






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于MapReduce的书目数据关联匹配研究
引用本文
虞为, 陈俊鹏. 基于MapReduce的书目数据关联匹配研究. 现代图书情报技术, 2013, 29(9): 15-22
Yu Wei, Chen Junpeng. Linking and Mapping of Library Catalogue Data Based on MapReduce. New Technology of Library and Information Service, 2013, 29(9): 15-22
Permissions
Yu Wei, Chen Junpeng. Linking and Mapping of Library Catalogue Data Based on MapReduce. New Technology of Library and Information Service, 2013, 29(9): 15-22
基于MapReduce的书目数据关联匹配研究
摘要
提出一个基于MapReduce的书目数据关联匹配架构, 通过参引MODS本体将MARC格式的书目数据转换成关联数据格式。再通过对书目数据和书目数据间的关联匹配, 以及书目数据和开放关联社区其他的关联数据间的匹配初步实现书目数据和其他关联数据集间的语义关联, 使关联的书目数据成为关联开放数据社区中的一部分, 为图书馆的知识发现和语义检索服务提供有效的语义数据支持。
关键词:
MapReduce; 关联匹配; 书目数据; 关联数据
Linking and Mapping of Library Catalogue Data Based on MapReduce
Abstract
In this paper, the MARC data is transformed to linked data, based on MapReduce model and MODS Onto-logy. Through the mapping among different linked open data sets, the library catalogue data can become part of the linked open data community and provide efficient semantic data to knowledge discovery and semantic service.
Keyword:
MapReduce; Mapping and linkage; Catalogue data; Linked data
1 引 言
在互联网大数据时代, 关联数据是构建网络大数据集之间的语义连接的有效途径[ 1]。关联数据的主要特性之一就是对不同的RDF数据集间有语义关联的实体或属性建立关联关系 (如owl:sameAs, rdfs:seeAlso) , 同时通过HTTP协议和URI实现对互联网上信息对象的发现、关联和共享服务。因此, 实现不同关联数据集间的关联匹配是实现互联网信息共享的基础, 受到来自研究领域和工业界的广泛关注。关联开放数据 (Linking Open Data, LOD)[2]运动得到广泛的支持和关注, 来自各个会议、学术组织和企业团体发布了大量的关联开放数据。这些关联数据中包括地理信息[ 3]、生物科学数据[ 4]、百科词条[ 5]、政府信息[ 6]、出版数据[ 7]等。关联数据已渗透到网络信息服务的方方面面, 成为新的网络应用服务增长点和新研究热点。
