{kind=link}
{kind=link}
基于语义指纹的中文文本快速去重
引用本文
李纲, 毛进, 陈璟浩. 基于语义指纹的中文文本快速去重. 现代图书情报技术, 2013, 29(9): 41-47
Li Gang, Mao Jin, Chen Jinghao. Fast Duplicate Detection for Chinese Texts Based on Semantic Fingerprint. New Technology of Library and Information Service, 2013, 29(9): 41-47
Permissions
Li Gang, Mao Jin, Chen Jinghao. Fast Duplicate Detection for Chinese Texts Based on Semantic Fingerprint. New Technology of Library and Information Service, 2013, 29(9): 41-47
基于语义指纹的中文文本快速去重
摘要
针对中文文本, 抽取出文本内容特征, 结合Simhash算法生成中文文本的语义指纹, 通过语义指纹的海明距离判断文本间相似程度。整合Single-Pass快速聚类算法对语义指纹快速聚类, 所得的语义指纹聚类即为文本去重的最终结果, 从而实现面向中文文本的快速去重流程。实验过程中, 通过与Shingle算法对比, 可以体现该方法在算法精确度、鲁棒性等方面的优势, 同时该方法的运行速度优势也能较好地支持大数据量文本的去重操作。
关键词:
语义指纹; Simhash; Single-Pass; 文本去重
Fast Duplicate Detection for Chinese Texts Based on Semantic Fingerprint
Abstract
Oriented to Chinese texts, text features are firstly extracted to generate semantic fingerprints by performing the Simhash algorithm. The Hamming Distances between semantic fingerprints are applied to determine the similarity between texts. Then, as the last step of the entire process of detecting duplicates for Chinese text, the Single-Pass clustering algorithm is integrated to cluster the generated semantic fingerprints, after which the clusters of fingerprints are the final results. By comparing with the Shingle algorithm, the experiment shows that the Simhash approach is superior at both precise and robustness, and the Simhash approach is capable to process large amount of texts due to its rapidness.
Keyword:
Semantic fingerprint; Simhash; Single-Pass; Duplicate detection
