




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
利用交互历史进行P2P知识共享社区发现的研究
引用本文
高海艳, 窦永香, 齐艺兰. 利用交互历史进行P2P知识共享社区发现的研究. 现代图书情报技术, 2013, 29(9): 93-98
Gao Haiyan, Dou Yongxiang, Qi Yilan. A Research of Knowledge Sharing Community Discovery Based on Interaction History Between Peers in P2P Networks. New Technology of Library and Information Service, 2013, 29(9): 93-98
Permissions
Gao Haiyan, Dou Yongxiang, Qi Yilan. A Research of Knowledge Sharing Community Discovery Based on Interaction History Between Peers in P2P Networks. New Technology of Library and Information Service, 2013, 29(9): 93-98
利用交互历史进行P2P知识共享社区发现的研究
摘要
提出一种利用用户交互历史实现P2P社区发现的方法。研究知识共享过程中交互历史的产生, 根据交互历史形成用户交互网络, 计算用户相似度; 对用户进行聚类分析发现P2P环境下自组织形成的知识共享社区。最后通过实验验证该方法的可行性和有效性。
关键词:
知识共享社区; 交互历史; 用户交互网络
A Research of Knowledge Sharing Community Discovery Based on Interaction History Between Peers in P2P Networks
Abstract
In this paper, a P2P community discovery method based on interaction history of knowledge sharing is proposed.At first, a research on the generation of interaction history during the knowledge sharing process is conducted, the user interaction network is formed on the basic of interaction history and the similarities between users are calculated. Then, the clustering analysis approach is used to discover the self-organized P2P knowledge sharing community. Finally, an experiment is designed to verify the feasibility and efficiency of the method.
Keyword:
Knowledge sharing community; Interaction history; User interaction network
