特征的两个混合模型用于汉语人名的识别,最好的调和平均值达到了93.61%。Wen等[ 4]通过在查询日志中使用检索序列,基于汉语人名姓的知识,提出通过局部扩展的方法来识别汉语人名。Wan等[ 5]通过把新闻中有关命名实体的信息添加到模型中的方法对新闻评论中的汉语人名进行了识别。Tian等[ 6]基于属性特征的自适应聚类算法,通过人名的消歧策略,对汉语人名进行了自动识别。毛婷婷等[ 7]提出一种基于SVM和概率统计组合算法的人名识别模型,在模型和词汇概率知识的基础上,F值达到了93.27%。蒋才智等[ 8]在贝叶斯分类器对汉语人名进行初步识别的基础上,基于HowNet中的语义知识,进一步完成了对人名边界的界定,提高了识别的性能。赵晓凡等[ 9]在汉语姓名分布特征知识的基础上,使用条件随机场模型对人名的性别进行了识别。张华平等[ 10]在角色序列的基础上,通过Viterbi算法构建了汉语人名识别的模型,并在ICTCLAS分析系统中验证了该模型的性能。章顺瑞等[ 11]利用层次聚类算法对中文人名消歧问题进行探究,并得出了不同词性对消歧的影响。通过对上述汉语人名识别相关研究的分析,在人名识别的过程中主要是基于机器学习的相关模型进行的,考虑到隐马尔科夫、最大熵模型不能完全使用人名左右边界及其内部的相应知识,本文采用条件随机场模型来完成对先秦人名的识别,同时也充分利用先秦人名的左右和内部特征知识,进而确保所识别人名模型的性能。
有关先秦文本信息处理的研究非常少,目前已有的研究主要是对先秦文献进行预处理、分词和词性标注。徐润华等[ 12]在对《左传》及其注疏文献进行自动对齐的基础上,提出了一种利用注疏的《左传》自动分词新方法,调和平均值达到了89.00%。马创新等[ 13]利用网络数据存储和交换语言XML,实现了《论语》与其注疏文献语料的对齐。石民等[ 14]基于条件随机场模型完成了对先秦古汉语的分词、词性标注一体化的对比实验。本文在上述研究的基础上,结合先秦人名的内部和外部特征,基于条件随机场,训练先秦人名自动识别模型,并进行了简单的识别实验。
本文所用的先秦语料库由南京师范大学语言科技研究所构建,共包括《左传》《国语》《尚书》《仪礼》《礼记》《周礼》《孝经》《公羊传》《谷梁传》《论语》《孟子》《荀子》《墨子》《老子》《庄子》《商君书》《韩非子》《管子》《吕氏春秋》《晏子春秋》《诗经》《楚辞》《孙子兵法》《吴子》《周易》等25种比较重要和可靠的先秦传世文献,达到了分词和词性标注的级别,其中的人名词性标注为“nr”。
本文选取先秦语料库中的《左传》语料进行人名内外部特征的统计,并按照条件随机场的要求形成特征模板,再按9∶1的比例将《左传》语料划分为训练与测试集,分别进行训练和测试,从中选优进而建立先秦古汉语人名自动识别模型。最后,从先秦语料库之外另行选取未进行词性标注的原始《国语》文本作为测试集,进行古汉语人名自动识别的实验。
为了向条件随机场模型提供有效的特征知识,进而确保人名自动识别的性能更加优良,本文基于《左传》中词性为“nr”的人名,统计了人名的分布、长度和左右一元词汇与词性等内部和外部的特征。
(1)先秦古汉语人名内部特征统计
在规模为187 901词次的《左传》语料中,3 373个人名共出现了11 006次,占整个语料的6.42%。在这些人名中,出现频次高于50的人名共有14个。其中,出现频次排第1的是“晉侯”共出现了199次,排第14的是“襄公”共出现了50次。这14个人名总共出现了1 348次,占整个人名分布的12.25%。这些人名的有效识别对确保高性能人名识别模型的构建具有重要的意义。
构成人名的汉字个数称为人名长度。人名长度的分布情况,不仅决定了条件随机场模型的词位数量,而且也决定了模型的序列跨度。基于3 373个人名的统计表明,《左传》语料中人名的长度为1的出现频次为371(占比11.00%)、长度为2的出现频次为1 767(占比52.39%)、长度为3的出现频次为1 038(占比30.77%)、长度为4的频次为193(占比5.72%)、长度为5的出现频次为4(占比0.12%)。由此可见,先秦人名的长度主要集中在2和3上,占整个人名的83.16%,长度为5的基本上是个例,如“百里孟明視”、“楚鬬穀於菟”、“延州來季子”等,因此条件随机场的词位标注集数应该在4左右。
(2)先秦古汉语人名外部特征统计.