1 引 言
随着各种各样信息的不断增长, 可供用户使用的信息资源不断增多, 同时用户的信息搜寻成本也越来越大, “信息迷航”问题越来越突出。导致这一问题的原因之一是信息复制的边际成本接近于零, 相似或重复内容增多。从信息资源集合中去除重复内容能提升用户使用信息资源的效率, 是信息资源管理中的一个重要工作。目前, 信息内容去重已应用于多种应用场景。在搜索引擎方面, 大量重复网页的存在一方面增加了搜索引擎在系统存储和运行上的负担, 同时也影响到检索算法的性能, 重复网页的检测和去除能在一定程度上减轻系统负担、提升检索效果, 也能增加用户对搜索结果排序的满意度[ 1]。在垃圾信息过滤方面, 垃圾信息往往表现出多次发布现象, 重复内容检测也是识别垃圾信息的手段之一, 例如针对博客评论中广泛存在的广告机器人特点, 采用信息指纹的方法对博客中的垃圾评论进行识别和过滤[ 2]。在文件去重方面, 利用内容去重方法可以识别文件内容的相似性, 用于追踪科技文献中的相似性, 从而识别论文抄袭现象[ 3]。
在目前大数据环境下, 需要快速地处理文本内容, 实现快速文本去重, 以满足对大数据量处理的要求。在此
背景下, 本文针对中文文本, 先提取出文本特征, 运用Simhash算法根据中文文本特征生成语义指纹, 通过判断不同文本语义指纹的比特位差异程度来识别文本间的相似程度, 并在语义指纹基础上应用Single-Pass快速聚类算法, 实现文本语义指纹快速聚类, 达到中文文本快速去重的目的。
2 文本内容去重方法
文本内容去重任务关注的是从文本数据集中找到相同或者高度相似的文本。在搜索引擎领域和目前大数据环境下, 如何快速地识别相同或相似文本是文本内容去重的挑战之一。目前主要的文本内容去重方法有两种:基于相似性的方法和基于摘要技术的方法。
2.1 基于相似性的方法
基于相似性的方法是用文本的内容或结构的相似性来判断文本是否属于重复文本。在内容相似性识别方面, 常见方法是利用多种途径提取出内容的特征信息, 通过匹配两个文本的内容特征, 来判断文本相似性。其中, Shingle算法是一种比较知名的基于相似性的内容去重方法[ 4]。该方法将文本视为词项序列, 将固定长度的相邻词项视为一个Shingle, 从而将文本转化为Shingle集合加以表示, 并通过对比两个文本的Shingle集合匹配程度来识别两者是否在内容上相似。在Shingle算法中, 每一个Shingle实质上是文本的一个特征码, 因此该算法也是一种基于特征码的方法。特征码的提取在具体应用中有多种方法:文献[5]面向短文本提取短文本中的特征码, 并利用关联规则方法判别文本之间的相似性;文献[6]通过将文本进行简单自然分句, 利用分句首尾字符生成文本的特征字符串作为文本的特征码;文献[7]在元搜索引擎的网页去重任务中, 根据用户查询词所在分句生成摘要特征码。另外, 文献[8]利用B-Tree数据结构进行索引, 极大地提升了处理速度, 从而使特征码方法适用于大数据量的文本内容去重场景。
然而, 基于特征码的方法并未考虑语义因素, 只单纯从字符串匹配的角度进行内容识别, 部分研究也尝试在一定程度上理解文本的语义内容, 得到文本的语义表示。文献[9]和文献[10]将文本表示为词向量, 通过余弦相似度计算文本间相似度, 从而将文本内容的相似性上升到语义层次的相似性, 但该方法在相似性阈值设置以及大数据量的处理方面存在缺陷。
内容相似的文本在结构上也可能具有一定的相似性, 例如互联网上近似镜像的网页在内容和结构上有可能高度一致[ 11]。因此, 结构识别也能为相似内容的发现提供一定的依据。文献[11]利用重复网页的结构特点, 利用正文结构树的形式来表达网页正文内容, 并结合指纹计算方法, 实现网页去重。
2.2 基于摘要技术的方法