1 引 言
P2P技术使人们在Internet上的共享行为提高到了一个更高的层次, 人们以更主动的方式参与到网络活动中去。利用P2P技术在分布式网络中进行知识共享, 用户通过P2P 网络相互交流, 交互彼此所拥有的知识, 具有相同或相似兴趣的用户通过交互自组织形成知识共享社区, 社区中的每个用户不仅是知识接受者, 还是知识生产者和协调者。发现P2P网络中的社区具有重要意义, 如文献[1]发现资源社区后以P2P资源社区为基础进行资源检索, 提高检索的查全率和查准率; 文献[2]和文献[3]利用P2P社区进行知识共享不仅使知识接受者获得较完整的知识, 而且由多个用户共同提供知识, 降低知识提供者的工作负担, 提高知识共享的效率。因此, 发现这些自组织形成的知识共享社区能够充分挖掘用户间的关系, 实现更高效的知识共享。
在利用P2P网络进行知识共享的过程中, 交互是节点间信息传递的桥梁, 辅助节点在P2P网络中进行探索, 使得用户能够共享知识, 并且交互历史是用户在一段时间内通过知识共享产生的, 是用户间关系最直接的反映, 在知识共享过程中具有重要的参考性, 说明了这些用户对某些资源有相同的兴趣。因此, 本文将交互历史应用到P2P社区发现过程中, 通过节点的交互历史寻找具有相同兴趣或爱好的用户, 然后对用户聚类分析发现知识共享社区, 从而帮助用户快速找到更加准确的资源, 提高知识共享的效率。
2 相关研究
现有的P2P社区发现方法主要有两种:随机游走法和相似度计算法。随机游走的方法主要是考虑网络距离及传输延迟, 是面向信息传输效率的。主要有CDC方法[ 4]、FDC方法[ 5]和PDC方法[ 6], 通过计算节点随机游走的概率值进行中心节点的选择和普通节点的聚类。相似度计算的方法主要是考虑节点上存储数据的相关性。文献[7]和文献[8]利用节点声明的属性, 计算属性相似度, 根据节点的属性识别用户的兴趣, 发现社区; 文献[1]和文献[9]通过计算用户相似度, 将相似度最大的节点作为中心节点, 相似节点聚类形成社区。文献[10]和文献[11]利用节点所提供的共享资源, 挖掘相关的资源, 最后发现相关度大的资源形成社区。
可以看出, 目前P2P社区发现方法主要利用节点存储的信息, 根据一定的标准对节点进行聚类。虽然有些节点具有相同或相似的资源, 但是这些节点可以随意离开网络或拒绝为其他用户提供资源, 因此也就很难加入社区为其他节点更好地提供服务。而交互历史则是多个节点自愿参与知识共享共同产生的, 产生交互的节点不仅具有相似的资源而且还活跃在网络中, 交互历史也是节点自组织形成社区的依据。因此, 本文充分发挥节点交互历史的作用, 提出了一种利用交互历史进行P2P知识共享社区发现的方法:首先研究了知识共享过程中交互历史的产生, 提出了根据交互历史记录形成用户交互网络, 然后试图通过用户交互网络的邻接矩阵来计算用户相似度, 最后结合K-means算法对用户进行聚类分析实现P2P知识共享社区的发现。
3 节点间的交互历史分析
在P2P网络环境下, 为了能够在知识共享过程中搜集有用信息, 节点需要充当服务器, 通过构建共享资源库和交互历史记录库来存储共享信息[ 12], 同时这两个库也为后序构建用户交互网络提供了依据, 本文参考文献[13]对其定义如下:
定义1: 共享资源库SR={class, resourceName, address}。共享资源库是节点所存储的进行知识共享的资源索引信息, 包括节点自己共享的资源和从其他用户下载的资源。class是资源类别, 在进行资源搜索时, 根据class信息可以提高搜索的准确率; resourceName是资源名称, 是对共享资源最直接的描述; address是class文件的物理地址, 共享资源的存放路径。
