{kind=link}
人名属性知识挖掘及其在查询分类中的应用
引用本文
张梅, 段建勇, 徐骥超. 人名属性知识挖掘及其在查询分类中的应用. 现代图书情报技术, 2013, 29(9): 82-87
Zhang Mei, Duan Jianyong, Xu Jichao. Person Name Attribute Knowledge Mining and Its Application for Query Classification. New Technology of Library and Information Service, 2013, 29(9): 82-87
Permissions
Zhang Mei, Duan Jianyong, Xu Jichao. Person Name Attribute Knowledge Mining and Its Application for Query Classification. New Technology of Library and Information Service, 2013, 29(9): 82-87
人名属性知识挖掘及其在查询分类中的应用
摘要
网络日志中存在大量的命名实体类查询, 而其中人名查询占到近半的比例。提出运用网络查询日志和维基百科知识构建人名知识库, 并应用于查询分类。通过抽取查询日志中的人名实体, 并结合百科知识充实实体属性知识, 形成包含属性知识的人名知识库。根据高质量的属性模板和统计分类方法对查询中的人名进行分类, 在查询推荐中依据不同人物分类知识库进行分类推荐。实验结果表明该知识库对查询串中的人名实体能进行有效分类。
关键词:
属性挖掘; 查询分类; 信息检索
Person Name Attribute Knowledge Mining and Its Application for Query Classification
Abstract
There are many name entity queries in the Web logs, and person name queries are more than half of these queries. This paper uses Web logs and Wikipedia information to construct the person name knowledge base for the query recommendation. Firstly the person name entities are mined from Web logs and the attributes of these entities are combined by extracting from Wikipedia. With the help of the person name knowledge, the person names in the user queries are classified by the attribute patterns and statistic methods. Then related attribute knowledge is used to recommend the user Intents. The results show that the person name knowledge can be used effectively in the query classification.
Keyword:
Attribute mining; Query classification; Information retrieval
1 引 言