语言的构成部分以线性序列呈现,人名作为这个线性序列上的一个线段在一定程度上决定了该线性序列的可延续性和完备性。从机器学习模型,尤其是条件随机场模型在判定线性序列中的人名过程中所需要的特征知识出发,本文主要使用了人名左右边界的一元邻接特征知识。具体统计过程中主要统计左右一元词汇和词性的知识分布情况。
基于“nr”这一词性标记,可获取并统计古汉语人名左右的一元词汇。排名前12位的人名左边界一元高频词中,出现频次排第1的“使”频次为375,排第12的“告”频次为76。这12个人名左边界一元词主要是动词、介词和地点名词,其中动词占据整个高频词的51.49%。这些词的确定可以直接作为特征知识应用于先秦人名识别模型的训练中。
排名前12位的人名右边界一元高频词中,出现频次排第1的“曰”频次为1 153,排第12的“于”频次为118。相较于左边界一元词,人名右边界一元词更加集中,排名前12位的高频词占整个右边界词的39.73%。而排名分别为第1、第2、第3的“曰、之、以”三个字又占总共12个高频词的频次分布的59.77%,由此可知,在条件随机场模型训练中,右边界词比左边界词会发挥更大的作用。
先秦人名的一元左右邻接词汇的词类分布通过以下公式[ 15]获取: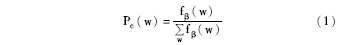
其中,fβ(w)为一元左右邻接词W 在邻接词位置上出现的频次,则Pc(w)为W在某一词性下出现的频率。一元左、右高频邻接词在词类中的分布具体情况如表1所示:
| 表1 人名左右边界词高频词类分布 |
条件随机场一般定义如下:给出一个无向图G=(V,E),其中V是图的顶点集合,E是边集合。然后把标记Y用顶点做索引,即Y={Yv|v∈V},每一个顶点的Y都可以取标记集中的任意一个标记。当Y的出现条件依赖于X,而且Yv根据图结构的随机变量序列具有马尔科夫性,即p(Yv|X,Yu,u≠v,{u,v}∈V)=p(Yv|x,Yu,(u,v)∈E)(u~v表示两个顶点之间有连接边),则称(X,Y)为一个条件随机域。在这个定义中, X是要被标注的数据序列上的随机变量,Y是相应的标注列的随机变量,例如, X 可以表示一个古汉语句子 X=(鄭伯 克 段 于 鄢。),Y 则表示该句子中每个词的词性序列Y = (nr, v, nr, p, ns, w)。在上述定义的基础上,条件随机场的公式[ 16]表示如下:
其中,p(|)是求在λ参数制约下类别向量Y的条件概率,Z()是归一化因子,n是序列长度,m是特征函数个数。特征函数fi有两种:状态特征函数和转移特征函数。本文基于条件随机场构建的先秦人名自动识别模型所用的工具主要是基于C++开发的CRF++[ 17](0.54版本)。
根据人名识别模型训练和测试语料的具体需要,语料预处理过程如下:首先,基于“nr”的词性标注,确定语料中的所有人名;其次,基于古汉语人名的具体特征,确定人名自动识别模型构建的标注集。本文在确定古汉语人名识别模型标注集的过程中,主要参考以下公式[ 18]: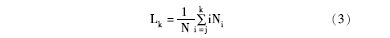