定义2: 交互历史记录库IH={Id, peerList, action, content, time }。在纯P2P网络中, 交互历史是本地节点所捕获的一段时间内的交互历史记录。Id是交互历史记录的唯一标识; peerList是与本地节点交互的节点集; action={Q, R}, Q表示交互节点向本地节点发送查询请求, R表示本地节点收到了服务节点的响应请求; content为本次交互的内容; time为历史交互发生的时间。
3.1 知识共享过程中交互历史记录的产生
在P2P网络中由于节点自己充当服务器, 因此节点间彼此都不熟悉, 只有通过知识共享不断地与其他节点交互, 才能找到与自己有相同兴趣的节点, 并且产生的交互记录在知识共享过程中具有重要的参考性, 而不同领域或没有共同兴趣的节点则很难产生交互。本文参考文献[14]详细描述了P2P网络中节点知识共享的过程, 分析交互历史记录的产生, 如图1所示:
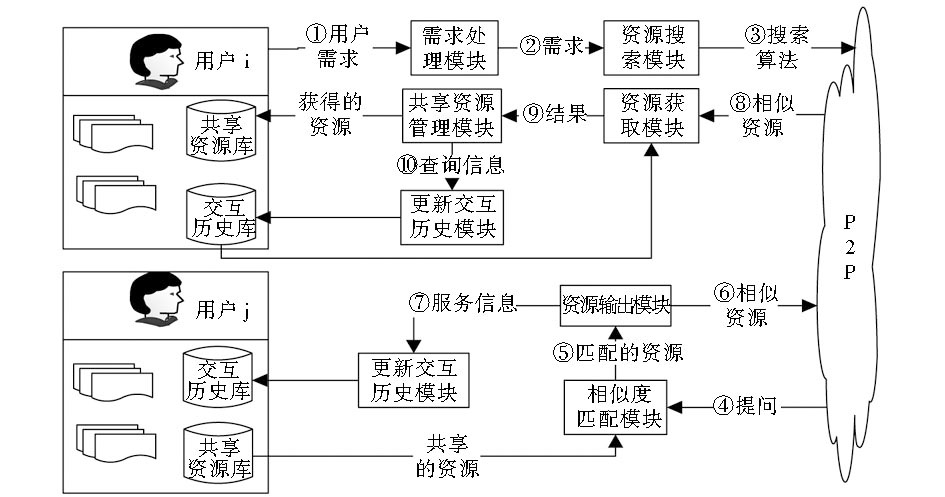 | 图1 P2P网络中节点知识共享的过程 |
(注: ①—⑩表示完成一次知识共享经历的步骤。)
从图1可知, 知识共享过程由以下8个模块组成:
(1) 需求处理模块:对用户输入的请求进行加工处理, 准确识别用户需求。
(2) 资源搜索模块:提出搜索算法, 向邻居节点发送搜索请求。
(3) 相似度匹配模块:当邻居节点收到搜索请求时, 计算与共享资源库中共享的资源的语义相似度。
(4) 资源输出模块:把高于相似度阈值的资源进行规范化处理返回给查询节点。
(5) 服务节点更新交互历史模块:邻居节点为查询节点提供服务后, 将查询节点、查询行为及交互时间等信息存入交互历史记录库, 并更新交互历史记录。
(6) 资源获取模块:当查询节点收到多个邻居节点返回的相似资源时, 计算与这些节点的交互频度, 连接交互频度最高的节点以获取资源, 作为检索结果。
(7) 共享资源管理模块:完成知识共享后, 将查询节点获取的资源进行加工处理后存入共享资源库中, 丰富共享资源库, 也为同其他节点知识共享做准备。
(8) 查询节点更新交互历史模块:查询节点将本次知识共享过程中收集的与其有相似兴趣的服务节点、服务时间等信息存入交互历史记录库中, 并更新交互历史记录。
在知识共享的过程中, 节点用户作为知识生产者, 通过相似度匹配模块和资源输出模块将隐性知识转化为显性知识, 提供给其他用户; 同时节点用户也可作为知识接受者, 通过资源获取模块和共享资源管理模块从其他节点获取知识; 节点用户还担任知识协调者的角色, 通过更新交互历史模块记录与自己有相似兴趣的用户, 而且在资源获取时通过交互频度准确找到所需知识的合适位置。
资源获取模块中选择最终检索结果时, 交互历史起到了重要的参考作用, 根据交互历史计算的交互频度越高, 说明该节点与查询节点越相似, 该节点提供的资源越准确。
3.2 交互历史相关参数分析
用户的交互历史是一段时间内交互历史记录的集合, 笔者借助节点存储的交互历史信息进行相关参数分析, 主要考虑以下几个参数的关系:节点间交互次数、节点交互总数、交互频度, 如表1所示。节点间交互次数为用户交互网络的形成奠定基础, 将交互频度作为用户相似度的影响因子。
| 表1 交互历史信息 |
以下是本文对这三方面信息的具体解释和定义。
定义3: 节点间交互次数M:两个节点pi和pj在知识共享过程中发生交互的记录总数, 包括响应记录和请求记录, 用公式Mij=m+nt=1 I(t)ij表示。
