{kind=link}
基于有效词频的改进C-value自动术语抽取方法
引用本文
熊李艳, 谭龙, 钟茂生. 基于有效词频的改进C-value自动术语抽取方法. 现代图书情报技术, 2013, 29(9): 54-59
Xiong Liyan, Tan Long, Zhong Maosheng. An Automatic Term Extraction System of Improved C-value Based on Effective Word Frequency. New Technology of Library and Information Service, 2013, 29(9): 54-59
Permissions
Xiong Liyan, Tan Long, Zhong Maosheng. An Automatic Term Extraction System of Improved C-value Based on Effective Word Frequency. New Technology of Library and Information Service, 2013, 29(9): 54-59
基于有效词频的改进C-value自动术语抽取方法
摘要
现有的中文术语自动抽取方法主要针对术语的高频特征与单元性指标, 而低频术语和术语的术语性指标缺乏有效的处理方法。针对上述问题, 将背景语料库引入C-value方法, 提出词语领域分布度与有效词频的概念, 通过计算候选术语的EC-value值来自动抽取术语, 并结合术语簇识别与挖掘, 改善低频术语抽取性能。通过计算机领域术语抽取实验, 表明本文提出的改进方法 (EC-value方法) 能更有效地衡量术语的术语性, 改善低频术语抽取性能。
关键词:
自动术语抽取; EC-value; 有效词频; 术语簇
An Automatic Term Extraction System of Improved C-value Based on Effective Word Frequency
Abstract
Existing Chinese term automatic extraction methods focus on the high-frequency characteristics and unithood indicators of terms, while low frequency terms and termhood indicators lack of effective treatment methods. In response to these problems, this paper introduces the background corpus into C-value method and proposes the concepts of word field distribution degree and effective word frequency. Then the paper automatically extracts the terms by calculating EC-value (Effective C-value) of candidate terms, and improves the extraction performance of low-frequency terms combined with the term cluster recognition and mining. The term extraction experiment in the computer field shows that the proposed improved method (EC-value method) can measure the termhood of terms more effectively, and improve the extraction performance of low-frequency terms.
Keyword:
Automatic term extraction; EC-value; Effective word frequency; Term cluster
