{kind=link}
{kind=link}
{kind=link}
词语位置加权TextRank的关键词抽取研究
引用本文
夏天. 词语位置加权TextRank的关键词抽取研究. 现代图书情报技术, 2013, 29(9): 30-34
Xia Tian. Study on Keyword Extraction Using Word Position Weighted TextRank. New Technology of Library and Information Service, 2013, 29(9): 30-34
Permissions
Xia Tian. Study on Keyword Extraction Using Word Position Weighted TextRank. New Technology of Library and Information Service, 2013, 29(9): 30-34
词语位置加权TextRank的关键词抽取研究
摘要
把关键词抽取问题看作是构成文档词语的重要性排序问题, 基于TextRank基本思想, 构建候选关键词图, 引入覆盖影响力、位置影响力和频度影响力用于计算词语之间的影响力概率转移矩阵, 通过迭代法实现候选关键词分值计算, 并挑选前N个作为关键词抽取结果。实验结果表明, 对词语位置加权的TextRank方法优于传统的TextRank方法和基于LDA主题模型的关键词抽取方法。
关键词:
关键词抽取; 词排序; TextRank; 图模型; LDA
Study on Keyword Extraction Using Word Position Weighted TextRank
Abstract
The keyword extraction problem is taken as a word importance ranking problem. In this paper, candidate keyword graph is constructed based on TextRank, and the influences of word coverage, location and frequency are used to calculate the probability transition matrix, then, the word score is calculated by iterative method, and the top N candidate keywords are picked as the final results. Experimental results show that the proposed word position weighted TextRank method is better than the traditional TextRank method and LDA topic model method.
Keyword:
Keyword extraction; Word rank; TextRank; Graph model; LDA
1 引 言
关键词是表达一个文档核心意义的最小单元, 人工抽取关键词耗时费力, 结果因人而异, 因此, 实现自动抽取具有重要意义。关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组, 抽取方法既可以通过训练语料构建模型实现, 也可以借助于词语之间的关系直接从文本本身抽取, 后者因无需训练过程, 应用较为方便, TextRank[ 1]是其中的典型代表。