传统的书目数据是以MARC格式存放的一维线性组织数据, 拥有结构化程度高、机读速度快等优点, 被图书馆大量采用。但同时, MARC数据格式也存在缺乏语义信息、没有对象层次、无法适应互联网环境下对信息共享和语义知识发现的需求的缺点。本文在对相关工作进行分析的基础上, 提出基于MapReduce模型的书目数据关联匹配架构, 通过对书目数据进行转换和关联匹配实现书目数据和其他的数据源间的语义关联。
2 相关工作
目前, 国内外已在图书馆关联数据服务研究方面取得了不少成果和进展。瑞典国家图书馆LIBRIS国家书目关联数据[ 7]是全球第一个将书目数据发布成关联数据的联合目录, 开放了所属的200多个成员馆的约650万条书目记录、20万条规范文档记录等, 并创立了和DBpedia之间的关联链接。美国国会图书馆关联数据服务LCSH以SKOS格式实现数据关联化, 并创建了不同资源之间的联系[ 8]。2012年6月, OCLC将WorldCat.org中的书目元数据发布为关联数据, 是目前Web上最大的关联书目数据[ 9]。国内也有不少关于图书馆关联数据的研究。OTCSS[10]在中文叙词表的基础上通过引入本体相关的理论和技术来完成从中文叙词表到关联数据的转换。语义数字图书馆的核心元数据本体构建[11]通过连接不同的元数据构建关联数据在元数据层的无缝连接。而夏翠娟等[12]以Drupal为平台, 对中国历史纪年和公元纪年对照表进行了关联数据格式的发布。白海燕等[ 13]对关联数据的自动关联构建做了相关的介绍。
除了图书馆, 其他的文献发布和出版机构也积极地引入关联数据作为图书论文发布的有效工具。著名的计算机科技文献书目数据库DBLP已通过D2R服务器将关系型数据库中的论文信息全部转换成关联数据并在互联网上公开发布[ 14]。同时, CiteSeer、ACM、NSF以及部分IEEE会议也将学术资源组织成关联数据的格式以方便在网络上访问。爱尔兰和英国的研究者将语义网学术会议资料组织成关联数据的格式发布, 并称之为Semantic Web Dog Food[ 15]。大量的关联数据带来了丰富的语义信息, 为用户提供了知识发现和语义检索的数据基础, 但也成为信息处理中的难点和热点。截止到2011年9月, 网络开放的关联数据云已包含310亿的RDF三元组, 5亿多的RDF关联连接[ 16]。如何对如此海量的关联数据进行匹配和处理成为关联数据服务中急需解决的问题。
针对这个问题, 国外一些图书信息发布机构尝试运用海量数据处理技术来实现快速有效的信息服务。如OCLC构建了云计算服务平台DuraCloud[ 17]以满足用户对大数据的快速有效的服务需求。本文采用书目数据作为实验数据, 构建基于分布式编程模型MapReduce[ 18]的书目数据关联匹配架构, 研究并初步实现书目数据向关联数据的转换, 为图书馆的信息服务提供多方位的数据补充和有效的语义链接。
3 书目数据关联匹配架构
