
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融入社会关系的微博排名策略研究
引用本文
唐晓波, 房小可. 融入社会关系的微博排名策略研究. 现代图书情报技术, 2013, 29(9): 74-81
Tang Xiaobo, Fang Xiaoke. Research on Microblog Ranking Strategy with the Social Relations. New Technology of Library and Information Service, 2013, 29(9): 74-81
Permissions
Tang Xiaobo, Fang Xiaoke. Research on Microblog Ranking Strategy with the Social Relations. New Technology of Library and Information Service, 2013, 29(9): 74-81
融入社会关系的微博排名策略研究
摘要
社会化媒体的出现, 使得搜索环境发生重大变化。针对当前微博搜索排名的不足, 在分析微博社会关系的基础上, 综合可测量的参数指标, 提出融入社会关系的微博排名策略, 即在传统的PageRank排名算法中增加社会强度, 综合考虑用户知名度、信息知名度、信息质量、时间因素等其他参数指标。实验结果显示, 取各参数指标的平均值 (AVG) 能获得排名精度最高的效果, 优于微博传统排名算法并且能获得更多社会关系。
关键词:
社会关系; 微博; PageRank; 排名
Research on Microblog Ranking Strategy with the Social Relations
Abstract
The emergence of social media makes the environment of retrieving changed. Since the shortcomings of retrieving ranking in microblog, this paper analyzes the microblogging social network relationship, and proposes microblogging ranking strategy with the social relations. That means, social strength is added to the traditional PageRank ranking algorithm, and some related indicators including people popularity, information popularity, information quality, the time factor and some others are considered. The experimental results show that AVG has a higher accuracy, and it can obtain more social relationships compared with conventional ranking algorithm.