1 引 言
术语是指语言中描述专业领域知识系统的词汇单位, 它蕴含丰富的专业领域知识, 是专业领域知识系统的重要组成部分[ 1]。在中文信息处理领域, 自动术语抽取 (Automatic Term Extraction) 是一项基础而重要的课题, 在信息抽取、机器翻译、问答系统和自动文摘等许多方面发挥着重要作用[ 2]。然而, 现有的自动术语抽取方法在测度术语的术语性 (Termhood) 和处理低频术语方面, 缺乏有效策略[ 2]。因此, 本文提出改进的C-value方法——Effective C-value (EC-value) 方法, 以更好地测度术语的术语性, 并改善低频术语抽取性能。
2 研究背景
2.1 研究现状
单元性 (Unithood) 和术语性 (Termhood) 是术语的两个基本特征。单元性指一个词语组合成为稳定结构的可能性;术语性指一个词语组合的专业领域性[ 3]。针对术语的基本特征, 现有的自动术语抽取方法一般分为以下4类:
(1) 基于语言学规则的方法。该方法认为术语应满足一定的语法结构, 并通过构建语言学规则来抽取术语[ 2]。但语言学规则难于发现, 费时费力, 且会导致总召回率偏低、系统可移植性差等问题。
(2) 基于统计的方法。此方法以统计学理论为基础, 利用术语在语料库中的分布统计属性来识别术语。常用的统计方法有互信息、信息熵、假设检验等[ 2]。这种方法可适性良好, 对语种、专业领域无过多限制, 但对多词术语和低频术语的识别并不理想, 存在许多噪声。
(3) 基于机器学习的方法。该方法是基于统计方法的一种, 与传统统计方法相比有其独特的优势。如胡健坤[ 4]利用隐马尔可夫模型进行中文术语抽取, 获得较高的准确率和召回率。然而, 此方法对训练语料要求很高, 语料训练需花费大量时间, 且基于某领域语料训练出的模型可移植性差[ 5]。
(4) 混合的方法。实际的术语抽取往往将以上方法有选择地结合起来, 兼顾各方法的特点, 以达到互补的目的。如Frantzi等[ 6]提出C-value方法, 结合语言学知识与统计信息, 在英文领域取得较好效果。国内周浪等[ 7]运用统计和语言学方面的多种策略, 对术语进行过滤, 精确度与召回率有较大提高。
然而, 现有的自动术语抽取方法主要针对术语的高频特征和单元性, 对低频术语和术语的术语性指标缺乏有效的处理方法[ 2]。以C-value方法为例, 其在衡量术语的术语性方面存在缺陷[ 8], 且缺乏低频术语处理策略。
2.2 C-value方法简介
C-value方法是一种结合语言学规则和统计学理论的混合术语抽取方法, 以词语C-value值的高低来识别术语[ 6]。其基本思想是:先以语言学规则筛取候选术语;候选术语的C-value值与其在领域语料中的词频成正比, 与其长度成正比; 候选术语如果被嵌套, 其权重会相应降低。
C-value值计算公式如下所示[ 5]:
C-value (a) =log2|a|×f (a) a未被嵌套
log2|a|× (f (a) -1c (a) ∑c (a) i=1f (bi) ) 其他 (1)
其中, a表示某候选术语, |a|指候选术语a的长度, 其值为a的字数, f (a) 为a的词频, bi表示嵌套a的候选术语, c (a) 则为嵌套a的候选术语的数量。
C-value方法简单、适用性强, 具有语言和领域无关性[ 9, 10]。此外, C-value方法考虑候选术语的长度和嵌套性, 在长术语与嵌套术语抽取方面极具优势[ 11]。
3 基于有效词频的改进C-value自动术语抽取
3.1 术语抽取框架
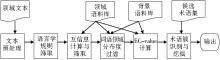
本文提出一种统计与语言学规则结合的方法进行术语抽取, 并将之命名为Effective C-value (EC-value) 方法。在已有研究基础上, 本文提出词语领域分布度、有效词频和术语簇识别与挖掘三个概念, 来改进C-value方法, 以更好地测度术语的术语性, 改善低频术语抽取性能。主要步骤是:
(1) 文本预处理;
(2) 参考前人研究成果, 以语言学规则与互信息方法筛取候选术语;
(3) 提出词语领域分布度和有效词频概念, 计算候选术语EC-value值, 抽取候选术语;