基于摘要技术的方法是利用摘要算法计算文本的摘要值, 即将文本表示为一个较小的数值或者较短的字符串, 以判断两个文本是否相同。基于摘要技术的方法可以单独使用, 即直接将文本的摘要值进行匹配, 也可以与基于内容相似度的方法结合使用, 在内容特征提取基础上, 进一步计算摘要值。目前该类方法主要有MD5、DSA等摘要算法。若直接用文本摘要值进行匹配, 往往只能判断内容是否完全相同。因为只有完全相同的文本才能产生完全相同的摘要值, 即使原始文本差别很小, 所得到的摘要值也可能差别非常大, 即从文本生成摘要的过程往往是不可逆的。针对文本内容去重任务, 需要一种能够识别出文本近似相同 (只做过少量修改) 的摘要算法, 该类算法在进行摘要计算前, 往往需要对文本内容特征进行一定的预处理。
文献[12]提出一种新的哈希算法, 在文本N-gram基础之上利用常用汉字编码表进行特征映射, 将文本映射为哈希值序列, 通过比较文本的哈希值序列来实现文本内容的重复性检测。文献[13]提出一种I-Match方法, 通过统计语料库词典与从文档中抽取词项的交集, 为每个文档产生一个摘要值, 从而保证每一个文档被映射到单个聚类上, 以聚类来表示相似的文档集。文献[14]在该方法的基础上, 提出采用多个语料库词典, 分别为每篇文章生成多个摘要值, 从而改变摘要值过分依赖于词典的现象, 提升了识别算法的性能。
可以看出, 以上算法都是先提取出文本的内容特征, 再利用摘要技术进行处理, 将变化较小的文本识别为相同文本。然而, 尽管如此, 这些方法也无法通过比较摘要值的差异来判断原始文本的差别程度。目前, Simhash算法是一种实现该目标的较好算法[ 15]。Simhash算法能够在将文本内容特征转化为摘要值的同时, 根据摘要值的差别大小, 判断原始文本内容的差别程度。
3 整合语义指纹和Single-Pass的文本
去重流程
Simhash算法由Charikar[ 15]于2002年提出, 目前被认为是文本内容近似去重最有效的方法[ 16]。Simhash实质上是一种语义指纹技术, 它能将文本内容的语义特征映射到相应的比特 (Bit) 上, 并以这些比特所组成的数值来表示文本内容的指纹 (Fingerprint) 。一般而言, 该指纹的比特位数相对较小, 例如32或64, 故也可将Simhash算法理解为一种降维技术。区别于其他指纹技术, Simhash算法能用于识别相似内容, 而不是像简单的摘要算法那样只能判断内容是否完全一致。相似的文本内容通过该算法生成的指纹值也只在少量的比特位 (Bit Position) 上不同, 因此可以根据语义指纹值的比特位差异来判断文本间的相似程度。
常用的内容去重方法是利用文本聚类技术将相似或相同文本聚集在一起, 从而达到文本去重的目的。本文在Simhash算法的基础上, 整合Single-Pass快速聚类算法实现面向中文文本的文本内容去重, 整体流程如图1所示:
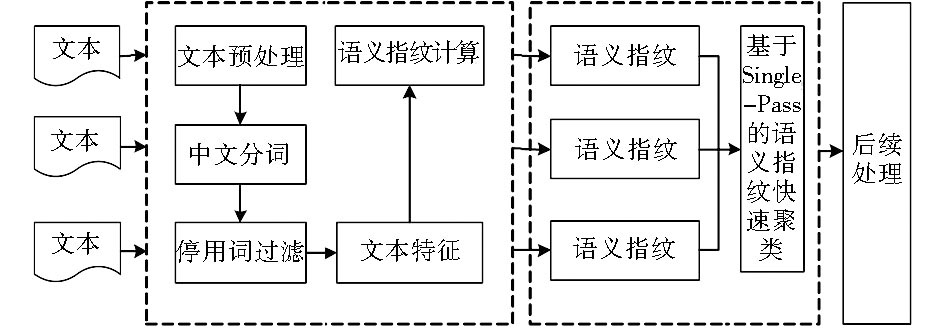 | 图1 基于语义指纹快速聚类的中文文本去重流程 |
该方法主要分为两大环节:文本的语义指纹值计算;利用Single-Pass聚类算法对语义指纹值进行聚类。
在文本的语义指纹值计算过程中, 根据Simhash算法, 需要先提取文本内容的语义特征, 常规的方法是对中文文本进行分词处理, 利用语词代表文本的语义特征, 然后再根据语义特征利用Simhash算法计算出文本的语义指纹值。该过程可以独立计算, 针对固定文本集, 一次性批量地计算所有文本的语义指纹值, 而针对流式的、动态的文本集, 则可以在文本加入时计算语义指纹值, 以备后续使用。在语义指纹聚类过程中, 根据语义指纹的数值特征应用Single-Pass聚类方法, 以实现对语义指纹的快速聚类, 单个聚类类别代表去重后的一个文本。在后续处理中, 只保留聚类中心, 去除单个聚类类别中其他文本。