Keyword:
Social relations; Microblogging; PageRank; Ranking
1 引 言
微博是一种在网络上日益流行的交流形式。众所周知的微博平台如Twitter, 一份最近的关于Twitter的研究揭示了使用微博的集中用途:日常说话, 比如发布一些人正在干什么的消息; 对话交流等, 如将信息发给他们社区的一些关注者; 信息分享, 比如发布一些网页的链接; 新闻报道, 如对新闻和当前事态的评论等[ 1]。鉴于微博中存在着复杂的社会关系, 许多学者利用社会网络的链接关系来表示社会关系, 从而对事件进行分析或对信息进行处理。如2009年伊朗大选, 人们通过一些社交网络平台如Twitter、Facebook等来表示抗议, 这项大规模运动被称为“绿色运动”, 对此, Khonsari等[ 2]通过社会网络分析工具对这项社会化网络的绿色运动进行了结构特征分析, 研究表明, 用户的活跃度与网络的中心节点有着密切关系。再有Song等[ 3]利用Twitter上用户反馈的社会网络关系提出了微博垃圾信息过滤的方法, 有效过滤了垃圾信息。可见, 有效地利用微博中的社会关系对现实情况进行分析可以为研究带来便利。
自搜索引擎出现后, 互联网迅速成为人们获取信息的来源。若干年前, 这种搜索方式效果明显, 但近年来由
于社会化媒体的出现, 加之传统搜索引擎的搜索结果存在大量过时的信息[ 4], 有学者提出传统的搜索已经不能满足用户的需求, 故提出利用社会化媒体搜索来满足用户的信息需求[ 5]。排名的好坏直接影响检索质量的高低, 因此对排名策略的研究十分必要。以往关于微博排名策略的研究已经取得了一定进展, 但同时也存在一些不足:一方面考虑的指标因素比较单一, 只考虑链接因素或只考虑微博特征因素, 并未将这些因素综合起来进行探讨; 另一方面虽然利用了PageRank经典排名算法, 但忽略了微博用户之间交互频度表现出的社会关系。因此, 本文提炼了微博中的交互性社会关系, 并综合表示社会关系的其他参数指标, 对微博的信息进行排名, 以期能够获得令人满意的排名结果。实验通过可视化的方式完成对比分析, 验证了本文提出方法的可行性和优势。
2 相关研究综述
伴随着排名机制的发展, 目前主要有两种经典的排名模型:基于内容的排名和基于链接的排名[ 6]。基于内容的排名主要根据检索内容与询问词之间的匹配度, 更多依赖于向量空间模型 (VSM)[ 7]和语言模型 (LM)[ 8]; 基于链接的排名主要考察节点在网络中的位置, 从而判断其重要程度。在社会化媒体领域, 目前对排名策略研究较多的是使用后一种方法。文献[9]提出了基于用户链接的排名策略, 然而忽略了用户的权威性。对此, Yamaguchi等[ 10]提出TURank算法, 该算法在微博链接基础上考虑了用户权威性得分, 弥补了之前研究的不足, 但忽略了微博信息本身的特征参数。