(4) 建立术语簇识别与挖掘规则, 反馈修正术语抽取结果。
术语抽取框架如图1所示:
 | 图1 EC-value术语抽取框架 |
3.2 具体抽取步骤
(1) 文本预处理
首先对领域语料与背景语料进行分词和词性标注, 并进行停用词处理, 去除一些出现频率高但无意义的词。
(2) 基于语言学规则的候选术语筛取
此处语言学规则主要指术语的构词规则。国内一些学者对中文术语构词规则进行了研究。例如, 李嵩[ 12]提出现代汉语中可以充当术语组成成分的词类有名词、动词、形容词、区别词、方位词等。根据前人的研究成果, 本文确定了以下构词规则[ 12, 13], 如表1所示:
| 表1 术语构词规则 |
(说明:n表示名词, v表示动词, a表示形容词, d表示副词, l表示习语, m表示数词, dvn表示副词+动词+名词的组合。)
(3) 互信息计算与筛取
C-value方法没有考虑候选术语的单元性, 因此国内研究者常常将C-value方法与测度单元性的方法结合, 进行中文术语抽取。如梁颖红等[ 14]将互信息与C-value方法结合, 实验表明效果好于单独使用互信息或C-value方法。本文也采用互信息方法[ 15]计算候选术语的单元性, 筛取候选术语。基本思想是:对单词候选术语, 不计算互信息值;对2-6词候选术语, 计算其互信息值, 并为2-6词候选术语各设定一个阈值, 将互信息值小于阈值的词组从候选术语集中删除。
由于互信息方法只计算两者之间的依赖程度, 因此对于3-6词候选术语, 则将词串分解为多个二元组, 取其中最大的互信息值作为整个词串的互信息值。例如一个4词候选术语ABCD, 可以分解为A-BCD, AB-CD, ABC-D三个二元组, 则ABCD的互信息值计算如下[ 14]
MIABCD=MaxMIA, BCD, MIAB, CD, MIABC, D (2)
其中, MI (ABCD) 表示4词词组ABCD互信息值, MI (A, BCD) 指词A与词组BCD的互信息值, Max表示取最大值。
(4) EC-value方法
传统C-value方法以词语的词频为基础, 无法有效区分高频术语和高频常用词[ 8], 且缺乏低频术语处理策略。以本文建立的计算机领域语料库为例, 术语“服务器”在1 000篇文档中出现1 710次, 而常用语“方法”则出现7 320次, 其C-value值远大于“服务器”。另外大量多词术语出现次数很少, 如“Web计算”仅出现12次, 其C-value值远小于一些高频常用语。出现这种问题的原因, 笔者认为是缺乏大规模背景语料库的支持。从术语特点看, 领域术语在某领域文本中大量出现或只在该领域中出现, 而在其他领域很少出现甚至不出现[ 2]。因此像“Web计算”这样的专业术语, 在其他领域中可能不会出现;而像“方法”这样的常用语在其他领域中可能出现很多次。以其他各个领域8 000篇文档构成背景语料库, 统计词频, 发现“方法”在背景语料库中出现23 000多次, “Web计算”在背景语料库中没有出现, 这证实了本文的假设。因此, 本文对C-value方法进行改进, 引入背景语料库, 提出词语领域分布度与有效词频概念, 计算候选术语EC-value值, 抽取候选术语, 并通过术语簇识别与挖掘, 反馈修正术语抽取结果。
①词语领域分布度
本文以词语领域分布度进一步筛取候选术语。词语领域分布度, 指某候选术语在领域语料库中的词频占其总词频的百分比, 公式如下:
p (a) =f (a) f (a) +g (a) ×100% (3)
其中, a表示某候选术语, f (a) 表示a在领域语料库中的词频, g (a) 表示a在背景语料库中的词频, p (a) 为a的领域分布度。由于背景语料库远大于领域语料库, 且许多领域通用术语也常常被背景语料库的文档所引用, 因此, 为了提高召回率, 本文将阈值设为30%, 只保留词语领域分布度大于30%的候选术语。实验表明, 这可以过滤掉大量噪声数据。
②基于有效词频的EC-value计算