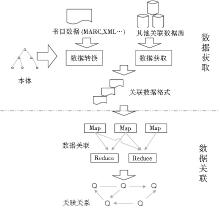
为了对书目数据进行有效的关联匹配, 本文提出了一个基于分布式编程模型MapReduce的书目数据关联匹配架构, 如图1所示:
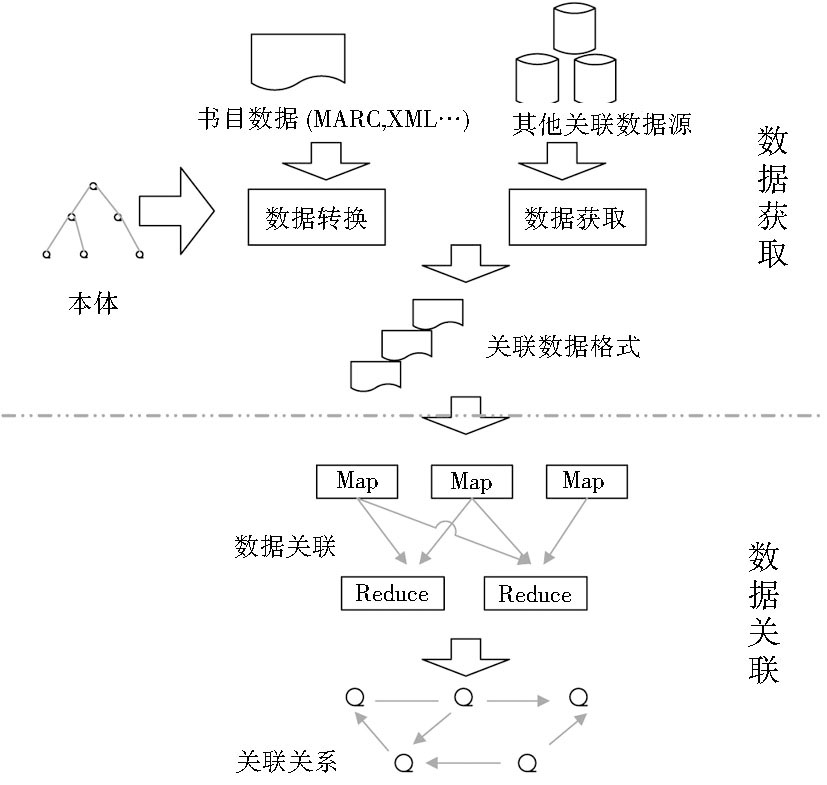 | 图1 关联匹配架构 |
这个架构主要有两部分功能:数据转换和获取功能、数据关联匹配功能。数据转换功能是对不同格式的书目数据进行转换, 使之成为关联数据格式。目前图书馆中的书目数据多是以MARC格式或XML格式存储, 但计算机并不能理解这些书目数据中蕴含的语义信息, 无法将这些书目数据和其他的数据互相关联起来。关联数据格式要求使用RDF数据, 同时以本体的形式对元数据格式进行描述, 使之能够描述数据中所包涵的语义信息。本文参照本体中的语义描述对书目数据进行转换, 使之成为关联数据格式。
为了获取互联网上其他的关联数据, 可以采用在线SPARQL Endpoint访问、语义搜索引擎查询关联数据集以及下载关联数据集这三种方式。对于从互联网上难以下载的网络大数据, 采用SPARQL Endpoint查询关联数据集的方式可以实时对其进行访问, 且有较高的准确率。但这种实时查询的方式需要占用大量的网络带宽, 且会造成较长的访问延迟。对于数据量较小的开源关联数据, 可以采用先将其下载到本地的方式。目前LOD中有34%的数据集提供本地文件下载, 而67%的数据集提供SPARQL Endpoint[ 19]。语义网搜索引擎如Sindice[ 20]、Falcons[ 21]等都提供查询API供机器访问, 但检索到的数据容易出现冗余和误差。本文实现了通过SPARQL Endpoint进行关联数据集的访问和下载到本地的关联数据获取方式。
在互联网大数据量的环境下, 快速获取和查找不同数据资源间的关联关系是实现关联数据服务的关键问题。在实际操作中, 数据之间的关联匹配操作类似求两张数据表间的笛卡尔映射, 会占用较长时间并产生大量的临时数据, 因此笔者采用MapReduce模型来获取不同数据资源间的关联关系。MapReduce模型是云计算技术中的一项主要技术, 通过把大数据分成较小的数据块, 并应用Map过程和Reduce过程来完成数据的分布式处理。MapReduce模型可以简化分布式程序的处理过程并提高对大数据的处理效率, 从而有效地查询关联数据集间的语义关联。
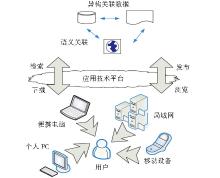
关联数据匹配的实现思路如图2所示。用户可以通过移动设备、便携电脑、个人PC、局域网等多种方式来访问相互有语义关联的关联数据。同时, 技术透明的应用技术平台可以为用户提供检索、浏览、发布、下载等多方位的关联数据服务。
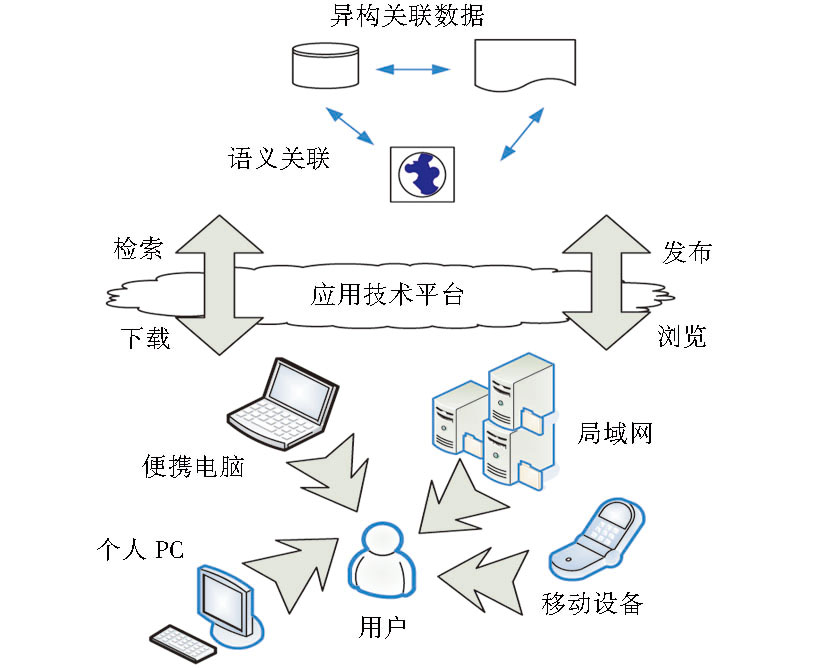 | 图2 关联数据匹配的实现思路 |
4 书目数据关联实现
4.1 RDF数据转换实现
(1) 元数据转换