为了进一步提高排名质量, Gupta等[ 11]从可信度角度对微博进行排名, 他们利用微博信息本身的特征参数, 如粉丝数、用户名长度等, 通过机器学习方法提高微博排名质量, 相似研究还有Ravikumar等[ 12]和Vosecky等[ 13], 他们通过微博中隐含的链接关系来提取可信度高的微博。此外, 还有将微博的实时信息作为传统搜索引擎补充资源的研究, Chang等[ 14]通过Twitter上的信息来补充实时信息, 从而提升搜索质量, 其中微博的排名通过对URLs的发布和转发参数指标的计算得到, 然而他们是把权威性并非社会关系作为重点的排名算法。由此可见, 以上微博排名的指标因素比较单一, 只考虑链接因素或只考虑微博特征因素, 因此每种算法存在着相应的缺陷。
PageRank作为链接排名的典型算法, 也被应用在微博排名上, 文献[15]将PageRank的基本思想融入到微博用户搜索, 并引入一个状态转移矩阵和自动迭代的MapReduce工作流将计算结果并行化, 使具有“重要性”的用户在搜索结果中的排名获得了提升。国内外相似的研究如文献[16-18]等。其中文献[18]在考虑微博中高排名的用户观点可信度高于低排名的用户观点情况下, 提出用PageRank排名方法来提取权威人物有价值的观点。但是该算法的视角大多是在PageRank的基础上考虑算法的迭代时间效应, 或是将其应用在某些具体问题中, 并没有根据微博的显著社会性特征究其本质来提出排名策略, 即并没有考虑到微博中用户交互频度这个因素。此外, 微博排名算法更多的是基于Twitter平台, 对于以中文微博为研究平台的排名算法仍处于起步阶段, 这是本文研究的一个主要动机。
综上所述, 微博排名平台主要是基于Twitter的分析, 一方面, 并没有对微博平台的本质特征进行分析, 即对用户交互频繁程度的社会关系分析; 另一方面, 考虑的指标因素比较单一, 只考虑链接因素或只考虑微博特征因素, 并未将这些因素综合起来进行探讨。鉴于此, 本文借鉴文献[19]的思路进行探索性研究, 提出了融入社会关系的微博排名策略, 提炼微博中的交互性社会关系 (社会关系强度) , 以此对PageRank算法进行改进, 综合表示社会关系的其他参数指标, 最终实现微博信息的排名, 以期改进国内微博排名现状。
3 微博社会网络关系分析
与传统网络服务相比, 微博在网络结构和用户特征方面存在很多新的特点, 对微博的社会网络关系进行分析, 是提出微博排名算法的前提。博客、在线社交网络均为无标度网络的一种[ 20], 同时也表现出“小世界性”[ 21], 微博中的用户网络也表现出这些特征[ 22]。笔者将微博上的社会关系分为两种:关注关系和交互关系。
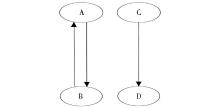
微博上用户的关注关系可以是单向关注关系, 也可以是相互关注关系, 因此更符合现实的社会情况。如用户A与用户B相互关注, 即他们是好友关系, 此时彼此都可以获得对方的即时消息; 用户C关注用户D, 也称C为D的粉丝, 此时用户D的消息会实时显示在用户C的页面上, 而C的消息D无从得知, 因此, 用户之间的关系是一个有向图。如果用节点V表示各用户, 用边E表示用户之间的关注, 则他们之间的关注关系G (V, E) 如图1所示:
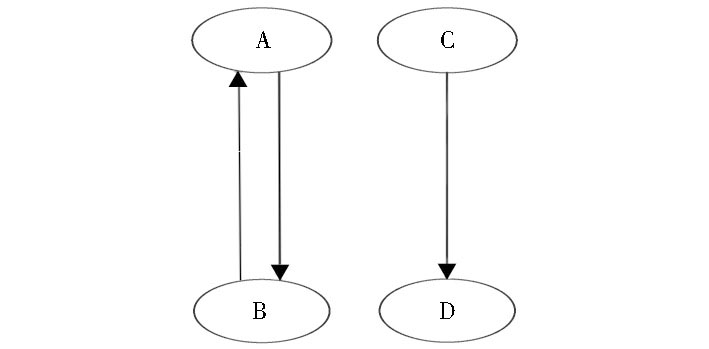 | 图1 用户关注关系 |
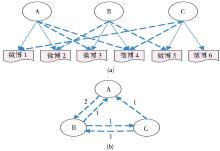
微博与现实生活的贴近体现为其中存在着复杂的社会关系, 其中交互关系体现得尤为明显。如用户A发布了消息, 会得到很多相互关注朋友的回复, 用户之间互动得越频繁, 说明他们之间的关系越密切, 彼此谈论的话题越相似。如图2 (a) 所示, 用户A发布了消息1、2, 用户B发布了消息3、4, 用户C发布了消息5、6, 其中用户A反馈了用户B的消息, 同理可解释用户B和用户C的反馈情况。如果用节点V表示各个用户, 用边E表示用户之间的消息反馈, 则他们之间的互动关系G (V, E) 如图2 (b) 所示, 用户A反馈用户B累计两次, 同时用户B反馈用户A一次, 说明两者之间的交流较频繁。
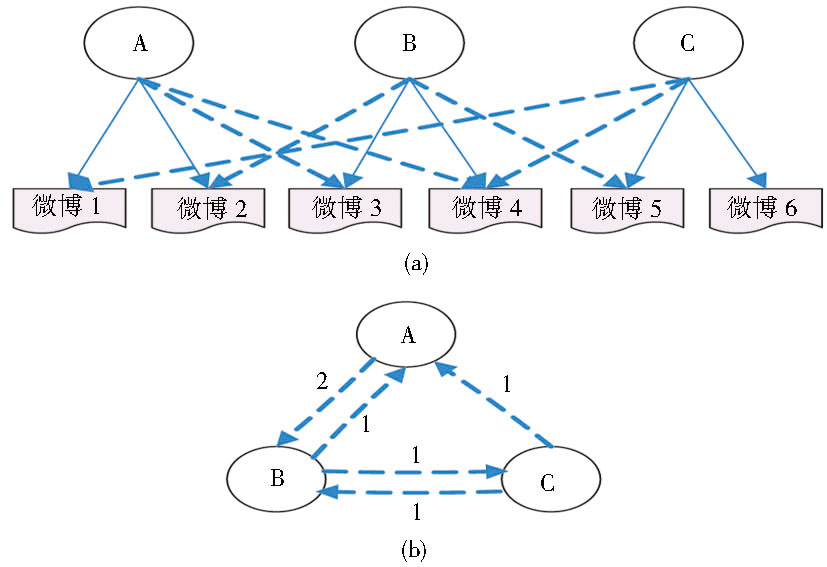 | 图2 用户交互关系 |
用户在微博中的社会关系图与互联网上的网络关系十分相似, 因此可考虑用PageRank算法来对微博用户进行排序。
4 PageRank排名算法及适用性分析
对于网页排名来说, 用户总是希望最需要和最相关的网页排列在检索结果的最前面。网页排名要考虑网页的重要性, 为了评价其重要性, 基于网页链接结构的PageRank网页排名算法被提出[ 23]。PageRank算法是Google的核心, 其基于这样的思想:主要从网页的内容和链接出发, 被链接的级别之和越高的网页, 其重要性越大, 通过分析网页内容与搜索关键词的相似性来获取相关网页集合, 并根据网页间的链接关系确定网页的顺序。因此, 该算法的基本出发点是试图为搜索引擎所覆盖的所有网页赋予一个量化的PageRank值, 每个网页的PageRank值是通过迭代计算的方式来定义, 由所有链接指向它的网页的PageRank值决定, PageRank计算公式如下:
PRn (A) = (1-d) +d×∑mi=1PRn-1 (Ti) C (Ti) (1)
其中, PRn (A) 表示网页A的PageRank值; PRn-1 (Ti) 表示网页Ti存在指向A的链接, 并且是网页Ti在上一次迭代式的PageRank值; C (Ti) 表示Ti的外链接数; d (0< d< 1) 表示阻尼系数, d×∑mi=1PRn-1 (Ti) C (Ti) 表示在随机冲浪模型中网页Ti将自身d份额的PageRank值平均分给每个外链。
在社会化媒体的微博中, 用户之间的关系十分重要。例如, 用户搜索词为“手机”, 排在前面的理应为权威人物发布的高质量的微博, 设此人物为A, 根据PageRank思想, 可推理其关注人B (相当于A的出度) 的重要性同样很重要, 即使B的粉丝数不高, 理应排在前面, 但如果仅使用粉丝数、微博转发量等独立的参数指标, B的排名往往更靠后。为了克服其不足, 在这种边界下引入具有等级关系的PageRank算法是合适的。具体来说, 笔者将引入社会关系的排名, 以期使得排名结果不局限于一个领域, 通过排名质量的提高来满足用户搜索的需求。
