
{kind=link}
{kind=link}
文献数据库中作者名消歧算法研究
[郭舒 ]
]
]
|
|


在深入分析基于图的人名识别框架GHOST的基础上, 针对其存在的局限性,结合对文献信息的文本挖掘提出一种更适用于文献数据库的作者名消歧算法, 并从中选取标题以及出版物名称这两个特征进行实证研究, 该算法在准确率、召回率等指标方面都有良好的表现, F1平均值达到84%, 具备较好的消歧效果。
This paper firstly analyzes a graphical framework for name disambiguation called GHOST, and then provides a modified name disambiguation algorithm combining with the text mining of literature information. The new algorithm is more suitable for literature database, making up for the limitations existed in GHOST. Based on selecting title and publication name as computing feature from the literature information, the experiment shows that the algorithm achieves high precision and recall value, and F1 reaches 84%, which is good enough for name disambiguation.
人名歧义现象在文献数据库中一直是一个棘手的问题,当用户以作者名来搜索文献数据库时,由于文献中的作者名可能被多个人使用,或是该作者使用了其他名称变体,导致检索的准确率和召回率大大降低,影响了文献数据集质量,也增加了基于作者层面分析评价的障碍。
传统上,处理作者名称歧义问题都是交给图书馆进行人工的名称规范控制,或者由出版商、集成商等一些机构采用名称唯一标识符(Name Identifier)的方法为科研活动中从事科研活动的相关研究者分配一个唯一标识号。在网络、数字图书馆普及的今日,传统的方法已经无法有效解决海量数据增长、人工辨识效率偏低并且耗费巨大人力财力的问题,随着信息技术的飞速发展,自动化的作者名消歧方法会更加适应不断扩大的数字化环境,弥补传统方法的不足。
目前针对文献的作者名自动消歧方法,已经有许多研究者给出了有效的解决方案。
根据所采用的聚类方式可以将作者名自动消歧方法分为基于监督学习的消歧方法与基于非监督学习的消歧方法。监督学习的方法需要数据训练的过程,例如Han等[ 1]分别采用两种监督学习的方法——朴素贝叶斯(Nave Bayes, NB)及支持向量机(SVM),针对文献信息中的合作者名称、标题、出版物名称(期刊名或会议名)特征来对作者进行排歧。Treeratpituk等[ 2]用Random Forest分类法自学习了一个相似度函数,利用MEDLINE数字图书馆中的元数据信息即标题、作者机构名称、出版物名称、主题词等信息对作者进行名称消歧。而非监督学习的方法则不需要训练的过程,例如Han等[ 3]后来又提出了一种非监督学习的方法K-way谱聚类算法来对人名进行消歧,该算法将每条文献信息看成一个特征向量,实验中仅仅使用了合作者名、标题和出版物名称这三个特征,每个特征对应特征向量中的一个项,每个特征的权重采用TF-IDF以及标准词项频率(NTF)计算,每条文献信息之间采用余弦相似度值形成相似度矩阵,再通过K-way谱聚类算法来进行聚类。
根据选取的特征类型不同,可以将作者名消歧方法分为利用文献信息消歧的方法、利用Web信息消歧的方法、利用隐含信息消歧的方法。例如国内清华大学Fan等[ 4]提出基于图的人名识别框架GHOST(GrapHical framewOrk for name diSambiguaTion),仅利用文献信息中的合作者关系对作者名进行消歧。Pereira等[ 5]则利用Web技术通过获取包含该作者文章的Web页或简历的Web文档,判断两个待消歧作者的文献是否同时出现在一篇Web文档中,从而区分人名。Song等[ 6]提出了一种利用概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)以及潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)来为每一条文献分配一个关于主题的概率分布向量,并将文献的主题概率分布作为一个新的特征用于人名消歧。