为了把MARC格式的书目数据转换成RDF格式的关联数据, 首先需要将这些书目数据对应的元数据格式转换成本体表示的结构, 即构造和MARC格式相应的本体模式来描述书目数据中的语义信息。目前国内外已有一些描述书目数据的本体, 如欧盟DERI (Digital Enterprise Research Institute) 创建的MarcOnt Ontology[ 22], 用于不同格式的书目描述间的转换。D’ Arcus & Giasson等人开发的基于RDF的书目本体Bibiliographic Ontology Specification[ 23], 可以作为其他书目数据源交换的通用词汇基础。NSTL书目本体[ 24]作为将数据库中的书目数据转换成关联数据的本体参照。Kvision本体[25]利用书目数据自动构建本体辅助对网络信息资源的组织和利用。这些本体和知识组织都部分地实现了MARC格式向RDF数据及本体模式之间的转换。
MODS (Metadata Object Description Schema) 是由美国国会图书馆2002年制定的一个基于XML的文献描述Schema[ 26], 用于融合MARC和DC中的元数据描述, 能够和现有的数据资源描述高度兼容, 而且更加适应互联网环境。SIMILE[ 27]项目是由W3C、麻省理工大学图书馆和麻省理工大学科学和人工智能实验室联合研制开发的, 主要关注数字资源的互操作性。在SIMILE项目中, 由Stefano Mazzocchi开发研制的本体RDF Ontology for MODS V3.1[ 28]将MODS V3.1中的要素 (Element) 描述成本体中的类和属性, 以便对相关的数字资源进行转换和交换。
考虑到MODS承启了MARC格式中元数据的描述, 和其他图书情报领域的受控词表互为补充, 并在领域内有较强的权威性, 笔者在书目数据的转换中采用RDF Ontology for MODS V3.1作为书目数据转换的参照本体, 用于描述书目数据的元数据属性。RDF Ontology for MODS V3.1共定义了40个类和62个属性, 其中不包含子类的有11个类, 包含子类的有5个类;属性则分为6大类, 分别是General Properties、Item Properties、Name Properties、Item Relationships、Record Properties和Roles。
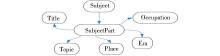
RDF Ontology for MODS V3.1各个类的名称和包含子类个数如表1所示。RDF Ontology for MODS V3.1的Subject Type中类和子类间继承关系如图3所示。
通过参照RDF Ontology for MODS V3.1, 笔者可以将书目数据转换成RDF的描述格式。
| 表1 RDF Ontology for MODS V3.1分类 |
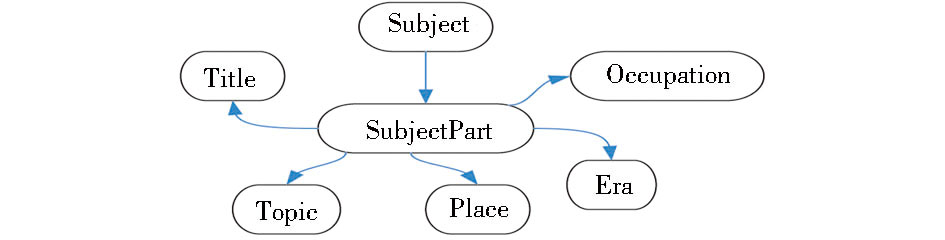 | 图3 Subject Type中类和子类间继承关系 |
(2) 书目数据转换