搜索引擎根据用户的查询需求, 对其查询词进行分析提交给信息检索系统, 检索系统通过对每个文献内容上的相关度的计算, 从中抽取到满足用户需求的文档结果。用户输入的查询词一般都很短, 约2-3个词, 并且其中一般都会包含实体词汇。查询推荐的核心是用一定的策略将用户关注的查询词推荐给用户, 而查询推荐是通过计算词与词之间的相似度, 根据相似度排序, 将排到前边的信息展示给用户。这种方法可能存在语义信息不完全的情况, 致使用户查询词与推荐词之间存在一定的差异, 使得查询推荐系统的准确率和召回率较低, 不能满足用
户真实查询需求。
为解决上述问题, 通过构建知识库分类推荐, 定位用户的真实查询意图。由于人名查询在所有查询中所占比例极高, 据考察搜狗一周内的网络日志 (以搜狗实验室公开发布的2008年6月的数据为基础, 选取第二周的数据进行分析) 发现, 每天日志记录的词汇中大部分都含有实体, 只有小部分查询不含命名实体, 很多搜索用户都关注以实体为基础的搜索信息, 如图1所示, 有超过一半以上包含人名实体, 研究查询中的人名实体非常重要。
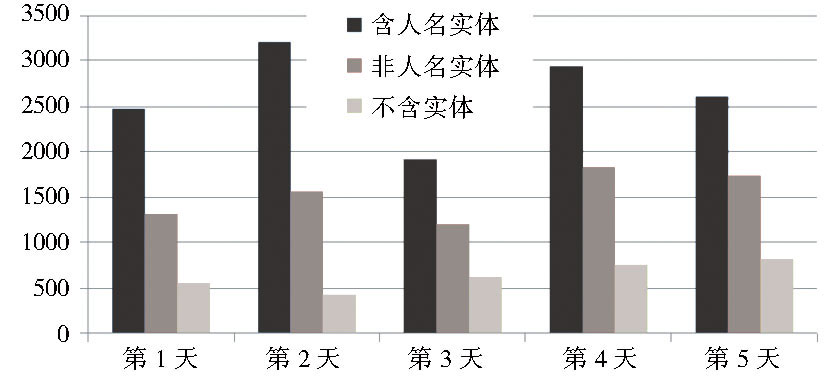 | 图1 一周内用户查询实体分布情况 |
2 相关工作
查询日志中用户输入的大部分词条很短, 包含的信息量很少, 仅通过网络查询日志所携带的信息对用户查询意图进行分析非常困难, 需要额外的辅助信息支持查询意图分类。本文主要从命名实体与属性知识库挖掘及其在查询分类中的应用进行调研。
命名实体及其属性知识库构建的研究集中在命名实体识别、分类、组织及其应用等方面。命名实体的挖掘范围包括网络在线资源、普通文本等异构资源[ 1]。在挖掘方法上除了命名实体本身的特征, 还引入外部语义资源包括维基百科、知网、万维网等, 辅助挖掘命名实体[ 2, 3]。在命名实体挖掘的同时, 伴随着实体相关属性知识的挖掘[ 4], 构建动态演化的命名实体知识库[ 5]或者细化领域的知识库[ 6], 在知识库组织过程中运用本体组织方法支持各种相关应用[ 7], 包括命名实体识别、分类、消歧等任务[ 8, 9]。
查询分类的研究主要集中在查询分类体系构建、查询意图识别等方面[ 10]。查询分类体系构建通常借助网站的目录结构及站点列表等资源形成分类体系[ 11]。查询意图识别可以看成是分类问题, 所使用的特征包括用户点击数据、查询串特征等[ 12, 13]。由于查询串所携带的信息量有限, 需要引入外部语义资源, 包括语义词典进行语义扩展, 提高查询意图识别的覆盖面[ 14]。由此可以看出, 语义知识库作为外部资源在查询分类中具有重要作用。
本文的主要工作是建立人名属性知识库, 人名知识是以类簇的方式组织起来的, 不同类别分别由不同的属性集合组成。通过构建特定领域的人名属性知识库辅助查询分类, 从而准确推荐用户最感兴趣的人名实体及其相关内容。
3 人名属性知识挖掘
主要从网络日志中抽取初步的人名信息作为种子, 然后结合百科知识挖掘人名相关的属性知识进行充实, 最终建立人名知识库。根据人物实体属性知识库中的属性, 制定人物属性规则, 完善人物属性知识库。
3.1 网络日志中人名信息抽取
以搜狗的网络日志作为研究对象, 该日志记录由用户的Session ID、用户查询词条、用户选择的URL、用户点击URL的Rank值、用户提交查询的时间几部分组成。从搜狗日志中抽取出用户经常搜索的人名实体, 并计算一些查询统计信息等。搜狗网的用户查询日志格式, 其中包括用户的ID、用户查询词条、点击URL等信息, 如表1所示:
| 表1 搜狗的网络日志格式 |
利用中国科学院计算技术研究所开发的ICTCLAS分词系统对搜狗网络查询日志中词条进行分词与人名识别。从网络日志中抽取最初的人名实体作为初始种子, 网络日志中人名信息反映了实际需求, 主要从搜狗网络日志中抽取。
3.2 百科知识中人名属性挖掘
维基百科是在线编辑的知识库, 每一个页面都包含了该实体对象的信息框, 信息框中包含实体的属性与属性值。由于不同圈子的人物的属性与属性值不同, 人物类别又可以根据职业不同分为不同圈子的人, 比如娱乐圈、政治圈、IT圈等。不同圈子的人物有着各自重要的属性。可以结合人物圈子, 采用属性与属性值人工制定高质量的模板与规则, 称为属性模板方法 (AttriPatterns) 来抽取维基百科中人物属性知识, 从而充实人名知识。