通过对现有各自动消歧方法的算法性质和特点以及特征选取、特征计算的方法进行全面而透彻的分析,在对文献数据库中应用自动化消歧方法进行作者名消歧时需要考虑以下几点因素:
(1)监督的方法需要大量已经标注好的文献数据进行训练,这需要有专业背景的人耗费大量的时间对数据进行标注,甚至需要在专家无法区分的情况下联系原文作者进行确认,这在大型数据库中是非常不适用的,因而非监督的方法会更适合大型数据库中的人名消歧。
(2)通过Web技术获取额外信息,查询的过程势必影响程序运行的效率,此外信息抽取所带来的噪音影响了消歧效果,可以说有些得不偿失。
(3)基于LDA隐含主题挖掘技术对于文献作者名消歧领域来说还是一项比较新兴的技术。LDA本身是概率模型,参数的估计需要一个迭代过程,运行速度相对较慢;而且LDA主题模型一般需要预先确定文献集的主题数,这就要求算法设计者事先对文献集的主题分布比较清楚。
(4)文献信息一般包括作者、合作者、文献标题、出版物名称等特征元素,在文献数据库中一般作为元数据存储在本地中,对于数字图书馆的系统构建者来说是极容易获取的。对于选择文献信息作为消歧计算特征的方法,通过选择合适的特征元素、相似度计算方式以及特征合并方法,往往能取得很好的消歧效果。因此对于应用到实际文献数据库中的自动化消歧方法来说也是首选的特征。
在文献数据库中,由于作者在很长一段时期会有其固定合作人员,因而合作者关系应该是众多特征元素中最具辨识能力的特征元素之一,也是消歧算法中需要重点考虑的因素。GHOST算法是一种非监督学习的方法,在挖掘节点多、结构复杂的合作者关系图上具有速度快、效果好的特点,然而其在文献数据库的实际应用中仍存在某些不足。基于以上考虑,本文结合对文献信息的文本挖掘,提出一种更完善的算法用于文献数据的作者名消歧,为提高数字资源检索的准确率以及文献数据的质量提供技术支持。
GHOST算法主要分为4步,包括合作者图的构建、有效路径选择、相似度计算以及聚类。
在构建合作者关系图中,GHOST算法对于被查询的待消歧作者建立合作者关系图。对于待消歧的作者,采用不同的节点来表示,称为待消歧作者节点,对于其他每一个名字,GHOST也只用一个节点表示。对于任意作者节点之间的无向边,用两者的合作文献集来关联。
之后,GHOST从合作者关系图中检索出待消歧作者节点之间的路径,为了消除冗余路径以及提高时间效率,GHOST用基于三条准则[ 4]且长度不超过阈值L的有效路径代替所有的路径,并根据公式(1)计算节点之间的相似度,该公式综合考虑了两待消歧作者节点之间的路径长度和条数[ 4]: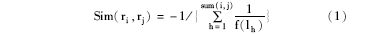
其中,sum(i,j)表示节点ri到rj的有效路径的条数,lh表示第h条路径中中间节点的个数。公式(1)表明两待消歧节点之间有效路径越短则越相似,可连通的有效路径条数越多则越相似。
GHOST算法采用仿射传播(Affinity Propagation)算法对待消歧节点进行聚类,该算法不需要预先设定最终簇的个数,而是通过调节“偏向参数”来决定最终簇的个数[ 7]。
虽然GHOST在利用合作者关系处理作者名消歧上取得了较好的效果,但如果将GHOST算法应用到实际的文献数据库系统中进行消歧工作,其自身存在的局限性有可能会影响消歧效果。
(1)由于GHOST算法是建立在合作者关系图上,关系的缺乏会降低节点之间的相似度,从而降低消歧结果的召回率。如果文献中的待消歧作者合作不那么频繁,在实际运用过程中GHOST算法的效能就不能充分发挥。
(2)GHOST方法会忽略单一作者文献的情况。
针对3.2节提到的局限性,在实际的文献数据库系统中应用GHOST算法时,单一作者文献、合作较少的作者文献都可能是导致其消歧结果不理想的原因,因此,除了利用GHOST算法来计算文献间的结构相似度,还需要融入文本相似度来提高其在实际应用中的消歧效果。