5 微博检索排名策略
5.1 引入社会关系的PageRank算法
由于简单利用一些参数指标的高低来实现微博检索排名是不够的, 需要引入具有等级关系的PageRank算法来发现潜在的价值信息。然而, 仅仅运用PageRank算法同样不符合现实, 由文献[24]可知, 公式 (1) 可看成基于随机游走模型的PageRank算法, PageRank算法对每一个链出网页节点都赋予了同等的重要性, 却没有考虑网页节点之间的相似度而赋予不同的权重, 对社会网络来说, 即没有考虑用户之间的社会网络关系强度。
在微博中, 用户之间的关系 (见图1) 存在两种关系, 对于双向图的反馈边来说, 用户之间的互动比较多, 则两人相互反馈的可能性就比较大, 因此从该点出发的边上PageRank的权重值并不能只简单计算平均值, 即从该点走到其他点的概率并不是随机的, 不能简单地认为用户交互关系是随机游走模型, 用户当下的反馈与用户之间的社会交互频繁程度密切相关。如存在这样一种情况:同样搜索“手机”, 设权威人物为A, B, C均为A的关注人, 其中B的粉丝数比C多, 而A与C的交互次数较B更频繁。此时即使C的权威度没有B高, 且与A不在一个领域, 但考虑到其与A的交互比较频繁, 且内容涉及到“手机”相关方面的微博, 说明他们微博内容具有极高的相似性, 也应同时排名靠前。这与大数据背景下, 人们更希望获得事物之间的相关关系的思想是一致的。因此笔者对原有的公式进行改进, 使其能体现微博上的社会关系强度。改进的基于随机游走模型的PageRank公式如下:
PR′n (A) = (1-d) +d×∑mi=1 (PRn-1 (Ti) C (Ti) ×FTi→APA) (2)
其中, 增加了强度项FTi→APA, FTi→A表示节点Ti到节点A的总反馈量, PA表示节点A发布的微博总量。用这样的参数指标衡量用户Ti到用户A出度的强度, 可以避免平均现象的发生, 同时可以有效表示用户之间的社会关系。因此, 在微博中用户A的得分可以理解为:反馈用户A的用户Ti在上一次得分的平均值中, 按与用户A的社会关系强度给予反馈值 (d为阻尼系数) 。
5.2 其他参数指标的设定
微博用户排名可参考PageRank排名的思想, 但是对于微博来说, 用户搜索的内容不仅是被关注者本身, 还涉及到被关注者发布的微博信息。社会网络分析 (SNA) 方法近年来被广泛使用在社交网络中, 作为领袖发现等应用, 如文献[25]和文献[26]等。因此, 笔者要将社会网络分析体现出的社会关系应用到微博排名中。
(1) 相似的微博内容从不同人发布出来的重要性是不同的。如领导人发布的消息比普通人发布的消息权威性更大, 可信度更高, 因此需要统计用户知名度。在社会网络分析法中, 入度更能体现出节点的重要性, 因此这里考虑有向图的内向程度中心性。设网络中共n个节点, 则用户知名度及公式如下:
定义1:用户知名度:通过社会网络分析法来测量用户的知名度, 即用户的中心度。
C=din (ni) n-1 (3)
(2) 微博排名需考虑用户和微博信息两方面, 同样需要考虑发布的微博内容的知名度。这里用微博的转发数作为直接变量, 设网络中共n个节点, |infre|表示一段时期内微博的转发数, 则微博内容知名度及公式如下:
定义2:微博知名度:通过统计微博的入度来测量微博的知名度, 即微博的转发率。
Inf=|infre|n-1 (4)
(3) 由于微博具有时效性, 如两个月前的微博重要性比最近发布微博的重要性要低, 因此需要将时间因素引起的影响力降低考虑进来。设t0表示微博发布的时间, d表示影响力衰减系数, 则微博时效性及公式如下:
定义3:微博时效性:一条微博随时间变化的影响力[ 28]。
Inf (t) =-d (t-t0)2+|infre| (5)
(4) 由于微博有不超过140个字的字数 (包括字符) 限制, 因此微博文本的质量是也需要考虑的因素, 见定义4; 此外, 文本的相似性也需要有所顾及。其中, 相似性采用空间向量的相似度计算方法, 权重选用TF-IDF来计算。具体定义和相似性公式如下:
定义4:微博信息质量:设m为一个微博信息, 则微博信息质量为|m|140, 这里|m|表示微博信息的长度[ 29]。
定义5:微博相似性:主要是指待查询关键词语相关信息相同或相近的概率。
W (tk, d) =tf·idf=log (tf (tk, d) +1) logTlogNntk (6)
其中, tf (tk, d) 为词语tk在文本d中的频数, T为经处理后文本d的词语总数, ntk为文本集中含有tk的文本数量。相似度Sim采用余弦公式计算, 这里不再赘述。
通过分析, 并综合以上因素, 得出微博排名测量参数指标如表1所示:
| 表1 微博排序的抽象参数指标和具体参数指标 |
至此, 本文提出了微博排序所考虑的参数指标。为将所有的因素考虑进去, 取参数指标的平均值作为排名策略, 公式如下:
AVG=CA+Infa+Infa (t) +|m|140+Sim (a, b) +PR′n (A) 6 (7)
6 实证分析
国内多数具有影响力的门户网站都开始提供微博服务, 如新浪、腾讯、网易等。《华尔街日报》印刷版援引市场研究公司Red Tech Advisorsd的数据显示, 新浪微博占据国内微博用户总量的57%, 以及国内微博活动量的87%, 用户注册数量居于国内第一[ 27]。因此, 本文以新浪微博作为实证研究平台。
实验目的:验证笔者提出的方法是否有效; 与关键词、微博转发数、微博评论数、时间4个因素平均值 (以下称这种排名算法为传统方法) 的排名结果对比是否具有优势。笔者通过两部分实验来验证上述假设:
(1) 考察调节变量 (用户知名度、微博知名度、微博时效性、信息质量、微博相似性、微博社会性) 的变化精度, 分组执行不同领域的排名对比;
(2) 将三个领域混合在一起, 把精度最高的调节变量组合与传统微博排名结果进行对比。
其中准确率如公式 (8) 所示:
精准率=检索出的相关信息量检索出的信息总量×100% (8)
实验用到的数据概念有:平均值 (AVG) :针对每条微博 (包括微博信息与用户信息, 下同) , 取各调节变量的平均值; 最大值 (MAX) :针对每条微博, 取各调节变量的最大值; 最小值 (MIN) :针对每条微博, 取各调节变量的最小值。
6.1 数据准备及工具