经典的TextRank算法在应用于关键词抽取时, 未探讨词语对相邻结点影响力强弱不同时的处理方法。本文贡献在于指出词语本身的重要性差异会影响相邻结点的影响力传递结果, 并通过分析影响词语重要性的主要因素, 提出从词语的覆盖影响力、位置影响力和频度影响力三个方面加权计算邻接词语所传递的影响力, 并归并计算形成候选关键词的整体概率转移矩阵, 结合抽税机制实现词语排序和关键词抽取, 取得了较好的实验结果。
2 研究背景
针对关键词抽取问题已经开展了大量研究, 部分研究者把关键词抽取看作是一个分类问题[ 2, 3], 通过训练数据构建学习模型, 进而判断词语是归属于关键词类别还是非关键词类别, 属于典型的有指导学习方法。有指导学习需要事先标注高质量的训练数据, 人工预处理的代价较高。
本文关注的重点是无指导关键词抽取方法的研究, 主流方法可归纳为三种:基于TF-IDF统计特征的关键词抽取、基于主题模型的关键词抽取和基于词图模型的关键词抽取方法。其中, 基于TF-IDF统计特征进行关键词抽取是一种简单易行的常用方法, 但这种方法忽略了重要的低频词语和文档内部的主题分布语义特征, 因此, 基于主题模型的关键词抽取方法在近年来得到了人们的重视。主题模型中以基于LDA的关键词抽取方法应用最为广泛[ 4, 5, 6], LDA 是一种无指导机器学习技术[ 7], 通过大量已知的“词语-文档”矩阵和一系列训练, 推理出隐藏在内部的“文档-主题”分布和“主题-词语”分布, 出现在文档中主要主题中的主要词语更有可能被识别为关键词。主题模型需要对数据进行训练得到, 关键词抽取的效果与训练数据的主题分布关系密切。
与基于TF-IDF和LDA的关键词抽取方法不同, 以TextRank为典型代表的基于词图模型的关键词抽取算法[ 1], 不需要事先对多篇文档进行学习训练, 因其简洁有效而得到了广泛应用。TextRank的思想来源于PageRank[ 8], 通过把文本分割成若干组成单元并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词抽取。
TextRank的迭代模型在理论上支持带权运算, 但文献[1]在应用TextRank方法进行英文关键词抽取时, 仅考虑了词语的词性信息, 采用的是词语结点影响力均分的无权图模型, 以A、B和C三个词语为例, 假设A与B相邻接, A与C相邻接, 传统TextRank算法会把A的影响力分值以50%的比例均匀传递到B和C, 而与B和C本身的差异无关。然而, 根据马太效应, 与A相邻的重要词语应获取更多的由A所传递的分值, 非重要词语所吸收的分值相应减少。基于这一假设, 本文分析提出了词语结点影响力的相关因素, 并给出了影响力分值的具体迭代计算方法, 从而显著提高了单文档的关键词抽取效果。
3 候选关键词图的构建
简单说来, 可以将关键词的抽取问题转换为构成文档词语的重要性排序问题, 把词语按照表达文档意图的强度递减排序, 前n个词语即可作为文档的关键词。如果能够将构成文档的词语及其关系组织成为一张图, 即可利用图模型的有关理论对结点进行排序, 进而实现关键词抽取, 为此, 在文献[1]基础上, 笔者针对中文文本采用如下步骤构建候选关键词图:
(1) 把给定文本T按照完整句子进行分割, 即T=[S1, S2, …, Sm];
(2) 对于每一个句子Si∈T, 进行中文分词和词性标注处理, 仅保留切分后的重要词语, 如名词、动词、形容词, 即Si=[ti, 1, ti, 2, …, ti, n], 其中, ti, j∈Si是保留后的候选关键词;
(3) 构建候选关键词图G= (V, E) , 其中, V为结点集, 由步骤 (2) 生成的候选关键词组成, EV×V, 对于每一个ti, j∈Si, ti, j+1∈Si, 有<ti, j, ti, j+1>∈E。
为便于形式化描述, 令候选关键词图G= (V, E) 是由结点集V和边集E组成的一个有向图, 对于任意的一个结点vi, 令:
In (vi) ={vj|<vj, vi>∈E}
Out (vi) ={vj|<vi, vj>∈E}