笔者从Project Gutenberg Australia (PGA) 项目[ 29]中下载1 281条MARC格式的书目数据。Project Gutenberg Australia网站是Choat在2001年创立的对澳大利亚的知识产权已经到期的电子书和电子文档进行免费共享的一个组织。为了对多种书目数据进行关联, 笔者从code4rda (Software for the Resource Description and Access (RDA) Library Standard) 项目中[ 30]下载了155兆的美国国家图书馆发布的NT格式的RDA数据。RDA格式[ 31]是图书馆资源描述的新方式, 和传统的FRBR方式相比, 它更适合对网络上的互联数据进行描述, 并且非常适合由关联数据的格式进行表达。NT格式是RDF数据格式的一种, 无需做数据转换即可和其他的网上数据资源进行关联匹配。笔者对PGA中下载的MARC格式数据进行转换, 如图4所示:
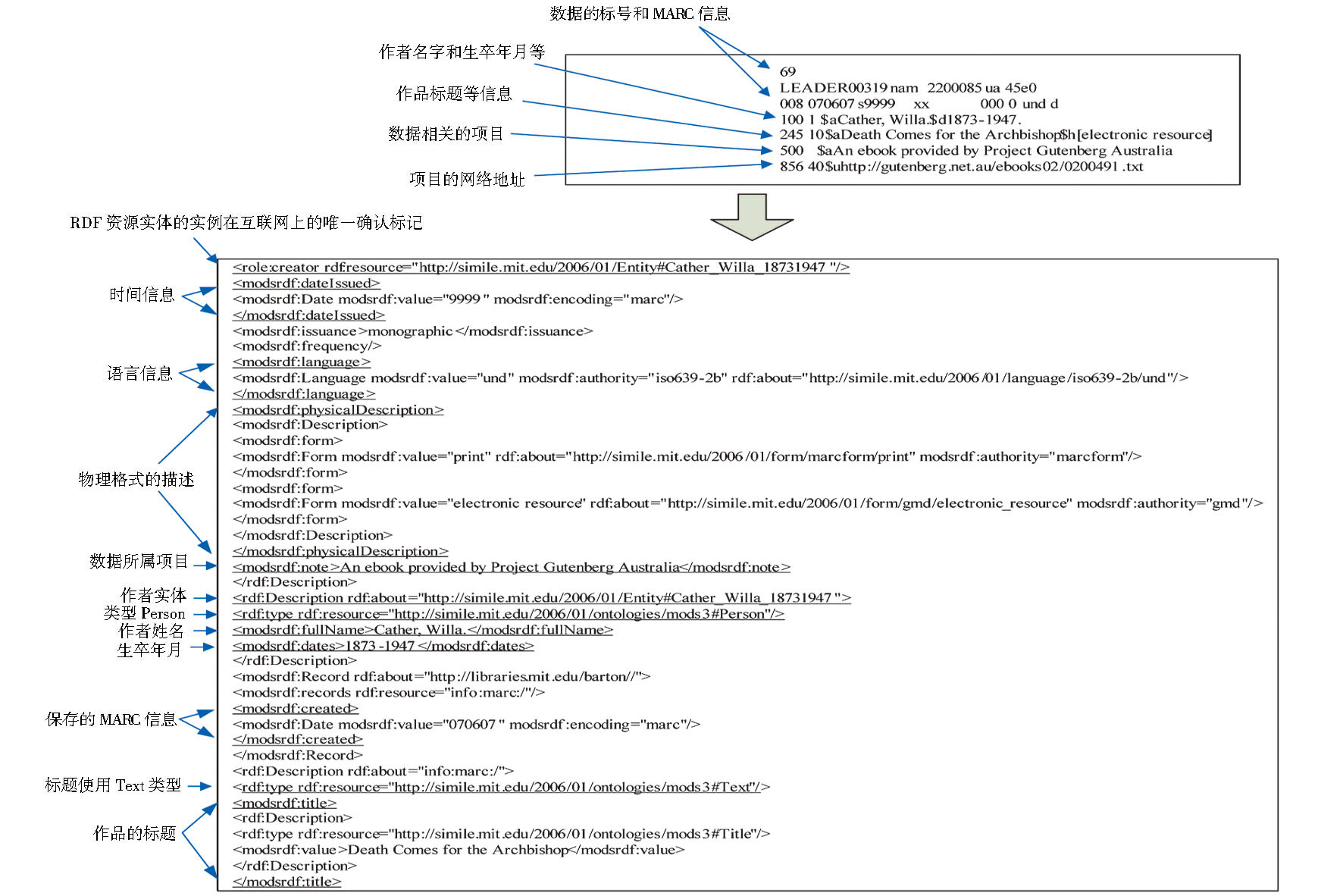 | 图4 书目数据转换 |
图4的上半部分是一段由MARC格式标记的书目数据, 包含相关的元数据信息和具体的书目信息。经过转换后生成的RDF文件保存了MARC数据中所应有的元数据信息, 同时把相关的书目数据实例转换成一个RDF资源实体的实例 (<role:creator rdf:resource=“http://simile.mit.edu/2006/01/Entity#Cather_Willa_18731947”/>) 。这个实例由URI标签唯一指定, 发布后可以在浏览器中直接浏览。对于书目数据中的作者数据, 转换后的RDF数据把作者作为一个实体 (Entity) 的实例 (<rdf:Description rdf:about=“http://simile.mit.edu/2006/01/Entity#Cather_Willa_18731947”>) , 并通过本体中定义的Person类型对作者这个实例进行数据类型的约束 (<rdf:type rdf:resource=“http://simile.mit.edu/2006/01/ontologies/mods3#Person”/>) 。作者的生卒年月 (<modsrdf:dates>1873-1947</modsrdf:dates>) 和全名 (<modsrdf:fullName>Cather, Willa.</modsrdf:fullName>) 是这个作者实例的属性, 和作者相关的作品被定义成本体中的文本类型 (<rdf:type rdf:resource=“http://simile.mit.edu/2006/01/ontologies/mods3#Text”/>) , 作品的标题 (<modsrdf:value>Death Comes for the Archbishop</modsrdf:value>) 标记为Title标签 (<modsrdf:title>) 。为了方便在互联网上进行信息共享, 转换后的RDF数据采用RDF/XML格式, 方便被其他的网络应用程序访问和处理。
为了最大化地防止信息丢失, 在MARC数据向RDF本体实例进行转换中保存了大部分的MARC数据物理格式和语言信息, 分别由标签modsrdf:dateIssued、modsrdf:language、modsrdf:physicalDescription等进行描述。而与原始MARC数据相关的项目信息也被保留在生成的RDF本体实例数据中, 由标签modsrdf:note进行标识。