由于新浪微博平台的数据量庞大, 采用随机抽样的方法获取研究样本。明星是具有一定使用年限的微博认证用户, 这一部分用户有一定的经验, 因此选择用一段时期内明星的微博作为实验样本。具体操作如下:
(1) 微博已实现了部分分类应用, 如明星分布在很多领域:体育界、娱乐界、教育界、新闻界等。笔者选取体育、娱乐和教育界三个大众比较熟知的领域。首先在每个领域内分别随机抓取一位明星及其发布的微博。
(2) 利用抓取工具实现多层抓取, 以每个领域的一位明星为起点, 在“关注”中链式抓取其余19位明星及微博, 每个领域20位明星。
(3) 在三个数据集中, 除去转发的微博 (即内容重复的微博) , 以及无实际内容的微博, 尽量减少对排序结果的干扰, 最终得到60位明星, 11 532个微博。
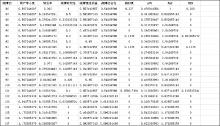
本文的实验工具为数据抓取工具火车头7.6, 中国科学院计算技术研究所分词软件ICTCLAS, 统计分析工具SPSS和Excel, 以及社会网络分析工具UCINET。按领域将这些明星组合在一起, 并结合对应的工具计算相关参数指标, 其中阻尼系数d取0.83, 时间以分钟为单位, 其衰减系数d取0.005, 部分明星的数据样本如图3所示:
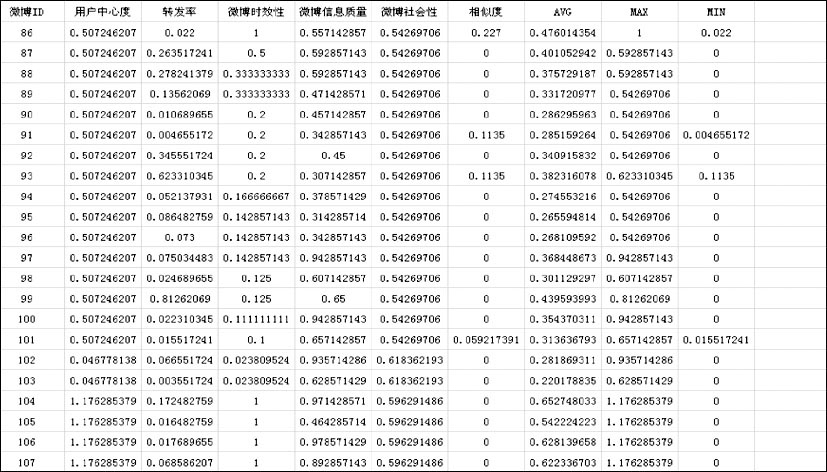 | 图3 明星用户各参数指标的计算结果 |
6.2 不同领域排名精度对比分析
通过关键词统计发现, 在“体育”领域中, 词频较高的关键词有“比赛”、“足球”, 由此确定三组搜索词, 分别为“演员”、“污染”和“比赛”; 在“娱乐”领域中, 词频较高的关键词有“演员”、“青春”; 在“教育”领域中, 词频较高的关键词有“空气”、“污染”。加入相似度参数指标, 分别针对三个领域的数据集进行检索。每个领域取前10个搜索结果并计算其精度, 结果如表2所示:
| 表2 三种方法在三组领域中排名前10个结果的精度 |
由计算结果可知, 在调节变量中, AVG方法的平均值最大, 每组明星样本中的精度与平均值偏差最小, 因此其排名效果最好。一部分原因是由于当所有的参数指标取平均值时, 此时不再只看一种参数指标, 而是存在着社会关系值, 这种社会关系将领域中明星的内在关系关联在一起, 使得可以排名靠前但粉丝数不高的明星排在前面, 检索出的内容更加相似, 查准率相对较高。
6.3 混合领域的排名结果对比分析
本节实验的内容主要是进一步验证提出方法的有效性, 选用调节变量组合最高的平均值算法与传统算法进行对比。
首先把混合在一起的微博内容进行分词, 去除无意义的虚词, 所得词频排名前几位的关键词有“空气”、“污染”、“比赛”、“演员”等。选取关键词“污染”作为检索词进而计算参数指标 (见图3) , 得到最终排名结果。利用6.2节得出的取平均值算法 (AVG) 与传统排名方法 (Conventional Ranking) 的精度对比, 如图4所示:
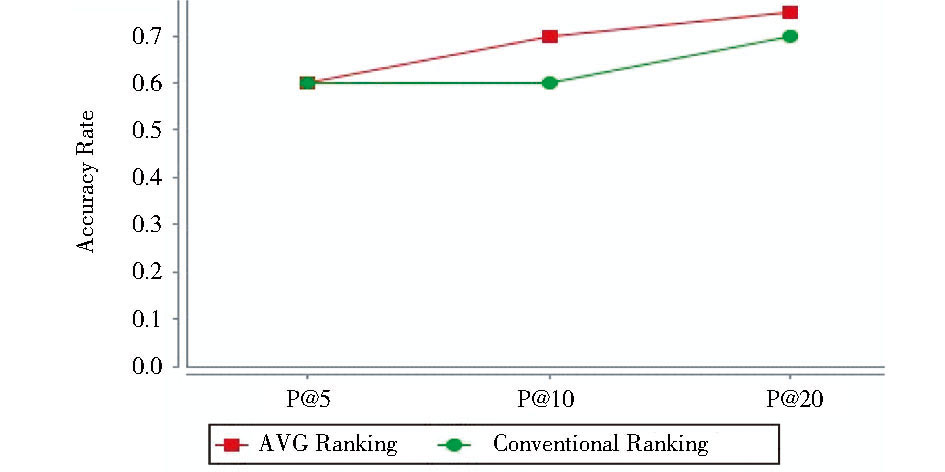 | 图4 两种方法P@5, P@10和P@20值对比 |