即In (vi) 表示指向结点vi的结点集合, Out (vi) 表示结点vi所指向的结点的集合。
进一步, 令wij表示由结点vi指向vj的边的权重, 则结点vi的分值可通过如下公式计算[ 1]:
WS (vi) = (1-d) +d×vj∈In (vi)wjivk∈Out (vj)wjkWS (vj) (1)
公式 (1) 即为TextRank的递归公式, 与最早提出的PageRank算法完全一致, 通过结点之间的投票或推荐机制, 实现重要性排序, 一个结点链入的结点集表示其投票支持者, 投票者越重要、数量越多, 则被投票者的排名越靠前。其中的d为阻尼系数 (Damping Factor) , 一般取值为0.85, 其在PageRank中的原始意义表示在任意时刻, 用户到达某页面后并继续向后浏览的概率值[ 8]。
TextRank的主要贡献在于将PageRank的思想引入到文本组成单元的重要性排序领域, TextRank算法应用于关键词抽取时, 构建的是一种无向无权图, 每一个结点被赋予一个初始值1, 然后迭代计算权重。直观看来, 可以根据某种策略对部分重要的结点赋予较高的初值, 以改善排序结果, 但这种方法无法奏效, 实际上, 排序的结果对应转移矩阵的特征向量, 和结点赋予的初值无关, 而是由连接结点的边的权重所决定。
笔者将基于候选关键词图, 讨论如何引入边的权重以改进排序效果, 实现关键词抽取。
4 权重赋值与关键词抽取
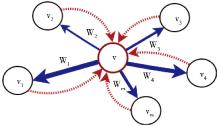
假设候选关键词图中与词语v相关的结点和边如图1所示:
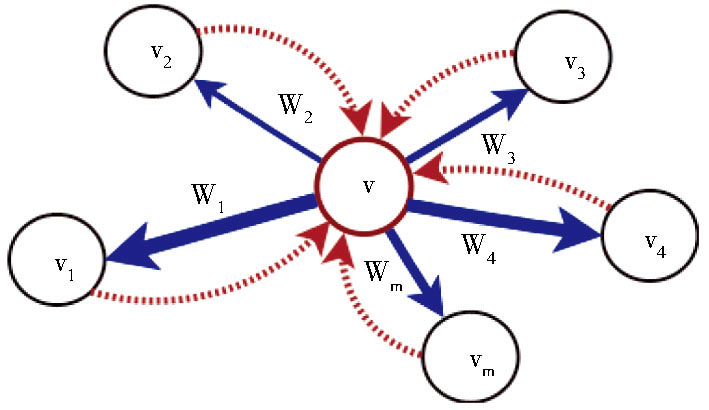 | 图1 候选关键词图示例 |
其中带箭头实线表示结点v到所指向结点vi的转移概率, 线条的粗细表示转移概率的大小;虚线则表示由vi结点跳转到结点v的转移概率。
如果用权重的大小代表转移概率的大小, 构建两个词语之间的权重就成为关键词抽取的关键。通过观察分析, 发现结点之间的权重主要与以下因素密切相关:
(1) 覆盖重要性:如果指向候选关键词t的不同词语数量越多, 则t越重要, 即t所拥有的不同投票者越多, 其重要性越高。
(2) 位置重要性:候选关键词t出现在重要的位置, 例如标题、摘要、段落的首句中, 则t越重要。
(3) 频度重要性:候选关键词t出现的频度越高, 则t越重要。
对于图中的任一结点v来说, 其重要性得分由其相邻结点的贡献组成 (如图1中相邻结点:v1, v2, …, vm) , 而其本身的得分也将被转移到相邻结点, 即影响力的转移。根据以上假设, 一个结点对相邻结点集的影响力可以分解为三个组成部分:覆盖重要性的影响力、词语重要性的影响力和频度重要性的影响力, 令W表示结点的整体影响力权重, α, β, γ分别表示这三类不同的影响力所占的比重, 则有:
W=α+β+γ=1 (2)
对于任意两个结点vi和vj, 结点vi对vj的影响力通过其有向边e=<vi, vj>传递, 边的权重决定了vj最终所获得vi部分的分值大小。针对不同类型的影响力权重, 分别给出其计算方法:
(1) 令wα (vi, vj) 表示结点vi的覆盖影响力传递到结点vj的权重, 计算公式如下:
wα (vi, vj) =1|Out (Vi) | (3)
其中, |Out (Vi) |表示vi所指向的结点集合的元素数量, 公式 (3) 说明结点vi的覆盖影响力将会被均匀传递到相邻结点。
(2) 令wβ (vi, vj) 表示结点vi的词语重要性影响力传递到结点vj的权重, 计算公式如下:
wβ (vi, vj) =I (vj) vk∈Out (vi)I (vk) (4)
其中, I (vj) 表示结点vj的重要性取值, 重要性赋值可根据实际需要采取不同的策略, 在本文实验中, 笔者仅处理了词语位置影响力, 即采用如下方式对词语重要性进行赋值:
I (v) =λv所对应的词语在标题中出现
1其他情况 (5)
其中, λ为一个大于1的参数。
(3) 令wγ (vi, vj) 表示结点vi的频度影响力传递到结点vj的权重, 计算公式如下:
wγ (vi, vj) =C (v) vk∈Out (vi)C (vk) (6)
其中, C (v) 表示结点v在文本中出现的次数, 公式 (6) 体现出高频度的词语将从连接点获得更高的影响力权重。
假设文本T共包含n个候选关键词, 即T所对应的候选关键词图由n个结点组成, 所有结点的初始分值可以通过一个分量为1、维数为n的向量B0表示, 即:
B0= (1n, 1n, …, 1n)
同时, 构建词语之间的影响力转移矩阵M如下:
M=〖JB ([〗w11w12…w1n
w21w22…w2n
wn1wn2…wnn
其中, M中的第j列元素表示第j个候选关键词vj的影响力转移到其他词语时的权重分配情况, 每一列数值之和为1。元素wij表示vj的影响力转移到第i个词语vi的权重比重, 可通过下式计算得到:
wij=α·wα (vj, vi) +β·wβ (vj, vi) +γ·wγ (vj, vi) (7)
给定一个结点vi, 令S (vi) 表示每次迭代计算中从其入点集合In (vi) 中所计算得到的分值, 结合上述公式, S (vi) 可通过下式计算得到:
S (vi) =vj∈In (vi)S (vj) ×wji (8)
所有结点的分值在经过转移矩阵的第一次转移之后, 其新分值B1可通过M×B0计算得到, 但是, 这种迭代计算方式无法处理非连通候选关键词图, 为此, 实验中引入了链接分析中的抽税机制[ 9], 允许每个结点能够以一个较小的概率随机转移到任一个结点, 此时, 迭代公式更改为:
Bi=d×M×Bi-1+ (1-d) ×e/n (9)
其中, e为一个所有分量为1、维数为n的向量。
基于公式 (9) 进行迭代运算, Bi最终会收敛, 当两次迭代结果Bi和Bi-1之间的差异非常小, 趋近于零时, 停止迭代运算。设最终迭代结果为B, 进一步对B按分值大小降序排序, 并取前σ个候选关键词作为关键词抽取结果。
5 实验结果
本文提出的关键词抽取算法采用Java1.6予以实现, 分词和词性标注使用中国科学院计算技术研究所ICTCLAS的Java开源实现ANSJhttps://github.com/ansjsun/ansj_seg
为测试算法的有效性, 笔者选择基于LDA的关键词抽取算法进行对比, 基于文献[7]中对LDA模型的描述, 令φ表示LDA中主题-词语的概率分布, φzw表示词语w在主题z中的概率, θ表示文档-主题的概率分布, θ(d)z表示指定文档d中的主题z的概率。则一个词语w在文档d中面向t个主题的概率可通过以下公式计算:
p (w|d) =tj=1φ(z=j)w θ(d)z=j
该数值的大小可以反映词语在文档中面向主题的重要性, 按照大小顺序挑选前σ个词语作为关键词, 即可实现关键词的抽取。
鉴于目前缺少权威的面向关键词抽取的中文公开测试数据集, 为保证测试数据的客观性和测试结果的可重现性, 实验针对门户网站所提供的较为规范的新闻报道, 采用自主研发的主题链接自动抽取算法[ 10]和网页正文自动抽取算法[ 11], 自动提取网页包含的标题、内容以及META中的关键词, 去除关键词为空、关键词为文章标题的无效报道, 并人工审核抽取结果, 保证所采用的基准关键词与文章主题内容一致, 最终保留1 000篇报道形成测试数据集合测试数据集已发布到如下地址:https://github.com/iamxiatian/data/tree/master/sohu-dataset., 每篇测试文档所拥有的关键词数量平均为2.73个。为评估关键词抽取效果, 用KA表示文章本身所提供的关键词集合, KB表示算法抽取出的关键词集合, 则准确率P、召回率R和常用的宏平均F值可通过如下公式计算:
P=|KA∩KB||KB| R=|KA∩KB||KA| F=2×P×RP+R
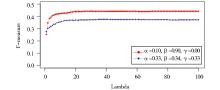
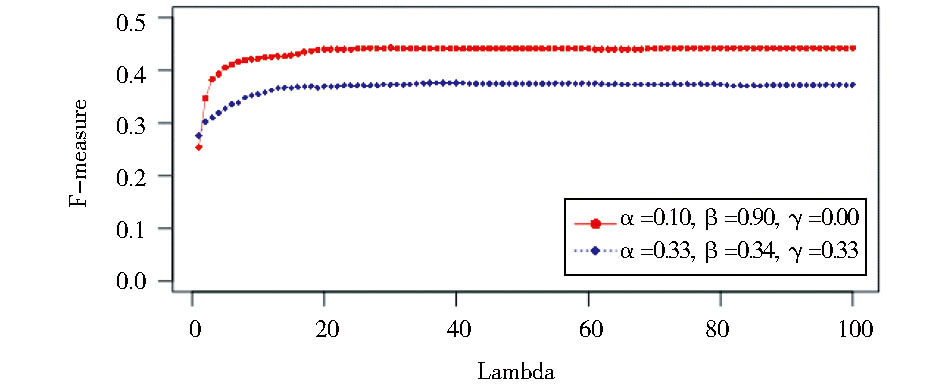
实验中, d=0.85;σ=5, 矩阵迭代运算的终止条件为两次迭代结果的差异值小于等于0.005, 或者迭代次数超过20。为确定参数λ的合理取值, 选定两组较有代表性的α, β, γ参数, 分别计算λ从1到100时的F值变化情况, 结果如图2所示:
 | 图2 不同取值对应的F值分布曲线 |
对于α=0.33, β=0.34, γ=0.33的情况, 在λ取值为36到41之中的任一值时, F值达到最大值0.3761;当α=0.1, β=0.9, γ=0.0时, λ取值为30时达到最大值0.4429。通过观察分析可得, λ超过20之后, 不同取值对于准确率的影响基本一致, 在30附近已经比较稳定, 因此, 实验选定λ=30, 进一步针对α、β、γ不同的参数组合, 分别计算每一篇报道的关键词抽取结果, 并取其均值, 结果如表1所示:
| 表1 实验结果 |
当参数取α=1, β=0, γ=0时, 算法即转化为传统的基于TextRank的关键词抽取算法, 从表1可以看出, 传统方式在实验数据中的F值仅有25.40%, 是实验中不同参数组合中F值最低的情况, 而均匀分配参数权重时, F值提高到37.32%。从数据中还可以看出, 以位置信息为主的词语本身的重要性起了最为重要的作用, 而词语频度信息所起作用较小。
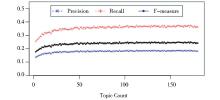
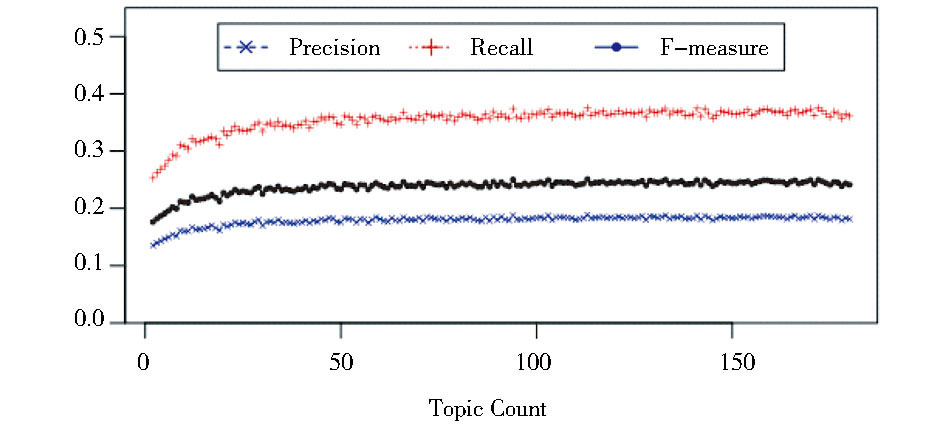
同时, 对于实验中所对比的LDA算法, 文档的内容由文档标题拼接文档正文组合而成, 词汇的概率分布通过Gibbs抽样获取, Gibbs抽样的主题数目记为K, 超参数α=50/K, β=0.01, 每次迭代次数为1 000。由于实验数据的内容主题较为分散, 分别统计了主题数目K从2到180变化时, 关键词抽取结果的变化情况, 如图3所示:
 | 图3 不同主题数量的关键词抽取结果 |
针对基于LDA的关键词抽取方法, 由图3可得出两点结论:主题数量参数的设置对关键词抽取结果有一定影响;基于LDA的关键词抽取算法在主题分布不明显的情况下, 准确率不高, 实验中最高的F值仅为25.14% (此时主题数量K=113) , 与传统的TextRank算法抽取结果相似。究其原因, LDA算法基于词袋假设, 未考虑词语的位置信息, 适用于文档集背后存在较有规律的主题分布的情况。可见, 本文所提方法充分利用了文档本身的信息, 抽取效果显著优于主题模型的关键词抽取方法和传统的TextRank抽取方法。
6 结 语
本文介绍了TextRank用于关键词抽取的基本思想和候选关键词图的构建过程, 提出引入覆盖影响力、位置影响力和频度影响力用于计算候选关键词之间的转移概率, 进而构建词语之间的影响力概率转移矩阵, 通过迭代法计算候选关键词的重要性分值, 并挑选高分值的候选关键词作为文本的关键词抽取结果。实验结果表明, 对于单文档的无指导关键词抽取来说, 词语所在的位置对于正确抽取关键词的贡献最大, 不同投票构成的覆盖影响力次之, 而频度的重要性较低。同时, 由于LDA基于词袋假设, 不考虑文档中词语的排列顺序和位置, 对于主题数量不确定的数据集, 其抽取的准确率显著低于改进的TextRank抽取方法。
下一步研究工作包括:考虑词语组合情况, 实现由多词构成的关键词抽取;考虑词语位置因素、词语在主题分布中的重要性因素, 优化词语重要性的参数设置, 并进行试验分析。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|