定义4: 节点交互总数N:与pi有过交互的所有节点的交互次数之和。假设节点p1, p2, …, pr与节点pi有过交互, 且交互次数为 (M1i,2i, …, Mri) , 则节点pi的交互总数Ni=rj=1 Mji, 交互总数越大说明节点不仅活跃而且兴趣广泛。
定义5: 交互频度W:节点pi与pj的交互次数在节点pi及pj交互总数中所占的比例。即Wij=Mij/ (Ni+Nj) , 在pi和pj所有的交互节点中, pi与pj之间的交互越频繁, 说明节点间的兴趣越相似, 即Wij越大对节点的兴趣相似度计算贡献越大, 因此本文将交互频度作为用户相似度的影响因子。
3.3 基于交互历史形成用户交互网络
在P2P系统中, 用户是网络中的节点, 用户在知识共享的过程中, 需要与其他用户进行交互, 这样就会使得用户与用户之间产生一种联系, 记录节点间的这种联系——交互历史记录, 依据某段时间内的用户交互历史能够形成一种拓扑结构——用户交互网络[ 15]。用户交互网络可以用无向图G= (P, E) 表示, 无向图的顶点集合用P= (p1, p2, …, pr) 表示, pr是P2P网络中的一个节点; 节点pi和pj之间有过交互就会产生一条边, 所以无向图的边用集合E= (e1, e2, …, er) 表示; 用户间的交互次数作为边的权重, 本文提出用户交互网络的生成算法如下:
输入:用户交互历史记录IH
输出:用户交互网络
①遍历用户的交互历史IH中的每个ID (ID=1…n) 对应的记录;
②判断pk∈pi的peerList, 且action为Q, 即判断节点pi是否是响应pk的查询请求;
If 是, 则交互次数Mik加1;
Else交互次数不变, Then ID+1, 转至步骤①;
③判断pi与pk之间是否建立了连接;
If 是, 更改边的权重为Mik;
Else在pi与pk之间建立连接且将交互次数Mik作为边的权重;
④判断是否遍历了所有交互历史记录, 即ID≥n;
If 是, 转至步骤⑤;
Else转至步骤①;
⑤输出用户交互网络, 结束。
该算法主要是遍历节点pi的交互历史库中的每条记录, 如果交互节点集peerList字段中存在节点pk且节点pi响应了节点pk的查询请求, 说明pi与pk在知识共享过程中有过交互, 交互次数加1, 然后判断节点pi与pk之间是否建立了连接, 如果没有则增加一条边, 并把交互次数作为边的权重。
4 社区发现方法
社区结构是P2P网络的一个重要特征, 同一社区的成员之间联系紧密, 不同社区的成员联系则相对较少。社区结构发现在本质上与聚类问题是相似的, 聚类的结果是一类中的事物彼此相似, 而不同类之间有明显的差异[ 16], 相似度又是定义一个类的基础, 因此, 本文通过计算用户相似度, 使用聚类分析进行用户交互网络中的社区发现。
基于用户交互历史构建的网络, 关键是用户之间是否有过交互, 所以本文利用交互频度Wij作为用户相似度的影响因子。基于交互历史形成的网络用一个邻
给出。这里参考文献[15]的用户相似度计算方法。在用户交互网络的邻接矩阵中, 每一个用户的交互历史信息相当于矩阵中的一个向量, 用户相似度就可以转化为用户向量在空间中的距离计算, 两个向量之间的距离越近, 表示用户越相似, 因此本文用户Ui与Uj之间的相似度定义为:
sim (Ui, Uj) =11+dis (Ui, Uj) sim (Ui, Uj) ∈[0, 1]