由图4可知, 融入社会关系的排名方法与传统方法在排名前5位时的准确率相同, 随着排名列表的增加, 准确率都呈现上升趋势; 本文提出的方法较传统方法在P@10和P@20都有显著提高。
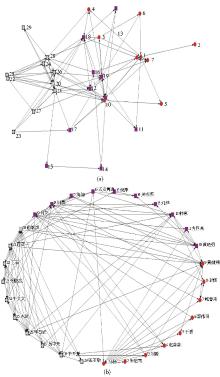
对前30个用户进行关联统计和社会网络分析, 去掉孤立点后得到他们之间的关系如图5所示:
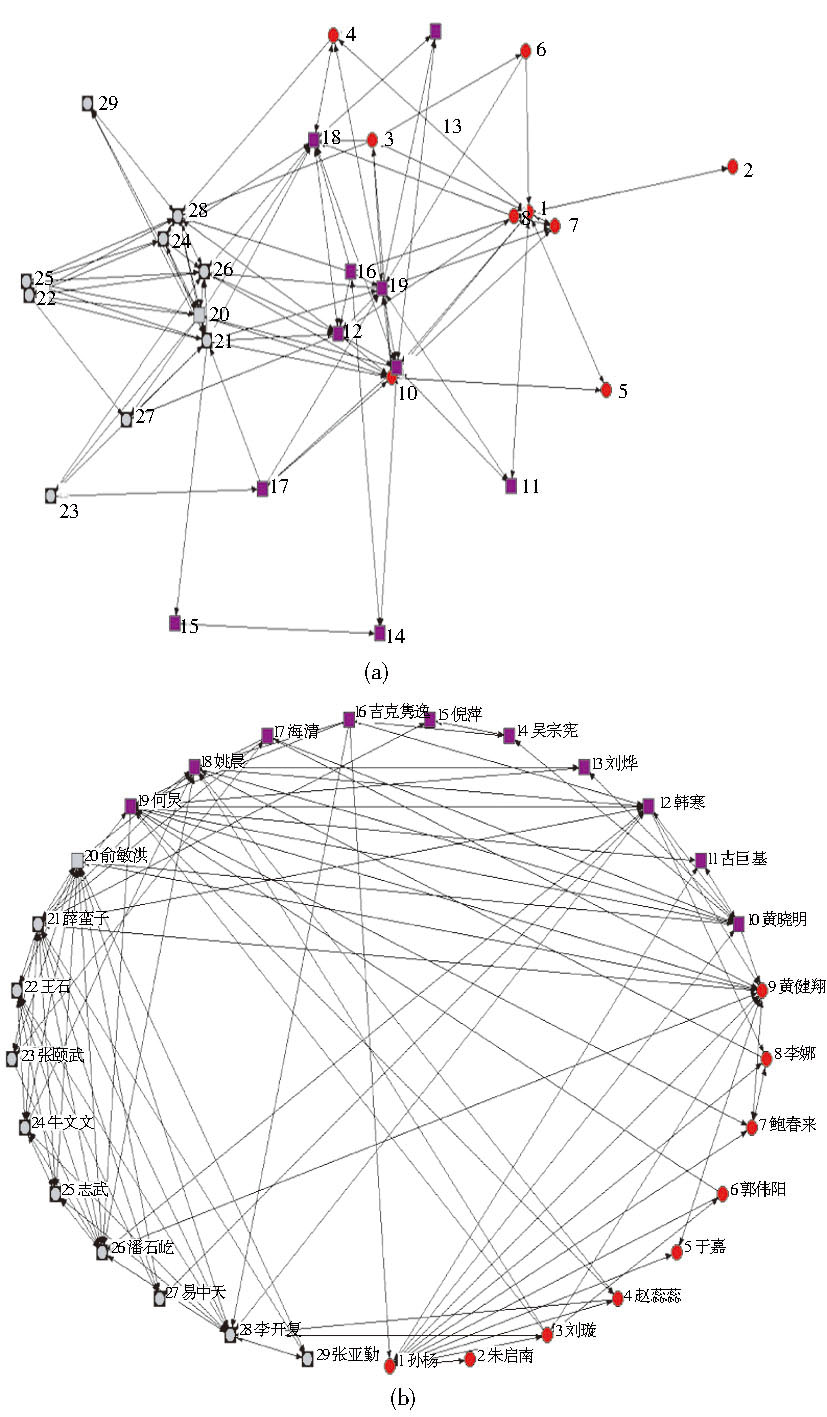 | 图5 前30个用户的社会网络关系 |
图5 (a) 和图5 (b) 从不同角度展示了用户之间的关系, “方块”表示娱乐界的明星, “圆形”表示体育界的明星, “方块包圆”表示教育界的明星。由图5 (a) 可见, 相同形状的节点更易聚集在一起, 表示独自领域内的明星交流比较多; 由图5 (b) 可见, 每个领域与不同领域的明星同样存在比较频繁的交流。AVG算法和传统算法排名的前10位的用户ID和微博ID如表3所示:
| 表3 AVG算法和传统算法的排名对比 |
对照图5 (b) , 在AVG算法排名前10的微博中, 明星有“李开复”、“何炅”、“姚晨”、“韩寒”、“孙杨”、“潘石屹”、“黄健翔”和“张颐武”; 在传统算法排名前10的微博中, 明星有“何炅”、“韩寒”、“李开复”、“姚晨”、“薛蛮子”。由此可知, 在融入社会关系的算法AVG中, 排名靠前的微博明星分布在不同领域, 从教育界到娱乐界再到体育界都包含在内; 而在传统算法中, 靠前的微博都来自于5位明星, 体育界的明星并不可见, 一部分原因是由于AVG中加入了社会关系因素, 排名考虑到用户之间的社会关系。由图5可知, 黄健翔与何炅虽属不同领域明星, 但两者相互关注, 且黄健翔与娱乐界交流频繁, 说明他们的微博内容具有相似性, 因此即使他的粉丝数不多排名也靠前。由此可知, 加入社会关系可以在某种程度上提高查全率。
7 结 语
社会化媒体新的网络形式的出现, 需要提出新的搜索排名策略来满足用户的检索需求。本文通过分析微博的社会关系, 提出了一种融入社会关系的微博检索排名策略, 参数指标分别为用户知名度、微博知名度、微博时效性、微博信息质量、微博相似性和微博社会性。其中用户知名度即用户中心度, 表示了一部分社会性; 微博知名度即微博转发率, 体现微博的重要程度; 微博时效性用时间衰减函数来表示, 以代表时间属性的权重; 微博信息质量用微博的长度衡量, 以此体现微博信息量的大小; 微博相似性用空间向量模型实现; 微博社会性是通过对基于随机游走模型的PageRank进行改进, 加入社会关系强度因子来体现用户之间的交互频繁社会性。
本文的实验分为两部分:为检验调节变量的变化对排名结果的影响, 并对比各组的排名结果; 为验证方法的有效性, 将本文提出的排名策略与传统排名策略进行对比。实验结果表明, 采用调节变量的平均值 (AVG) 查准率更高, 较传统算法更具有优势。
本文的研究存在一定局限性:由于微博海量数据的存在, 社会关系表现复杂, 本文所统计的样本数据量有限, 未能将微博上的所有关系都表示出来; 是否存在比AVG更好的指标权重组合有待进一步研究。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|