文献信息除了包含作者与合作者名称,还有文献标题、出版物名称、主题词等文本属性特征。由于作者在一段时期内会有着比较稳定的研究方向和研究主题,因此在选题以及主题词选择方面可能会频繁使用同一类学科或者同一研究主题的某些特定的描述词,所刊用的出版物可能也会在一定的学科范围内频繁出现。也就是说同一作者文献的主题是否接近,取决于其文本特征在选词上的相似性,而文本特征在选词上的相似性可以采用余弦相似度进行度量。如果两篇文献同属于同一作者,其文本特征会频繁使用某些特定主题词,反映在每篇文献的特征上,它们的文本特征向量在这些主题词所在维度上的值都会比较大,而在其他维度的值比较小。反过来看,如果两篇文献不属于同一作者,那么它们的特征向量中,值较大的维度之间没有什么交集。总之文献主题越接近,文本特征向量越相似,余弦相似度也就越大,因而余弦相似度能在一定程度上反映文献主题的相关性。
若在运用GHOST算法的基础上,充分利用主题相关性来进行辅助消歧,一方面当合作者关系缺乏时,对于那些因合作不频繁导致关联程度低的两个待消歧作者,利用其文献文本特性选词的相似性可将其关联起来;另一方面也能利用文本相似性将单一作者文献的情况考虑在内。从理论上来说,结合文献信息的文本挖掘可以进一步提高GHOST算法消歧的效果。
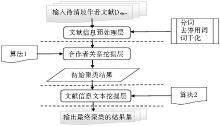
针对3.3节中的理论分析,笔者所设计的改进后的作者名消歧算法框架如图1所示:
 | 图1 改进的作者名消歧算法框架 |
图1中算法输入为待消歧作者文献集,记为Ddiam,算法主要分为三个子函数层次,分别为文献信息预处理层、合作者关系挖掘层和文献信息文本挖掘层。考虑到GHOST算法消歧正确率高的特点,因此合作关系挖掘与文本特征挖掘之间采用顺序组合的方式,即先基于GHOST算法利用合作者关系进行初次聚类,从而获得一个正确率较高的聚类结果,然后在此基础上,期望通过文本挖掘方法来解决可能出现的单一作者文献,缺乏合作者关系的作者文献所导致的召回率降低的问题。本文工作的重点即对文献信息文本挖掘层进行扩展。
选取文献信息的文本属性中标题、出版物名称这两个特征,从实证角度出发验证该算法的有效性。
(1)文献信息预处理层
此次实验数据来源于Han等[ 1] 从计算机领域科学文献数据库DBLP[ 8]中抽取的数据集,他们已对数据进行了标注,即明确哪些文献属于同一个作者。该数据集目前是开源的,数据集Ddiam如图2所示:
 | 图2 待消歧作者的文献数据集Ddiam |
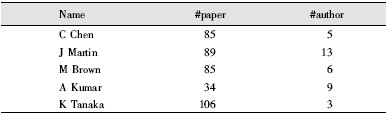
本实验所使用的部分作者文献数据情况如表1所示,其中“#paper”为文献数,“#author”为实际作者数。
| 表1 DBLP中待消歧的部分文献数据 |
①输入待消歧的作者的文献信息数据集Ddiam;
②遍历Ddiam中每一条记录,利用开源的全文检索引擎工具包Lucene[ 9]对数据集Ddiam中文献标题及出版物名称进行分词、去停用词以及词干化等预处理。
(2)合作者关系挖掘层
对数据集Ddiam应用GHOST算法挖掘合作者关系,算法流程如下:
算法1:合作者关系挖掘算法
①遍历数据集Ddiam的每一条文献,输入待消歧作者文献Ddiam中的作者集合Author(作者与合作者);
②对Author建立合作者网络图G,取G中任意待消歧作者节点ai与aj,重复执行步骤③,直至所有待消歧作者节点处理完毕;
③根据GHOST算法定义的有效路径准则,搜索ai与aj之间的有效路径集合,根据有效路径条数与长度利用公式(1)计算ai与aj之间的相似度,形成相似度矩阵S;
④对矩阵S应用基于优先队列的层次聚类算法[ 10];/*层次聚类算法不需要事先指定最终簇的个数,通过枚举的方式进行实验来决定最佳的聚类阈值,而且效果等同原GHOST算法中的仿射传播算法*/
⑤返回第一次聚类后的文献簇集ClusterGHOST,算法结束。
算法1先遍历文献集每一条文献,并应用GHOST算法利用待消歧作者之间的合作者关系度来关联属于同一作者的文献,得到一个初始聚类的结果ClusterGHOST,对于 ClusterGHOST中任意一个簇,簇中的文献均属于同一作者。本文需要在初次聚类结果ClusterGHOST的基础上做进一步处理即进行文献信息的文本挖掘。
(3)文献信息文本挖掘层.