属性与属性值抽取过程结合笔者的前期工作[ 3], 利用获得人名实体和属性与属性值作为种子集合, 构造查询器并从搜索引擎中抽取相应的属性与属性值。从返回的结果中抽取具有并列结构的属性, 例如表示并列结构的标志有“、”“和”等, 或通过构造简单的句子分类器, 对包含人名实体和属性的句子进行筛选, 获得人名实体属性知识。
3.3 人名知识库组织
获取的人名知识库组织方式分两类情况:一种是已经获取的人名知识, 其已经确定了分类领域并且附带了属性信息等, 可以直接进行应用, 如刘德华属于娱乐圈, 包含年龄、代表作品、经纪公司等属性及其具体属性值;另一类按照人物圈进行属性集合构建, 支持后期人物的查询分类, 如娱乐圈类别, 所有具体人物共同出现的属性信息情况都可以作为娱乐圈潜在的属性, 在此基础上按照共现频率选择高频的属性形成特定人物圈的属性集合。
按照本体的构建方法, 针对人名实体主要组织了三个大的人物圈, 包括娱乐圈、体育圈以及商业圈, 后期可在此基础上增加新的层级体系。三个人物圈共组织了接近300个具体人名知识库, 并为每个人物圈形成属性集合, 以频率信息为主要指标, 为每个集合遴选出20个最主要的属性信息, 其他属性信息备用, 人物圈的属性集合可作为后期人物实体自动分类的重要依据。
4 人名知识库在查询分类中的应用
4.1 人名实体分类算法
在实际的查询分类中, 单纯的属性知识方法进行人物分类准确率比较高, 但是由于属性知识受到训练规模等因素影响, 覆盖度不高, 未被分类的人名的查询分类效果受到一定影响, 存在召回率低的缺陷。融合统计方法正好克服了这个问题, 主要依据属性知识作为分类依据进行人物圈子的分类, 结合维基百科中各种属性信息的频率等信息以及查询串上下文词汇特征, 提高人名实体分类的覆盖率。笔者提出一种基于属性信息与词频相结合的人名命名实体分类算法 (Attributes and Word Frequency based Person Name Classification, AWFPNC) , 该算法主要基于贝叶斯后验概率公式计算两种特征分类能力, 如下所示:
输入:人名属性训练集:不同人物圈Ci的属性集合ATTR={attr1, attr2, …, attrk…};词汇特征训练集:人名NEj以及对应的上下文词汇termk;综合训练集:带有人物圈Ci标注的人名实体NEj上下文。
输出:待分类人物命名实体NEe的分类Cg。
①词汇特征清洗:用停用词表去掉大量重复的词, 离线统计网络日志中特征训练数据的s个高频词汇termi的词频Count (termi) 。
②词汇特征值计算:利用训练集计算s个高频词汇termi属于类别Ck的条件概率Pw (termi |Ck) , 这是典型的分类问题。它是termi在类别Ck中出现的次数占所有类别中出现次数的比值, 得到特征分类能力Pw (Ck|termi) =Pw (termi|Ck) Pw (Ck) ∑sj=1Pw (termi|Cj) Pw (Cj) , 此值为后验概率值, 可通过训练集合得到。
③词汇特征分类:在待分类的人名实体NEi的上下文中, 选取上下文窗口长度为m的词汇特征termj, 这里m个窗口长度中的词汇选取依据这样的原则:只有在训练过程中termj已经得到其分类能力才会真正被用于计算。在计算中不考虑顺序因素, 那么Pw (Ck|NEi) =∑mj=1Pw (Ck|termj) m为NEi属于类别Ck的概率。
④人名属性特征值计算:利用输入的人名属性集合, 考察训练集合上下文中获取的t个属性信息attri, 计算人物圈Ck条件下属性attri的条件概率Pa (attri|Ck) , 得到属性分类能力的后验概率值Pa (Ck|attri) =Pa (attri|Ck) Pa (Ck) ∑tj=1Pa (attri|Cj) Pa (Cj) 。