有效词频的提出基于以下考虑:假设词A在领域语料库中出现300次, 在背景语料库中出现100次, 组成词频对 (300, 100) , 词B的词频对为 (100, 10) , 词C的词频对为 (50, 0) , 则哪个词更可能是术语?从术语性分析, 词C更可能是术语, 词B次之, 词A的可能性最低。但传统的C-value方法会赋予词A更高的权重, 这是因为C-value方法只考虑词语在领域语料库中的词频。因此, 本文提出有效词频的概念, 即综合考虑词语在领域语料库和背景语料库中的词频。计算时, 使其与词语在领域语料库的词频成正比, 与词语在背景语料库的词频成反比。计算公式如下:
F (a) =f (a) g (a) +0.5×lgf (a) a未被嵌套
f (a) -1c (a) ∑c (a) i=1f (bi) g (a) +0.5×lgf (a) a被嵌套 (4)
其中, a是某候选术语, F (a) 表示a的有效词频, f (a) 表示a在领域语料库中词频, bi表示抽取的嵌套a的候选术语, c (a) 表示嵌套a的候选术语数量, g (a) 表示a在背景语料库中的词频。分母中的“0.5”既是为了防止出现分母为零的情况 (即词a没出现在背景语料库中) , 也是增加没有出现在背景语料库的词语的权重。lgf (a) 是高频加权系数, 表示在同等比值下, 领域语料库中出现次数更多的候选术语加权更高。
以有效词频取代词频参数后, 候选术语的C-value值变为EC-value值, 其计算公式如下:
EC-value (a) =log2 (|a|×F (a) ) (5)
其中, a是某候选术语, |a|为a的长度, F (a) 为a的有效词频, 同公式 (4) 。
结合有效词频, 本方法降低了领域性较弱的高频候选术语的权重, 提高了领域性较强的中低频候选术语的权重, 不但能更好地测度术语性, 而且能改善低频术语抽取性能。
③术语簇识别与挖掘
在人工标注领域语料库部分术语时, 发现术语领域存在术语簇现象。术语簇是指具有相同特征公共字串、表示相同或相似概念的一组术语。例如表2所示的“IP”术语簇。
| 表2 术语簇例子 |
在上述“IP”术语簇中, “IP”是特征公共字串, 且各词在领域语料库和背景语料库中的词频各不相同。“IP地址”是高频词, 词频对为 (121, 1) , EC-value值很高;而“源IP地址”是低频词, 词频对为 (3, 1) , EC-value值很低。因此, 可以通过对候选术语中术语簇的识别, 提取有效的特征公共字串, 挖掘具有该特征公共字串的低频术语。具体识别与挖掘步骤如下:
1) 采用EC-value算法计算候选术语的EC-value值, 并按其值大小排序;
2) 设定一个阈值, 将EC-value值大于阈值的候选术语作为真术语加入术语集A中, 剩下的候选术语成为集B, 设立一个挖掘术语集C, 初始为空;
3) 对于集A和集C中的任一词a, 若集B中有词语嵌套词a, 则将该词加入挖掘术语集C中, 重复这个过程直至没有新术语加入集C;
4) 在集A和集C中寻找特征公共字串, 具体寻找规则如下:公共字串的字长为2-11个字;集A与集C中, 只要有3个术语包含同一个字串, 则将该字串加入候选公共字串集D中, 并建立公共字串到术语的对应;对集D中的字串进行最多归并与最长归并, 最多归并指字串S1对应的术语包含字串S2对应的术语, 则S2归并到S1;最长归并指字串S1包含字串S2, 若两者对应的术语相同, 则S2归并到S1;归并结束后, 集D的每一个公共字串对应一个术语簇;
5) 对集D的每一公共字串, 计算其词语领域分布度。若字串S1的词语领域分布度大于等于70%, 则将集B中包含字串S1的候选术语加入集C;若字串S1的词语领域分布度小于70%, 则只将集B中词语领域分布度大于等于70%的包含字串S1的候选术语加入集C;
6) 重复4) 、5) 两个步骤, 直到没有新的术语加入集C为止。此时集C便是最终的挖掘术语集合。
通过术语簇识别与挖掘, 可进一步改善低频术语抽取性能, 提高术语抽取的精确度和召回率。
4 实验结果与分析
4.1 领域语料库与背景语料库
从复旦分类语料库计算机领域中挑选1 000篇文档组成领域语料库, 从其他领域挑选8 000篇文档组成背景语料库。
4.2 术语抽取效果评价方法
评价术语抽取效果一般采用精确度和召回率两个指标。然而在一个没有经过人工标注的语料库中, 很难确定其包含的全部术语数。因此, 采用一种替代方法, 精确度用系统正确标记的术语数占系统找到的术语数的百分比表示, 而召回率用系统正确标记的术语数占人工标记术语数的百分比表示[ 7]。为此, 从领域语料库中随机抽取50篇文档, 人工标记全部383条术语。为综合评价术语抽取算法效果, 可采用F-score评价指标, 计算公式如下[ 3]:
F-score=2×精确度×召回率精确度+召回率 (6)
4.3 实验结果与分析
按前述术语抽取流程, 对领域语料库1 000篇文档进行文本预处理、语言学规则和互信息过滤、词语领域分布度过滤, 得到18 213个候选术语。采用基于有效词频的EC-value计算公式对其进行计算, 并按EC-value值的大小进行排序。对前500、前1 000、前2 000和前4 000候选术语进行精确度与召回率的计算, 并分别进行术语簇识别与挖掘, 结果如表3所示:
| 表3 术语抽取效果 |
从表3中可以看出, 随着术语集A的增大, 通过术语簇识别可挖掘出更多的术语, 数量占术语集A数量的0.5%-1.5%。随着术语抽取数量增多, 抽取精确度逐渐下降, 召回率迅速上升。同时, 将EC-value方法和C-value、互信息、C-value与互信息结合三种方法比较, 结果如表4所示:
| 表4 与C-value、互信息、C-value与互信息结合方法的比较 (前2 000候选术语) |
从表4可以看出, 相比C-value方法、互信息方法以及C-value与互信息结合的方法, EC-value方法在精确度和召回率上都有提高, 这表明了EC-value方法的有效性。
另外, 为验证EC-value方法的领域普适性, 从复旦分类语料库环境领域选取1 000篇文档作为领域语料库, 从其他领域选取8 000篇文档作为背景语料库, 采用EC-value方法进行术语抽取, 将实验结果与计算机领域实验结果对比, 如表5所示:
| 表5 环境领域与计算机领域实验结果对比(前2 000候选术语) |
从表5可以看出, EC-value方法在环境领域取得了与计算机领域同等的效果, 这表明本文方法可适用于其他领域。
另外, 对前2 000候选术语进行术语簇识别与挖掘, 可识别部分术语簇, 挖掘低频术语。术语簇识别与挖掘的部分实例如表6所示:
| 表6 术语簇识别与挖掘的部分实例 |
通过实验结果分析, 本文方法相比传统方法有了明显改进。相比基于机器学习的方法, 本文方法无需高质量的训练语料, 不用花费大量时间进行语料训练, 且适用于各个专业领域。当然, 本文方法依然存在一些不足:
(1) 虽然词语领域分布度和有效词频的概念过滤并降低了高频常用词的权重, 但是与计算机相关的领域的中低频术语的权重在提高, 例如数学领域的一些术语如公理、定理、正态分布等。
(2) 对组合型术语抽取效果较好, 对领域通用术语抽取效果差。主要原因在于, 组合型术语很少甚至不会在背景语料库中出现, 有效词频较高, 如“Web计算”的词频对为 (12, 0) ;而一些领域通用术语如“计算机”, 在领域外也常常被引用, 词语领域分布度不高, 与许多噪音数据混在一起。
(3) 对字长较长的术语抽取效果较好, 对字长较短的术语抽取效果较差, 这与EC-value计算公式中词语长度参数有关。表7是在抽取前2 000个候选术语情况下, 对人工标注的383条术语的抽取情况。可以看出, 4字及以上的术语抽取比率大于平均召回率44.91%, 说明本文方法对字长较长的术语更加敏感。
| 表7 人工标注的383条术语抽取情况 |
(4) 术语簇识别与挖掘缺乏完善的规则。本文术语簇识别规则较简单, 一些单字术语簇不能识别, 如 “局域网、广域网、Internet网、以太网、令牌环网”, 识别的术语簇也存在一些错误。此外, 术语挖掘规则较严格, 影响了术语挖掘的数量。
5 结 语
中文自动术语抽取是中文自然语言处理的一个重要问题。本文在传统C-value方法基础上, 提出词语领域分布度和有效词频的概念, 并结合术语簇识别与挖掘, 使之更好地测度术语的术语性, 改善低频术语抽取性能。实验表明, 本文方法取得了较好的抽取效果。
自动术语抽取的研究与实现是一个较为复杂的过程, 每种方法都存在一定的局限性, 本文方法也不例外, 还有很多工作可做, 比如术语簇识别与挖掘缺乏完善的规则。因此下一步研究工作重点在于构建比较完善的术语簇识别与挖掘规则。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|