通过对比RDF本体实例数据和MARC格式的书目数据, 可以看出RDF本体实例数据对语义关系和实体属性的描述更加精确, 依照本体定义的实体属性关系对数据进行层次化的定义和描述, 不仅仅是平面化的、简单的数据描述。本体实例的方式对书目数据中的各个不同的部分进行描述, 可以灵活地对这些数据进行有机的组织和阐释, 也符合语义网的命名规范和关联数据原则[ 32], 适用于现在广为接受的网络信息传播方式。
4.2 关联数据匹配
为了把图书馆的书目数据和其他关联数据集连接起来, 并成为开放关联数据社区的一部分, 笔者主要把MARC格式的书目数据和两类数据互相关联:其他格式的书目数据资源和开放关联数据社区中的非书目数据资源。通过把不同的出版机构之间的书目数据资源互相关联, 用户可以对相同的作者、主题、作品等有全面的认识, 从而进行全面和系统的查找和理解。另一方面, 通过把书目数据和开放关联数据社区中的非书目数据资源相互连接, 可以使图书馆的数据信息真正融入关联数据社区, 为图书馆的语义服务提供数据资源和语义关系, 对关联社区进行有效的扩展和补充。由于人名数据在书目数据中出现频次较高, 且有较高的辨识度, 不易发生歧义, 本文对关联数据的匹配主要从作者人名方面进行实现。
(1) MapReduce模型实现
为了实现数据关联匹配任务, 笔者使用开源软件Hadoop, 并应用分布式编程模型MapReduce来进行任务部署。Map过程先对数据进行处理, 然后将它们发给Reduce过程。Reduce过程接受到Map过程发来的文件后再进行详细的比较, 将有<owl:sameas>关系的关系对进行输出。这一过程的伪码如下所示:
Map (K, v) :
//K: document name
//v: target field
For each v:
V=Sort (v) ;
在Map过程中, 笔者将有相似的带比较字段的文件归并到一起。比如对文件中的人名字段进行比较, 可以把人名字段中姓的首字母相同的文件都放到同一个数据组中, 然后将这些有相似的带比较字段的文件发送给同一个Reduce过程进行处理。这一过程的伪码如下所示:
Reduce (K, V) :
//K: the similar target field value
//V: a array of the document D with the similar target field
L = null;
L ← V;
For each L (di, vi) and L (dj, vj) :
If di<>dj
Then Compare (L (di, vi) , L (dj, vj) ) ;
Reduce过程接受来自Map过程的中间数据, 对于被比较字段相似的两个文件, 如果它们不是同一个文件, 就执行比较程序Compare () , 找到并输出两个文件之间的关联关系。通过MapReduce模型, 笔者可以在Map过程中对数据进行预处理, 从而在Reduce过程中只需对被比较字段相似的文件做比较, 从而避免了对所有输入的文件做笛卡尔映射来找到两两相似的关系。同时, 由于MapReduce任务可以同时在多台计算机上并行运行, 可以有效地提高数据处理的效率。
(2) 书目数据间的关联匹配