⑤人名属性分类:输入待分类的人名实体上下文, 利用属性集合识别上下文窗口长度为n的属性, 计算NEi属于类别Ck的概率Pa (Ck|NEi) =∑nj=1Pa (Ck|attrj) n。
⑥特征融合:融合词汇特征与属性特征两种方式计算结果, 计算出待分类人名实体NEe属于人物圈Cg的概率Pwa (Cg |NEe) , 提出特征融合计算公式如下:
Pwa (Cg|NEe) =α·Pw (Cg|NEe) +β·Pa (Cg|NEe)
其中, α与β的值是在词汇特征与属性特征同时存在的前提下才启用, 否则按照词汇特征方法或属性特征单独进行计算。
4.2 查询分类中的人名歧义消解
从搜狗查询日志中识别出来的人物实体在实际情况中可能存在多种歧义现象:第一类为同一个人名实体对应不同的类别标签;第二类为多个不同人名实体对应相同类别标签。第一类情况如李宁最先属于运动员, 而在退出体坛后转身变为一名成功的商人, 此时李宁既属于运动员又属于商人, 这时需要通过一种策略来选择出用户最有可能想要的一个类别分类;第二类如娱乐圈的宋佳分别有两个对应的人名实体, 这种情况相对来说较为复杂, 目前在歧义消解方面主要利用属性信息, 例如利用年龄、出生地、代表作品等初步歧义消解, 而深度消解歧义则相对困难, 拟在后期研究中深入探讨, 本文侧重对第一类情况进行歧义消解。
第一类情况的同一个实体对应两个甚至多个类别的情况, 一个人物可能存在两种身份, 不合适的推荐顺序会导致用户满意度下降。由于搜索引擎返回的结果中排名靠前的数据都是权重比较大的数据并且具有实时性, 能最大概率反映当时的用户需求, 可以根据返回结果来对人名实体分类进行消歧。
人物实体消歧算法的实质就是利用网页快照离线计算出最大可能的人物分类。通过计算实体与类别间的条件概率对人物实体进行消歧分类, 消解方法主要运用搜索引擎的返回结果。首先将待分类查询q (含歧义人名NEi) 提交给搜索引擎, 获取返回的网页快照, 表示为R={r1, r2, …, rn}, 其中n通常取前10个网页快照, ri包含丰富的词汇信息, 可看成是人名实体的上下文;人名实体的目标分类体系为C={C1, C2, …, Ck}, 借助每个网页快照ri提供的上下文特征与属性特征, 分别计算出NEi所属类别Ck, 即Pwa (Ck |NEi) , 其计算过程参照属性信息与词频相结合的方法。按照最大似然估计, 在返回网页快照中出现次数最多的类别即是用户最感兴趣的类别, 该类别可用来进行人物推荐。在实际使用中也可以采用列表的形式按照概率大小列举出来, 供查询用户自主选择。人名歧义消解算法根据搜索引擎反馈的网页快照来进行识别并分类, 该方法利用互联网信息的实时性近似模拟用户实际信息需求。
5 实验结果
实验以网络日志、维基百科等作为训练库与测试库, 分别就人名属性知识抽取以及查询推荐中人名分类情况进行考察, 并对其中参数选取与人名歧义消解的效果进行测试。
5.1 人名属性知识库构建实验
训练数据随机从网络日志中抽取, 以1 800个人名实体的查询串作为人物实体语料数据, 其中包含860个娱乐数据、450个体育数据、490个商业数据等不同的分类数据, 如表2所示:
| 表2 属性规则产生的人物圈分类训练集 |
挖掘方法在维基百科中采用属性模板方法对上述人名数据进行属性挖掘, 这种方法利用人物相对应的属性规则进行分类, 得到准确率高的数据。由于属性模板方法得到的人物分类不完全正确, 对分类好的数据通过人工校验来提高数据的质量, 作为后续实验的测试集合, 形成297个具体人名。
构建的人物属性知识库是查询推荐中人物分类的基础数据。首先对各个人物类别利用TF (Term Frequency) 的方式抽取出代表类别的属性/属性值信息, 统计不同人物圈子中各个属性出现的频率, 结合频率信息, 分别建立人物圈子的属性知识库, 包括属性名与属性值。人物圈属性库如表3所示:
| 表3 人物职业圈属性 |