其中, dis (Ui, Uj) =nm=1 (wim-wjm)2表示用户向量Ui= (wi1, wi2, …, win) 与用户向量Uj= (wj1, wj2, …, wjn) 之间的距离。
根据用户相似度, 选择简单、高效而且可以使用于多种数据类型的K-means算法对用户进行聚类。
5 实验验证
本实验的目的在于验证本文提出的利用交互历史实现社区发现方法的可行性及有效性, 根据实际P2P应用系统中的查询和下载日志, 模拟用户交互网络的生成过程, 计算用户相似度, 并结合K-means算法实现P2P知识共享社区的发现。
5.1 数据准备
实验数据来源于某高校的BT站, 它是根据BitTorrent协议创建的, 以资源共享为主, 包括论坛在内诸多功能的综合娱乐、学习、资源交流的P2P平台。在BitTorrent中, Tracker服务器保存了用户共享的资源信息、查询及下载的信息。本文从该平台上随机选取了8 025个用户参与资源共享产生的20 960条历史记录, 近似于用户在一段时间内形成的交互历史。
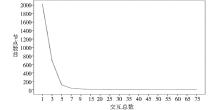
用Java语言编写程序从原始数据集中提取用户交互历史并计算用户间的交互次数。交互总数对应的节点数目 (图中节点数目经过了归一化处理) 关系如图2所示:
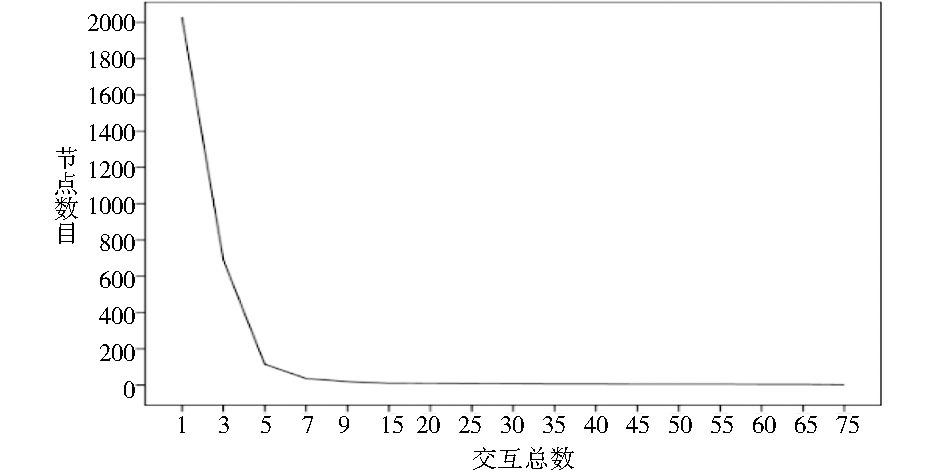 | 图2 交互总数对应的节点数目 |
从图2可以看出, 随着交互总数的增加节点数目在迅速减小, 这说明网络中大部分节点间交互次数较少, 少数的节点比较活跃, 因此可以通过增加交互总数过滤那些相似度较低的节点。
5.2 构建用户交互网络
依据交互历史, 利用UCINET工具构建用户交互网络。为不影响结果图的呈现, 在这个过程中两个用户间建立边时必须满足:用户的交互总数至少为4, 即过滤掉那些相似度较低的节点; 用户间的交互次数大于1, 即至少有过一次交互。同时满足这两个条件的用户形成的用户交互网络如图3所示:
 | 图3 用户交互网络图 |
5.3 社区发现
根据用户交互网络图计算用户交互频度, 得到用户交互网络邻接矩阵。然后根据邻接矩阵利用Matlab工具计算用户相似度。由于数据量比较大, 本文给出部分实验数据, 如图4所示:
 | 图4 用户相似度矩阵 |
最后, 根据用户相似度, 使用K-means算法对用户进行聚类。由于K-means算法要求社区个数k是已知的, 而在实际应用中k难以确定, 选取不同的k值往往会得到差别较大的社区结构, 因此本文根据Newman在2004年提出的Q值度量社区结构的方法[ 17], 针对不同的k值聚类的结果计算Q, 得出当k=3时, Q为0.639达到最大, 社区结构最强, 聚类结果如图5所示:
为了更清晰地表示出在知识共享过程中形成的社区结构, 利用可视化工具Pajek对实验结果进行模拟和验证, 得到的社区结构如图6所示, 其中共有三个社区, 社区中成员个数与图5也基本一致。
6 结 语
本文在分析知识共享产生的交互历史的基础上, 提出一种利用用户交互历史进行P2P社区发现的方法。该方法在考虑用户间的交互次数及交互频度的基础上计算用户相似度, 接着采用K-means算法发现知识共享过程中形成的社区, 最后通过实验验证了方法的有效性。但是, 由于P2P网络的特性, 使得发现的社区中存在大量的恶意节点, 会降低知识共享的效率。未来工作将考虑节点间的信任关系, 隔离社区中的恶意节点, 遏制恶意行为, 使节点可以公平、高效地利用并共享P2P社区中的资源。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|