在书目数据和书目数据的相互匹配中, 笔者使用由PGA项目提供的MARC数据和XML数据转换成的RDF/XML格式的数据, 见图4。另外, 还采用code4rda项目中的RDA形式的NT格式的书目数据, NT格式是以RDF三元组的形式来表示。图5所示的代码显示了书目的名称和作者关系, 包括书名“In a sunburned country”和作者“Bill Bryson”。
 | 图5 RDA形式的NT格式书目数据 |
为了找出两种书目数据之间的关系, 在进行关联比较的Compare () 部分笔者使用了开源的关联数据连接工具SILK[ 33], 用SILK-LSI来查找并构建两个书目数据集间的数据关联如图6所示:
 | 图6 SILK-LSI语义关联发现 |
SILK使用一种专有的连接语言Link Specificaiton
Language (SILK-LSI) 来完成对两个关联数据资源间的语义关联发现, SILK-LSI以XML的形式表现。由于两个书目数据都较易获取, 为了提高匹配效率, 笔者采用将数据源下载到本地进行匹配的方式。在SILK-LSI文件中使用<DataSources>对读取的数据源位置进行指定。如果需要在读取数据源时采用访问SPARQL Endpoint的方式, 只需要在<DataSources>标签中指明endpointURI即可。代码如下所示:
<DataSource id="dbpedia" type="sparqlEndpoint">
<Param name="endpointURI" value="/sparql" />
<Param name="retryCount" value="100" />
</DataSource>
其中, type="sparqlEndpoint"表明使用的是SPARQL Endpoint的方式进行访问, 对于一个返回数据的链接retryCount, 返回数据的数量是100个, 即value="100"。
对于两个关联数据源, 可以通过<Interlinks>标签来标注要进行匹配的关联信息, 并通过<Interlink>标签命名和解释每一个关联信息。图6显示了两个书目数据间的关联连接RdaLibrary, 它连接的源数据是RDF/XML格式数据中的Person类型, 目标数据是RDA数据中的purl:Person类型, 关系的类型是owl:sameAs关系。
在RDA数据中, 人名取用的preferredNameForThePerson标签的值 (value) , 而在RDF/XML格式数据中取的modsrdf:fullName的值。由于在不同的数据集中, 同一数据的表示形式可能会有区别, 如“Zane, Grey”在另一个数据集中的表现方式可能是“Grey Zane”。因此, 在进行匹配时, 去掉了数据中的标点和空格等没有意义的符号, 并把大小写不一致的数据全部转化为小写数据。这一步骤通过<TransformInput>中的函数来完成。经过转换后的两个字符串通过笔者定义的条件即相等关系equality来进行比较, 并给拥有此关系的关系组赋予权值1, 通过语句<Compare metric="equality" required="false" weight="1">来实现。对于owl:sameAs关系, 当两个进行匹配的关联实体间的最小相似度大于0.8的时候, 即认为这组实体关系为equality, 并对这组关联关系进行输出, 通过标签<Output>来完成。