其中,Lk表示当i≤k时,古汉语人名平均加权后的长度,Ni表示先秦古汉语语料库中长度为i的人名出现的次数,k和j分别表示语料库中最长与最短人名的长度,N表示语料库中人名分别出现的总的次数。基于公式(3),结合相应的实验结果,人名自动识别模型构建中确定使用4词位的标注集,标注集用R来表示,具体为 R={B,C,E,S},B表示人名的初始词,C为人名中间词,E为人名结束词,S表示人名外词,若某一个人名长度超过3,则用C来表示扩展的词。
基于经过词性标注的先秦古汉语语料,结合已定义的4词位标注集,在条件随机场训练和测试语料的具体要求下,语料预处理后的样例见表2。
条件随机场最大的一个特点是在训练过程中可以增加外在的相关特征知识,从而确保可以利用尽可能多的特征知识从线性序列中获取相应的知识。从关于先秦人名的内外特征统计可以看出,作为先秦古汉语重要组成部分的人名有其自身的分布特点,这些特点可以转化为相应的特征知识添加到特征模板的训练当中,具体的特征知识如下:
(1)词语长度分布
从先秦古汉语人名左边界和右边界词汇的分布整体状况可以观察出,先秦古汉语人名左右的高频词全是单字词,也就是长度为1的词汇,如“壬申,及鄭伯盟,歃如忘。”,基于这一点,本文把词汇的长度作为一个特征添加到条件随机场训练的模型中,具体根据每一个词汇的长度标注为阿拉伯数字。
(2)虚词特征
根据人名左右高频词类的统计可以看出,虚词在人名自动判别的过程中起到非常重要的结点作用,从这一点出发,本文把以“p、c、d、u”为词性标记的词性作为一个特征添加到先秦人名条件随机场训练的模板中,统一标注成“Y”,不属于这几个虚词的标注为“N”。
(3)左右边界词.
在人名自动识别的过程中,如果确定了人名的左右边界词,该人名的识别也就基本完成,所以边界词在人名自动识别的过程中扮演了极为重要的角色,本文把“使、於、謂、殺、及、曰、之、以、為、將”这10个古汉语词汇作为特征知识添加到训练模板中,整体标注为“Y”,不属于这10个词汇的标注为“N”。
基于上述由统计的特征构成的特征模板,表2给出了特征模板下的训练语料样例。
先秦人名自动识别模型构建的流程主要是由训练和测试两部分组成。训练模块主要是在条件随机场算法的基础上,使用本文所确定的特征模板,在训练语料上得到人名自动识别模型的参数,主要是特征的权重。
| 表2 基于特征模板的先秦古汉语人名 自动识别训练语料样例在具体标注过程中,标点的长度统一计算为1。 |
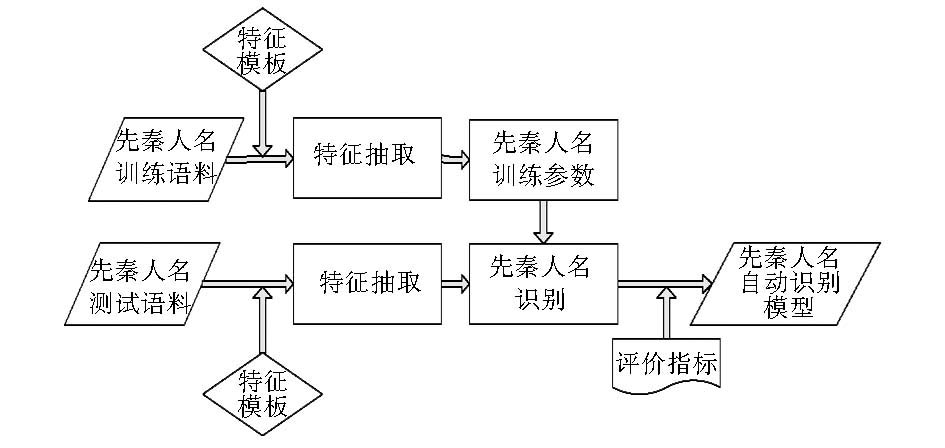 | 图1 先秦人名自动识别模型训练流程 |
人名自动识别的评价指标主要由精确率P(Precision)、召回率R(Recall)和调和平均值(F-Score)组成。具体的人名自动识别的精确率和召回率计算公式[ 19]如下:

在利用精确率和召回率来评价先秦人名自动识别的性能的过程中,有时候提高召回率,精确率会下降,反之亦然。在这种情况,本文采用P和R的调和平均值F作为综合的评价指标。具体的计算公式如下: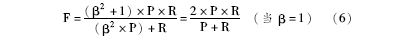
基于条件随机场,通过特征模板,本文选取先秦语料的187 901个词汇进行训练和测试,从而确定先秦人名自动识别训练模型。在具体的测试过程中,为了使所得结果更加合理和科学,采取了交叉验证,把训练和测试的语料按9∶1的比例共分成了10份,分别进行训练和测试,以期从中确定最优的人名识别模型,具体测试中10个模型的性能如表3所示:
| 表3 先秦人名自动识别模型的测试性能 |
从测试的结果来看,人名容易识别错误的主要有两类:一类人名中的最后一个字易与其他词性混淆,比如“孔丘使【茲無】還揖對,曰:‘而不反我汶陽之田,吾以共命者亦如之!’”这个例子中的“茲無”就被错识别成人名,正确的人名应该是“茲無還”“茲無還”是一个鲁国大夫的名字。,人名识别模型把“還”误判成动词;另一类就是人名与地名错判,例如“【公子】荊之母嬖,將以為夫人,使宗人釁夏獻其禮。”这个例子中,本来“公子荊”是一个人名,由于受“荆”为地名的影响,而识别错误。
基于确定的第4个调和平均值为91.52%的先秦人名自动识别模型,以未经词性标注的《国语》原始文本为测试集,对其中的人名进行自动识别实验,具体识别的样例选取《齐语》中齐桓公与鲍叔牙的一段对话。结果如下:
“【桓公】自莒反于齊,使【鮑叔】爲宰,辭曰:‘臣,君之庸臣也。君加惠于臣,使不凍餒,則是君之賜也。若必治國家者,則非臣之所能也。若必治國家者,則其【管夷吾】乎。臣之所不【若夷】吾者五:寬惠柔民,弗若也;治國家不失其柄,弗若也; 忠信可結于百姓,弗若也,制禮義可法于四方,弗若也;執枹鼓立于軍門,使百姓皆加勇焉,弗若也。’【桓公】曰:‘夫【管夷吾】射寡人中鈎,是以濱于死。’【鮑叔】對曰:‘夫爲其君動也。君若宥而反之,夫猶是也。’”
从识别结果来看,由于“桓公、鮑叔、管夷吾”都是《左传》中的语料,所以能精确地识别出来,但“夷吾”这个人名识别发生错误,原因是《左传》中没有这个人名,但有“若敖、若敖氏”这两个人名,模型学习到“若”是名字的构成部分,从而导致把“若夷”误判为人名。
根据制定训练模型特征模板的需要,本文统计了古汉语人名的分布、长度、左右一元词汇与词性等内部和外部的特征。在确定的包含词汇、词性、词汇长度、虚词词性、边界词等5个特征的特征模板基础上,通过10次交叉验证,在规模为187 901个词汇的先秦训练和测试语料上,将调和平均值为91.52%的训练模型确定为最优模型,并在所选取的《国语》语料上进行了识别实验。下一步将会通过互信息、卡方、搭配度等统计的方法,从先秦语料库中挖掘更多的特征知识添加到人名自动识别的特征模板中,进一步提高人名自动识别的精确率和召回率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|