3.1 文本特征提取
文本特征提取是从原始文本中抽取出能表征文本语义内容的词项作为文本特征, 将文本表示为词项集合, 并以词频作为特征的权重。文本特征提取过程主要包括如下三个环节:
(1) 中文文本预处理。中文文本语义指纹生成流程中的第一步是对中文文本进行预处理, 得到文本内容字符串。中文文本数据源的常见格式有HTML网页、XML文件、Word文件、Excel文件等各种结构化或半结构化数据, 需要从这些文件中解析出文本内容字符串, 以便后续处理。
(2) 文本分词。在英文文本中, 文本特征往往指从单个单词经过处理后得到的词项, 而针对中文文本, 需要借助文本分词工具得到文本的语词, 作为文本特征项。
(3) 停用词过滤。在中文文本中往往存在一些对语义贡献较小或者出现频率过高的词, 例如“的”、“是”等, 称作“停用词”。因此, 在得到最终特征项前, 需要先将这些停用词去掉, 以减少这些词项对文本内容特征的干扰。
通过以上步骤, 经过文本分词和停用词过滤后所得的词项即为文本的最终特征, 并交由Simhash算法处理, 以生成语义指纹。
3.2 语义指纹生成
将文本特征作为Simhash算法的输入, 通过Simhash算法计算得到文本的语义指纹值, 详细算法过程描述如下[ 15]:
输入:n 维特征向量v={w1, w2, …, wn}, 其中w1, w2, …, wn分别是文本内容特征v1, v2, …, vn 的权重;
输出:一个b位的指纹f={f1, f2, …, fb}, 其中f1, f2, …, fb取值为0或1。
计算过程:
①维持一个b维向量fc, 每一维度值初始化为0;
②通过运用某种普通字符串哈希函数, 将文本的特征vi映射为一个具有b个比特的数值hi;
③根据hi, 应用如下规则更新fc:如果hi的第j位是1, 那么将fc的第j维值加上该特征vi的权值wi;如果hi的第j位是0, 那么将fc的第j维值减去该特征vi的权值wi;
④针对所有的特征, 重复步骤②和③;
⑤根据fc得到最终的指纹f:如果fc中的第i维向量值为正, 则f中第i位的比特值为1, 否则为0。
常用的普通字符串哈希函数有RS、JS、PJW、EFL、SDBM等[ 17], 本文采用SDBM函数作为普通字符串哈希函数, 其来源于SDBM开源软件项目[ 18], 并已在多个数据集中广泛应用。通过以上算法, 将一个具有n维特征的文本内容表示为一个b位的语义指纹值, 可转化为一个数值加以表示。由于一般情况下n远大于b, 同时语义指纹中直接采取比特位进行计算, 语义指纹所使用的计算空间远小于对n维特征直接存储所使用的空间。本文沿袭文献[16]的做法, 将b设置为64。
3.3 基于Single-Pass的语义指纹快速聚类
Single-Pass算法是一种面向流式数据的经典增量式聚类算法, 也称作单通道法或单遍法[ 19]。该算法的基本思路是对于流式数据, 一次取出一个文本, 进行增量式动态聚类, 将文本与已有的聚类类别进行相似度匹配。如果与某一类别的相似度大于某阈值, 则将该文本归入这一聚类类别;如果与所有类别的相似度都小于某个阈值, 则新建一个聚类类别。Single-Pass聚类算法的优势在于算法复杂度低, 只需要一次扫描数据集即可完成聚类过程。
结合文本语义指纹的数值特点, 利用Single-Pass实现聚类过程, 详细算法描述如下[ 20]:
输入:中文文本流p1, p2, …, pn;内容相似一致性判断阈值HD;
输出:网页去重后文本集DistSet= (ds1, ds2, …, dsi) , 及对应的相似内容文本集SimSet (S) ;