5.2 查询中人名分类结果对比实验
实验数据用500个已经人工分类好的包含人名实体的查询串作为测试数据, 其中包括223个娱乐圈实体, 187个体育圈实体, 90个商业圈实体。
(1) 主要方法对比实验
实验中对比方法主要有三种:基于属性模板的方法 (AttriPatterns) 、基于属性信息与词频相结合的人名命名实体分类算法 (AWFPNC) 以及基于属性信息与词频相结合的人名命名实体分类算法+人名歧义消解算法 (AWFPNC+WSD) 。
度量标准使用信息检索中经典的准确率 (Precision) 和召回率 (Recall) 。准确率为检索到的相关文档除以所有被检索到的文档得到的比率;召回率是检索出的相关文档数和文档库中所有的相关文档数的比率。为了更好地体现算法总体的分类效果, 对整个分类体系中的各个类别计算准确率、召回率, 最后通过平均准确率、平均召回率进行评估, 比较结果如表4所示:
| 表4 查询串中人名分类结果 |
由表4可以看出, AWFPNC的查询词分类算法有较高的召回率, 但准确率并不太高, 说明AWFPNC人物实体分类算法可以覆盖很多种情况, 但对单个实体的查询准确率稍低。AWFPNC+WSD分类算法具有较高的平均准确率和召回率, 而AttriPatterns的人物实体分类具有较高的准确率, AWFPNC的分类算法具有较高的召回率, 总体上讲AWFPNC +WSD具有更好的准确率和召回率。
(2) 人名歧义消解情况分析
在算法AWFPNC+WSD中人名歧义消解起了一定作用, 为此进行详细考察:实验语料经过人工分析, 发现有31个同名兼类情况 (本文所述的第一类人名歧义情况) , 兼类分两种情况, 即娱乐圈/商业圈, 体育圈/商业圈。具体情况如表5所示:
| 表5 第一类人名歧义情况 |
在这些具有歧义人名中的热门查询包括姚明、谢霆锋等, 这些查询涉及到人物在体育圈、娱乐圈主业以外还从事其他的商业投资活动;而李宁、陈晓旭等则改行从事商业。这些热门查询中的名人转行从商是人名歧义的主要来源, 转行人物查询主要原因是影视剧怀旧版重播导致网络用户对昔日明星的近况关注;体育圈的人名转行人数较多, 这与体育圈本身的职业生涯较短有直接关系, 经商是多数退役运动员的首选。
人名歧义消解的识别率比较高, 能达到90%以上, 部分原因是查询用户对经商为副业的娱乐圈、体育圈明星的关注点还是其主业, 因而返回网页能够排名靠前。在转行的人物中识别率较低, 识别率占50%左右, 但转行的人物数量较少, 所以人名歧义消解总体正确率较高, 其对人物查询分类的支撑较好, 对准确率、召回率的分类结果见表4。
(3) 重要参数选择实验
当算法AWFPNC的属性特征与词汇特征同时出现的时候, 特征融合主要依靠两者的权值调整, α是词汇特征权值, β是属性特征权值, 且有这样的条件:α+β=1。参数包括准确率与召回率及F-score值, 其中F-score= (2×Precision×Recall) / (Precision+Recall) 。按照一定的参数滑动窗口, 其结果如表6所示:
| 表6 参数α与β影响情况 |
从表6可以看出, 当参数α=0.3, β=0.7时, F-score的效果最佳, 因而选取该组参数作为本算法的经验值。
6 结 语
本文主要通过对搜索引擎中的用户查询日志进行分析处理, 挖掘其中人名信息, 并从半结构化维基百科的网络知识库中抽取人名相关的属性/属性值知识, 对搜狗网络查询日志中包含人名查询实体进行分类, 将不同的人物实体贴上不同类别的标签, 以满足用户查询需求。
未来可以考虑人物属性/属性值知识库升级扩充问题, 人物属性是随着时间不断扩充的, 今后系统必须考虑到知识库同步升级的策略, 以丰富人物属性库、人物分类库等知识库。另一方面, 可以引入更全面的人物潜在关联信息, 实现第二类人名实体的歧义消解。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|