通过对两组书目数据进程匹配, 可以得到两个数据源中关于作者的关联关系共56条。RDF/XML数据和RDA数据间owl:sameAs关系中的一个例子如图7所示, 描述了RDF/XML数据中的一个数据资源实体“Entity#Allen_Grant_18481899”和RDA数据中的数据资源“person/00006568-1”间的关联关系。
 | 图7 RDF/XML数据和RDA数据间owl:sameAs关系 |
通过找到这些数据集之间的“owl:sameAs”关系, 笔者可以将RDF/XML数据和RDA数据互相联系起来, 通过RDF/XML数据中的内容可以直接查找到RDA数据与之相对应的部分, 如相同作者的不同出版物、作品等, 反之通过RDA数据也可以有效查找到RDF/XML数据中的相关内容。
(3) 书目数据和DBpedia之间的关联匹配
对于开放关联数据社区中的数据, 笔者选用DBpedia来获取和书目数据间的关联关系。首先从网上获取DBpedia的相关数据227兆[ 34], 并把它和RDA书目数据以及RDF/XML书目数据进行匹配。DBpedia的数据格式如图8所示, 包含人名信息“Attila the Hun”, 类型是“foaf/0.1/Person”, 以及相关描述“Khan of the Huns from 434 until his death”。
 | 图8 DBpedia数据 |
在DBpedia数据中关于人名的解释使用FOAF中定义的Person格式, 这种方式将人名分成了“surName”和“lastName”两部分来进行组织。因此, 笔者在做匹配的时候需要将这两部分组合起来以适应统一的人名匹配模式。
通过将DBpedia的数据和RDF/XML数据进行匹配, 得到两组数据间相关的连接共134条, 如图9所示, 关联连接把RDF/XML书目数据中作者和DBpedia中的人物联系起来。用户可以通过这些连接来查看作者在DBpedia中的相关生平和事迹, 也可以通过DBpedia中的人物来查询图书馆书目数据中与其相关的作品和出版物。
 | 图9 DBpedia和RDF/XML数据间的owl:sameAs关系 |
同样, 对DBpedia和RDA数据中有语义关联的数据进行查找, 共发现两者间的owl:sameAs关系1 279条, 其关联关系如图10所示, 通过对不同数据源之间进行关联匹配, 可以找到其中相同的部分并建立语义连接, 从而方便读者进行信息浏览和知识发现。
 | 图10 DBpedia和RDA数据间的owl:sameAs关系 |
5 结 语
关联数据作为语义网的最佳实践, 在网络信息服务的各个方面都得到相关的应用和研究。本文以书目数据为研究对象, 提出了一种对不同格式的书目数据进行转换, 并基于MapReduce模型将书目数据和其他的关联数据资源互相关联的方法, 为实现图书馆的关联数据服务提供了丰富的语义连接和技术实现。在后续的工作中, 笔者将研究把已经转换的书目关联数据发布在网上, 并提供针对语义关联的查询检索服务, 进一步实现对关联数据在图书馆信息服务中的应用。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|