数据结构:网页去重后文本集DistSet按语义指纹值升序排列。
算法执行过程:
①接收一篇文本di, 利用Simhash算法计算该文本的语义指纹值fi;
②将该文本的Simhash值与已有聚类的聚类中心文本的语义指纹值进行对比, 比较两者比特值的海明距离 (Hamming Distance) h, 找到与fi 海明距离最小的聚类中心dsj (其语义指纹值为fdsj) ;
③判断海明距离最小者hmin是否小于给定阈值HD;
④如果hmin≤HD, 则认为该文本与该聚类类别内容相似, 将该文本加入到该类别相似内容文本集SimSet (dsj) 中;
⑤如果hmin>HD, 则认为在已有的类别中未找到与该文本相似的类别, 新建一个聚类类别dsnew, 并以该文本作为聚类中心, 更新DistSet。更新方法为:如果fi<fdsj, 则将dsnew放置在dsj前, 否则放置在其后;
⑥本次聚类结束, 等待新的文本到来。
其中, 海明距离是指两个二进制数的对应比特位不同的比特位数, 例如二进制数10101和00110从左往右第1位、第4位和第5位不同, 则两个二进制数的海明距离为3。同时, 在上面计算过程中, 将阈值HD取值设为3。这里沿用文献[16]的取值, 即如果两个文本语义指纹值的海明距离小于等于3, 则认为两者内容相似。
4 实验分析
4.1 实验数据及过程
实验数据来自于笔者所在实验室构建的基于互联网的企业竞争情报系统平台, 从博客、新闻、论坛等多个相关网站中采集关于“手机”领域的网页, 经过网页解析提取出网页正文内容, 并经过文本预处理, 去除采集出错和解析出错的网页, 得到最终语料, 其中新闻7 951条、博客53 865条、论坛9 949条。在实验过程中, 将本文方法 (标示为“Simhash方法”) 与Shingle算法[ 4]进行对比分析。在评价近似文本时, 分别将Simhash方法中海明距离小于3以及Shingle算法中Jaccard相似度值大于0.95的文本对认为是相似文本对。
文本处理过程中, 采用IK Analyzer 2012中文分词工具, 该工具具有160万字/秒的高速处理能力, 同时支持用户词典扩展和英文字母、数字、中文词汇等的分词处理[ 21], 并在搜狗输入法词库基础上扩展形成用户词典, 共392 755个词。
实验软硬件环境是CPU为Intel (R) i5 3210 2.50GHz, 内存8GB, 操作系统为Windows7 64bit, 采用Java语言实现算法, 并在Eclipse3.3上运行。
4.2 实验结果分析
(1) 算法运行情况分析
首先考察算法在整个流程中的时间和空间复杂度, 以判断算法的适用情况。从整体流程上看, Simhash方法可以分为两个主要步骤:文本集的语义指纹计算和语义指纹快速聚类过程。文本的语义指纹计算只需运行一次, 最终语料进行语义指纹计算共用时1 614 712ms, 平均每条数据用时22.5ms。本文所提方法与Shingle算法对数据集的计算结果及运行用时情况如表1所示:
| 表1 Simhash方法与Shingle算法的运行情况 |
从运行情况来看, 在新闻、博客、论坛三种信息类型数据上, Shingle算法用时都长于Simhash方法, 因此Simhash方法在处理速度上具有优势。
在算法运行时对于存储的要求方面, 由于单个语义指纹长度为8字节 (64bit) , 总共数据存储只需16n字节。由此, 仅需要4GB内存即可满足2.5亿数据的存储要求。因而Simhash方法能够支持大数据量的文本内容去重。
(2) 精确度分析
为进一步评价本文方法的精确度, 从数据集中选取1 000个文本, 分别增加或者删减文本内容的约5%, 并使其基本语义保持不变, 即为每个文本构建了两个相似文本, 并分别运用Simhash方法和Shingle算法计算。这里, 精确度指标定义为相似文本对的数量占总文本对数量的比例。Simhash方法与Shingle算法的精确度对比如表2所示:
| 表2 Simhash方法与Shingle算法的精确度对比 |
从表2发现, 无论内容增加还是内容删减情况, Simhash方法的精确度都高于Shingle算法, 同时内容增加比内容删减的精确度值更高。
(3) 鲁棒性分析
本文中鲁棒性是指文本内容的改变程度对算法将变化前后文本识别为相似文本的影响, 若文本的小幅度改变仍然能被算法识别为相似性文本, 则算法的鲁棒性较高。在现实环境下, 相似文本主要有如下几种情况[ 22]:文本段落的重新组织, 文本内容几乎没有变, 只是语句或段落的重新排序;文本内容的少量增加和删除;文本内容的少量改写, 而核心段落仍然存在。
因此, 需要考察不同的内容改变程度下, 算法仍将改变前后的文本识别为相似文本的比例, 设计如下实验:
①内容的增加与删除。在原文本的随机位置分别增加或者删除1%-20%的文本, 考察将更改前后的文本识别为相似文本的比例, 即相似性识别率;
②内容的重排序。对原文本随机截取文本内容中的句子, 再重新插入到文本的随机位置中, 考察将更改前后的文本识别为相似文本的比例。
从实验语料中选取1 000个文本作为测试文本, 同时选择50个文本进行分句等处理后作为内容增加语料。文本内容增加或删减后的相似性识别率如图2所示:
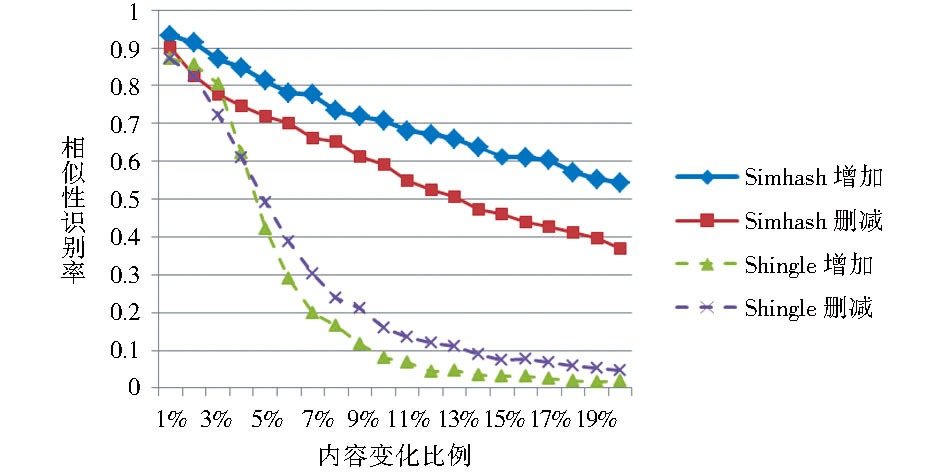 | 图2 内容删减与增加下算法结果 |
从图2中可以看出, 内容删减或者增加越多, 算法识别为相似文本的比例就越低, 即文本内容更改增大时, 算法将慢慢认为改变前后的文本不具有相似性。同时, 从曲线的位置来看, 增加曲线在删除曲线之上, 说明算法对于内容的增加更能识别为相似文本。从数值上来看, 当文本内容更改在5%以内时, 无论是内容删减还是内容增加, Simhash方法都能达到70%以上的识别率。
对比Shingle算法发现, 随着内容变化比例增大, Shingle算法的相似性识别率下降幅度越过Simhash方法的下降幅度。相较于Shingle算法, Simhash方法在文本内容变化幅度上具有更高的容忍度, 因此Simhash方法的鲁棒性更强。
针对内容重排序实验, 将1 000个测试文本分句后, 进行随机次数的语句重排, 比较前后文本的内容相似性。实验结果表明, Simhash方法和Shingle算法分别有86.1%和6.1%的文本被识别为相似文本。由此发现, 在内容重排序情景中, 相较于Shingle算法, Simhash方法的相似性识别率具有极大的提升。其次, 由于本文语料来源于互联网, 网络语料本身存在大量噪音, 同时中文文本分词较为复杂, 所提取出的文本特征发生改变, 从而导致Simhash方法未能完全识别内容重排, 本文方法在该方面有待进一步提升。
5 结 语
针对中文文本的特征, 在Simhash算法的基础上改进得到中文文本语义指纹生成方法, 并结合Single-Pass快速聚类算法对语义指纹进行快速聚类, 从而实现了面向中文文本的快速去重流程。同时, 实验过程中, 在算法运行情况、精确度、鲁棒性等方面将该方法与Shingle算法进行对比分析, 证明本方法的优越性。通过实验分析发现, 本文方法运行速度上的优势能够支持大数据量情况下的文本去重任务。本文方法还有待进一步改进, 笔者将在后续的研究中进一步探索在分布式环境中计算文本语义指纹值。此外, 网页等文本存在大量噪音, 需要进一步研究中文文本特征提取方法, 以优化语义指纹计算。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|