算法2:文献信息文本挖掘算法
①调用算法1进行初始化聚类;
②将单一作者文献(如果存在)集Single中每一篇文献单独作为一个簇并入算法1的结果文献簇集ClusterGHOST中,得到新的文献簇集ClusterGHOST+Single=ClusterGHOST∪Single;
③取ClusterGHOST+Single中每一个簇,重复步骤④,直至ClusterGHOST+Single=Φ;创建词项合并后的文献簇集Clusterfused=Φ;
④取ClusterGHOST+Single中某一个文献簇cluster,将cluster内所有文献标题及出版物名称的词项进行合并[ 11](簇中只有一条文献的情况可省略此步),即
Foreach paperi in cluster do
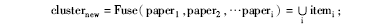
(其中itemi∈paperi中标题及出版物名称词项)
End
且令ClusterGHOST+Single=ClusterGHOST+Single-cluster,
Clusterfused=Clusterfused∪clusternew;
⑤取Clusterfused中任意两个簇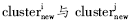 ,重复步骤⑥,计算两者之间文本相似度,直至clusternew中所有簇对处理完毕;
,重复步骤⑥,计算两者之间文本相似度,直至clusternew中所有簇对处理完毕;
⑥为簇建立文档向量V,以词频-逆文档频率(TF-IDF)[ 12]作为向量的特征值,并用余弦相似度计算两者之间的文本相似度值,从而构成簇的相似度矩阵Scluster,即:
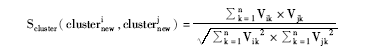
⑦对单一作者文献集Single中的文献进行优先分配处理,执行以下步骤:
Foreach singlei in Single do
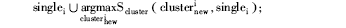
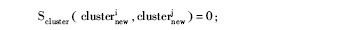
Clusterfused=Clusterfused-singlei;
End
Clusterfused进行分配操作后记为Clusterallocated;
⑧依据相似度矩阵Scluster,对Clusterallocated再次进行层次聚类算法;
⑨返回最终结果Cluster。
算法1中GHOST并没有考虑单一作者的情况,基于此,笔者在算法2的步骤②中完成单一作者的文献合并处理,并对合并后的所有文献信息的文本特征进行文本挖掘。步骤③至步骤⑦为文献文本特征相似度计算操作,由于文献标题和出版物名称中包含的词项非常少,导致词项-文档矩阵高维稀疏,所以需要在步骤③和步骤④中进行词项合并操作,那么在步骤⑧聚类计算过程中,只需比较簇之间的相似度而不是比较簇中两两文献信息之间的相似度,从而显著减少了比较的次数,步骤⑤和步骤⑥即为计算簇之间相似度的步骤。另外,笔者考虑到大的簇中词项较多,而层次聚类算法会偏向于先对大的簇进行聚类,因此在聚类之前即步骤⑤和步骤⑥中对单一作者的文献进行优先分配处理,算法2输出的是最终的聚类结果。
下面以一个简单的例子来说明实验的过程以及原理。对于表1中的待消歧作者“M Brown”有如下部分文献集,如表2所示:
| 表2 待消歧作者M Brown的部分文献集 |
Cluster1:文献2,文献3;
Cluster2:文献4,文献5;
Cluster3:文献6,文献7。
由于文献1没有合作者,因此单独作为一个“Cluster4:文献1”并入ClusterGHOST中得到ClusterGHOST+Single={Cluster1,Cluster2,Cluster3,Cluster4}。对ClusterGHOST+Single继续应用算法2,由于簇Cluster1、Cluster2以及单一作者簇Cluster4的文献标题与出版物名称主要与“Digital Libraries”、“ACM”、“JCDL”相关,通过文本挖掘后将被合并为一个簇Cluster’1,而对于簇Cluster3,其文献标题与出版物名称主要涉及“Web”、“Computer”等词,选词上几乎没有什么交集,因而与簇Cluster’1主题无关,从而不进行合并。最终得到的聚类结果为:
Cluster’1:Cluster1,Cluster2,Cluster4;
Cluster’2:Cluster3。
为了进一步看到改进后的作者名消歧算法的消歧效果,将对表1中的所有文献数据进行实验,实验中采用信息检索中常用的评价指标正确率(P)、召回率(R)、F1值[ 10]来对聚类结果进行评价,各个指标定义如下: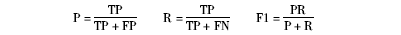
其中,真阳性(True-Positive, TP)决策将两个同一作者的文献归入一个簇,在此过程中会犯两类错误:FP决策会将两个不是同一作者的文献归入一个簇,而FN决策将两个同一作者的文献归入不同簇。
对表1中的文献数据除去单一作者的文献数据后应用GHOST算法得到的结果如表3所示:
| 表3 单纯应用GHOST算法得到的结果 |
| 表4 结合文本挖掘得到的结果 |
本文在深入分析GHOST算法的基础上,将GHOST算法用于文献数据库中的作者名消歧,针对GHOST算法的局限性,结合对文献信息的文本挖掘,提出一种更完善的作者名称消歧算法,旨在提高现有作者名消歧算法的效率和识别结果的准确性,并为自动化消歧方法在文献数据库中更好地应用提供技术支持,进而有助于科技评价、学术研究以及科研管理等研究工作。
利用余弦相似度进行相似度计算无法考虑异词同义的情况,造成本算法召回率方面还存在不足,因而在下一步工作中可以考虑从语义关联的层面进行文本挖掘,例如引入基于潜在语义分析(LSA)的统计语义模型以及基于知识库的语义词聚类等方法。另外在实际应用中,还可以加入用户反馈机制,以便能够及时发现消歧结果不够理想的作者实体[ 13],对聚类的阈值进行适当调节,从而改进消歧效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|